SQLALlchemy数据查询小集合
SQLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作。将对象转换成SQL,然后使用数据API执行SQL并获取执行结果。在写项目的过程中,常常要使用SQLAlchemy操作数据库,同事前期教我很多东西,感谢之余写一篇文章记录使用过的技术,做到心里有数,手上有活。
在开发过程中涉及到的内容:
- 联表查询(外键加持)
- 联表查询(无外键)
- and 多条件与查询
- or 多条件或查询
- in 包含查询
- offset&limit 切片查询
相关查询操作还有:
- ~ 取反操作
- is_ 空值判断
- between
- like 模糊查询
最后补充:
- 查询数据类型判断
- 多表连接方式(全连接,外连接,内连接)
1|0准备工作
1.sqlalchmey开发环境的搭建
2.安装mysql数据库
3.创建数据库mydb
创建数据库时一定要加上数据的编码方式,否则无法存入中文。
4.下载mysql的python驱动
2|0创建模型和数据
创建表结构
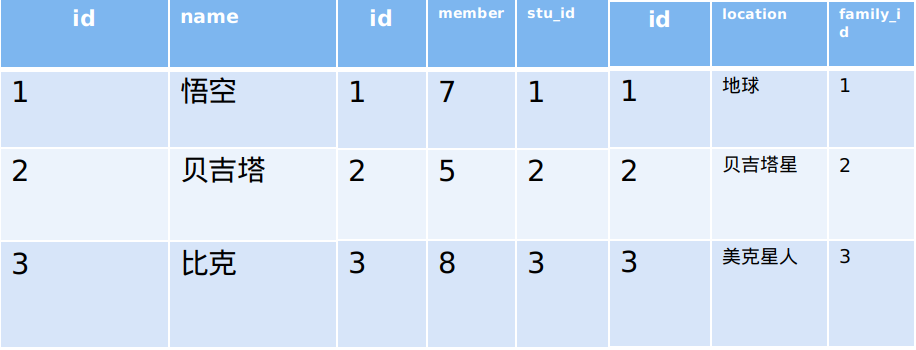
定义四张表:Student,Family,House,Car。关系如下:
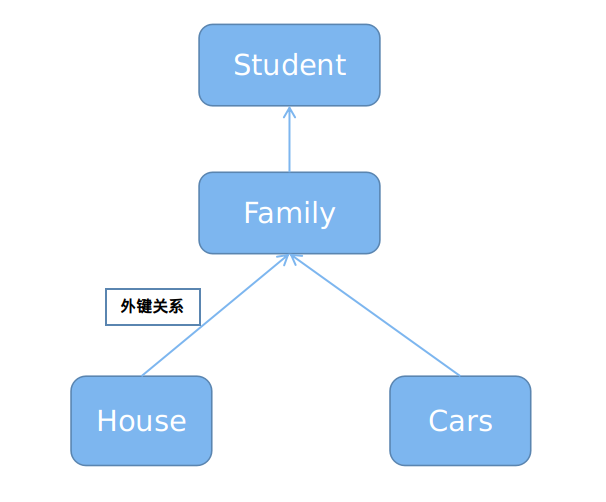
代码创建过程:
创建了四张表,写入了多条数据。
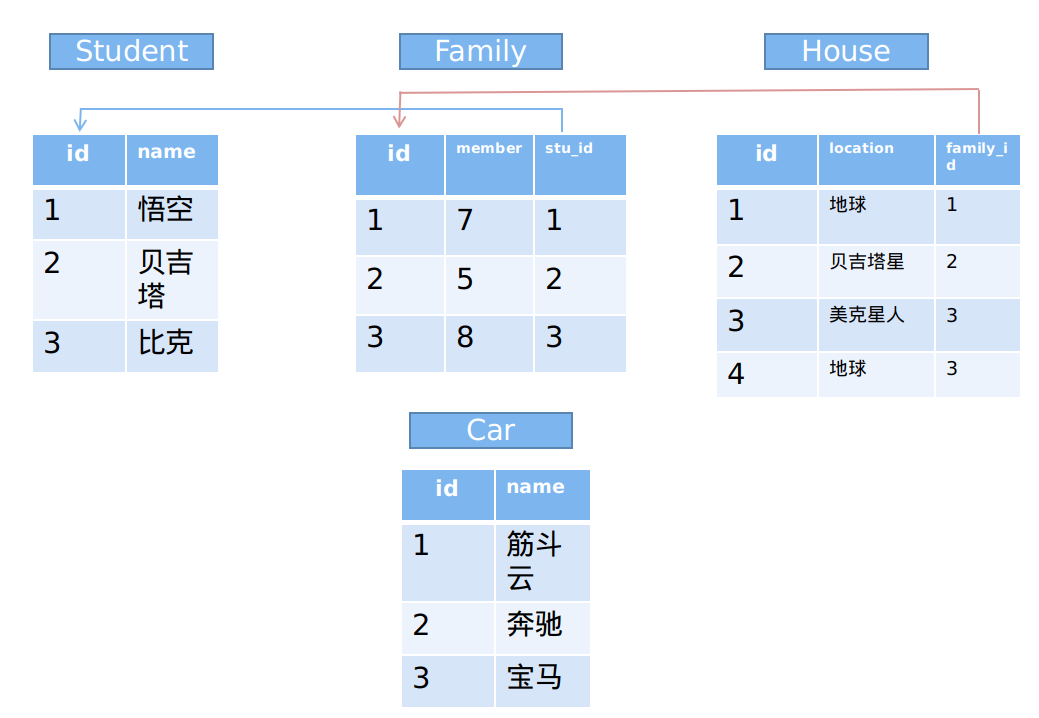
3|0查询
首先来一波基础查询,了解各个表的数据。
student表
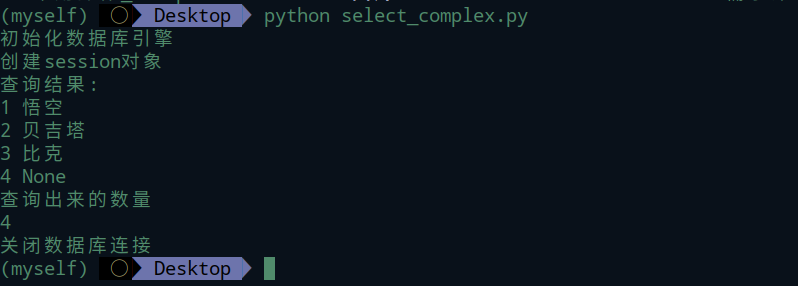
Family表
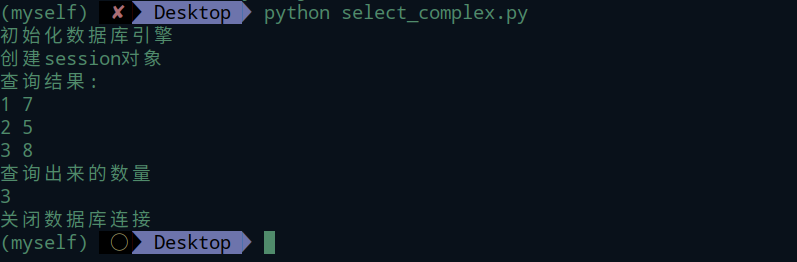
House表
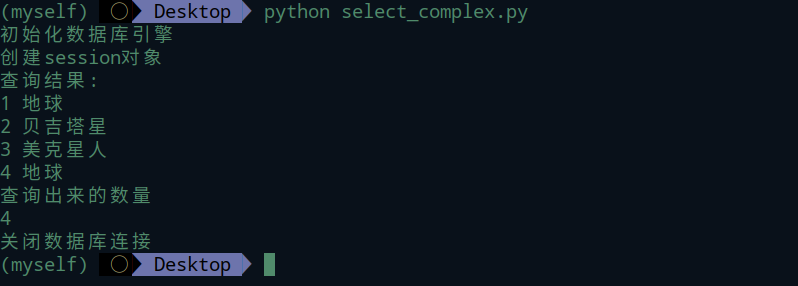
Car表
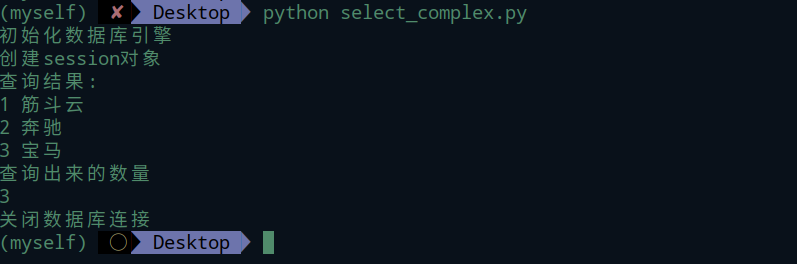
查询操作
查询子句使用session的.query()方法来获取Query查询对象。
查询对象能够使用一些方法来对应一些查询子句,比如.order_by(),.limit(),.filter()等,高级的查询后面会专门讲。
查询对象有这么几种方法.one(),.all(),.scalar(),.one_or_none(),.get(),以及.first()等。
下面对这几个方法的用法及效果做简单解释。
.all()
返回查询到的所有的结果。
这个方法比较危险的地方是,如果数据量大且没有使用limit子句限制的话,所有的结果都会加载到内存中。
它返回的是一个列表,如果查询不到任何结果,返回的是空列表。
.first()
返回查询到的第一个结果,如果没有查询到结果,返回None。
.scalar()
这个方法与.one_or_none()的效果一样。
如果查询到很多结果,抛出sqlalchemy.orm.exc.MultipleResultsFound异常。
如果只有一个结果,返回它,没有结果返回None。
.one()
如果只能查询到一个结果,返回它,否则抛出异常。
没有结果时抛sqlalchemy.orm.exc.NoResultFound,有超过一个结果时抛sqlalchemy.orm.exc.MultipleResultsFound。
.one_or_none()
比起.one()来,区别只是查询不到任何结果时不再抛出异常而是返回None。
.get()
这是个比较特殊的方法。它用于根据主键来返回查询结果,因此它有个参数就是要查询的对象的主键。
如果没有该主键的结果返回None,否则返回这个结果。
两张表连表查询
查询Student表,限制条件是Family表中的member字段。Family表外键关联到Student表,查询Family中member 大于6的Student表数据。即家庭成员大于6人的学生表。
1 | result = session.query(Student).join(Family).filter(Family.member>6) |
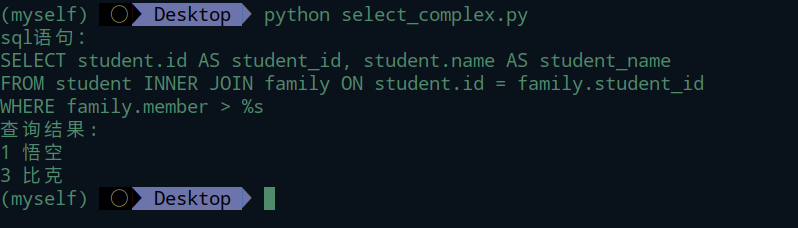
两张表连表查询使用了join关键字。 将Family表添加到Student表中,通过外键关联到一起。通过打印的查询sql语句可以看出,sqlalchemy的join使用的是'INNER JOIN',即内连接方式。可以说,内连接方式是sqlalchemy的默认连接方式。
三张表连表查询
查询Student表,限制的条件是House表中的location字段。

查询语句使用了两次join,student表连接了family和house。底层的sql查询语句同样使用了INNER JOIN方式。目前三张表的连接方式如下所示:
无外键加持的连表查询
没有外检关联时,使用join关键字连表查询。
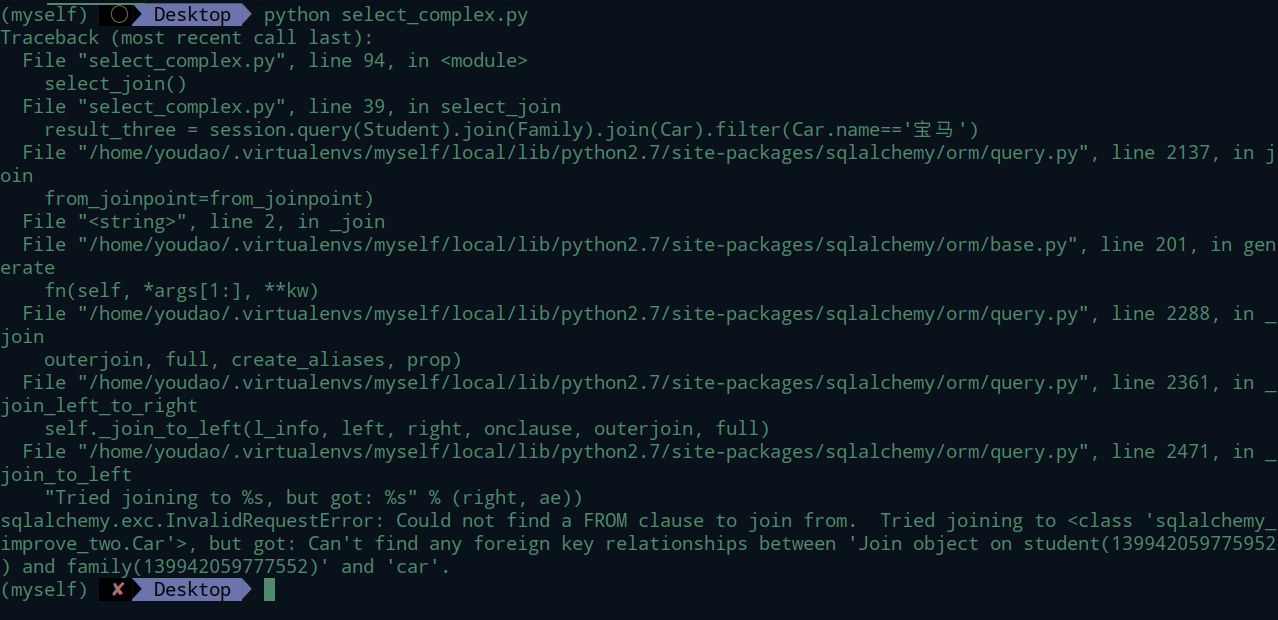
从报错信息来看,找不到外键关联。这里Car表没有和其他表做外键关联,所有这里找不到关联关系。
无外键的join连表查询
如果建表时使用了外键关联,那么可以直接使用join关键字连接数据库查询。如果没有外键关联,也可以连表查询,只需要指明外键关系即可。
还是上面的查询语句,指明关联字段 Car.family_id==Family.id 。

这样就可以完成连表查询。
or操作
or操作常用于满足多个条件中的一个条件情况下,例如下面一调语句是指满足location是地球,或者member=7的条件。只要这两种条件其中一种满足即可。

and操作
和or相反的,and是所有的条件必须要满足。上面的例子是指同时满足location是地球,member等于7的条件。所有or有两个结果,and就只有一个结果。

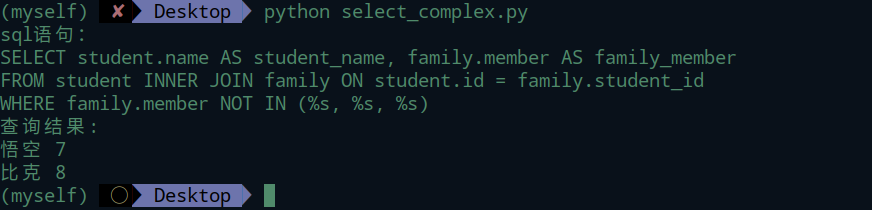
in操作
in操作是一个很方便的操作。如果没有in的话,可以用or同样来完成,但是效率会低,代码也不够简洁。如in_((4,5,6))等价于or_(Family.member == 4,Family.member==5,Family.member==6)。数量多的情况下in操作是效率很高的操作。
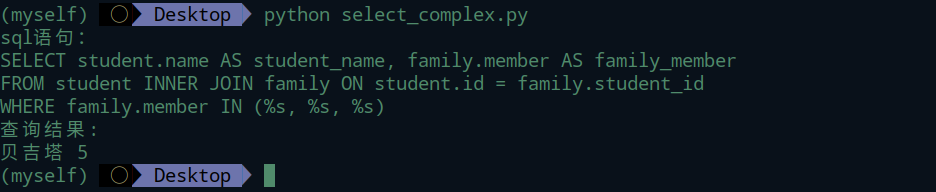
offset & limit切片操作
之所以将offset和limit放在一起来将,是因为这两位常常是一起出现的。对的,你猜的不错,就是前台分页是使用。抛开后台分页工具,如果熟练使用offset和limit,自己完全可以写一个后台分页器。
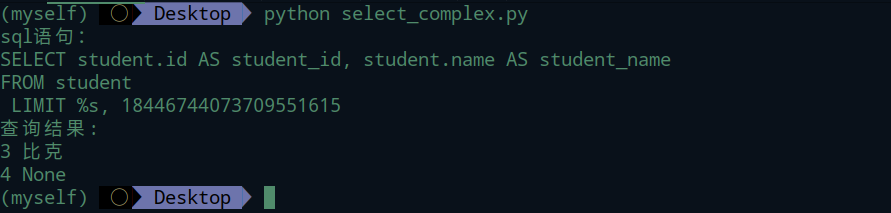

~ 取反操作
between
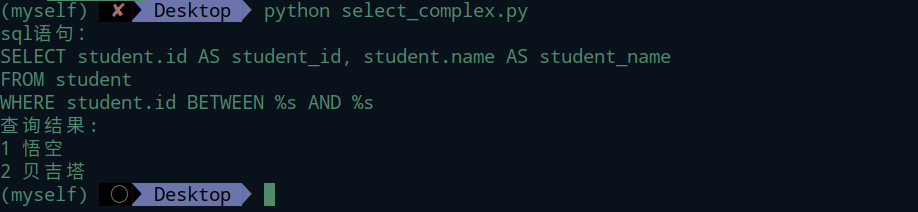
like 统配
like的参数有两种写法,分别是带%s和不带。使用%来做通配符,带%表示模糊查询;不带表示精确查询
模糊查询
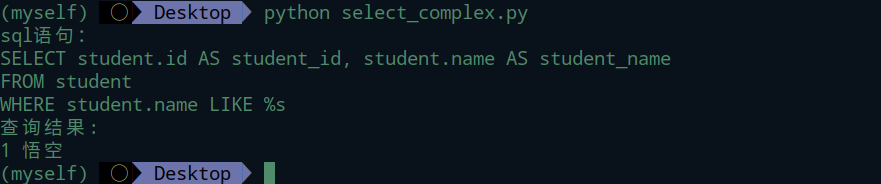
精确查询

is空值判断

查询结果类型分析
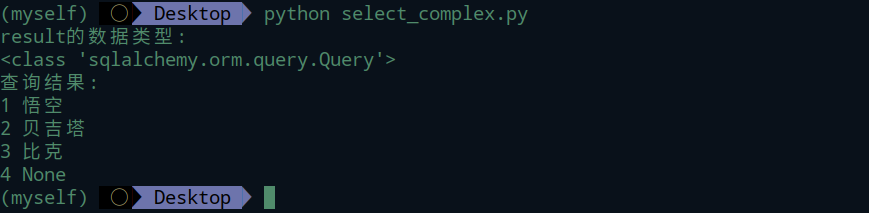
query查询出来的是对象。对象可以继续filter过滤,也可以all取出所有。
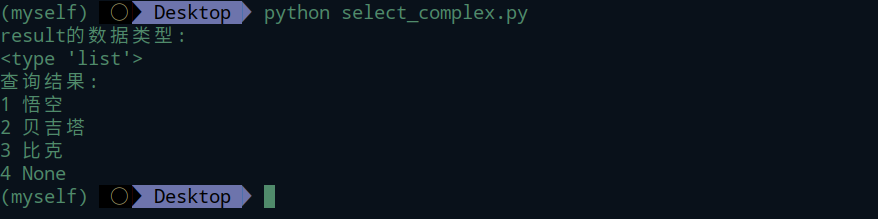
all()方法查询出来的是列表。一定要主意在列表是空值的情况下使用取值或者别的操作会造成报错。

filter查询出来的是对象。对象支持链式操作,一个filter后面可以继续增加多个filter操作。
4|0连接方式
SQLAlchemy 内,外,左,右,全连接
在连表查询时,从打印出来的sql语句可以看出join是使用了内连接的方式来完成的。内连接的连接方式如下,查询两张表中相同的部分。
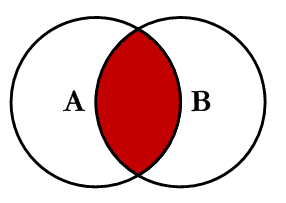
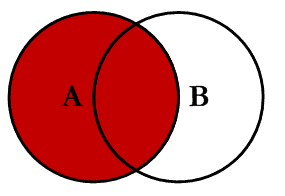
外链接,也叫左连接。以左边的表为主表,右边的表为副表,将主表中需要的字段全部列出,然后将副表中的数据按照查询条件与其对应起来。使用关键字outerjoin
SQL 原生查询:
Left Join
左连接后的检索结果是显示table1的所有数据和table2中满足where 条件的数据。
简言之 Right Join影响到的是右边的表,左边的表全部展示,而右边的表只能展示条件限制之内的。
右连接,右连接和左连接相反。1.0本不支持
SQL 原生:
Right Join
检索结果是table2的所有数据和table1中满足where 条件的数据。
简言之 Right Join影响到的是左边的表,右边的表里的数据全部展示,而左边表里的数据只能展示条件限制之内的。

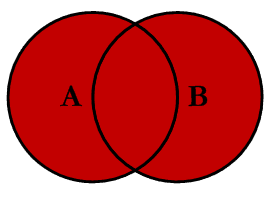
全连接,则是将两个表的需要的字段的数据全排列。全连接比较特殊,使用一个参数full=True 来完成全连接。1.0版本不支持
查询的全部代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 | #coding:utf-8from sqlalchemy.orm import sessionmakerfrom sqlalchemy import create_engine,and_,or_from sqlalchemy_improve_two import Student,Family,House,Car# print "初始化数据库引擎"engine = create_engine("mysql+mysqldb://root:123@localhost:3306/mydb?charset=utf8")# print "创建session对象"DBSession = sessionmaker(bind=engine)session = DBSession()def select_join(): # result = session.query(Student) # result = session.query(Family) # result = session.query(House) # result = session.query(Car) # print '两张表联表查询' # print 'Student表joinFamily表,通过查找Family表中member字段大于6的Student表中数据' # result = session.query(Student).join(Family).filter(Family.member>6) #三张表连表查询 # result = session.query(Student).join(Family).join(House).filter(House.location=='美克星人') #没有外键关系的join查询。car与其他表没有外键关系 # result_three = session.query(Student).join(Family).join(Car).filter(Car.name=='宝马') #在没有外键关联的情况下使用join连接两张表 # result = session.query(Student).join(Family).join(Car,Car.family_id==Family.id).filter(Car.name=='宝马') #or 操作 # result = session.query(Student.name,Family.member,House.location).join(Family).join(House).filter(or_(House.location=='地球',Family.member==7)) #in操作 # result = session.query(Student.name,Family.member).join(Family).filter(Family.member.in_((4,5,6))) #offset # result = session.query(Student).offset(2) #limit # result = session.query(Student).limit(2) #~取反操作 # result = session.query(Student.name,Family.member).join(Family).filter(~Family.member.in_((4,5,6))) #between # result = session.query(Student).filter(Student.id.between(1,2)) #like # result = session.query(Student).filter(Student.name.like('悟%')) # result = session.query(Student).filter(Student.name.like('悟')) #空值判断 # result = session.query(Student).filter(Student.name.is_(None)) # result = session.query(Student) # result = session.query(Student).all() result = session.query(Student).filter(id==1) # print 'sql语句:' # print result print 'result的数据类型:' print type(result) print '查询结果:' for x in result: print x.id,x.name if __name__ == "__main__": select_join() # print '关闭数据库连接' session.close() |
__EOF__

本文链接:https://www.cnblogs.com/goldsunshine/p/10124859.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理