Flask中本地栈的使用

1|04种上下文变量
承接上一篇内容。当一个请求到来时,除了request被封装成全局变量之外,还有三个变量也是同样被封装成全局变量,那就是current_app、g、session。上面4个变量之所以能够使用,是因为程序上下文生效了。
上下文这个概念非常常见,比如在进程切换时时会保存当前进程的上下文,恢复活动进程的上下文。我见过对上下文对通透的解释就是说所谓上下文就是运行环境,恢复上下文就是恢复运行环境。
在Flask中有两种上下文:程序上下文和请求上下文。当一个请求到来时,Flask会激活这两种上下文,其中request就是在请求上下文中获取。
| 变量名 | 上下文 | 说明 |
|---|---|---|
| current_app | 应用上下文 | 当前激活程序的程序实例 |
| g | 应用上下文 | 处理请求时用作临时存储的对象。每次请求都会重设这个变量 |
| request | 请求上下文 | 请求对象,封装了客户端发出的HTTP请求中的内容 |
| session | 请求上下文 | 用户会话,用于存储请求之间需要“记住”的字典 |
1|1上下文在请求中的生命周期
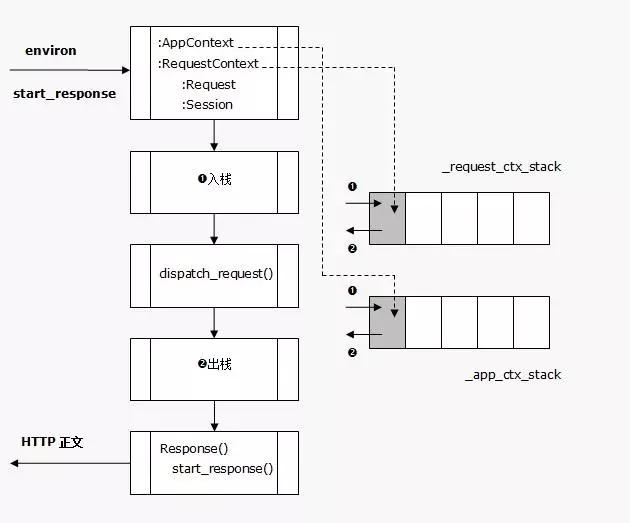
Flask在分发请求之前将程序上下文(AppContext)压入应用本地栈中,将请求上下文(RequestContext)压入请求本地栈中。请求处理完成后再将两个上下文分别出栈。
程序上下文被入栈后,就可以在视图函数中使用current_app和g变量;类似的,请求上下文被推送后,就可以使用request和session变量。
具体来说:请求上下文保存在_request_ctx_stack,程序上下文保存在 _app_ctx_stack。当一个请求到来时,请求上下文对象RequestContext,程序上下文对象AppContext都会相应入栈。
1|2Flask经典错误
如果我们没有激活程序上下文或请求上下文就使用这些变量会导致一个Flask的经典错误。
RuntimeError: Working outside of application context.
比如:
在上面的示例中打印current_app的名字,但是并没有在视图函数中,也就是说没有请求到来。那么这一段程序就会报错:
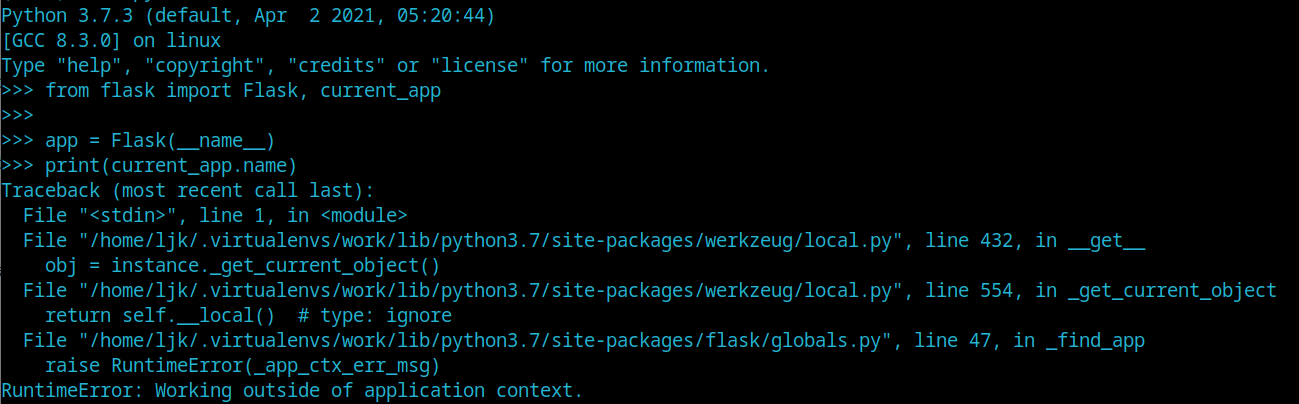
这就是因为current_app必须是要在请求到来时,请求上下文和程序上下文都激活之后才能使用。上面一段代码没有请求到来,所以current_app不能使用。
1|3手动压栈程序上下文
为了能够在没有请求到来也能使用Flask项目的配置,文件等,可以手动将程序上下文入栈。
1|4请求上下文和程序上下文为什么要分开
在flask0.1中请求上下文和程序上下文是在同一个栈中保存,为什么后面分离开来?
是为了非 web 应用的场合。所谓非web应用场合就是没有请求到来时,也需要使用程序上下文的场景,典型代表就是flask shell。在处理一些数据库导入,脚本等场景时没有网络请求到来,也就没有请求上下文和程序上下文。所以current_app不可使用,如配置信息、orm数据库等都不可使用。为了能够在没有请求到来的场景下使用程序上下文,所以将程序上下文和请求上下文分开,然后使用手动入栈程序上下文的方式来方便的使用flask提供的功能。也就是上面分析的手动入栈。
2|0为什么用栈来保存上下文对象
学到这里时我其实有一个疑问,为什么请求上下文对象和程序上下文对象要用本地栈来保存呢?用本地线程不可以吗?
网上给出的解释是flask通过中间件同时处理两个app的程序,两个app的请求会同时存在,用本地栈能够让各自请求找到自己的数据。但是根据flask的服务端模型,同一时间,一个线程只处理一个请求,根本不会有多个请求同时被处理的情况,用本地线程也可以保存上下文,那么到底什么原因让flask用本地栈这种数据结构呢?
2|1Flask 处理模型
首先说明flask的服务处理模型
flask 有两种启动模式,分别是单线程和多线程。单线程启动就是请求只在一个线程中处理,当上一个请求没有返回,下一个请求需要等待;多线程请求中每一个请求到来不会被阻塞,会有多个线程提供处理。默认是多线程
单进程
多进程
但是不管是多进程启动还是单进程启动,同一个线程同一个时刻只会处理一个请求, 又因为本地线程技术(上一篇有介绍本地线程技术Flask中请求数据的优雅传递)也就是说同一个时刻只有一个request对象,那么为什么flask保存request对象时使用的是本地栈而不是本地线程呢?
这个问题的答案是:当程序上下文手动入栈时,可以入栈多个程序上下文。这样会同时存在多个程序上下文,为了获取正确的程序上下文,需要使用栈这种先进后出的结构。
如果没有明白原因没关系,可以从下面的程序中找到解释。
同时在Flask中程序上下文入栈之后打印了调试信息

当app1入栈后,_app_ctx_stack中只有一个元素,就是app1,这时访问current_app就是app1;
当app2入栈后,_app_ctx_stack中有两个元素,且栈顶是app2。这时访问current_app就是app2;
当app2出栈后,_app_ctx_stack中剩余一个元素,就是app1,这时再访问current_app就是app1。
正是通过这种栈数据结构,让处理函数都是获取自己程序上下文中的current_app。
3|0小结
程序上下文和请求上下文都是保存在本地栈中,因为手动入栈时存在多个上下文环境嵌套,所以需要栈这样的数据结构保持最新的上下文在最先获得。
__EOF__

本文链接:https://www.cnblogs.com/goldsunshine/p/15890861.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理