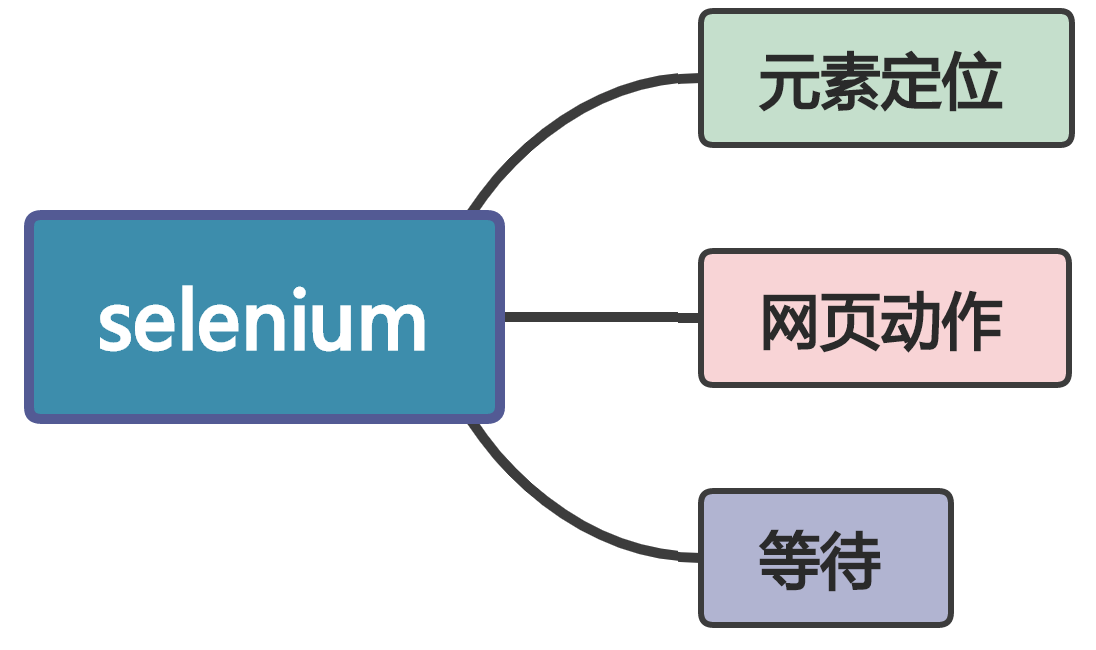
selenium 开源UI测试工具

UI 自动化测试相关内容:
1|0简介
selenium是一个用于Web应用程序测试的工具。selenium测试直接运行于浏览器网页上,可以模拟用户操作网页。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera,Edge等。
Selenium 能够实现的功能包括:定位网页元素、模拟点击、滑动、键盘输入等等操作。
selenium 支持的语言包括:
- Python
- CSharp
- Ruby
- JavaScript
- Kotlin
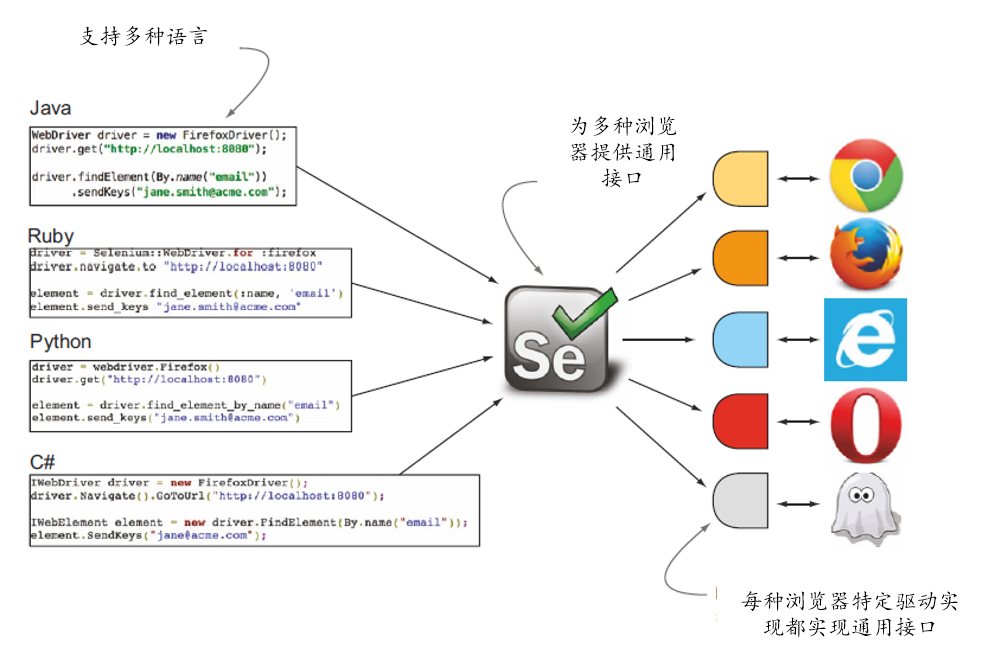
本教程以python操作selenium为例,说明selenium的使用方法。
2|0简单使用
selenium 是第三方模块,首先安装该模块
selenium模块 一共有4个大的版本,最新的4.x版本和之前的版本在语法上有较大的变化,所以安装最新的4.x版本,避免低版本带来的混乱。
2|1打开浏览器请求网页
执行该代码,打开chrome浏览器,请求网页
2|2操作网页元素
操作网页的原理就是首先根据元素name定位找到了输入框
然后向输入框填充 python selenium,
最后触发输入框的回车键。
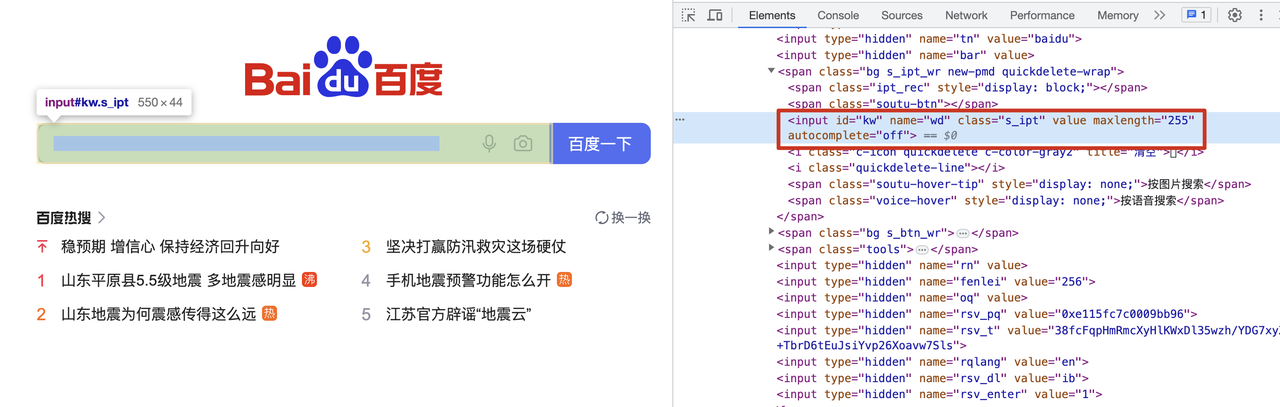
selenium 拥有的能力简单来说就是定位html中元素,操作元素。
3|0元素定位
selenium 可以定位网页中元素,其拥有的方法和JavaScript类似,可以通过元素的特征定位,一共拥有8种定位元素的方法,分别是:
- 根据元素ID定位
- 根据元素name定位
- 根据元素class_name定位
- 根据元素xpath定位
- 根据元素tag_name定位
- 根据元素css定位
- 根据超链接文本定位
3|1ID
在id定位里,会返回第一个id属性匹配的元素,如果没有元素匹配,会抛出NoSuchElementException异常。
可以这样定位表单元素form:
3|2Name
在name定位里,会返回第一个name属性匹配的元素,如果没有元素匹配,会抛出NoSuchElementException异常。
username 和 password元素 可以这样定位:
3|3class_name
知道class就使用这个定位,只返回匹配的第一个,无元素匹配,会抛出NoSuchElementException异常。
实例:
定位p元素:
3|4xpath
XPath是用来定位XML文档节点的语言。不过HTML可以看成是XML(XHTML)的一种实现。selenium用户可以使用这个强力的语言来瞄准Web应用的元素。 XPath延伸了用id或者name属性来定位的单一方法,开创了许多可能性,例如定位页面的第三个复选框
用XPath的主要理由之一,就是你想定位的元素没有合适的id或者name属性的时候,你可以用XPath来对元素进行绝对定位(不推荐)或者把这个元素和另外一个有确定id或者name的元素关联起来(即相对定位)。XPath定位器也可以用来找出那些具有id,name以外属性的元素。
form元素可以这样定位:
这里下标表示是从1开始的
- 绝对路径(如果HTML有细微的改变就会失效)
- HTML的第一个form元素
- id属性为'loginForm'的form元素
username元素可以这样定位:
- 第一个form元素的 name属性是'username'的input子元素
- id属性为'loginForm'的form元素的第一个input子元素
- name属性为'username'的第一个input元素
clear 按钮可以这样定位:
- type属性为'button',name属性为'continue'的第一个input元素
- id为'loginForm'的表单的第四个input子元素
3|5tag_name
知道元素标签名就使用这个定位,如果没有元素匹配,会抛出NoSuchElementException异常。
实例:
可以这样定位标题元素(h1):
3|6css
如果你能用css选择器的语法来表述一个元素,那么就选这个,只返回匹配的第一个,无元素匹配,会抛出NoSuchElementException异常。
实例:
定位p元素:
3|7Link text
链接标签使用了什么文本,那么通过链接的文本进行定位。在超链接定位里,会返回第一个文本属性匹配的链接,如果没有元素匹配,会抛出NoSuchElementException异常。
实例:
可以这样定位 continue.html链接:
知识加油站: find_element 方法特点是查找到匹配的元素,返回第一个。如果想返回所有的元素可以使用方法find_elements。参考"登录算法仓"中的使用。
4|0网页动作
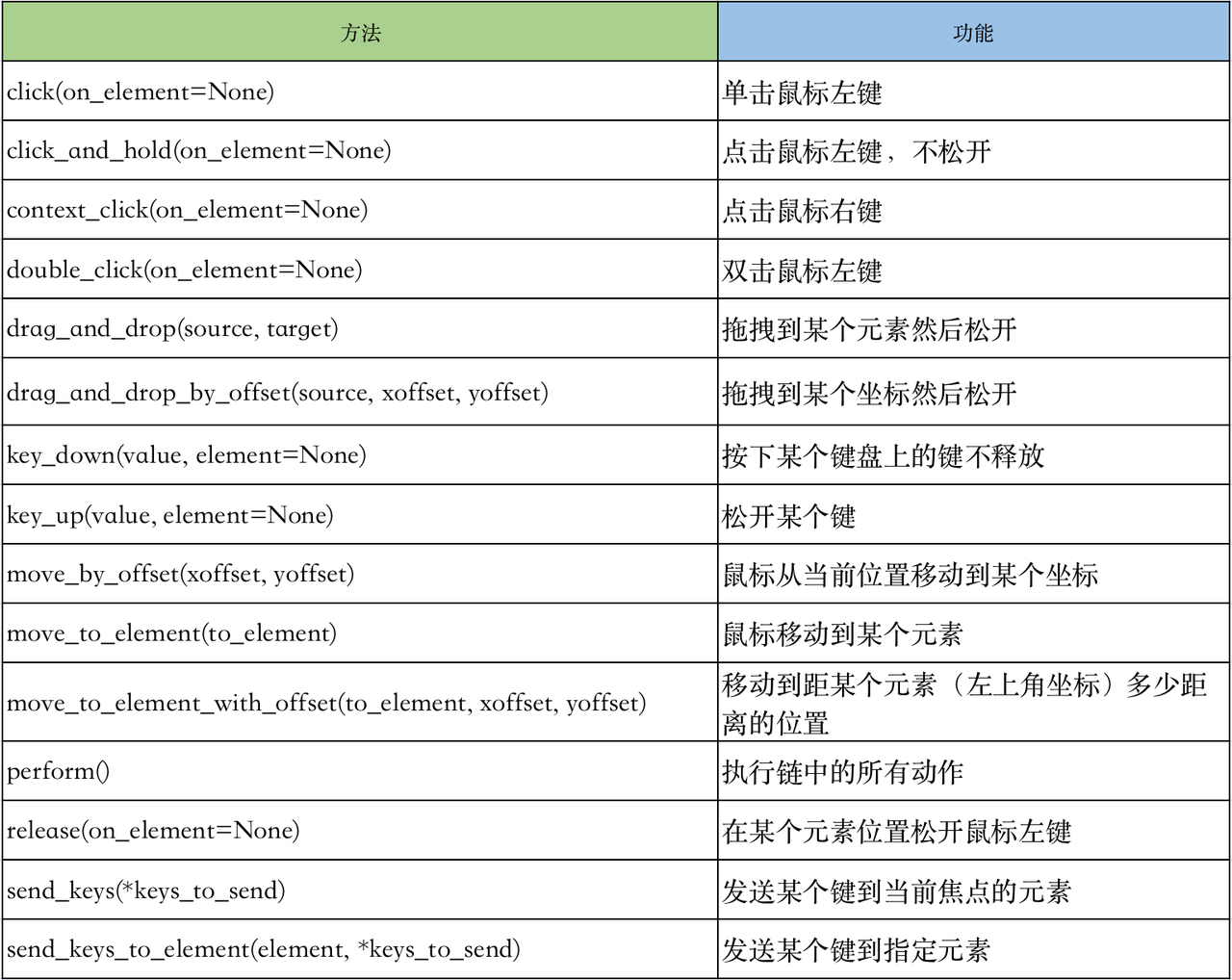
用selenium做自动化,有时候会遇到需要模拟鼠标操作才能进行的情况,比如单击、双击、点击鼠标右键、拖拽等等。而selenium给我们提供了一个类来处理这类事件——ActionChains。ActionChains 能够模拟键盘、鼠标等设备的操作。
ActionChains基本用法
首先需要了解ActionChains的执行原理,当你调用ActionChains的方法时,不会立即执行,而是会将所有的操作按顺序存放在一个队列里,当你调用perform()方法时,队列中的时间会依次执行。
这种情况下我们可以有两种调用方法:
链式写法
分步写法
两种写法本质是一样的,ActionChains都会按照顺序执行所有的操作。
动作列表
4|1Click
Click 模拟鼠标左键的点击事件,也就是最常用的鼠标点击
4|2key_down key_up
key_down动作是按下一个按键,对应的key_up是释放一个按键。通常这两个操作时成对出现的。模拟在数据框中以shfit + 小写字母 输入,将小写字母变成大写字母。
4|3send_keys
send_keys的功能有两个:
- 向当前元素发送文字
- 向当前元素发送按键
在搜索框上有两种方法可以触发搜索,一种是点击搜索按钮;另一种是搜索框绑定回车键。其中bing.com支持第二种方法,所以可以在输入框输入完成之后发送回车按键完成搜索。
5|0等待
为什么要使用等待?
在自动化测试脚本的运行过程中,webdriver操作浏览器的时候,对于元素的定位是有一定的超时
时间,大致在1-3秒
如果这个时间内仍然定位不到元素,就会抛出异常,中止脚本执行
我们可以通过在脚本中设置等待的方式来避免由于网络延迟或浏览器卡顿导致的偶然失败
常用的三种等待方式
- 强制等待
- 隐式等待
- 显示等待
5|1强制等待
利用time模块的sleep方法来实现,最简单粗暴的等待方法
强制等待,不管你浏览器是否加载完成,都得给我等待3秒,3秒一到,继续执行下面的代码
弊端
不建议用这种等待方法,严重影响代码的执行速度
5|2隐式等待
implicitly_wait()方法用来等待页面加载完成(直观的就是浏览器tab页上的小圈圈转完)网页加载完成则执行下一步
隐式等待只需要声明一次,一般在打开浏览器后进行声明。声明之后对整个drvier的生命周期都有效,后面不用重复声明
弊端
程序会一直等待整个页面加载完成,直到超时
有时候我需要的那个元素早就加载完成了,只是页面上有个别其他元素加载特别慢,我仍要等待页
面全部加载完成才能执行下一步
5|3显示等待
WebDriverWait,配合该类的until()和until_not()方法,就能够根据判断条件而进行灵活地等待了。
它主要的意思就是:程序每隔xx秒看一眼,如果条件成立了,则执行下一步。否则继续等待,直到超过设置的最长时间,然后抛出TimeoutException。
显示等待必须在每个需要等待的元素前面进行声明
参数说明:
- driver:浏览器驱动
- timeout:等待时间
- poll_frequency:检测的间隔时间,默认0.5s
- ignored_exceptions:超时后的异常信息,默认抛出NoSuchElementException
打开b站鬼畜区示例
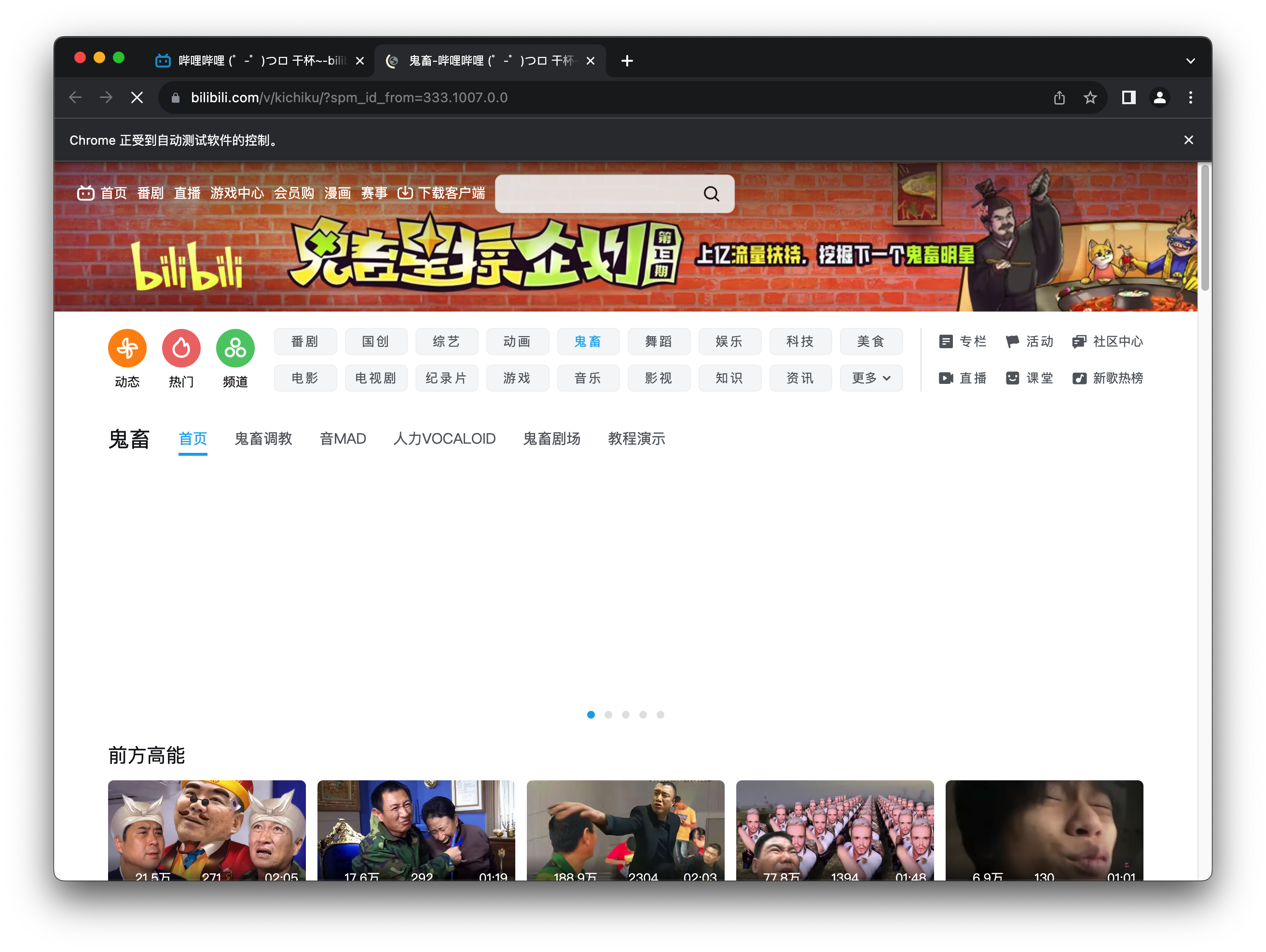
显示等待常用方法
__EOF__

本文链接:https://www.cnblogs.com/goldsunshine/p/17632487.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理