经典排序 python实现
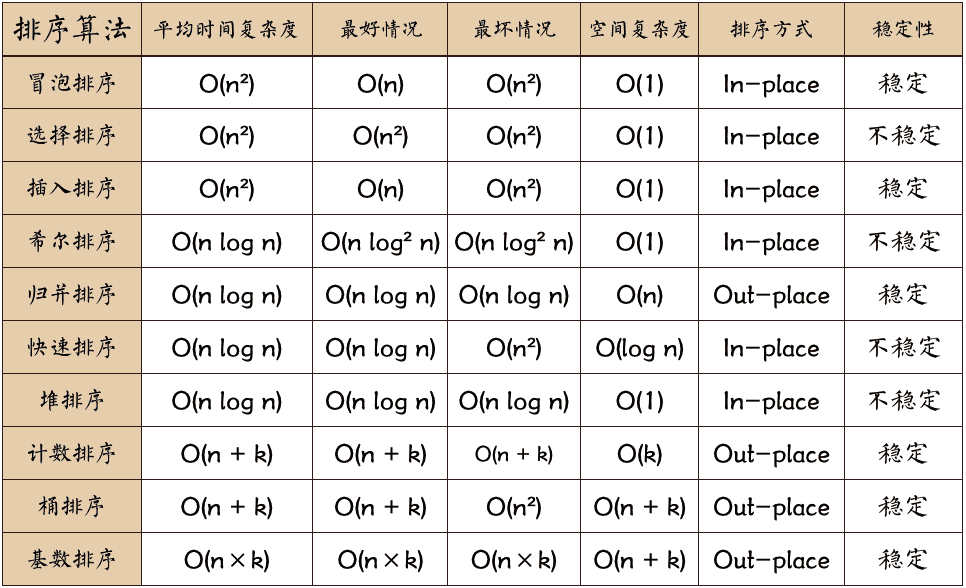
稳定的排序算法:冒泡排序、插入排序、归并排序和基数排序。 不是稳定的排序算法:选择排序、快速排序、希尔排序、堆排序。
1|0冒泡
2|0选择
选择排序的思想是将序列分为有序和无序两个部分,不断从无序序列中选择最小的增加到有序序列中,这样,序列就从小到大排列整齐。
3|0插入排序
插入排序原理是将当前元素与前面的元素比较,如果小于则不断移动前面的元素向后,直到大于前面的某一个元素。
1.使用一个变量保存当前元素
2.使用变量不断与前面的元素比较,如果小于前面的变量则移动被比较的元素向后,直到变量大于某一个元素则停止
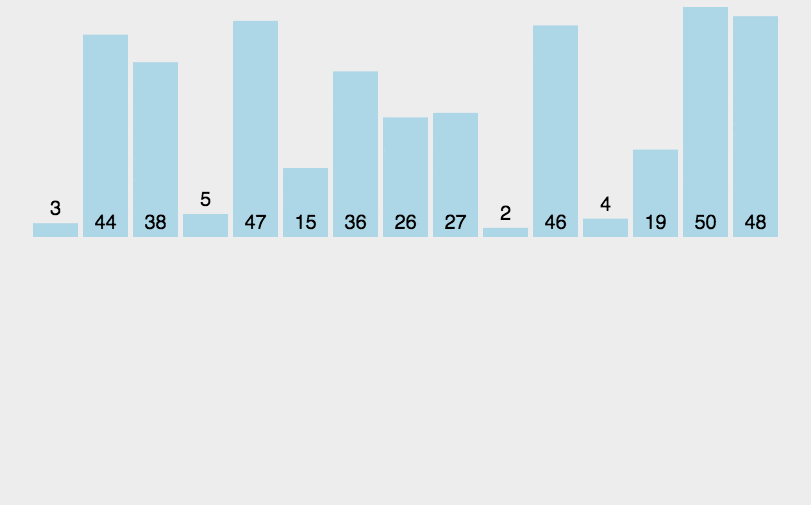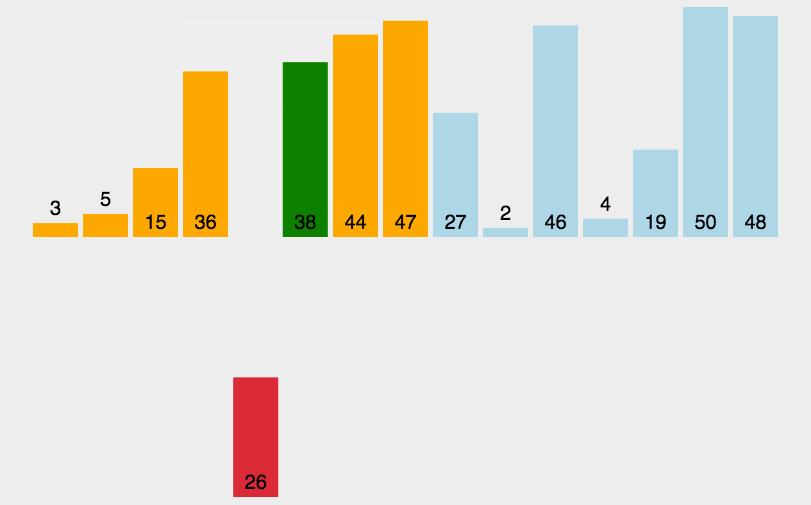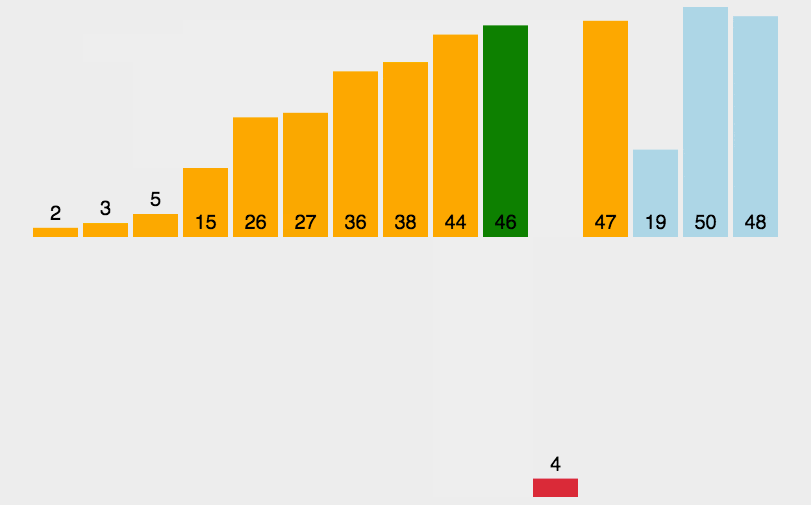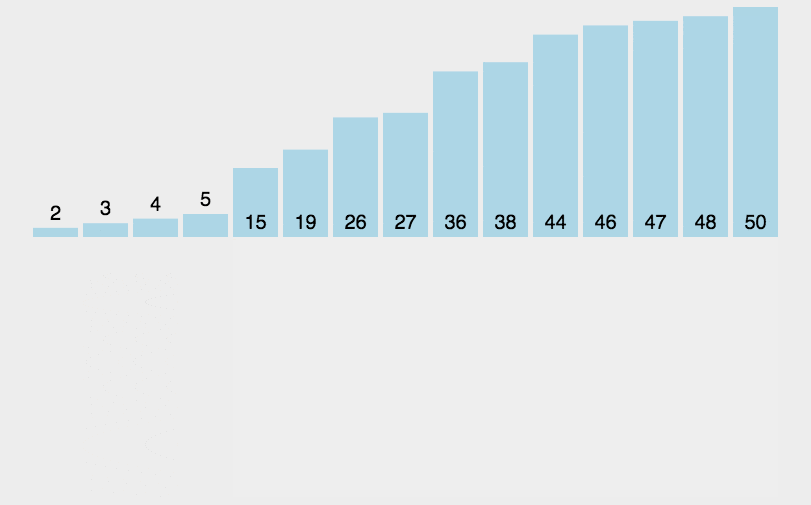
4|0希尔排序
因为插入排序效率在集合大体有序时比较高,所有希尔的思想就是将数组先大体排序程成有序的状态。
gap是增量,使用增量将整体数组分割成若干小数组,先对小数组排序。直到gap=1,就变成了插入排序。
gap既是增量,又是大数组分割成小数组的数量。
希尔排序是插入排序的改进版,其改进之处在于希尔排序的最后一次排序就是插入排序,而在之前希尔排序将集合大致排序程有序的序列。
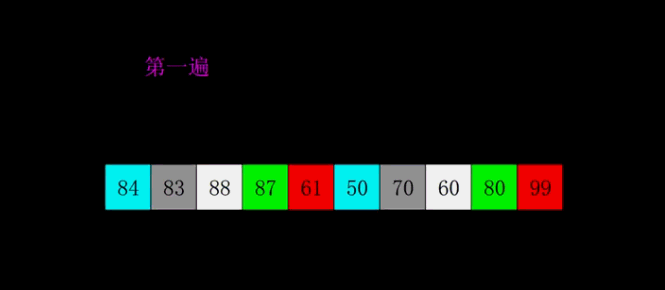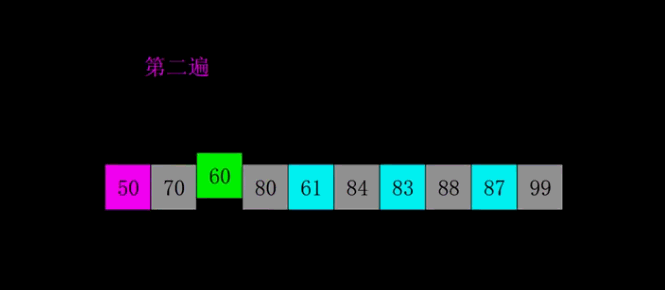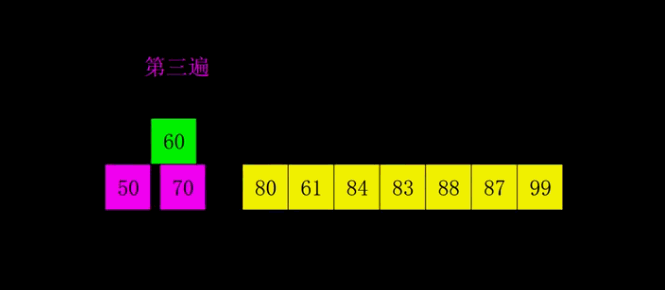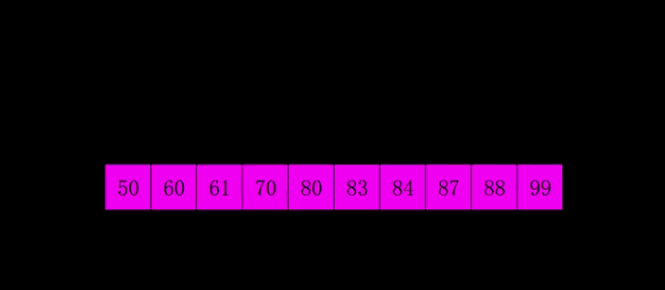
5|0快速排序
https://www.cnblogs.com/morewindows/archive/2011/08/13/2137415.html
快速排序的是思想是从序列中找一个元素作为基准,将所有小于基准的元素都排在前面,所有大于基准的元素都排在后面。此时序列就被分成两个部分,然后重复该过程,直到所有的序列都有序为止。
以上的思想是排序的思想,实际的代码思想应该用挖坑填坑,分而治之。
双循环法
单循环法
快速排序的核心思想是根据一个基准,将列表分成大于和小于两部分。
双循环方法是通过挖坑填坑的方式,根据基准分为大于和小于部分。而单循环法,使用了一个mark来维护小于基准的边界,以第一个元素为基准,循环后面的,有小于基准的元素,mark加1,然后交换mark和i的元素。mark始终都在小于基准元素的边界。最后将left和mark交换,将基准放在边界,完成大于和小于的分类。
6|0归并排序
https://www.cnblogs.com/piperck/p/6030122.html
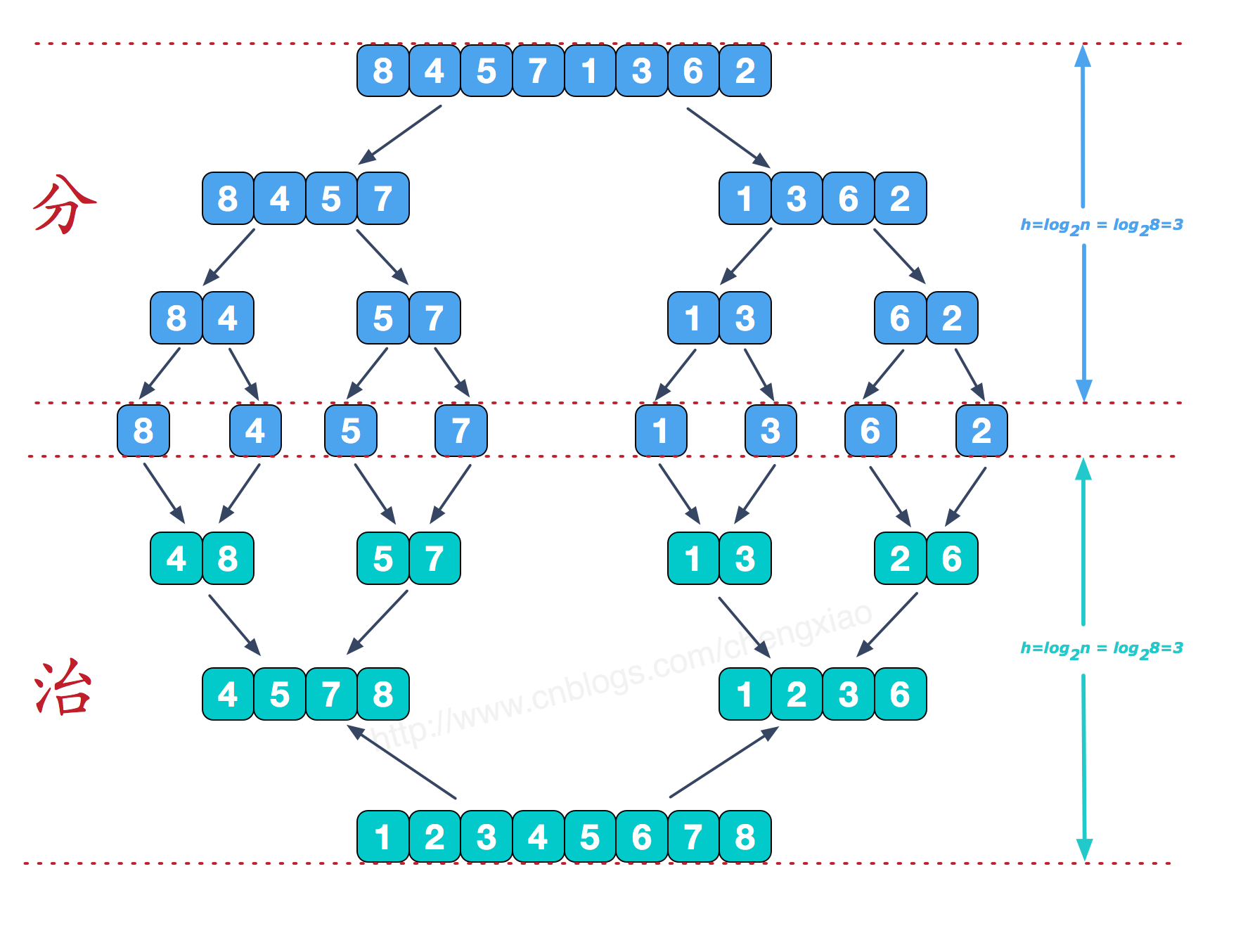
归并排序思想:先并开,后归拢。将一个序列中所有元素都分开,然后从单个元素开始两两合并,将两个有序序列合并成一个新的序列。
7|0计数排序
http://www.sohu.com/a/258222713_684445
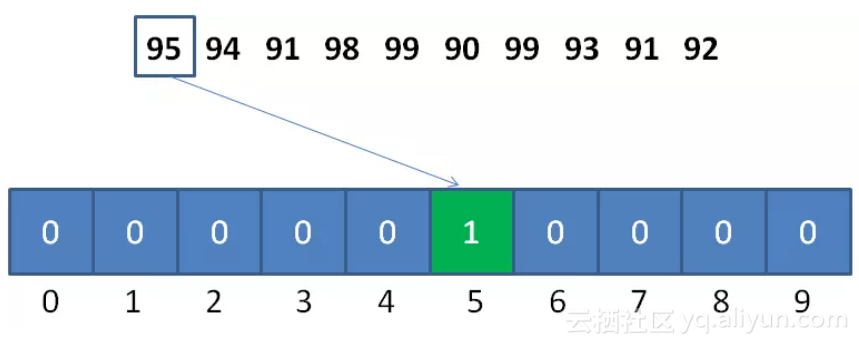
计数排序是一个种外排序,需要一个数组的辅助。排序思想是:
1.首先求出待排序的集合中的最大值
2.然后根据最大值建立max+1个元素的列表
3.将待排序元素的值和列表的下标一一对应,有元素的值就在列表对应的下标的元素加1
4.所有元素对应完成,此时列表就表示排好序的集合,顺序输出即可
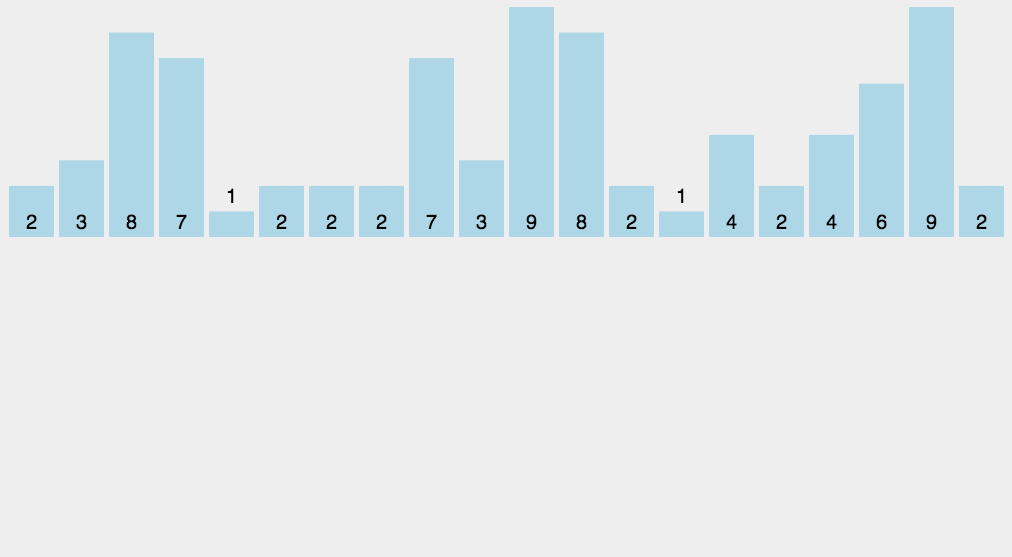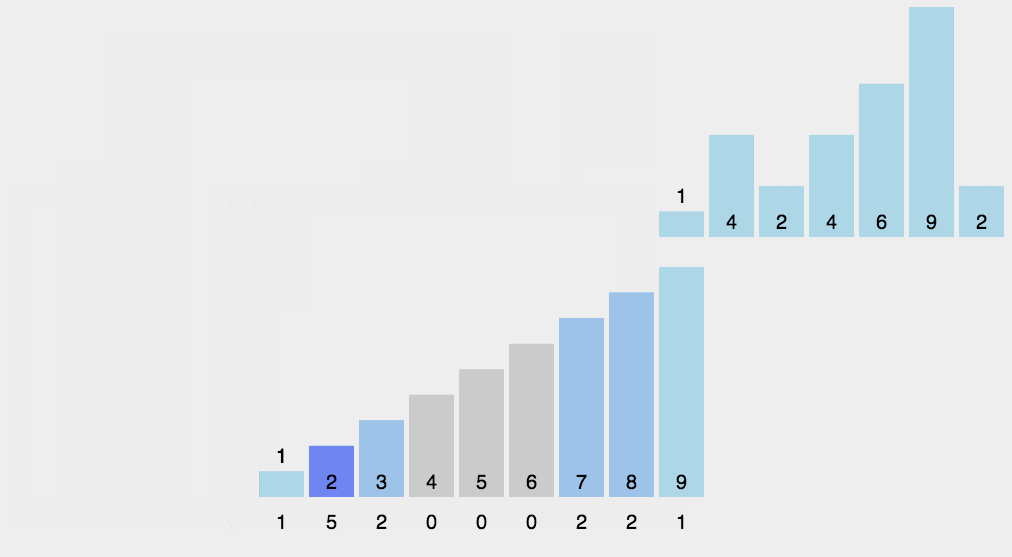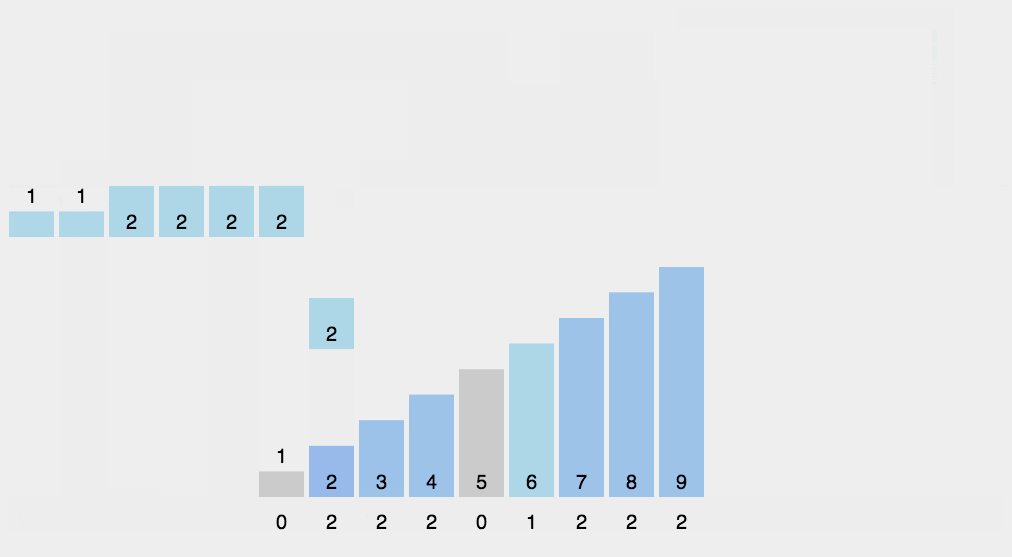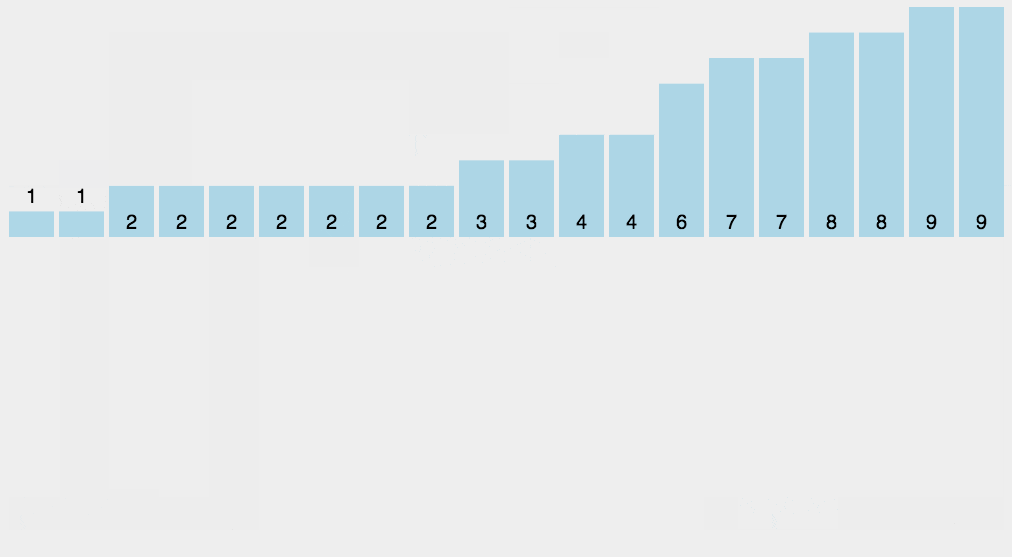
8|0桶排
https://yq.aliyun.com/articles/652774
桶排序是计数排序的优化版。计数排序的思想是构建一个列表,其长度是待排序集合的最大值+1。这样当集合过大时,资源浪费。
通排序是用一个列表当做一个桶,代表一个取值范围。节省了创建的列表的数量。排序思想:
1.首先找出最大值,根据最大值确定桶的数量
2.将所有的元素放入对应的桶中
3.对每个桶进行快速排序,结束后桶内有序,并且所有的桶组合在一def quick( l = lef r = right
9|0基数排序
https://cuijiahua.com/blog/2018/01/algorithm_8.html
基数排序的思想比较有创意,按照每一个元素的位排序。先按照个位将集合排序,然后再用十位将上次排好的集合再排序,直到最高位的元素都排好。
1.找出最大的位数
2.循环取出每个元素的个位,按照个位的值放入一个0~9的桶中
3.循环上一个过程,位数不断变高
4.最后输出即一个有序的集合

10|0堆排
https://www.jianshu.com/p/938789fde325
堆排序又叫做二叉堆排序
二叉堆是一种完全二叉树,它的类型分为两种:
1. 最大堆
2. 最小堆
最大堆:任何一个父节点,都大于或等于它左孩子和右孩子节点的值
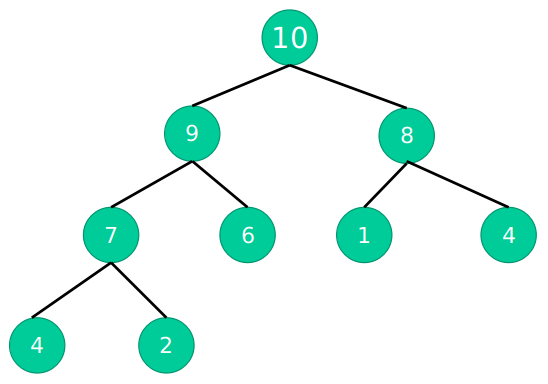
最小堆:任何一个父节点,都小于或等于它左孩子和右孩子节点的值
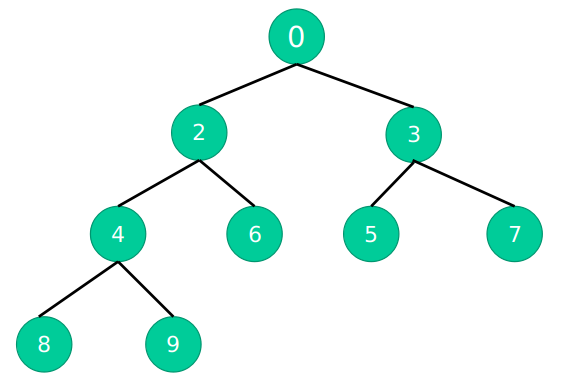
堆排序有两个步骤:
1. 将一个无序的数组排列成有序的堆
2. 不断将堆顶节点和最后一个节点互换,然后平衡二叉堆
__EOF__

本文链接:https://www.cnblogs.com/goldsunshine/p/11181461.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理