Python高性能工具迭代标准库itertools

itertools是python内置的标准模块,提供了很多简洁又高效的专用功能,使用得当能够极大的简化代码行数,同时所有方法都是实现了生成器函数,这就意味着极大的节省内存。
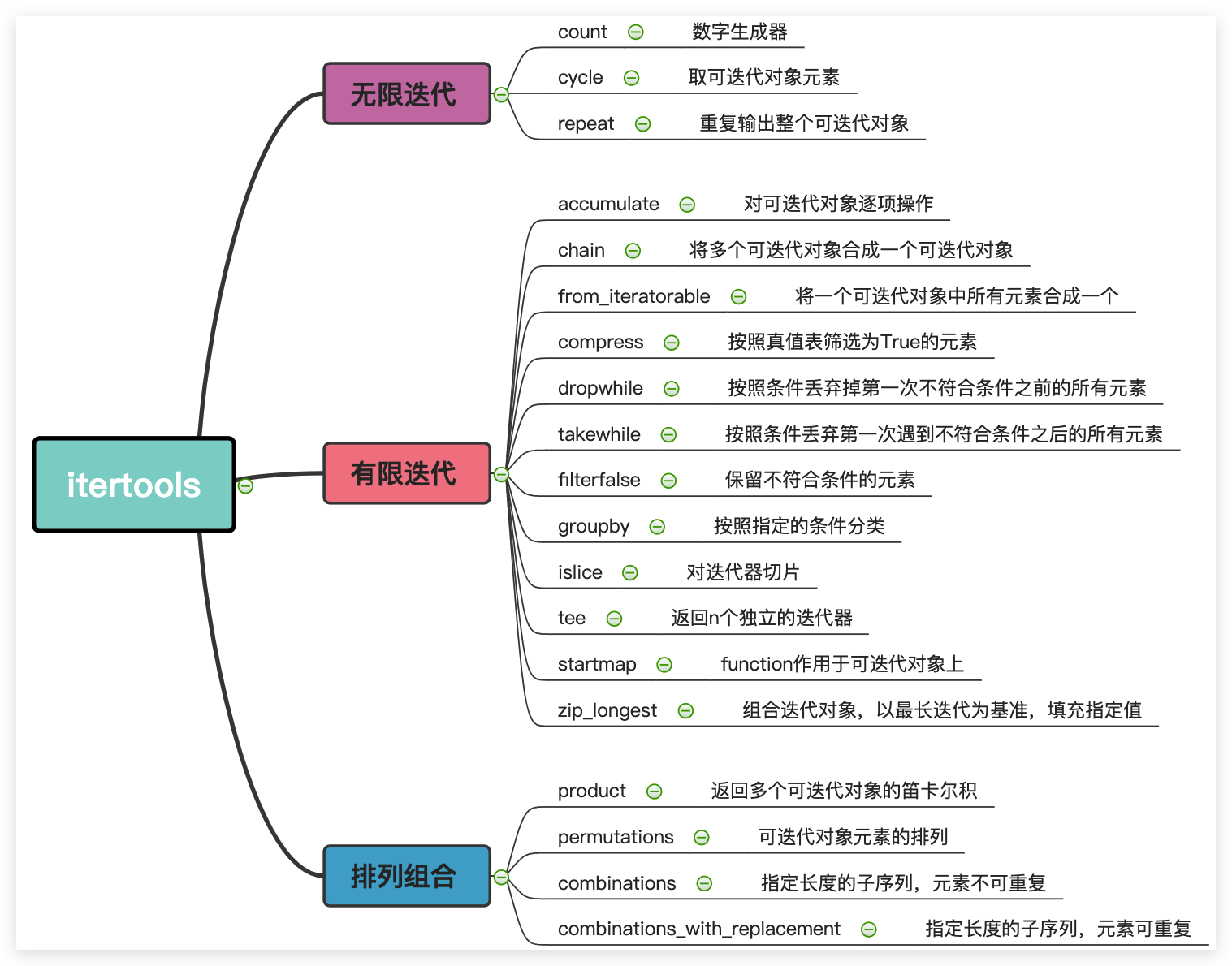
itertools提供的功能主要分为三大块,以最新版本的3.10为例:
- 对可迭代对象无限迭代,无限输出
- 对可迭代对象有限迭代
- 对可迭代对象排列组合
方法如下:
导入包
1|0无限迭代
iteratortools.count(start=0, step=1)
数值生成器,可以指定起始位置和步长,并且步长可以为浮点数。无限输出,一直累加,在例子中需要边睡眠1s边输出。
iteratortools.cycle(iteratorable)
无限循环取出可迭代对象里的元素
iteratortools.repeat(object[, times])
不断重复输出整个object,如果指定了重复次数,则输出指定次数,否则将无限重复。
2|0有限迭代
2|1accumulate
iteratortools.accumulate(iteratorable[, func, *, initial=None])
返回对列表中元素逐项的操作,操作有:
- 累加,返回累加到每一项的列表
- 累乘,返回累乘到每一项的列表
- 最小值,返回到当前项的最小值
- 最大值,返回到当前项的最大值
2|2chain
iteratortools.chain(*iteratorables)
将多个可迭代对象构建成一个新的可迭代对象,统一返回。类似于将多个对象链成一条串
优点:可以将多个可迭代对象整合成一个,避免逐个取值
2|3from_iteratorable
chain.from_iteratorable(iteratorable)
将一个迭代对象中将所有元素类似于chain一样,统一返回。
2|4compress
iteratortools.compress(data, selectors)
按照真值表筛选元素
2|5dropwhile
iteratortools.dropwhile(predicate, iteratorable)
按照条件筛选,丢弃掉第一次不符合条件时之前的所有元素
2|6takewhile
iteratortools.takewhile(predicate, iteratorable)
根据predicate条件筛选可迭代对象中的元素,只要元素为真就返回,第一次遇到不符合的条件就退出。
按照条件筛选,丢弃第一次遇到不符合条件之后的元素。行为类似于上一个dropwhile,区别在于丢弃的选择不同。
例如:输出符合条件的数据,遇到不符合的数据就退出
常规使用方法:
takewhile的使用方法
takewhile可以有效减少if条件判断。
2|7filterfalse
iteratortools.filterfalse(predicate, iteratorable)
保留不符合条件的元素,返回迭代器
2|8groupby
iteratortools.groupby(iteratorable, key=None)
按照指定的条件分类。输出条件和符合条件的元素。
groupby时传入的数组是否有序很关键,对于有序的数组,groupby之后会产生两个记录,如[1,2,3,4,5,6]按照大于4区分,得到的就是
如果列表是无序的,如[1,3,5,2,4,6],那么得到的就是
2|9islice
iteratortools.islice(iteratorable, start, stop[, step])
对迭代器进行切片,老版本中不能指定start和stop以及步长,新版本可以。
2|10starmap
iteratortools.starmap(function, iteratorable)
将function作用于可迭代对象上,类似于map函数
2|11tee
iteratortools.tee(iteratorable, n=2)
从一个可迭代对象中返回 n 个独立的迭代器
2|12zip_longest
iteratortools.zip_longest(*iteratorables, fillvalue=None)
创建一个迭代器,从每个可迭代对象中收集元素。如果可迭代对象的长度未对齐,将根据 fillvalue 填充缺失值。
迭代持续到耗光最长的可迭代对象。大致相当于:
3|0排列组合迭代
iteratortools.product(*iteratorables, repeat=1)
生成多个可迭代对象的笛卡尔积
大致相当于生成器表达式中的嵌套循环。例如, product(A, B) 和 ((x,y) for x in A for y in B) 返回结果一样。
将可选参数 repeat 设定为要重复的次数。例如,product(A, repeat=4) 和 product(A, A, A, A) 是一样的
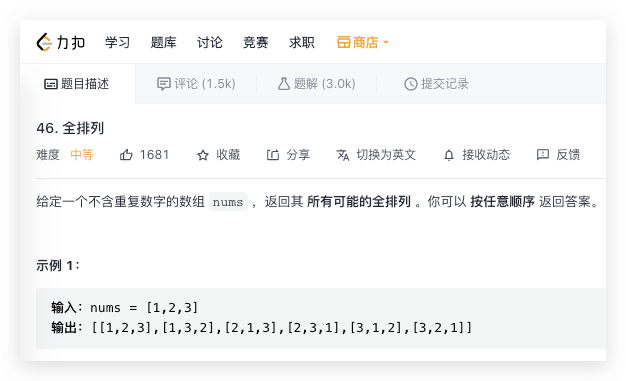
iteratortools.permutations(iteratorable, r=None)
由 iteratorable 元素生成长度为 r 的排列。元素的排列,类似于给一个[1,2,3],选取其中两个元素,一共有多少种组合方法?不要求元素排列之后的位置。
这个方法能够完美解决算法中的全排列问题,简直是量身定做。如果早知道这么简单,当年考算法也不会。。,哎
可参见leetcode46题:https://leetcode-cn.com/problems/permutations/
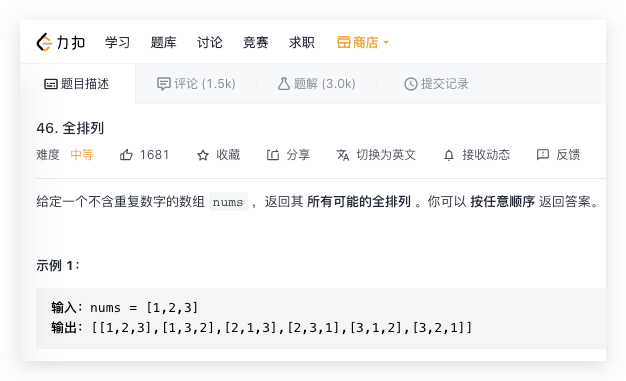
iteratortools.combinations(iteratorable, r)
返回由输入 iteratorable 中元素组成长度为 r 的子序列。元素不可重复使用。子序列是要求元素在排列之后和之前的相对位置不变的。1,2,3中3在1的后面,子序列中3也一定在1的后面。
这个方法可以曲线解决组合总数问题
https://leetcode-cn.com/problems/combination-sum/
iteratortools.combinations_with_replacement(iteratorable, r)
返回由输入 iteratorable 中元素组成的长度为 r 的子序列,允许每个元素可重复出现
4|0小结
以上方法并不是每一个都能见到,但至少在项目开发过程中遇到过 chain、 takewhile、groupby、islice。能够用上这些方法,既能减少代码量,又能提高效率,同时也能让人编码方法更高级。
__EOF__

本文链接:https://www.cnblogs.com/goldsunshine/p/15678828.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理