Prometheus 监控告警系统搭建(对接飞书告警)
Prometheus 是一套开源的系统监控报警框架,非常适合大规模集群的监控。它也是第二个加入CNCF的项目,受欢迎度仅次于 Kubernetes 的项目。本文讲解完整prometheus 监控和告警服务的搭建。
prometheus 监控是当下主流监控系统,它是多个服务组合使用的体系。整体架构预览如下:
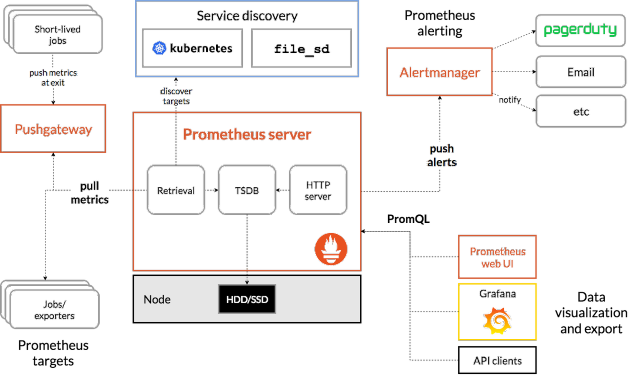
本篇教程监控系统搭建,包括的服务有:
- prometheus 监控的主体,负责数据汇总,保存,监控数据,产生告警信息
- exporter 监控的采集端,负责数据采集
- grafana 数据可视化,负责以丰富的页面展示采集到的数据
- alertmanager 告警管理,负责告警信息处理,包括告警周期,消息优先级等
- prometheusAlert 告警的具体发送端,负责配置告警模板,发出告警信息
除了监控采集节点,其他服务均通过docker-compose部署。部署系统信息:
- 系统:ubuntu20.04
- 服务器IP:172.16.9.124
- docker版本:20.10.21
- docker-compose版本:1.29.2
- 配置文件路径:/root/prometheus
部署prometheus
prometheus主要负责数据采集和存储,提供PromQL查询语言的支持。部署prometheus分为两个步骤:
- 准备配置文件
- 启动prometheus
准备配置文件
整个体系的配置文件在/root/prometheus,首先新建prometheus服务的配置文件路径 /root/prometheus/prometheus,并在这个目录下新建:
- config 用于放置服务主要配置文件 prometheus.yml
- data 用于放置服务的数据库文件
root@ubuntu-System-Product-Name:~/prometheus# tree . -L 3
.
├── docker-compose.yaml
└── prometheus
├── config
│ └── prometheus.yml
└── data
新建prometheus.yml,prometheus服务的主配置文件
global:
scrape_interval: 30s # 每30s采集一次数据
evaluation_interval: 30s # 每30s做一次告警检测
scrape_configs:
# 配置prometheus服务本身
- job_name: prometheus
static_configs:
- targets: ['172.16.9.124:9090']
labels:
instance: prometheus
修改 data 目录的文件权限,让容器有权限在data目录里生成数据相关数据
chmod 777 data
创建 docker-compse.yml
version: '3'
services:
prometheus:
image: prom/prometheus
container_name: prometheus
restart: always
ports:
- "9090:9090"
volumes:
- /root/prometheus/prometheus/config:/etc/prometheus
- /root/prometheus/prometheus/data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.enable-lifecycle'
参数说明:
command:
- --config.file=/etc/prometheus/prometheus.yml 指定使用的配置文件
- --storage.tsdb.path=/prometheus 指定时序数据库的路径
- --web.enable-lifecycle 支持配置热加载
volumes:
- /root/prometheus/prometheus/config:/etc/prometheus 映射配置文件所在目录
- /root/prometheus/prometheus/data:/prometheus 映射数据库路径参数
启动prometheus
启动 docker-compse docker-compose up -d
查看日志:
root@ubuntu-System-Product-Name:~/prometheus# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
776772d69b20 prom/prometheus "/bin/prometheus --c…" 5 minutes ago Up 5 minutes 0.0.0.0:9090->9090/tcp, :::9090->9090/tcp prometheus
查看容器的日志:
docker logs -f 776
ts=2023-12-25T10:21:17.560Z caller=main.go:478 level=info msg="No time or size retention was set so using the default time retention" duration=15d
ts=2023-12-25T10:21:17.560Z caller=main.go:515 level=info msg="Starting prometheus" version="(version=2.32.1, branch=HEAD, revision=41f1a8125e664985dd30674e5bdf6b683eff5d32)"
ts=2023-12-25T10:21:17.561Z caller=main.go:520 level=info build_context="(go=go1.17.5, user=root@54b6dbd48b97, date=20211217-22:08:06)"
ts=2023-12-25T10:21:17.561Z caller=main.go:521 level=info host_details="(Linux 5.15.0-56-generic #62~20.04.1-Ubuntu SMP Tue Nov 22 21:24:20 UTC 2022 x86_64 776772d69b20 (none))"
ts=2023-12-25T10:21:17.561Z caller=main.go:522 level=info fd_limits="(soft=1048576, hard=1048576)"
ts=2023-12-25T10:21:17.561Z caller=main.go:523 level=info vm_limits="(soft=unlimited, hard=unlimited)"
ts=2023-12-25T10:21:17.562Z caller=web.go:570 level=info component=web msg="Start listening for connections" address=0.0.0.0:9090
ts=2023-12-25T10:21:17.562Z caller=main.go:924 level=info msg="Starting TSDB ..."
ts=2023-12-25T10:21:17.562Z caller=tls_config.go:195 level=info component=web msg="TLS is disabled." http2=false
ts=2023-12-25T10:21:17.564Z caller=head.go:488 level=info component=tsdb msg="Replaying on-disk memory mappable chunks if any"
ts=2023-12-25T10:21:17.564Z caller=head.go:522 level=info component=tsdb msg="On-disk memory mappable chunks replay completed" duration=1.305µs
ts=2023-12-25T10:21:17.564Z caller=head.go:528 level=info component=tsdb msg="Replaying WAL, this may take a while"
ts=2023-12-25T10:21:17.564Z caller=head.go:599 level=info component=tsdb msg="WAL segment loaded" segment=0 maxSegment=1
ts=2023-12-25T10:21:17.564Z caller=head.go:599 level=info component=tsdb msg="WAL segment loaded" segment=1 maxSegment=1
ts=2023-12-25T10:21:17.564Z caller=head.go:605 level=info component=tsdb msg="WAL replay completed" checkpoint_replay_duration=14.305µs wal_replay_duration=301.534µs total_replay_duration=327.342µs
ts=2023-12-25T10:21:17.565Z caller=main.go:945 level=info fs_type=EXT4_SUPER_MAGIC
ts=2023-12-25T10:21:17.565Z caller=main.go:948 level=info msg="TSDB started"
ts=2023-12-25T10:21:17.565Z caller=main.go:1129 level=info msg="Loading configuration file" filename=/etc/prometheus/prometheus.yml
ts=2023-12-25T10:21:17.565Z caller=main.go:1166 level=info msg="Completed loading of configuration file" filename=/etc/prometheus/prometheus.yml totalDuration=217.62µs db_storage=555ns remote_storage=860ns web_handler=182ns query_engine=371ns scrape=90.382µs scrape_sd=10.238µs notify=450ns notify_sd=788ns rules=737ns
ts=2023-12-25T10:21:17.565Z caller=main.go:897 level=info msg="Server is ready to receive web requests."
日志很重要!日志很重要!日志很重要!😬 整个监控告警体系服务较多,环节较长,想要顺利完成一定要学会看日志排查问题。比如日志中报错容器没有权限创建文件,所以需要修改目录的权限。
查看web页面
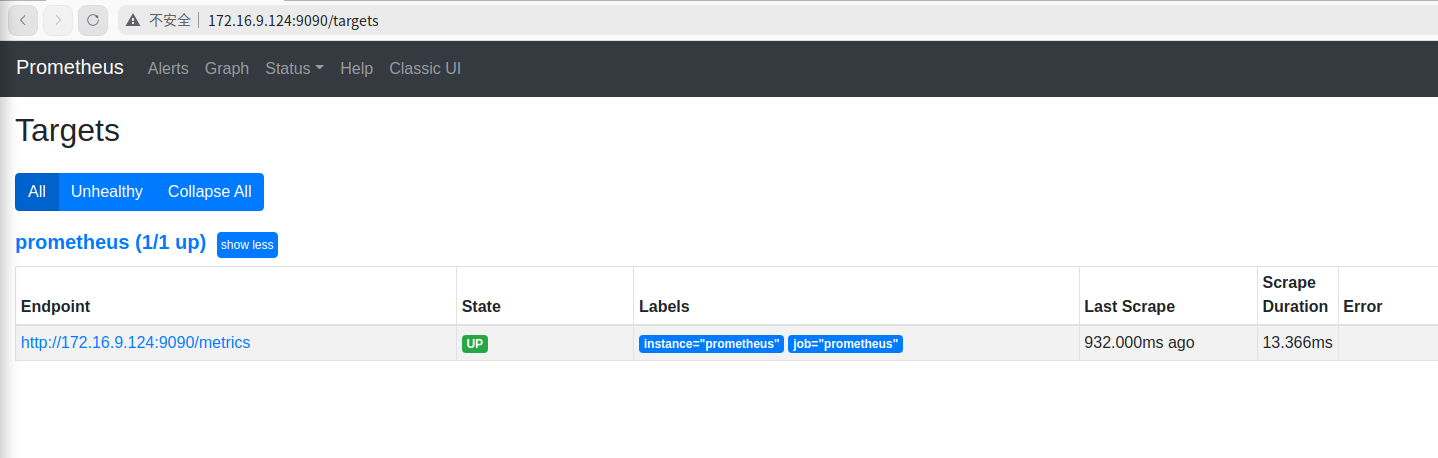
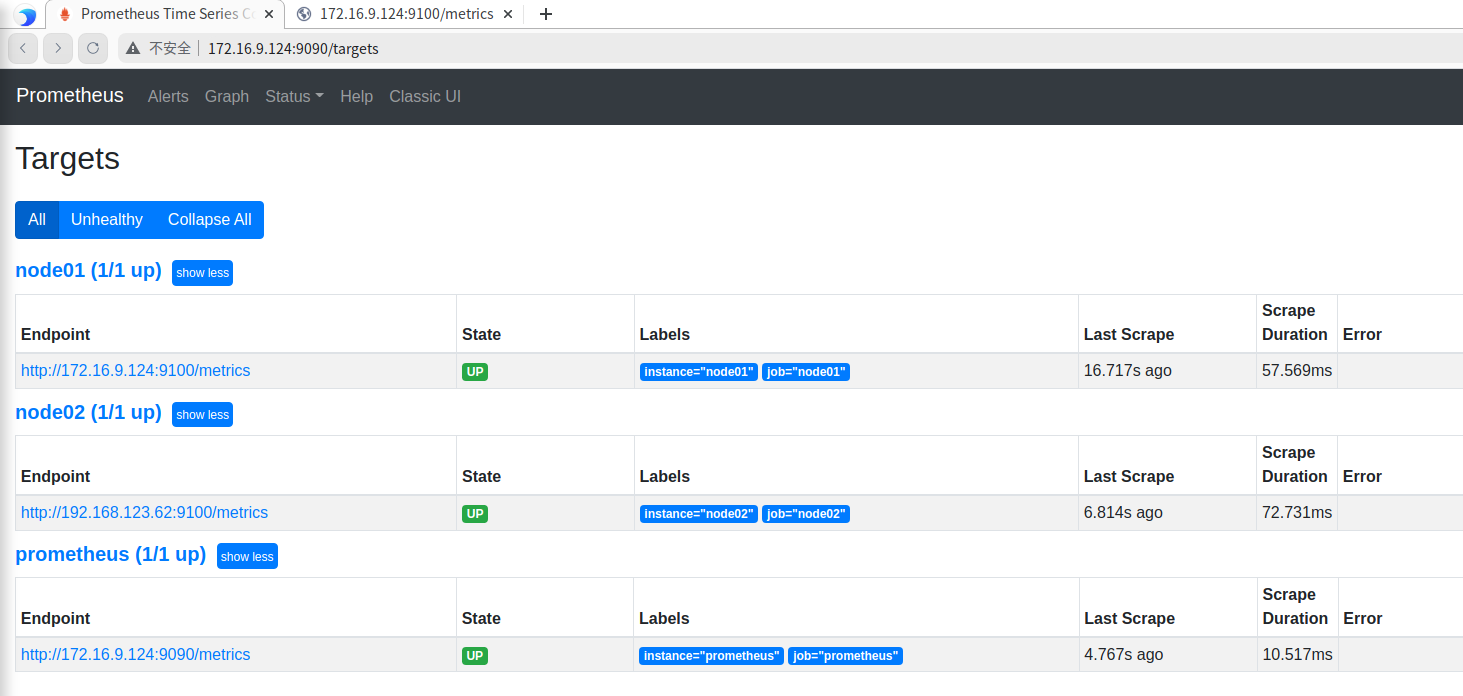
登录prometheus的web页面 172.16.9.124:9090,查看监控的目标端点信息
可以看到只有一个服务,就是prometheus自身,已经是up的状态。
部署exporter
部署了prometheus主服务之后,下一步部署exporter。可以在这里找到常用的exporter,
本篇以最常用的服务器监控node-exporter为例,通过docker部署(最好使用安装包部署,这里主要为了方便快捷)。
启动node-exporter
root@ubuntu-System-Product-Name:~/prometheus# docker run -d --restart=always -p 9100:9100 prom/node-exporter
Unable to find image 'prom/node-exporter:latest' locally
latest: Pulling from prom/node-exporter
aa2a8d90b84c: Pull complete
b45d31ee2d7f: Pull complete
b5db1e299295: Pull complete
Digest: sha256:f2269e73124dd0f60a7d19a2ce1264d33d08a985aed0ee6b0b89d0be470592cd
Status: Downloaded newer image for prom/node-exporter:latest
fa3754932320ed9936d340cb4bb753db38086fa18fd0e99a8cb2ec556ed7f4bd
查看exporter状态
root@ubuntu-System-Product-Name:~/prometheus#docker ps | grep node
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
fa3754932320 prom/node-exporter "/bin/node_exporter" 43 seconds ago Up 42 seconds 0.0.0.0:9100->9100/tcp, :::9100->9100/tcp eager_lehmann
所有的exporter都实现了一个查询的接口,通过访问exporter的端点可以访问其采集到的资源,如node-exporter的接口172.16.9.124:9100

相同步骤,部署了两个node-exporter,分别是node01: 172.16.9.124、node02: 192.168.123.62
更新prometheus
部署好exporter之后,需要配置prometheus定时从exporter采集资源。更新prometheus.yml
global:
scrape_interval: 30s # 每30s采集一次数据
evaluation_interval: 30s # 每30s做一次告警检测
scrape_configs:
- job_name: prometheus
static_configs:
- targets: ['172.16.9.124:9090']
labels:
instance: prometheus
- job_name: node01
static_configs:
- targets: ['172.16.9.124:9100']
labels:
instance: node01
- job_name: node02
static_configs:
- targets: ['192.168.123.62:9100']
labels:
instance: node02
node01 和 node02是启动的两个node-exporter,如果有更多客户端也添加到这里。
重新加载配置文件
让prometheus配置文件生效有两种方法,重新启动prometheus和热加载。因为在部署prometheus时已经配置了其可以热加载,所以通过如下命令即可快速重新加载配置文件。
curl -X POST http://172.16.9.124:9090/-/reload
刷新prometheus页面,查看已经配置的节点的状态,可以看到新加的两个采集节点已经处于up状态,配置生效。
部署grafana
prometheus自带的页面比较简单,通常使用grafana来查看prometheus采集的监控数据。grafana是一个可以展示和分析数据的平台,支持多种数据源和仪表盘的展示方式。下面部署grafana服务。
准备配置文件
新建目录 /root/prometheus/grfana作为grafana服务的主要目录,新建data目录将grafa配置文件映射出来,这样重启不会丢失配置。
root@ubuntu-System-Product-Name:~# tree prometheus/
prometheus/
├── docker-compose.yaml
├── grafana
│ └── data
└── prometheus
├── config
│ └── prometheus.yml
└── data
├── chunks_head
├── lock
├── queries.active
└── wal
├── 00000000
└── 00000001
修改grafana目录的读写权限
chmod 777 -R grafana/
启动grafana服务
在docker-compose.yml中新增grafana服务
version: '3'
services:
prometheus:
image: prom/prometheus
container_name: prometheus
restart: always
ports:
- "9090:9090"
volumes:
- /root/prometheus/prometheus/config:/etc/prometheus
- /root/prometheus/prometheus/data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.enable-lifecycle'
grafana:
image: grafana/grafana
container_name: grafana
restart: always
ports:
- "3000:3000"
volumes:
- /root/prometheus/grafana/data:/var/lib/grafana
重新启动docker-compose.yml
root@ubuntu-System-Product-Name:~/prometheus# docker-compose down
Stopping prometheus ... done
Removing prometheus ... done
Removing network prometheus_default
root@ubuntu-System-Product-Name:~/prometheus# docker-compose up -d
Creating network "prometheus_default" with the default driver
Pulling grafana (grafana/grafana:)...
latest: Pulling from grafana/grafana
97518928ae5f: Pull complete
5b58818b7f48: Pull complete
d9a64d9fd162: Pull complete
4e368e1b924c: Pull complete
867f7fdd92d9: Pull complete
387c55415012: Pull complete
07f94c8f51cd: Pull complete
ce8cf00ff6aa: Pull complete
e44858b5f948: Pull complete
4000fdbdd2a3: Pull complete
Digest: sha256:18d94ae734accd66bccf22daed7bdb20c6b99aa0f2c687eea3ce4275fe275062
Status: Downloaded newer image for grafana/grafana:latest
Creating grafana ... done
Creating prometheus ... done
查看容器状态
root@ubuntu-System-Product-Name:~/prometheus# docker-compose ps
Name Command State Ports
----------------------------------------------------------------------------------------------
grafana /run.sh Up 0.0.0.0:3000->3000/tcp,:::3000->3000/tcp
prometheus /bin/prometheus --config.f ... Up 0.0.0.0:9090->9090/tcp,:::9090->9090/tcp
查看grafana日志
docker logs -f grafana
t=2023-12-25T10:51:21+0000 lvl=info msg="Executing migration" logger=migrator id="add index builtin_role.org_id"
t=2023-12-25T10:51:21+0000 lvl=info msg="Executing migration" logger=migrator id="add unique index builtin_role_org_id_role_id_role"
t=2023-12-25T10:51:21+0000 lvl=info msg="Executing migration" logger=migrator id="Remove unique index role_org_id_uid"
t=2023-12-25T10:51:21+0000 lvl=info msg="Executing migration" logger=migrator id="add unique index role.uid"
t=2023-12-25T10:51:21+0000 lvl=info msg="Executing migration" logger=migrator id="create seed assignment table"
t=2023-12-25T10:51:21+0000 lvl=info msg="Executing migration" logger=migrator id="add unique index builtin_role_role_name"
t=2023-12-25T10:51:21+0000 lvl=info msg="migrations completed" logger=migrator performed=381 skipped=0 duration=1.361595517s
t=2023-12-25T10:51:21+0000 lvl=info msg="Created default admin" logger=sqlstore user=admin
t=2023-12-25T10:51:21+0000 lvl=info msg="Created default organization" logger=sqlstore
t=2023-12-25T10:51:21+0000 lvl=info msg="Initialising plugins" logger=plugin.manager
t=2023-12-25T10:51:21+0000 lvl=info msg="Plugin registered" logger=plugin.manager pluginId=input
t=2023-12-25T10:51:21+0000 lvl=info msg="Live Push Gateway initialization" logger=live.push_http
t=2023-12-25T10:51:21+0000 lvl=info msg="warming cache for startup" logger=ngalert
t=2023-12-25T10:51:21+0000 lvl=info msg="HTTP Server Listen" logger=http.server address=[::]:3000 protocol=http subUrl= socket=
t=2023-12-25T10:51:21+0000 lvl=info msg="starting MultiOrg Alertmanager" logger=ngalert.multiorg.alertmanager
t=2023-12-25T10:52:41+0000 lvl=info msg="Request Completed" logger=context userId=0 orgId=0 uname= method=GET path=/ status=302 remote_addr=192.168.123.62 time_ms=1 size=29 referer=
配置grafana
grafana服务启动之后,配置展示的数据来源、展示的模板等。操作步骤:
- 配置展示数据来源为prometheus服务
- 选择合适的展示模板
登录grafana 172.16.9.124:9100 默认密码是 admin / admin
配置grafana展示数据的来源是 prometheus
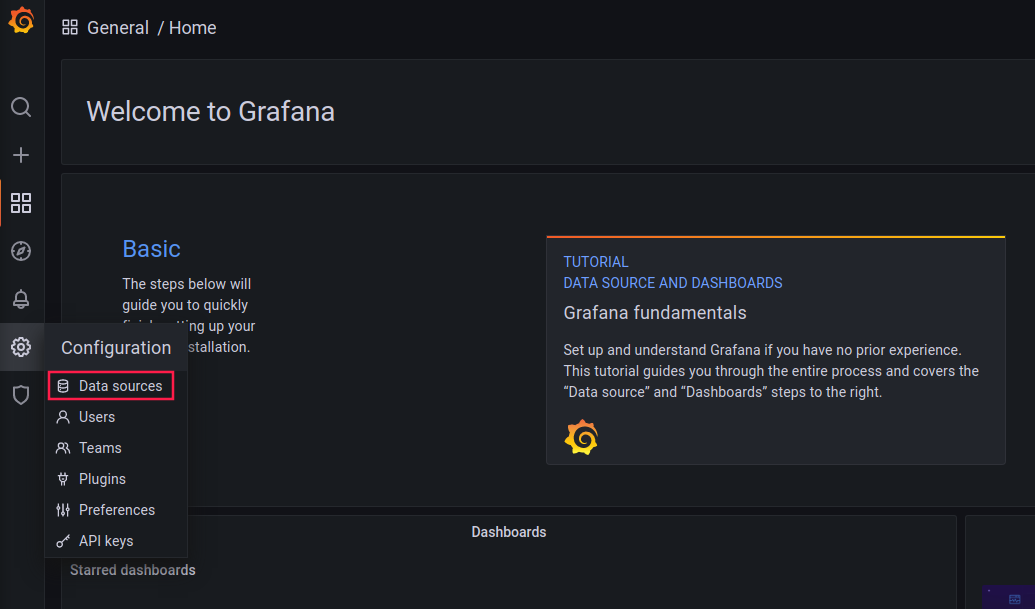
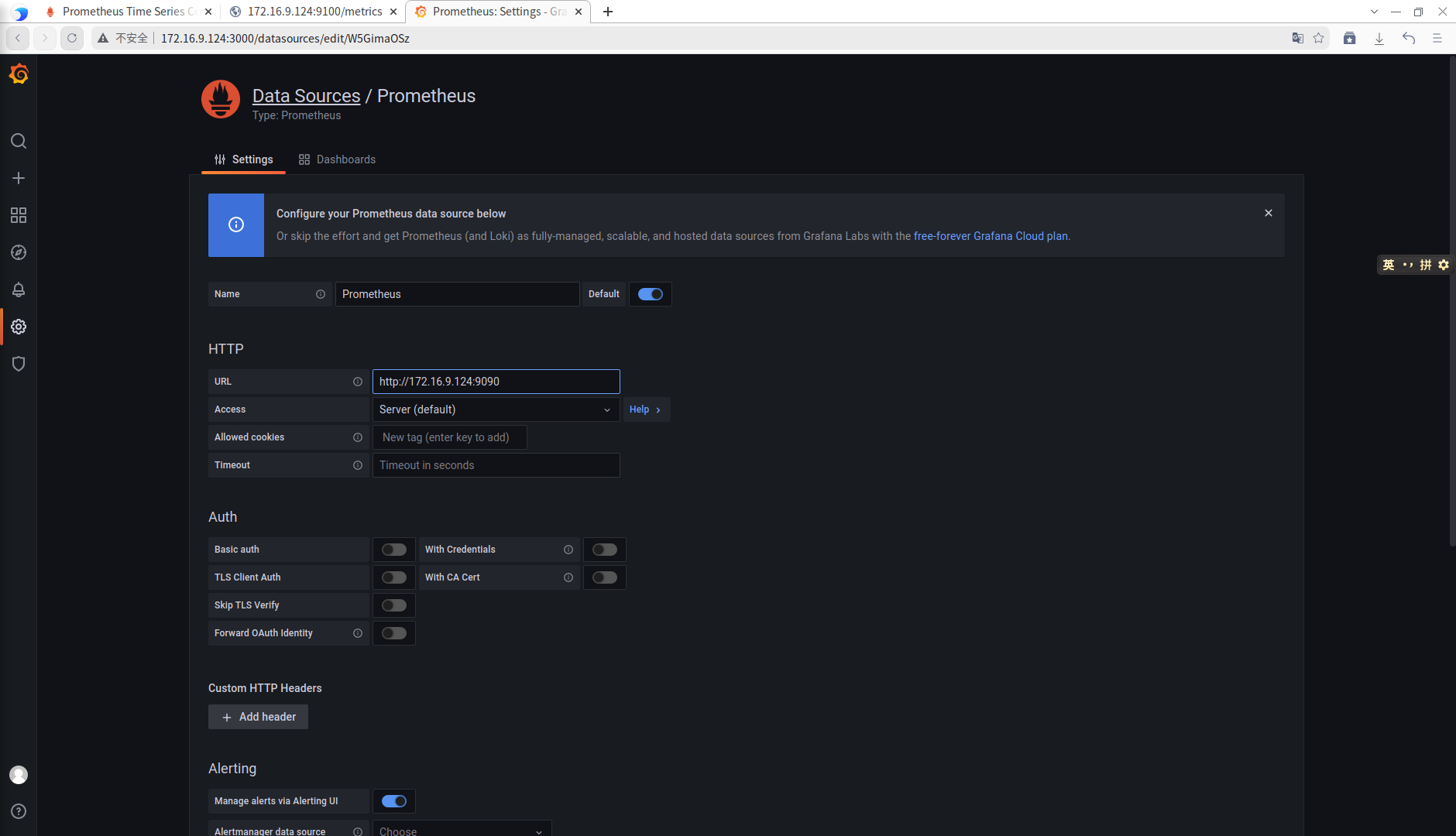
URL中填写 prometheus 的IP:端口号,http://172.16.9.124:9000
保存配置信息
到这里数据来源就配置好了,下面配置展示的模板。
添加展示模板
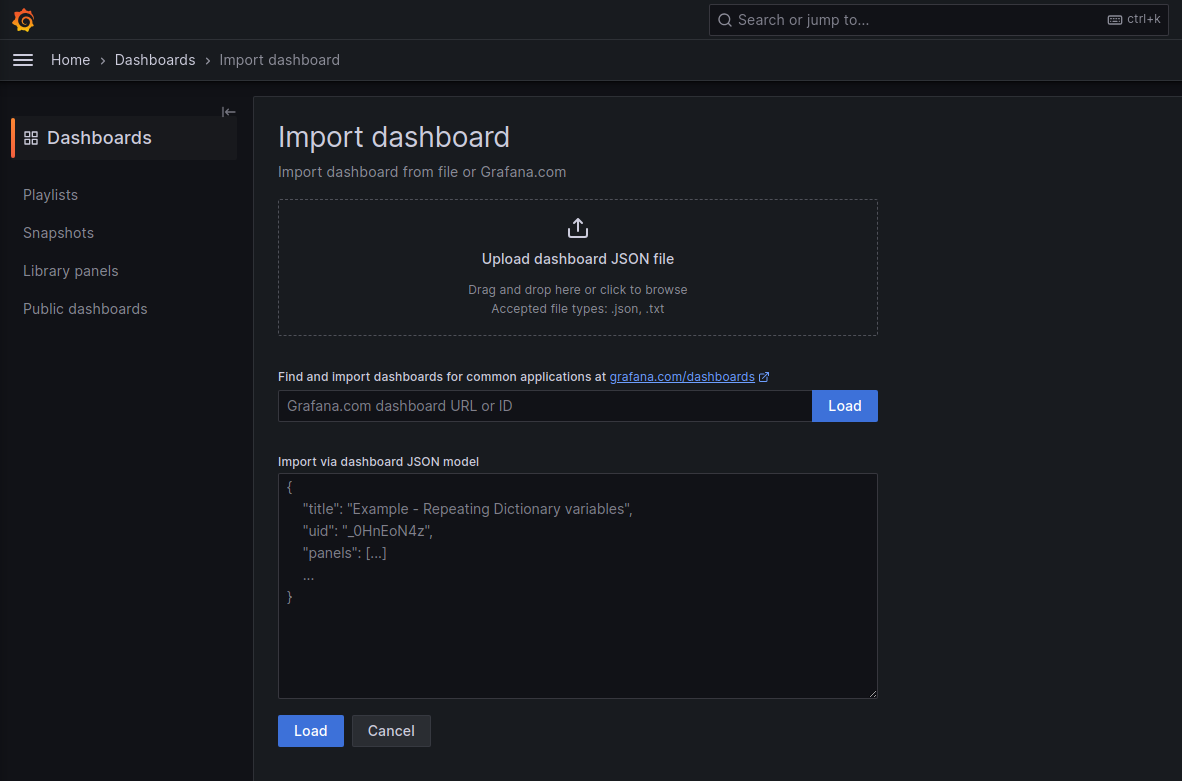
有三种添加模板的方法,分别是上传json文件、load 模板ID、粘贴json字符串。最方便的方法当然是load模板ID,因此选用这种方法。可以在模板商城选择模板 https://grafana.com/grafana/dashboards/
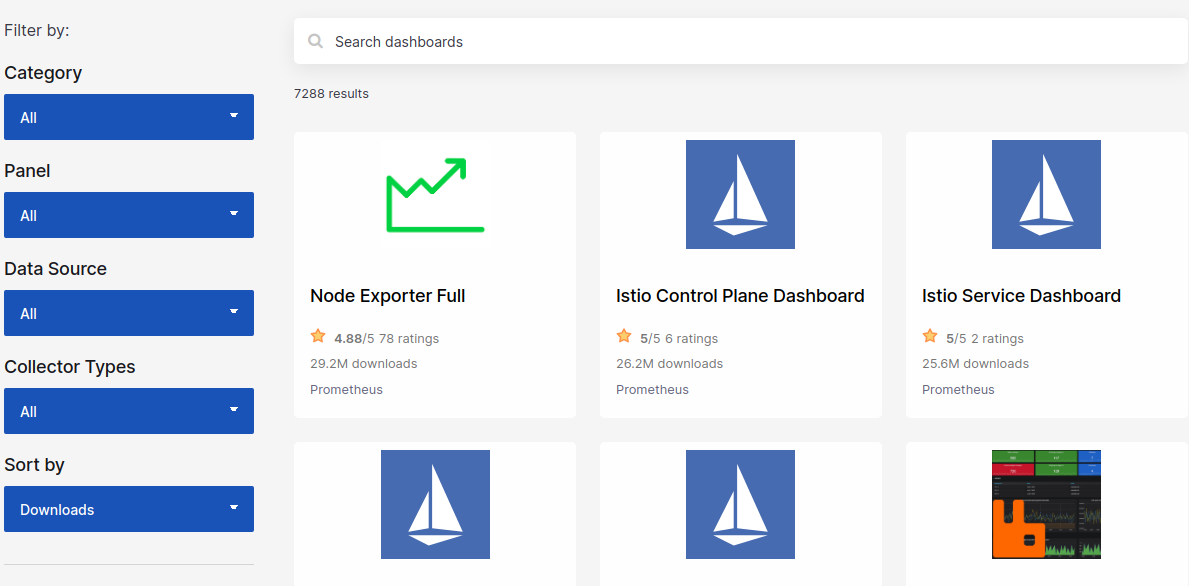
这里我们选择node-exporter配套的展示模板8919
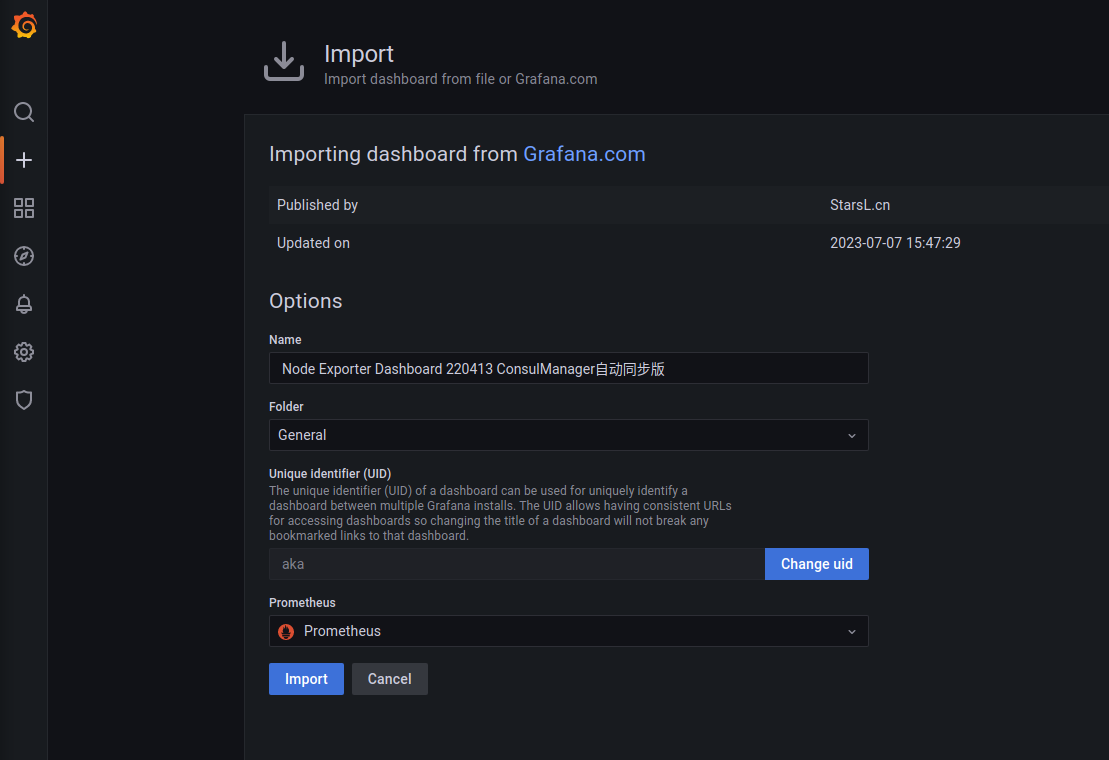
配置完成
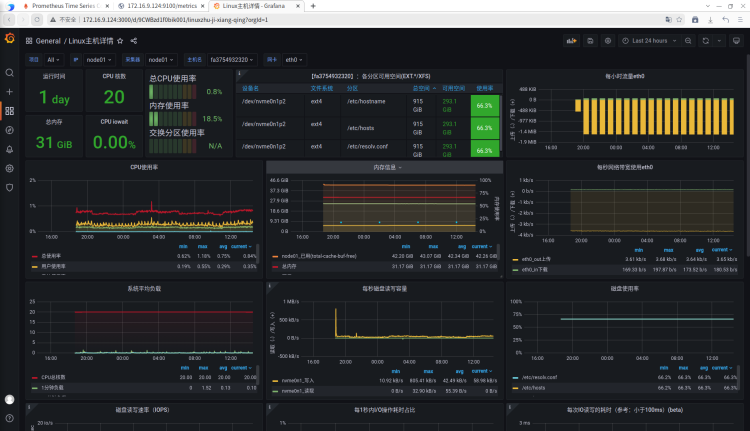
相同步骤导入单个服务器展示模板 12633
展示监控页面
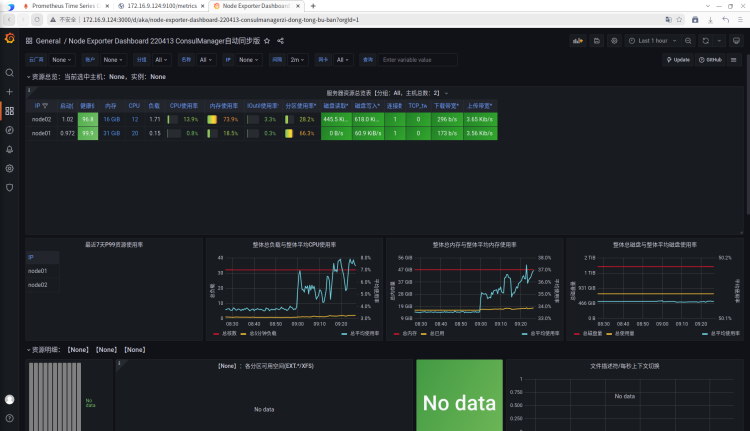
- 服务器列表展示 ID:8919
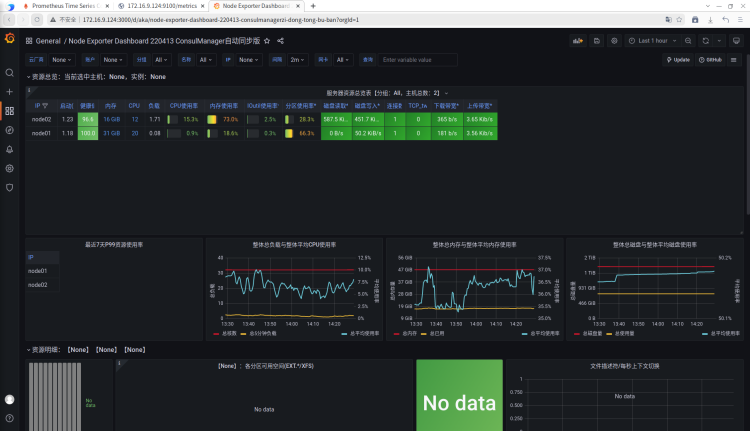
- 单个服务器展示 ID:12633
到这里我们就拥有一个可以采集资源,查看资源的监控平台了。如果不需要告警消息就可以完工了,需要告警配置的请大步向前迈🏃➡️。
部署alertmanager
采集的数据除了展示之后,更重要的是数据集异常告警。prometheus体系中告警是alertmanager服务。
部署步骤:
- 准备配置文件
- 更新prometheus
- 启动alertmanager服务
- 告警测试
准备配置文件
新建告警服务配置目录 /root/prometheus/alertmanager
root@ubuntu-System-Product-Name:~/prometheus# tree . -L 2
.
├── alertmanager
│ └── alertmanager.yml
├── docker-compose.yaml
├── grafana
│ └── data
└── prometheus
├── config
└── data
创建alertmanager服务配置文件 alertmanager.yaml
global:
resolve_timeout: 5m
route:
group_by: ['instance']
group_wait: 30s
group_interval: 60s
repeat_interval: 5m
receiver: 'web.hook.prometheusalert'
receivers:
- name: 'web.hook.prometheusalert'
webhook_configs:
- url: 'http://172.16.9.124:9093'
参数解释:
| 参数 | 解释 |
|---|---|
| resolve_timeout: 5m | 持续5分钟没收到告警信息后认为问题已解决 |
| route | 定义告警路由规则,可以定义多个receiver和group实现告警分组 |
| group_by: ['instance'] | 分组,处于同一组的告警会被合并为同一个通知。这里设置的是instance相同的告警会被合并为同一个通知 |
| group_wait: 30s | 30秒是个时间窗口,这个窗口内,同一个分组的所有消息会被合并为同一个通知 |
| group_interval: 60s | 同一个分组发送一次合并消息之后,每隔1分钟检查一次告警,判断是否要继续对此告警做操作 |
| repeat_interval: 5m | 发送报警间隔,如果指定时间内没有修复,则重新发送报警 |
| receiver: 'web.hook.prometheusalert' | 告警接受者,具体信息将在receivers区域中配置 |
注意:这里receiver配置了一个无效的webhook,所以alertmanager可以收到告警,但是暂时发送不出去。
更新prometheus
将alertmanager集成到prometheus中,分为两步走:
- 新建告警规则文件rules.yml
- 更新prometheus.yml新增alertmanager相关配置
在 /root/prometheus/ptometheus/config 目录下新增告警规则文件 rules.yml,用于给prometheus服务触发告警的规则。
rules.yaml
groups:
- name: 实例存活报警
rules:
- alert: 服务器宕机报警
expr: up == 0
for: 30s
labels:
severity: emergency
level: critical
annotations:
description: '服务器 {{ $labels.instance }}宕机'
该规则用于测试,当一个实例up状态为0超过30s就产生一个告警,告警的内容就是annotations中的description, 例如:服务器node01宕机。更多告警规则自行选择。
修改prometheus.yml相关的配置,新增告警服务和告警规则文件
global:
scrape_interval: 30s # 每30s采集一次数据
evaluation_interval: 30s # 每30s做一次告警检测
# 告警服务
alerting:
alertmanagers:
- static_configs:
- targets: ["172.16.9.124:9093"]
# 告警规则文件
rule_files:
- "rules.yml"
scrape_configs:
- job_name: prometheus
static_configs:
- targets: ['172.16.9.124:9090']
labels:
instance: prometheus
- job_name: node01
static_configs:
- targets: ['172.16.9.124:9100']
labels:
instance: node01
- job_name: node02
static_configs:
- targets: ['192.168.123.62:9100']
labels:
instance: node02
启动alertmanager服务
在docker-compose.yaml中新增alertmanager服务
version: '3'
services:
prometheus:
image: prom/prometheus
container_name: prometheus
restart: always
ports:
- "9090:9090"
volumes:
- /root/prometheus/prometheus/config:/etc/prometheus
- /root/prometheus/prometheus/data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.enable-lifecycle'
grafana:
image: grafana/grafana
container_name: grafana
restart: always
ports:
- "3000:3000"
volumes:
- /root/prometheus/grafana/data:/var/lib/grafana
alertmanager:
image: prom/alertmanager
container_name: alertmanager
restart: always
ports:
- "9093:9093"
volumes:
- /root/prometheus/alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml
重启docker-compose
docker-compose down
docker-compose up -d
登录 172.16.9.124:9093 可以看到告警服务正常启动
登录prometheus web页面,点击菜单Alerts,可以看到所有的告警规则以及触发状态。当前告警处于非active的状态。
告警测试
触发一个告警规则,当一个node-exporter 停止30s就是触发告警规则。关闭node01 的 node-exporter
root@ubuntu-System-Product-Name:~/prometheus/prometheus/config# docker ps | grep node
fa3754932320 prom/node-exporter "/bin/node_exporter" 24 hours ago Up 24 hours 0.0.0.0:9100->9100/tcp, :::9100->9100/tcp eager_lehmann
root@ubuntu-System-Product-Name:~/prometheus/prometheus/config# docker stop fa3
fa3
root@ubuntu-System-Product-Name:~/prometheus/prometheus/config#
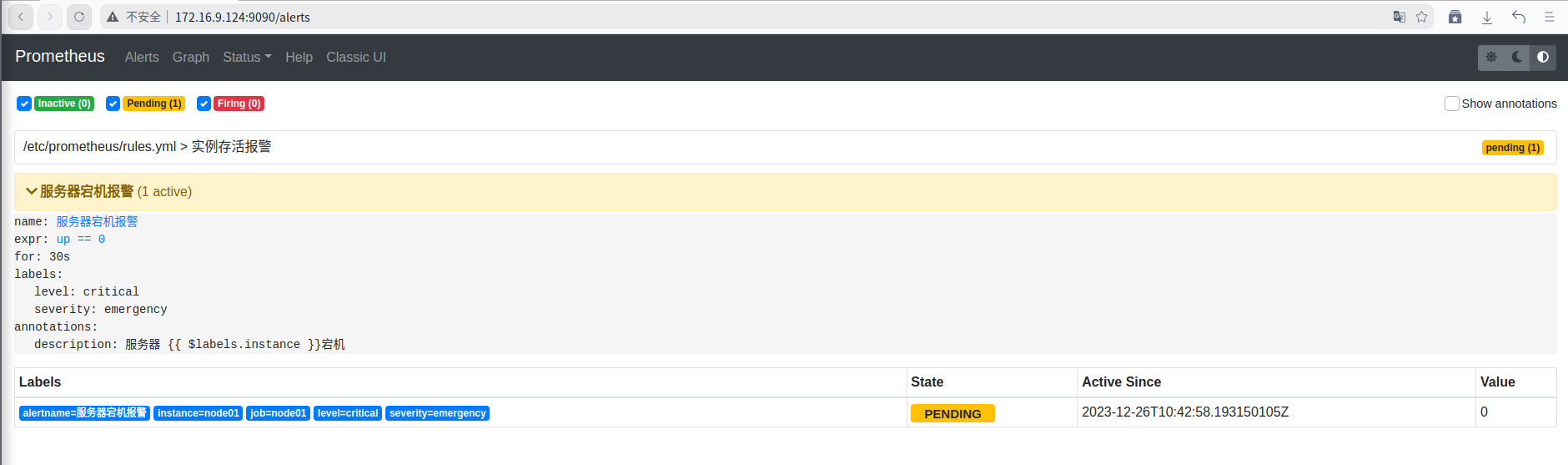
查看prometheus服务的页面,30s之后报警处于等待状态
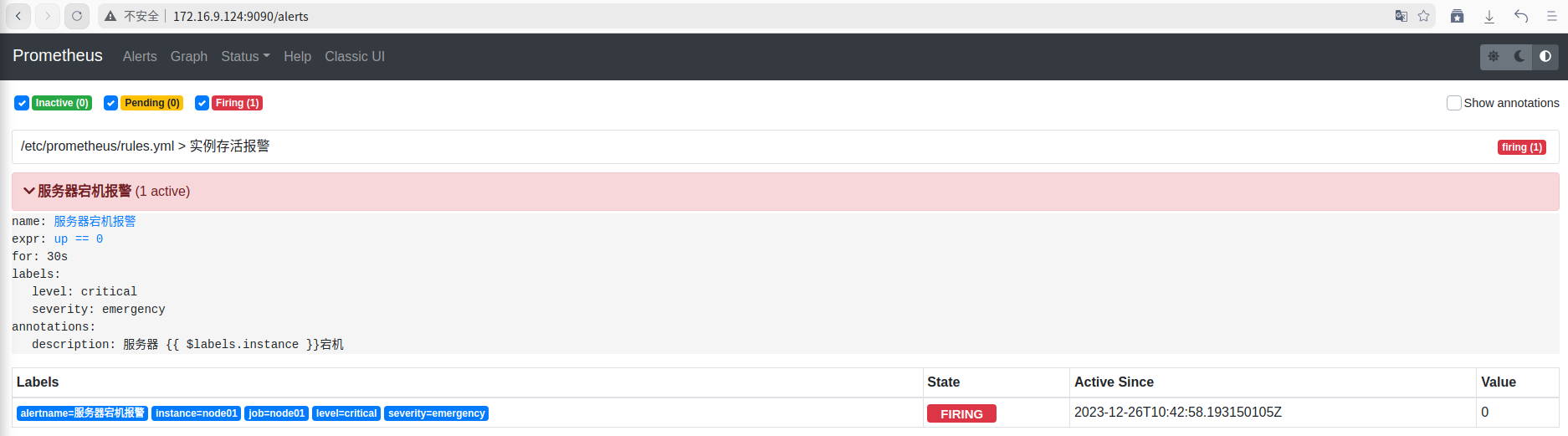
60s之后报警处于激活状态
到这里告警就部署完成了,因为没有给告警receiver配置可用的webhook,所以告警消息能收到但不能发送出去。下一步就部署能将告警消息发送到各个终端的服务 prometheusAlert。
部署prometheusAlert
alertmanager 是告警处理模块,但是告警消息的发送方法并不丰富。如果需要将告警接入飞书,钉钉,微信等,还需要有相应的SDK适配。prometheusAlert就是这样的SDK,可以将告警消息发送到各种终端上。
prometheus Alert 是开源的运维告警中心消息转发系统,支持主流的监控系统 prometheus,日志系统 Graylog 和数据可视化系统 Grafana 发出的预警消息。通知渠道支持钉钉、微信、华为云短信、腾讯云短信、腾讯云电话、阿里云短信、阿里云电话等。
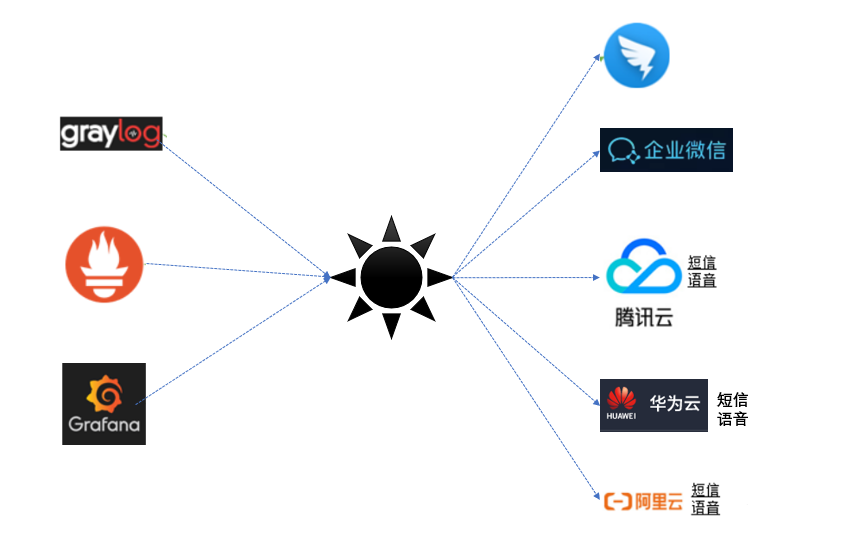
部署prometheusAlert相关步骤:
- 创建飞书机器人
- 准备配置文件
- 启动 prometheusAlert服务
- 对接告警服务
- 调试告警模板
创建飞书机器人
创建飞书机器人步骤比较简单
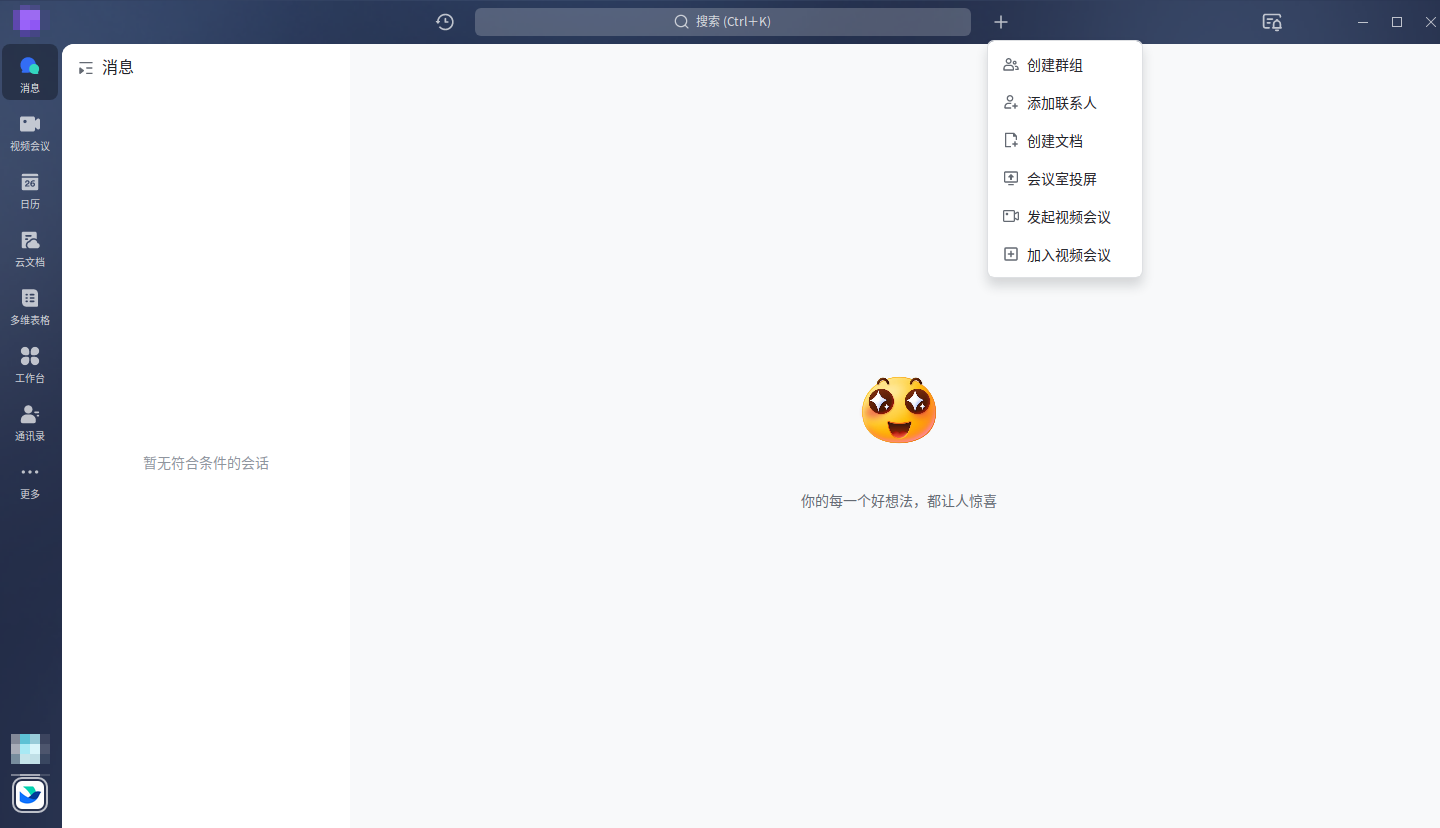
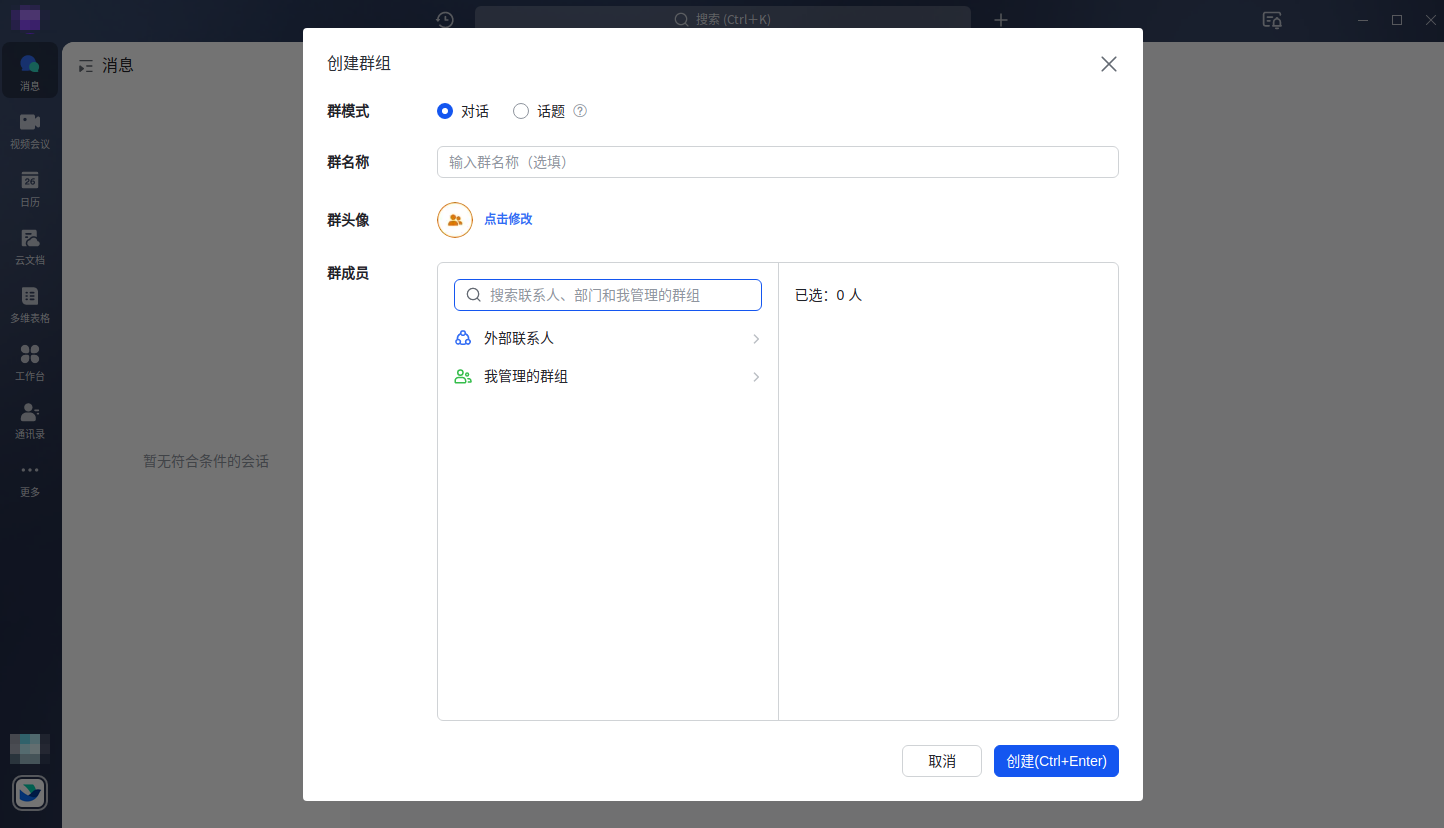
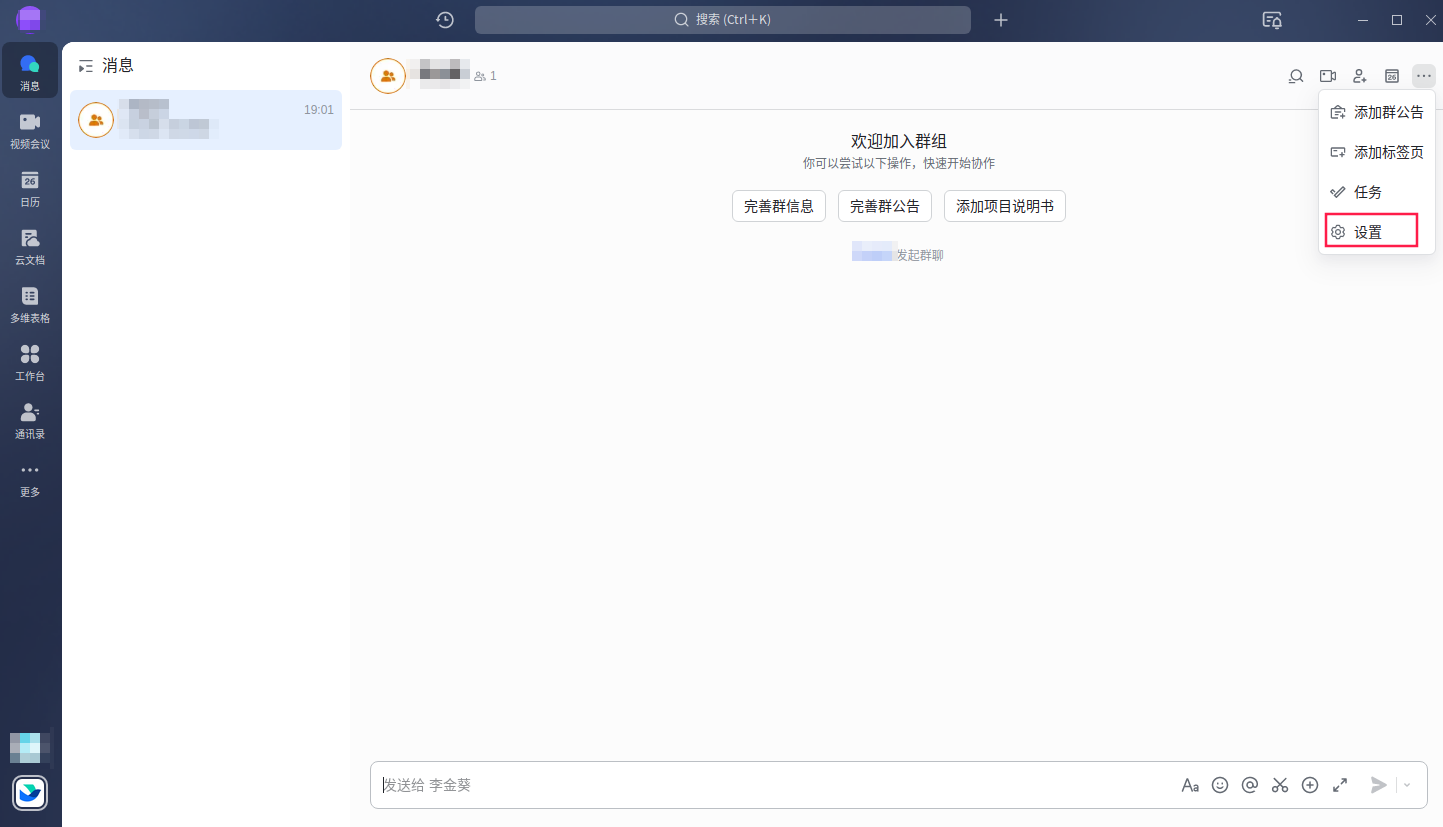
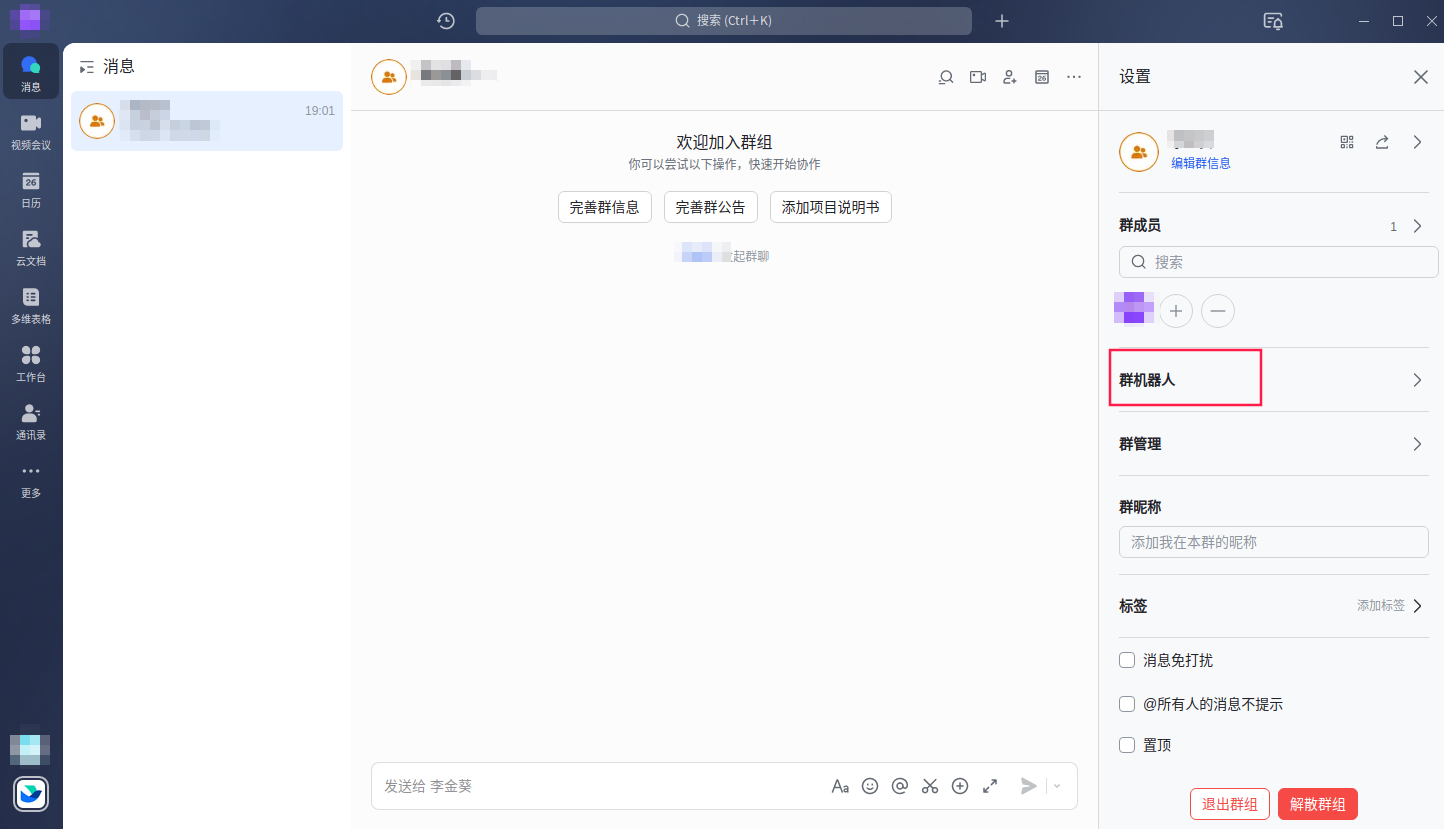

添加自定义关键词,后续在发送的告警消息中一定要包含该关键字,如果没有飞书机器人会丢掉消息。
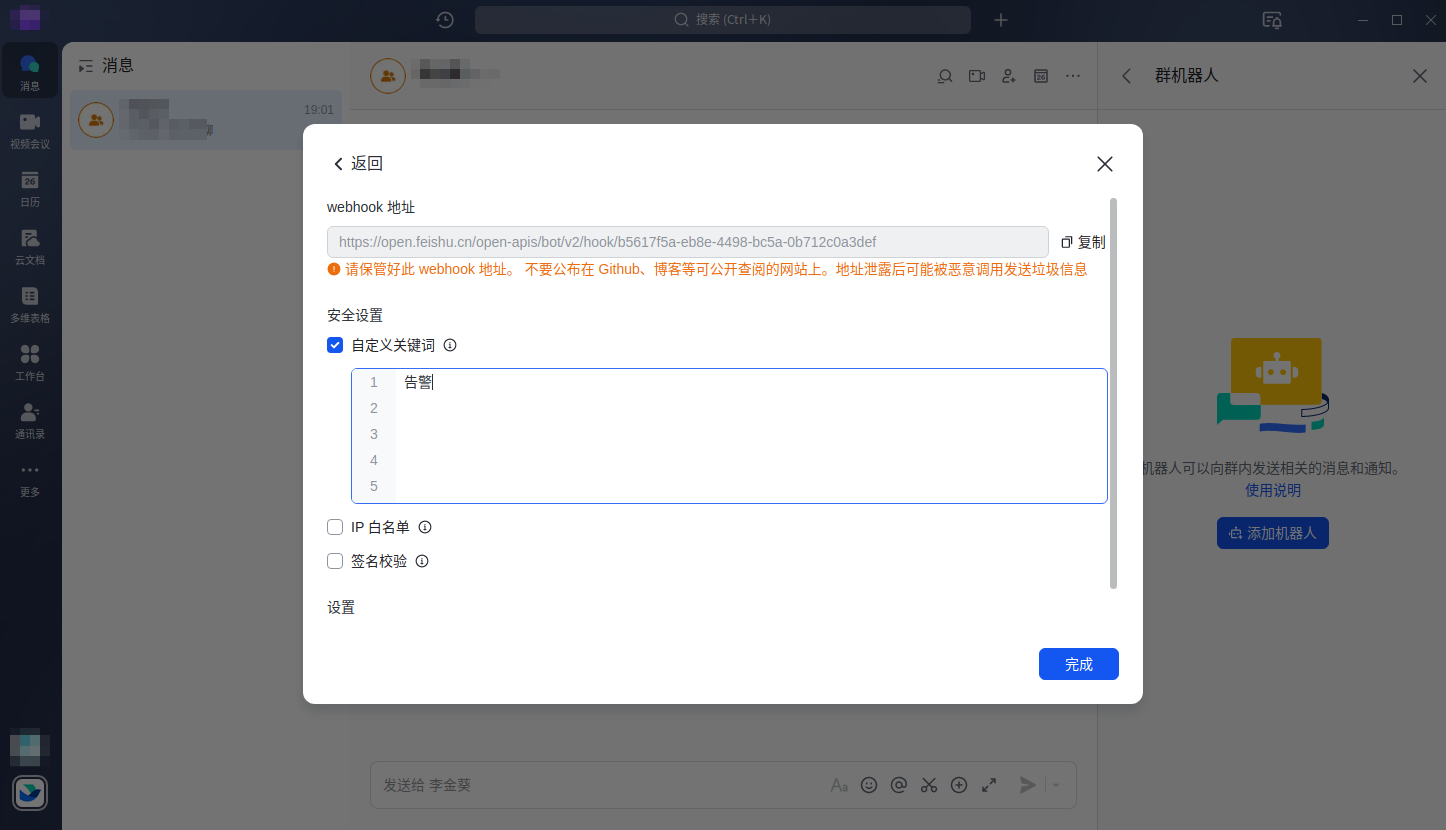
拿到最重要的webhook地址,后面作为告警地址使用
https://open.feishu.cn/open-apis/bot/v2/hook/b56175a-eb8e-4498-b5a-0b712c0a3d4f
不要尝试使用这个webhook,当你能看到的时候,该webhook已经失效了😌。
准备配置文件
新建目录 /root/prometheus/prometheus-alert/db用于保存prometheusAlert的数据库文件,当服务重新部署时不会丢失配置信息。
prometheus
├── alertmanager
│ └── alertmanager.yml
├── docker-compose.yaml
├── grafana
│ └── data
│ ├── alerting
│ ├── csv
│ ├── grafana.db
│ ├── plugins
│ └── png
├── prometheus
│ ├── config
│ │ ├── prometheus.yml
│ │ └── rules.yml
│ └── data
│ ├── 01HJHKAFY3SB9XYD71NECDARSV
│ ├── chunks_head
│ ├── lock
│ ├── queries.active
│ └── wal
└── prometheus-alert
└── db
启动prometheusAlert服务
docker-compose.yml 中新增prometheus-alert服务
version: '3'
services:
prometheus:
image: prom/prometheus
container_name: prometheus
restart: always
ports:
- "9090:9090"
volumes:
- /root/prometheus/prometheus/config:/etc/prometheus
- /root/prometheus/prometheus/data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.enable-lifecycle'
grafana:
image: grafana/grafana
container_name: grafana
restart: always
ports:
- "3000:3000"
volumes:
- /root/prometheus/grafana/data:/var/lib/grafana
alertmanager:
image: prom/alertmanager
container_name: alertmanager
restart: always
ports:
- "9093:9093"
volumes:
- /root/prometheus/alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml
prometheus-alert:
image: feiyu563/prometheus-alert:latest
container_name: prometheus-alert
restart: always
ports:
- "9094:8080"
volumes:
- /root/prometheus/prometheus-alert/db:/app/db
environment:
- PA_LOGIN_USER=alertuser
- PA_LOGIN_PASSWORD=123456
- PA_TITLE=prometheusAlert
- PA_OPEN_FEISHU=1
- PA_OPEN_DINGDING=0
- PA_OPEN_WEIXIN=1
参数解释:
- PA_LOGIN_USER=alertuser 登录账号
- PA_LOGIN_PASSWORD=123456 登录密码
- PA_TITLE=prometheusAlert 系统title
- PA_OPEN_FEISHU=1 开启飞书支持
- PA_OPEN_DINGDING=0 开启钉钉支持
- PA_OPEN_WEIXIN=1 开启微信支持
- /root/prometheus/prometheus-alert/db 将数据库映射出来
重启服务
docker-compose down
docker-compose up -d
查看服务启动状态
root@ubuntu-System-Product-Name:~/prometheus# docker-compose ps
Name Command State Ports
-----------------------------------------------------------------------------------------------------------
alertmanager /bin/alertmanager --config ... Up 0.0.0.0:9093->9093/tcp,:::9093->9093/tcp
grafana /run.sh Up 0.0.0.0:3000->3000/tcp,:::3000->3000/tcp
prometheus /bin/prometheus --config.f ... Up 0.0.0.0:9090->9090/tcp,:::9090->9090/tcp
prometheus-alert /bin/sh /app/docker-entryp ... Up (healthy) 0.0.0.0:9094->8080/tcp,:::9094->8080/tcp
查看日志
docker logs -f 5ec
登录web页面
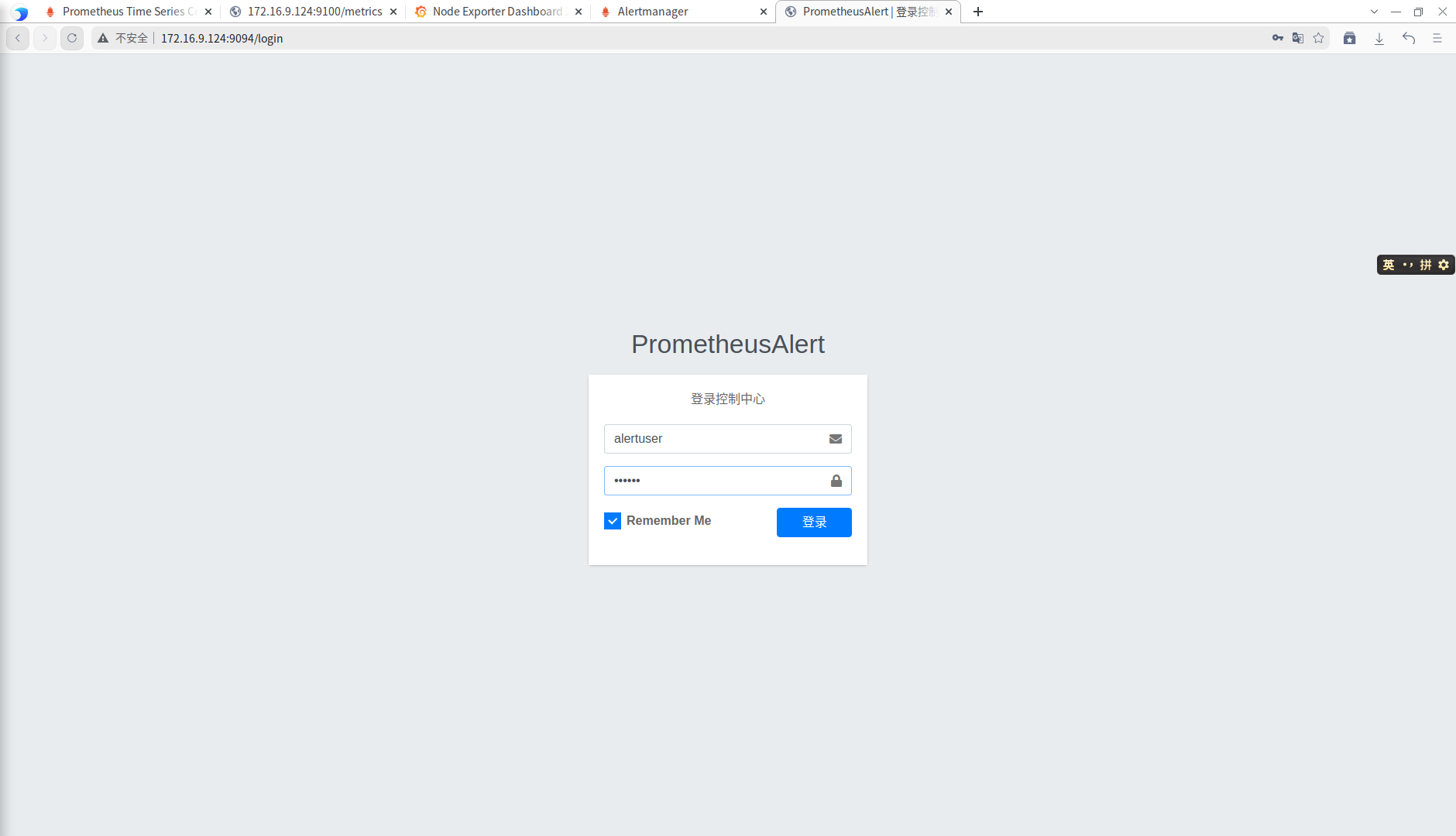
prometheusAlert到这了就部署完成了,目前只是部署好该服务,还没有将服务器接入到告警消息流中。
对接告警服务
prometheusAlert是用于将告警服务alertmanager产生的消息发送给终端,也就是将消息格式化,适配不同的终端,如邮件,短信,微信,钉钉,飞书等不同的接口。
将alertmanager告警消息的接受者指定为prometheus-alert提供的url。修改告警规则rules.yml,添加webhook_configs中url配置。
rules.py
global:
resolve_timeout: 5m
route:
group_by: ['instance']
group_wait: 10m
group_interval: 10s
repeat_interval: 10m
receiver: 'web.hook.prometheusalert'
receivers:
- name: 'web.hook.prometheusalert'
webhook_configs:
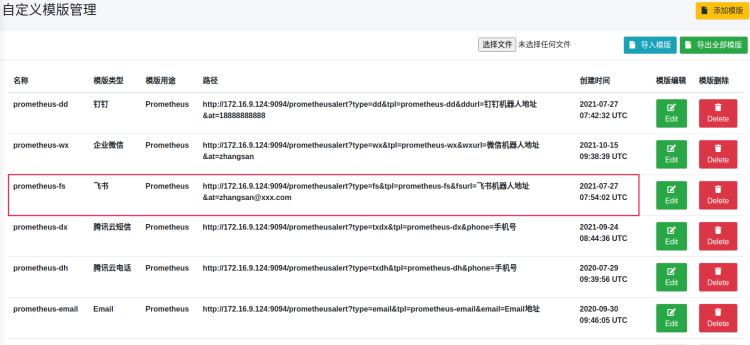
- url: 'http://172.16.9.124:9094/prometheusalert?type=fs&tpl=prometheus-fs&fsurl=https://open.feishu.cn/open-apis/bot/v2/hook/5f4b9c9b-9fed-4bb9-af26-3e1ce174d145'
http://172.16.9.124:9094/prometheusalert?type=fs&tpl=prometheus-fs&fsurl=xxx
是prometheus-alert提供的固定格式,
- type=fs表示为飞书
- tpl=prometheus-fs 表示是prometheus消息
- fsurl 为飞书机器人的webhook,就是创建飞书机器人拿到的webhook
这些参数非常关键,通过type和tpl可以匹配到prometheus-alert上的模板,以上参数匹配到就是飞书的模板。当消息到来的时候,会自动适配到飞书模板,发送给飞书机器人。
重启alertmanager让配置生效
docker-compose start alermanager
重启之后飞书应该就能收到告警消息了
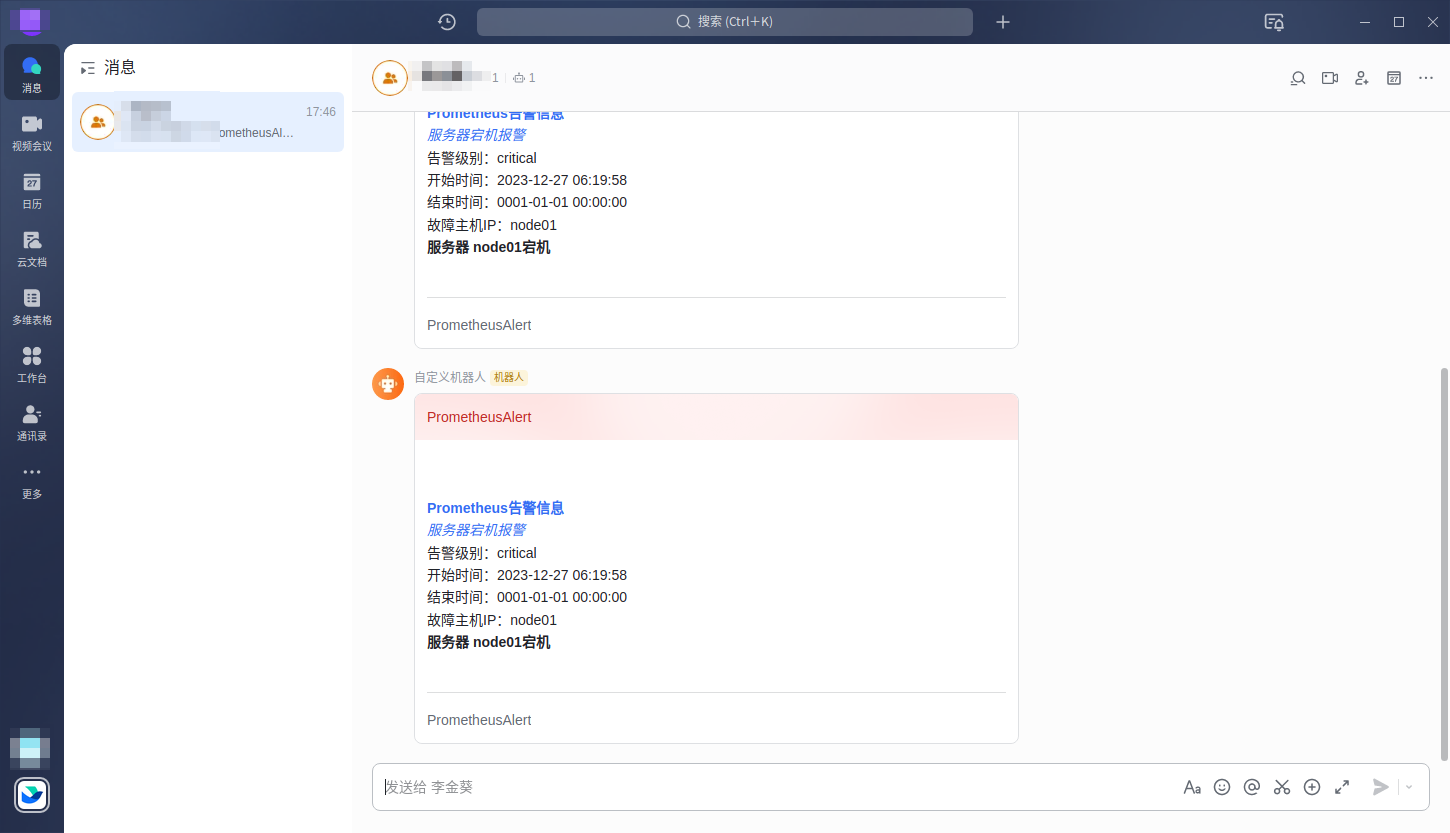
如果不能收到告警消息,排查三个地方,查看告警信息的流向:
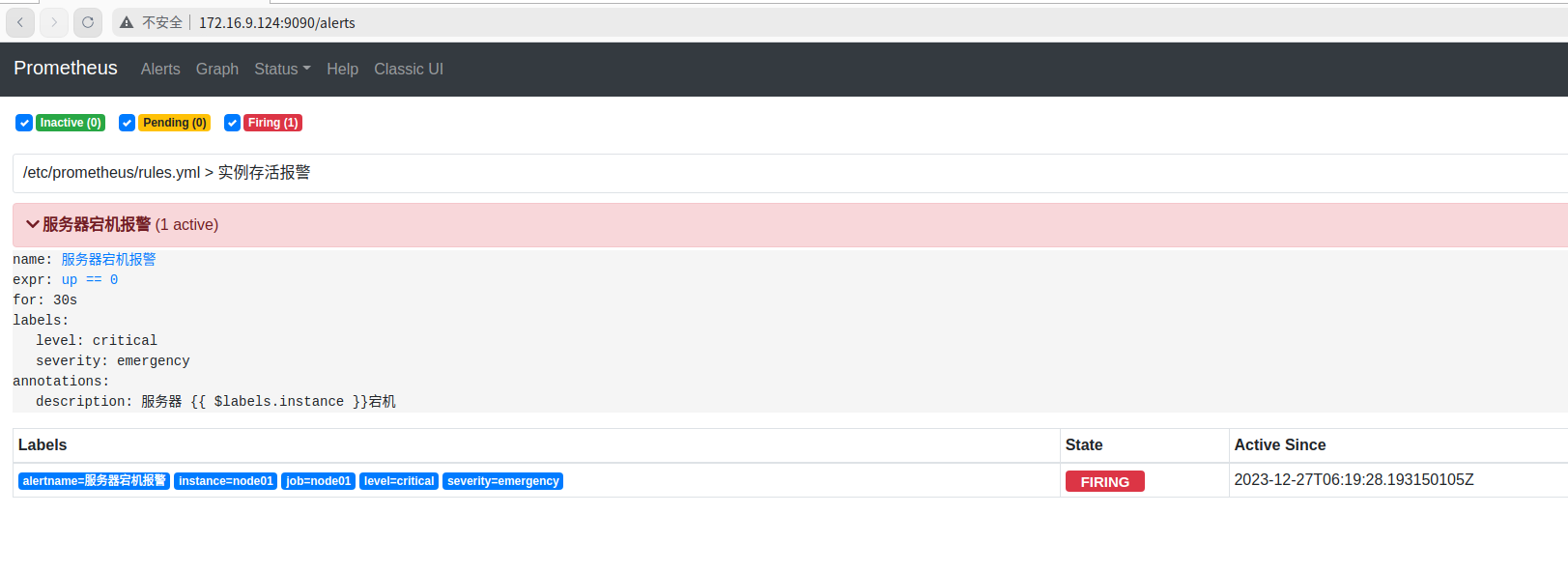
一、prometheus 触发的告警。
是否产生了告警消息
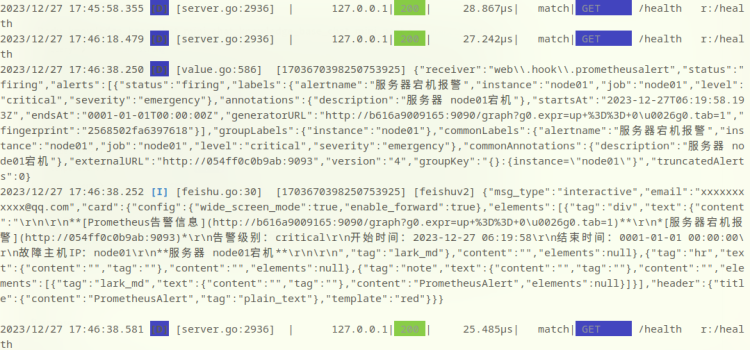
二、prometheusAlert 接收到的告警msg。
当prometheusAlert对接alertmanager之后,告警消息就能发送过来,从日志中可以看到prometheusAlert接收到的错误信息。
三、prometheusAlert web端显示发送的告警。
查看prometheusAlert的消息统计信息,是否有消息发送进来和出去。如果从日志中看到有消息进来,但是统计页面没有消息出去,那就是服务模板配置有问题,有问题——看日志。

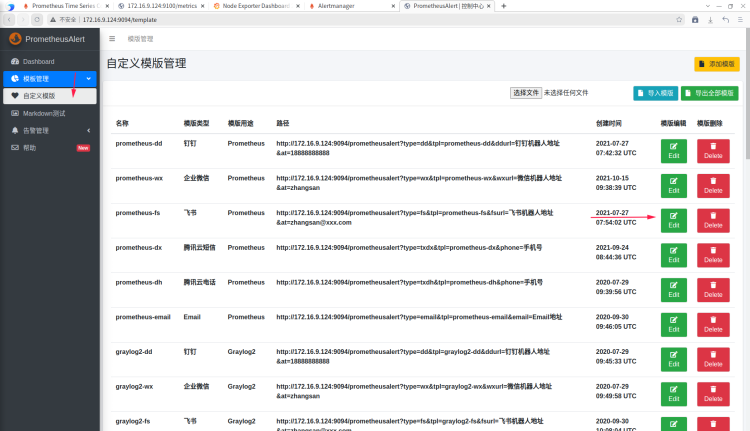
调试告警模板
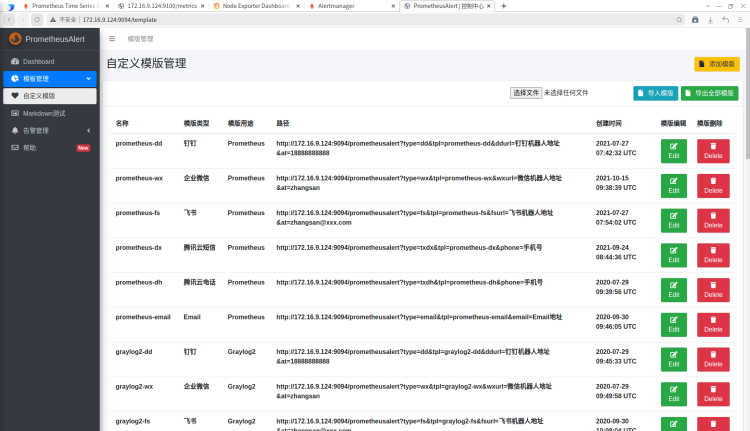
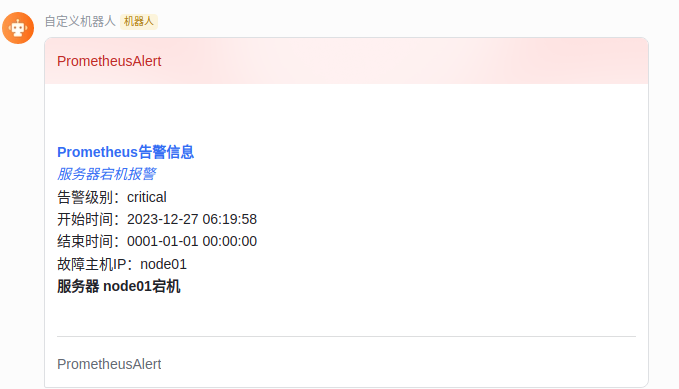
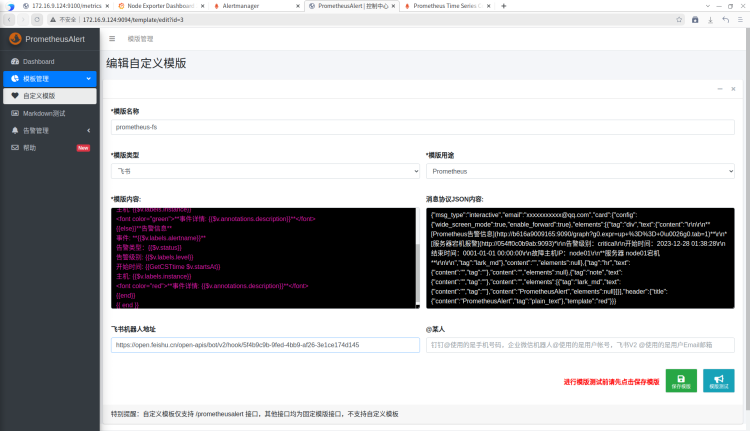
默认告警模板很难满足所有人的审美,如果要选择更多模板,可以使用prometheusAlert提供的模板功能完成。默认的模板如下:
进入模板编辑页面
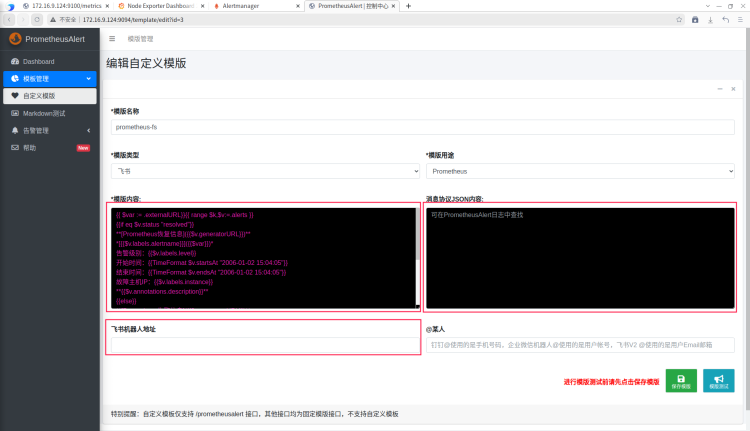
红框内容都是必填内容,分别是模板的内容,日志中json格式的告警消息,飞书机器人的地址。
其中模板可以从这里去找:https://github.com/feiyu563/prometheusAlert/issues/30,比如说我个人喜欢这个
填写相应的信息
点击测试,能够发送该模板的消息到飞书机器人
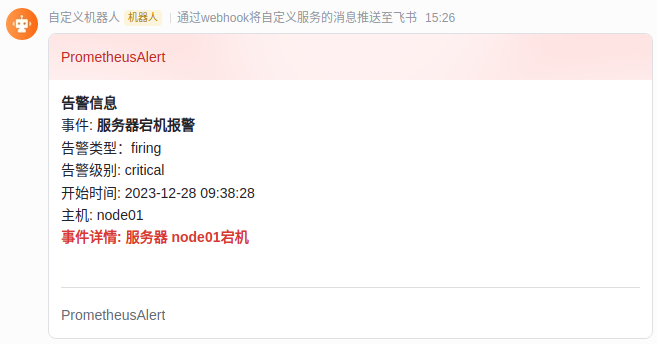
当告警恢复了之后,还会发送一个恢复的消息

为了方便测试,把模板和告警日志也搬过来
模板
{{ range $k,$v:=.alerts }}{{if eq $v.status "resolved"}}<font color="green">**告警恢复信息**</font>
事件: **{{$v.labels.alertname}}**
告警类型:{{$v.status}}
告警级别: {{$v.labels.level}}
开始时间: {{GetCSTtime $v.startsAt}}
结束时间: {{GetCSTtime $v.endsAt}}
主机: {{$v.labels.instance}}
<font color="green">**事件详情: {{$v.annotations.description}}**</font>
{{else}}**告警信息**
事件: **{{$v.labels.alertname}}**
告警类型:{{$v.status}}
告警级别: {{$v.labels.level}}
开始时间: {{GetCSTtime $v.startsAt}}
主机: {{$v.labels.instance}}
<font color="red">**事件详情: {{$v.annotations.description}}**</font>
{{end}}
{{ end }}
日志
{"msg_type":"interactive","email":"xxxxxxxxxxx@qq.com","card":{"config":{"wide_screen_mode":true,"enable_forward":true},"elements":[{"tag":"div","text":{"content":"\r\n\r\n**[prometheus告警信息](http://b616a9009165:9090/graph?g0.expr=up+%3D%3D+0\u0026g0.tab=1)**\r\n*[服务器宕机报警](http://054ff0c0b9ab:9093)*\r\n告警级别:critical\r\n开始时间:2023-12-28 01:38:28\r\n结束时间:0001-01-01 00:00:00\r\n故障主机IP:node01\r\n**服务器 node01宕机**\r\n\r\n","tag":"lark_md"},"content":"","elements":null},{"tag":"hr","text":{"content":"","tag":""},"content":"","elements":null},{"tag":"note","text":{"content":"","tag":""},"content":"","elements":[{"tag":"lark_md","text":{"content":"","tag":""},"content":"prometheusAlert","elements":null}]}],"header":{"title":{"content":"prometheusAlert","tag":"plain_text"},"template":"red"}}}
ok,到此为止prometheus的搭建就完成了,撒花🎉🎉🎉
整个过程步骤较多,即使是我第二次搭建也出现了很多问题。有问题也不要慌,多看日志,搜索报错记录,分析可能的报错原因,问题终会解决👌。

