python 正则表达式简单使用
定义:
正则表达式,又称规则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个"规则字符串",这个"规则字符串"用来表达对字符串的一种过滤逻辑。
功能:
给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
- 匹配 给定的字符串是否符合正则表达式的过滤逻辑
- 过滤 通过正则表达式,从文本字符串中获取我们想要的特定部分
原理:
1|0单字符匹配
1.最简单匹配:匹配指定字符
所有的字符都可以匹配自身如 abc 能够匹配 abc
2. . 匹配换行'\n'之外所有字符
在这个例子中,字符串中看似符合标准的有两个:attc,axc,因为.代表一切字符,所有能够匹配a[]c,又因为.只代表数量上匹配一位,所以只能匹配axc
3.给定范围匹配
使用[],在里面写入需要匹配的字符,作用是在字符串中匹配写入的字符,能够匹配任意一个即可
a[gx]c可以匹配以a开头c结尾,中间一位是g或者x的字符串。在string中有两位,agc和axc,使用findall可以将符合条件的都查找出来。
4.匹配特殊字符
在2中使用.可以匹配除\n外所有的字符串,但如果想要匹配.本身呢?如匹配一个qq号12345@qq.com,youdao@163.com,找到是哪一家公司的。\可以让特殊符号变成原来的意思。
通配符匹配
字符的类型有很多,字符,数字,点,空格,tab等。对类型复杂的字符,正则表达式提供了多种匹配方式。
\d 能够匹配0-9的数字
匹配到了string中所有的数字,使用pattern = re.compile('[0-9]')可以达到同样的效果
\s 匹配 空格\t\r\n\f\v
\s 的效果同样可以使用pattern = re.compile([ \t\y\n\f\v])替换。
还有一些方便的匹配字符集,所有的字符集都可以使用[]这种方式实现
\D 匹配非数字 [^\d] \S 匹配非空白字符 [^\s] \w 匹配单词字符 [A-Za-z0-9_] \W 匹配非单词字符 [^\w]
2|0多字符匹配
前面所有的匹配都是只能匹配一个字符,往往在工作中需要配多个字符。如23gbhtrev56匹配23和56之间所有的字符。这时不知道是一个字符还是多个字符。所以需要使用数量上的匹配来实现。
0~无限次
*表示匹配无限个字符,包括0个。使用方式:a*代表a可以匹配0-无限次
.代表所有字符,.*表示匹配所有字符0~无数次
1~无限次
+和*用法相似,唯一不同的是+能够1~无数次,即一定要有一次出现。
string1中ab和cd之间没有数字,所以没有匹配到,而string2中ab和cd之间有12345,所有能够匹配到。这就是+的能力。如果使用*则可以都匹配到。
指定次数
除了匹配无数次这种不确定的次数外,也可以使用{m}匹配指定次数。使用{m}可以匹配一个字符m次。如a{4}这个意思就是匹配字符4次,只有类似xaaaa3244这种出现4次a的字符串才会被匹配到。
同样使用{m,n}可以匹配 小于n次,大于m次的字符。
3|0边界匹配
边界匹配简化了一些匹配表达的填写,这些都可以使用基础表达式完成。
1.匹配以XXX字符开头的字符串
使用^abc可以匹配以abc开头的字符串
匹配以xxx字符结尾的字符串
使用$xyz可以匹配以xyz结尾的字符串
匹配以字符串开头
匹配以字符串结尾
4|0逻辑分组
分组就是用一对圆括号“()”括起来的正则表达式,匹配出的内容就表示一个分组。分组的匹配结果可以通过group()获取。规则是:
res.group(): 默认分组结果,整个表达式的匹配结果
res.group(0): 整个表达式的匹配结果,等同于res.group()
res.group(1): 第一个分组的匹配结果,即()中匹配的内容。
| 匹配左右任意一个表达式
|代表左右表达式任意匹配一个,先尝试匹配左边的表达式,一旦成功则跳过匹配右边的表达式。如abc|xyz
在使用|时最好用括号包裹匹配条件(abc|xyz),如果没有包裹它的匹配范围是整个正则表达式。
小场景:匹配出邮箱的公司名在qq,163和gmail三者之中。 格式:邮箱的公司名都要跟在@符号后面
匹配文件的格式,是否属于docx,pdf,doc中的某一种。
(ab) 将括号中的字符作为一个分组
使用()分组可以将()中表达式匹配的值取出来。
小场景:提取html标签中的内容。在做网页爬虫时,比如某网页HTML中有这样的内容:<h1>content</h1>。如何把把<h1>content</h1>中的content提取出来?
提取的内容用()括起来就可以了。<h1> </h1>是固定标签,这是不变的,变的是content。可以这样写: r'<h1>(.*)</h1>'。匹配解释是匹配<h1></h1>这样的字符串,分组中匹配任意字符串0次~无数次
注意:以上分组的匹配写法是贪婪模式,python匹配默认为贪婪模式,但在项目中使用非贪婪模式更多,毕竟要更准确。如果想改成非贪婪模式,可以写成这样:r'<h1>(.*?)</h1>'。更多详情参见文末贪婪匹配。
分组的进阶使用技巧还有如下:
- \num 引用分组num匹配到的字符串
- (?P<name>) 分组起别名
- (?P=name) 引用别名为name分组匹配到的字符串
可参考:https://blog.csdn.net/m0_37673307/article/details/81607986
5|0匹配范围规则
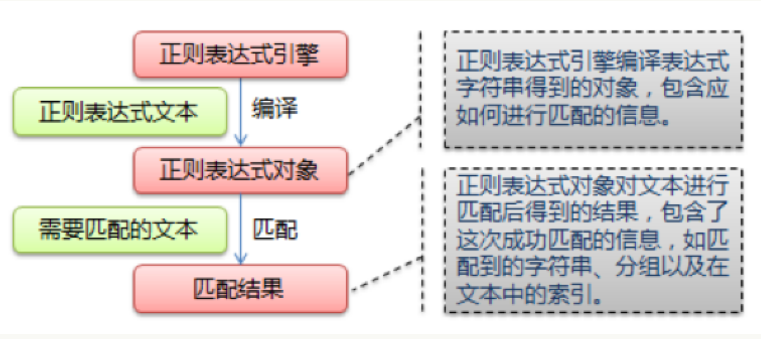
re模块的一般使用步骤如下:
1.使用compile()函数将正则表达式的字符串形式编译为一个Pattern对象
2.通过Pattern对象提供的一系列方法对文本进行匹配查找,获得匹配结果,一个Match对象。
3.最后使用Match 对象提供的属性和方法获得信息,根据需要进行其他的操作
compile 函数
compile 函数用于编译正则表达式,生成一个 Pattern 对象,它的一般使用形式如下:
在上面,我们已将一个正则表达式编译成Pattern对象,接下来,我们就可以利用pattern的一系列方法对文本进行匹配查找了。
Pattern 对象的一些常用方法主要有:
- match 方法:从起始位置开始查找,一次匹配
- search 方法:从任何位置开始查找,一次匹配
- findall 方法:全部匹配,返回列表
- finditer 方法:全部匹配,返回迭代器
- split 方法:分割字符串,返回列表
- sub 方法:替换
match方法
match 方法用于查找字符串的头部(也可以指定起始位置),它是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果。
在上面,当匹配成功时返回一个Match对象,其中:
-
group() 方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用 group() 或 group(0);
-
start() 方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0;
-
end() 方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0;
-
span() 方法返回 (start(group), end(group))。
search方法
search 方法用于查找字符串的任何位置,它也是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果。
findall 方法
上面的 match 和 search 方法都是一次匹配,只要找到了一个匹配的结果就返回。然而,在大多数时候,我们需要搜索整个字符串,获得所有匹配的结果。
findall 以列表形式返回全部能匹配的子串,如果没有匹配,则返回一个空列表。
sub 方法
sub 方法用于替换。它的使用形式如下:
使用repl替换string中匹配到的字符
小场景:将字符串中所有数字替换成*号
去除html中的标签。
小场景:去除html标签,获得标签内容。`<h1>博客园让分享更easy</h1>` 去掉标签`<h1>` 和`</h1>`。
可以通过`r<[^>]+>`来实现。r'<>'表示匹配两个尖括号,`[^>]+`表示尖括号中内容不是>,并且内容可以有多个,即多个非>符号。
通过findall方法可以看出能够找到所有的标签,而sub则是用空字符串替换标签,所有最后得到的就是一个去掉标签的字符串。
5|1贪婪模式与非贪婪模式
- 贪婪模式:在整个表达式匹配成功的前提下,尽可能多的匹配 ( * );
- 非贪婪模式:在整个表达式匹配成功的前提下,尽可能少的匹配 ( ? );
- Python里数量词默认是贪婪的。
示例一 : 源字符串:abbbc
-
使用贪婪的数量词的正则表达式
ab*,匹配结果:abbb。
决定了尽可能多匹配 b,所以a后面所有的 b 都出现了。 -
使用非贪婪的数量词的正则表达式
ab*?,匹配结果:a。
即使前面有 *,但是 ? 决定了尽可能少匹配 b,所以没有 b。
示例二 : 源字符串:aa<div>test1</div>bb<div>test2</div>cc
使用贪婪的数量词的正则表达式:<div>.*</div>
匹配结果:<div>test1</div>bb<div>test2</div>
这里采用的是贪婪模式。在匹配到第一个""时已经可以使整个表达式匹配成功,但是由于采用的是贪婪模式,所以仍然要向右尝试匹配,查看是否还有更长的可以成功匹配的子串。匹配到第二个""后,向右再没有可以成功匹配的子串,匹配结束,匹配结果为<div>test1</div>bb<div>test2</div>
使用非贪婪的数量词的正则表达式:<div>.*?</div>
匹配结果:<div>test1</div>
正则表达式二采用的是非贪婪模式,在匹配到第一个""时使整个表达式匹配成功,由于采用的是非贪婪模式,所以结束匹配,不再向右尝试,匹配结果为<div>test1</div>。
非贪婪模式在匹配html结构化数据时非常有效,可以将最小html结构匹配出来
爬取网站,并使用正则匹配完成html解析
最后写入到文本中的内容
__EOF__

本文链接:https://www.cnblogs.com/goldsunshine/p/12218859.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理