用python讲解数据结构之树的遍历

1|0树的结构
树(tree)是一种抽象数据类型或是实现这种抽象数据类型的数据结构,用来模拟具有树状结构性质的数据集合
它具有以下的特点:
①每个节点有零个或多个子节点;
②没有父节点的节点称为根节点;
③每一个非根节点有且只有一个父节点;
④除了根节点外,每个子节点可以分为多个不相交的子树;
2|0树的分类
2|1二叉树
二叉树:每个节点最多含有两个子树的树称为二叉树。
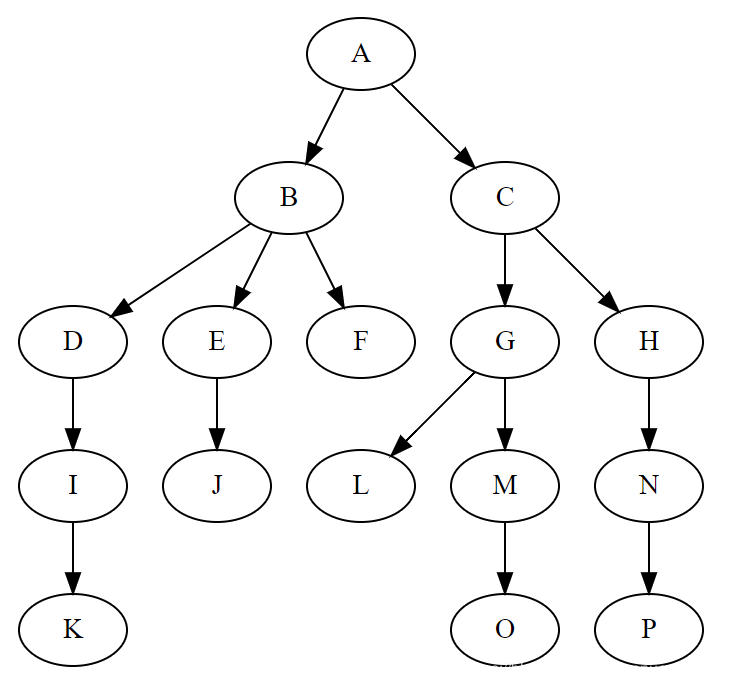
二叉树中一些专业术语:
- 父节点:A节点就是B节点的父节点,B节点是A节点的子节点
- 兄弟节点:B、C这两个节点的父节点是同一个节点,所以他们互称为兄弟节点
- 根节点:A节点没有父节点,我们把没有父节点的节点叫做根节点
- 叶子节点:图中的H、I、J、K、L节点没有子节点,我们把没有子节点的节点叫做叶子节点
节点的高度:节点到叶子结点的最长路径,比如C节点的高度是2(L->F是1,F->C是2)节点的深度:节点到根节点的所经历的边的个数比如C节点的高度是1(A->C,只有一条边,所以深度=1)节点的层:节点的高度树的高度:根节点的高度
基于二叉树衍生的多种树型结构:
2|2满二叉树
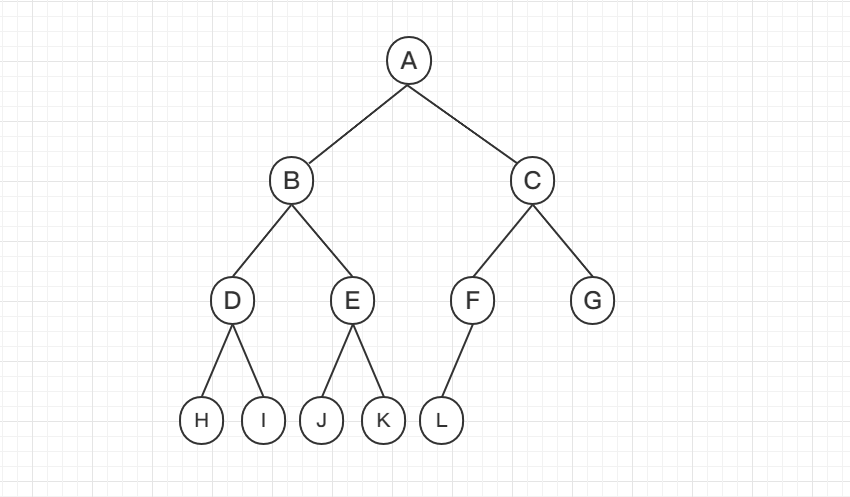
满二叉树:除最后一层无任何子节点外,每一层上的所有结点都有两个子结点。也可以这样理解,除叶子结点外的所有结点均有两个子结点。节点数达到最大值,所有叶子结点必须在同一层上

2|3完全二叉树
完全二叉树:设二叉树的深度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第h 层所有的结点都连续集中在最左边,这就是完全二叉树
满二叉树和完全二叉树对比:

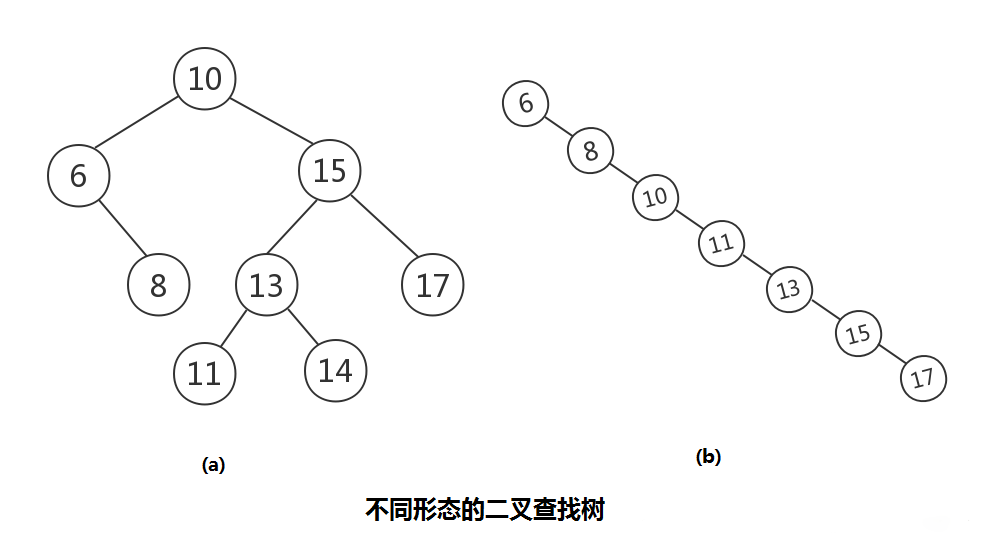
2|4二叉查找树
二叉查找树: 也称二叉搜索树,或二叉排序树。其定义也比较简单,要么是一颗空树,要么就是具有如下性质的二叉树:
(1)若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
(2) 若任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
(3) 任意节点的左、右子树也分别为二叉查找树;
(4) 没有键值相等的节点。
2|5平衡二叉树
定义: 平衡二叉搜索树,又被称为AVL树,且具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树
平衡二叉树出现原因:
由于普通的二叉查找树会容易失去”平衡“,极端情况下,二叉查找树会退化成线性的链表,导致插入和查找的复杂度下降到 O(n) ,所以,这也是平衡二叉树设计的初衷。那么平衡二叉树如何保持”平衡“呢?根据定义,有两个重点,一是左右两子树的高度差的绝对值不能超过1,二是左右两子树也是一颗平衡二叉树。
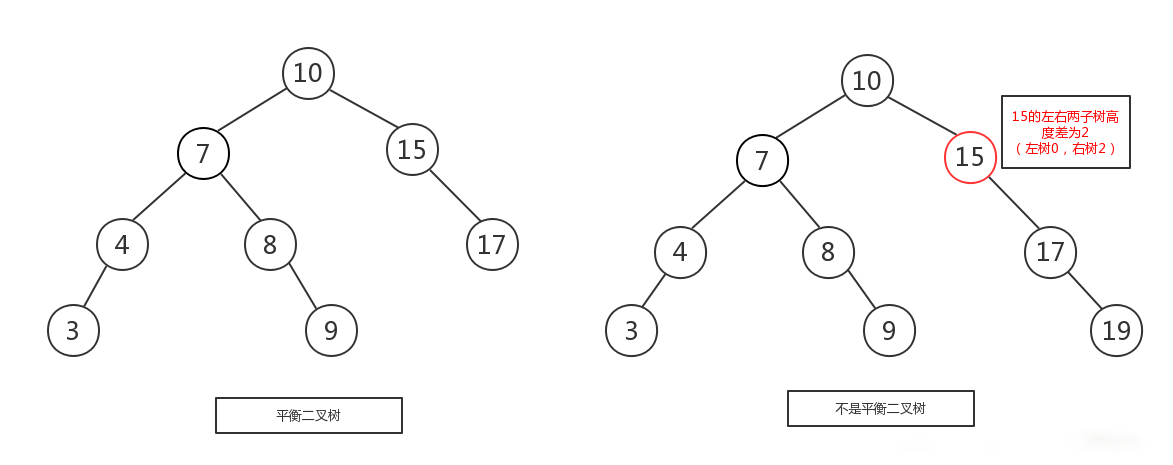
平衡二叉树的创建:
平衡二叉树是一棵高度平衡的二叉查找树。所以,要构建跟维系一棵平衡二叉树就比普通的二叉树要复杂的多。在构建一棵平衡二叉树的过程中,当有新的节点要插入时,检查是否因插入后而破坏了树的平衡,如果是,则需要做旋转去改变树的结构
2|6红黑树
avl树每次插入删除会进行大量的平衡度计算导致IO数量巨大而影响性能。所以出现了红黑树。一种二叉查找树,但在每个节点增加一个存储位表示节点的颜色,可以是红或黑(非红即黑)

定义:
- 每个节点非红即黑;
- 根节点是黑的;
- 每个叶节点(叶节点即树尾端NULL指针或NULL节点)都是黑的;
- 如图所示,如果一个节点是红的,那么它的两儿子都是黑的;
- 对于任意节点而言,其到叶子点树NULL指针的每条路径都包含相同数目的黑节点;
- 每条路径都包含相同的黑节点;
红黑树有两个重要性质:
1、红节点的孩子节点不能是红节点;
2、从根到叶子节点的任意一条路径上的黑节点数目一样多。
这两条性质确保该树的高度为logN,所以是平衡树。
优势:
红黑树的查询性能略微逊色于AVL树,因为他比avl树会稍微不平衡最多一层,也就是说红黑树的查询性能只比相同内容的avl树最多多一次比较,但是,红黑树在插入和删除上完爆avl树,avl树每次插入删除会进行大量的平衡度计算,而红黑树为了维持红黑性质所做的红黑变换和旋转的开销,相较于avl树为了维持平衡的开销要小得多
使用场景:
- 广泛用于C ++的STL中,地图和集都是用红黑树实现的;
- 着名的Linux的的进程调度完全公平调度程序,用红黑树管理进程控制块,进程的虚拟内存区域都存储在一颗红黑树上,每个虚拟地址区域都对应红黑树的一个节点,左指针指向相邻的地址虚拟存储区域,右指针指向相邻的高地址虚拟地址空间;
- IO多路复用的epoll的的的实现采用红黑树组织管理的的的sockfd,以支持快速的增删改查;
- Nginx的的的中用红黑树管理定时器,因为红黑树是有序的,可以很快的得到距离当前最小的定时器;
- Java的的的中TreeMap中的中的实现;
2|7B树
定义:
B树是为实现高效的磁盘存取而设计的多叉平衡搜索树。(B树和B-tree这两个是同一种树)
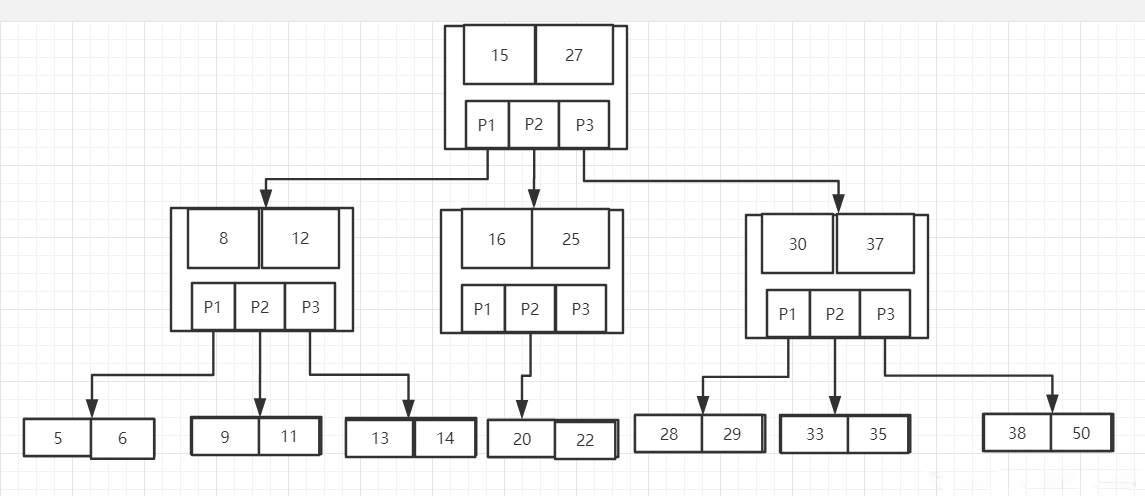
产生原因:
B树是一种查找树,我们知道,这一类树(比如二叉查找树,红黑树等等)最初生成的目的都是为了解决某种系统中,查找效率低的问题。
B树也是如此,它最初启发于二叉查找树,二叉查找树的特点是每个非叶节点都只有两个孩子节点。然而这种做法会导致当数据量非常大时,二叉查找树的深度过深,搜索算法自根节点向下搜索时,需要访问的节点也就变的相当多。
如果这些节点存储在外存储器中,每访问一个节点,相当于就是进行了一次I/O操作,随着树高度的增加,频繁的I/O操作一定会降低查询的效率。
定义:
B树是一种平衡的多分树,通常我们说m阶的B树,它必须满足如下条件:
- 每个节点最多只有m个子节点。
- 每个非叶子节点(除了根)具有至少⌈ m/2⌉子节点。
- 如果根不是叶节点,则根至少有两个子节点。
- 具有k个子节点的非叶节点包含k -1个键。
所有叶子都出现在同一水平,没有任何信息(高度一致)。
特点:
- 关键字集合分布在整棵树中;
- 多路,非二叉树
- 每个节点既保存索引,又保存数据
- 搜索时相当于二分查找
2|8B+树
B+树是应文件系统所需而产生的B树的变形树
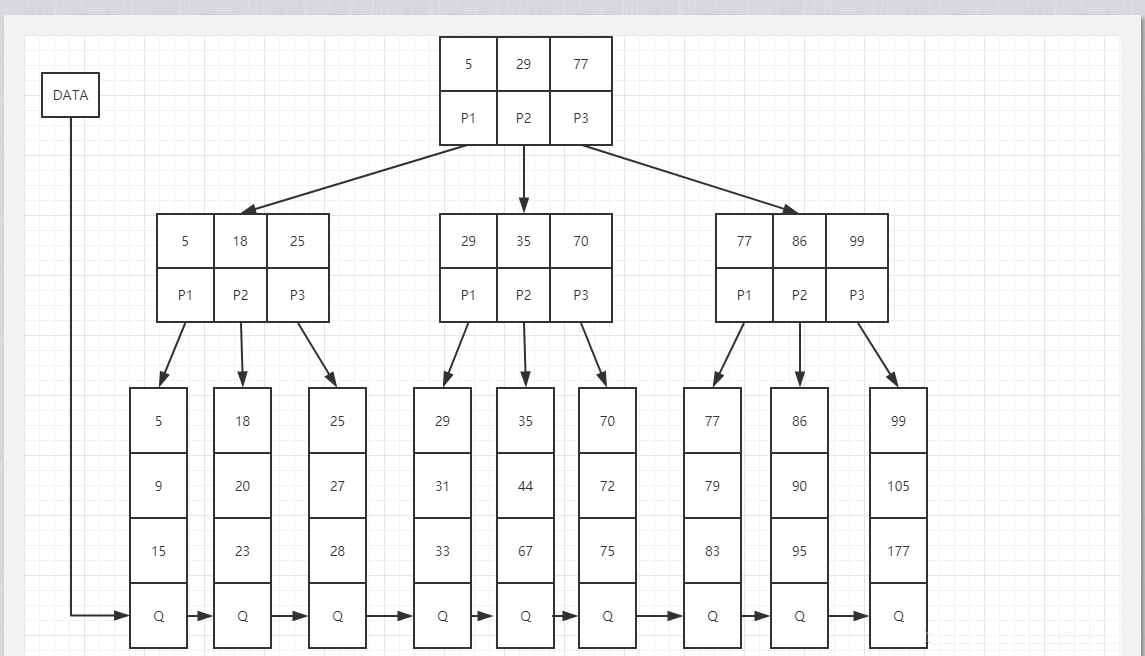
B+树有两种类型的节点:内部结点(也称索引结点)和叶子结点。内部节点就是非叶子节点,内部节点不存储数据,只存储索引,数据都存储在叶子节点。
内部结点中的key都按照从小到大的顺序排列,对于内部结点中的一个key,左树中的所有key都小于它,右子树中的key都大于等于它。叶子结点中的记录也按照key的大小排列。
每个叶子结点都存有相邻叶子结点的指针,叶子结点本身依关键字的大小自小而大顺序链接
父节点存有右孩子的第一个元素的索引。
最核心的特点如下:
(1)多路非二叉
(2)只有叶子节点保存数据
(3)搜索时相当于二分查找
(4)增加了相邻接点的指向指针
B+树为什么时候做数据库索引:由于B+树的数据都存储在叶子结点中,分支结点均为索引,方便扫库,只需要扫一遍叶子结点即可,但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫。简单来说就是:B+树查询某一个数据时扫描叶子节点即可;而B树需要中序遍历整个树,所以B+树更快。
为什么说B+树比B树更适合数据库索引?
1)B+树的磁盘读写代价更低
B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了;
2)B+树查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当;
3)B+树便于范围查询(最重要的原因,范围查找是数据库的常态)
B树在提高了IO性能的同时并没有解决元素遍历效率低下的问题,正是为了解决这个问题,B+树应用而生。B+树只需要去遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作或者说效率太低;
B树的范围查找用的是中序遍历,而B+树用的是在链表上遍历;
3|0树的创建
树的创建有很多种方式,分为迭代创建和递归创建。下面分别介绍这两种创建数的方式。
3|1迭代创建
创建的树:
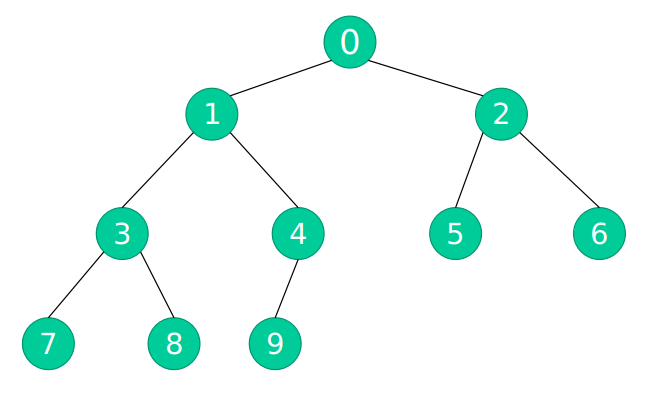
该创建方法是按照层次创建,第一层创建好之后第二层,第二层完成后创建第三层。在程序中使用了一个队列用来存放下一步创建的树节点的数值。
3|2递归创建
该创建方式是递归创建,前提是将树的数据组织成一个完全二叉树的形式。如果使用数组来存储一个完全二叉树或者满二叉树的话,那么父子节点之间有一个规律:
父节点的下标为x,那么左子树的下标为2x+1,右子树的下标为2x+2。
|||||||||||
|-|-|-|-|-|-|-|-|-|-|-|-|
|0|1|2|3|4|5|6|7|8|9|
根节点的下标:0 ,其左子树为 2*0+1 = 1, 右子树为2*0+2 = 2。递归创建正是使用了这个规律来完成数组到树的转化。
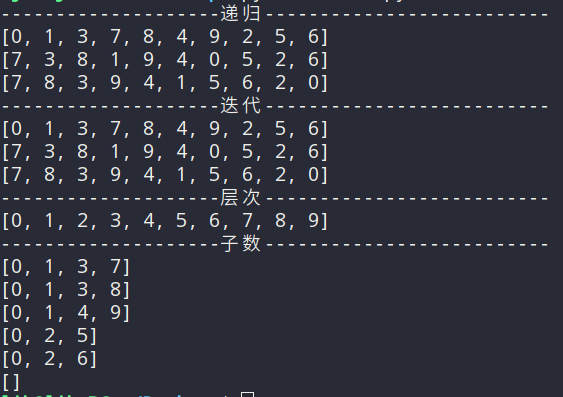
4|0树的遍历
树的遍历方式有很多种,可以分为五类:
- 前序遍历
- 中序遍历
- 后序遍历
- 层次遍历
- 子树遍历
实现遍历的方式中又可以分为递归和迭代
__EOF__

本文链接:https://www.cnblogs.com/goldsunshine/p/13943608.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理