

科学知识图谱绘制的大数据挖掘方法-3
新兴学科科学知识图谱绘制的大数据挖掘方法和实现 -3
金刀客
6 抓取数据预处理
对于数据预处理需要使用自然语言处理理论、方法和工具。
6.1 自然语言处理简介
自然语言处理(简称NLP)是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以它与语言学的研究有着密切的联系,但又有重要的区别。自然语言处理并不是一般地研究自然语言,而在于研制能有效地实现自然语言通信的计算机系统,特别是其中的软件系统。因而它是计算机科学的一部分。自然语言处理整体技术体系如下图所示:
最早的自然语言理解方面的研究工作是机器翻译。1949年,美国人威弗首先提出了机器翻译设计方案。20世纪60年代,国外对机器翻译曾有大规模的研究工作,耗费了巨额费用,但人们当时显然是低估了自然语言的复杂性,语言处理的理论和技术均不成热,所以进展不大。主要的做法是存储两种语言的单词、短语对应译法的大辞典,翻译时一一对应,技术上只是调整语言的同条顺序。但日常生活中语言的翻译远不是如此简单,很多时候还要参考某句话前后的意思。
大约90年代开始,自然语言处理领域发生了巨大的变化。这种变化的两个明显的特征是:
(1)对系统输入,要求研制的自然语言处理系统能处理大规模的真实文本,而不是如以前的研究性系统那样,只能处理很少的词条和典型句子。只有这样,研制的系统才有真正的实用价值。
(2)对系统的输出,鉴于真实地理解自然语言是十分困难的,对系统并不要求能对自然语言文本进行深层的理解,但要能从中抽取有用的信息。例如,对自然语言文本进行自动地提取索引词,过滤,检索,自动提取重要信息,进行自动摘要等等。
同时,由于强调了“大规模”,强调了“真实文本”,下面两方面的基础性工作也得到了重视和加强。
(1)大规模真实语料库的研制。大规模的经过不同深度加工的真实文本的语料库,是研究自然语言统计性质的基础。没有它们,统计方法只能是无源之水。
(2)大规模、信息丰富的词典的编制工作。规模为几万,十几万,甚至几十万词,含有丰富的信息(如包含词的搭配信息)的计算机可用词典对自然语言处理的重要性是很明显的。
常用的自然语言处理框架有:
| 名称 | 模块 | 语言 |
|---|---|---|
| Stanford NLP | 最著名的NLP框架。包括多种语言的各方面NLP模块:英文词根化、中文分词、词性标注、名词识别、语法分析等等 | Java、Python |
| NLTP | 使用广泛的开源NLP框架。包括众多NLP模块、多种语料库:英文词根化、词性标注、名词识别和语法分析等对于中文分词需要调用Standford NLP实现 | Python |
| 哈工大Ltp3 | 中文领域最著名对的NLP框架,包括全面的NLP模块:中文分词、词性标注、名词识别、句法分析、语义角色标注等等 | C++ |
| Fudan NLP | 复旦大学的NLP处理框架中文分词和句法分析等 | Java |
| HanLP | 开源NLP处理框架中文分词、句法分析等 | Java |
6.2 数据预处理方法和技术
数据预处理主要包括中文和英文预处理两部分。
6.2.1 中文数据预处理
数据预处理具体使用的自然语言处理中的包括中文分词、英文词根化、去停用词和特殊字符等方法。其中最难处理的是中文分词,下面对其进行简介。
汉语自然语言处理有别于英文自然语言处理的重要部分就是中文分词(Chinese Word Segmentation)。中文分词常用的方法分为两大类:
- (1)基于条件随机场(CRF)的中文分词算法,如Standford NLP和哈工大分词系统
- (2)基于中科院的张华平教授的NShort中文分词算法,如中科院ICTCLAS分词系统
| 分词方法 | 规模 | 编程语言 |
|---|---|---|
| ICTCLAS分词系统 | 大规模中文分词系统 | C++ |
| 结巴分词 | 小规模 | Python |
| Ltp | 中等规模 | C++、python |
| Stanford NLP | 大规模 | Java |
本书使用Spark调用Stanford NLP中的分词方法,进行中文分词。安装JDK开发环境,下载Stanford NLP工具包 Stanford CoreNLP 3.6版,及下载包括中文在内的全部语言包,就可以在spark项目中添加stanfoud-chinese-corenlp-model.jar,使用Stanford NLP工具包进行分词。
下面使用HanLP说明一下分词原理,它和ICTCLAS分词原理基本类似。
ICTCLAS分词算法源于隐马尔科夫模型(HMM)。其中核心代码为NShortSegment类的segSentence方法:
@override
public List<Term> segSentence(char[] sentence){
WordNet wordNetOptimum = new WordNet(sentence);
WordNet wordNetAll = new WordNet(sentence);
//1.粗分
List<List<Vertex>> coarseResult = BigSegment(sentence, 2, wordNetOptimum, wordNetAll);
boolean NERexists = false;
for(List<Vertex> vertexList : coarseResult){
if(HanLP.Config.DEBUG){
System.out.println("粗分结果" + convert(vertexList, false));
}
//2. 实体名识别
if(config.ner){
wordNetOptimum.addAll(vertexList);
int preSize = wordNetOptimum.size();
if(config.nameRecognize){
PersonRecognition.Recognition(vertexList, wordNetOptimum, wordNetAll);
}
if(config.translatedNameRecongnize){
translatedPersonRecogniztion.Recognition(vertexList, wordNetOptimum, wordNetAll);
}
if(config.japaneseNameRecognize){
JapanesePersonRecognition.Recognition(vertexList, wordNetOptimum, wordNetAll);
}
if(config.placeRecognize){
PlaceRecongnition.Recognition(vertexList, wordNetOptimum, wordNetAll);
}
if(config.organizationRecognize){
vertexList = Dijkstra.compute(GenerateBiGraph(wordNetOptimum));
wordNetOptimum.addAll(vertexList);
organizationRecognition.Recognition(vertexList, wordNetOptimum, wordNetOptimum);
}
if(!NERexists && preSize != wordNetOptimum.size()){
NERexists = true;
}
}
}
//3.细分阶段
List<Vertex> vertexList = coarseResult.get(0);
if(NERexists){
Graph graph = GenerateBiGraph(wordNetOptimum);
vertexList = Dijkstra.compute(graph);
if(HanLP.Config.DEBUG){
System.out.printf("细分词网:\n%s\n", wordNetOptimum);
System.out.printf("细分词图: %s\n", graph.printByTo());
}
}
//识别数字
if(config.numberQunantifierRecognize){
mergeNumberQuantifier(vertexList, wordNetAll, config);
}
//如果是索引模式则全部切分
if(config.indexMode){
return decorateResultForIndexMode(vertexList, wordNetAll);
}
//4. 词性标准阶段
if(config.speechTagging){
speechTagging(vertexList);
}
return convert(vertexList, config.offset);
}
6.2.2 英文数据预处理
英文数据预处理主要包括:提取词元(token)、词根化(stemming),保留表情、标签等特殊符号,去停用词,我们是NLTK来完成这一过程。完整的英文数据预处理过程如图4.5所示。
图4.5 英文数据预处理过程
7 预处理后数据的存储
7.1 数据常规存储
7.1.1 保存为JSON文件
JSON是一种在网络上特别是JavaScript经常使用的一种数据存储格式,属于轻量级数据交换格式。
JSON与XML对比如下图所示:


7.1.2 保存在MySQL数据库
使用Python的pymysql模块对Scrapy爬虫爬取的数据保存到MySQL数据库中,病进行数据库操作。将Scrapy爬取的数据存入MySQL中需要修改pipelines.py,修改代码如下所示:
import pymysql
class MysqlPipeline(object):
def __init__(self):
# 链接MySQL数据库
self.conn = pymysql.connect(
host="127.0.0.1", user="root", passwd="pass", db="mysqldb")
def process_item(self, item, spider):
# 获取到的name和keywd分别赋给变量name和变量key
name = item["name"][0]
key = item["keywd"][0]
# 构造对应的SQL语句
sql = "insert into mytb(title, keywd) VALUES ('" + name + "', '" + key + "')"
# 通过query实现执行对应的sql语句
self.conn.query(sql)
return item
def close_spider(self, spider):
self.conn.close()
ITEM_PIPELINES = {
'mysqlpjt.pipelines.MysqlpjtPipeline': 300,
}
修改乱码问题,在c:\Python3.5\Lib\site-packages\pymysql目录下找到名为connections.py。然后将文件中“charset=”,改为对应的编码“utf8”,即:Charset=’utf8’。
7.2 数据海量存储
本书项目得到的数据是海量的无法用传统的方式进行存取,因此需要对大数据的有效的存储方法。对于大非结构化数据可以存储在Hadoop的HDFS系统中;如使用如HBase的分布式数据库来存储。既提高了存储效率,也为后期使用Hadoop平台进行大数据计算做好了准备。
HBase是一个分布式、面向列的开源数据库,利用HBase技术可以在廉价的PC服务器上搭建大规模结构化存储集群。HBase思想来源于Google的BigTable思想HBase利用Hadoop_MapReduce来处理海量数据,利用Zookeeper作为其系统服务。
HBase具有以下特点:
-
(1) 线性和模块化可扩展性
-
(2) 严格一致的读写
-
(3) 表的自动配置和分片
-
(4) 支持区域服务器集群之间的自动故障转移
-
(5) 方面的基类支持如MapReduce作业
-
(6) 易于使用Java API的客户端访问
-
(7) 块缓存和布鲁姆过滤器实时查询
-
(8) Thrift网关和RESTful web 服务支持
-
(9) 可扩展的基于JRuby的脚本
-
(10) 支持监控信息通过Hadoop子系统导出达到文件
此外,Pig和Hive为HBase提供了高层的语言支持,使得HBase上进行数据统计处理变得非常简单。Sqoop则为Hbase提供了方便的RDBMS数据导入功能,使得传统数据库数据向HBase迁移非常方便。
HBase设计的初衷是针对大数据进行随机地、实时读写操作。随着互联网的发展,很多企业的数据也
7.3 Spark SQL读取HBase
Hive本质上是一种关系型抽象,是将SQL查询转换为MapRedcue作业。Spark_SQL使用来代替以前的Shark的,其中支持Hive的部分封装为一个称谓HiveContext的新包中。
Spark_SQL支持标准的SQL和HiveQL来读写数据。HiveContext提供更好的HiveQL解析能力、UDF借口和从Hive表中读取数据的能力。
要启动Hive的全部功能,首先要确保每个worker节点上都要启动集成Hive的jar包(Phive)并将hive-site.xml复制到spark安装目录下的conf文件夹下。默认情况下,Spark_SQL创建的所有表格都是由Hive管理。也就是说,Hive拥有该表的整个生命周期的控制权,包括删除权。注意Spark1.6支持Hive0.13。
具体实现步骤:
- (1)打开spark-shell
- $ spark-shell –driver-memory 1g
- (2)创建HiveContext实例
- Scala> val hc = new org.apache.spark.sql.hive.HiveContext(sc)
- (3)创建一张person表,列名为first_name、last_name和age
- Scala> hc.sql(“create table if not exists person( first_name string, last_name string, age int) row format delimited fields terminated by ‘,’ ”)
- (4)将本地数据导入到Person表中
- Scala> hc.sql(“load data local inpath \”/home/dhuser/person\” into table person”)
- (5)或从HDFS中导入数据
- Scala> hc.sql(“load data inpath \”/home/dhuser/person\” into table person”)
- (6)通过HiveSQL查询Person表
- Scala> val persons = hc.sql(”from person select first_name, last_name, age”)
- Scala>persons.collect.foreach(println)
- (7)直接进行表与表的复制
- Scala> hc.sql(“create table person2 like person localtion ‘/user/hive/warehouse/person’ ”)
本书项目中,是在Hive中创建了包括论文(papers)、作者(authors)、出版社(publisher)和关键词(keywords)在内的四张大表,并将Scrapy抓取的结果通过Spark SQL写入Hive的表中。其中论文表包括:题目、作者、关键字、摘要、参考文献和出版社六个字段。
8 大数据分析
8.1 特征提取
8.1.1 向量空间模型
向量空间模型(VSM:Vector_Space_Model)由Salton等人于20世纪70年代提出,并成功地应用于著名的SMART文本检索系统。VSM概念简单,把对文本内容的处理简化为向量空间中的向量运算,并且它以空间上的相似度表达语义的相似度,直观易懂。当文档被表示为文档空间的向量,就可以通过计算向量之间的相似性来度量文档间的相似性。文本处理中最常用的相似性度量方式是余弦距离。
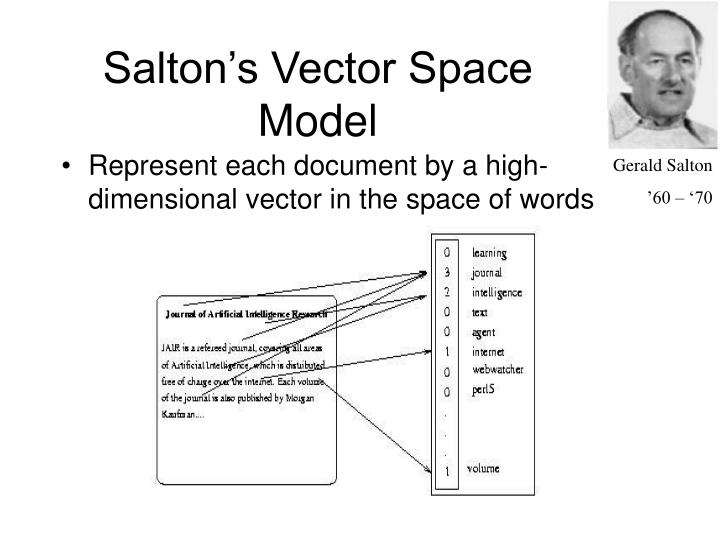
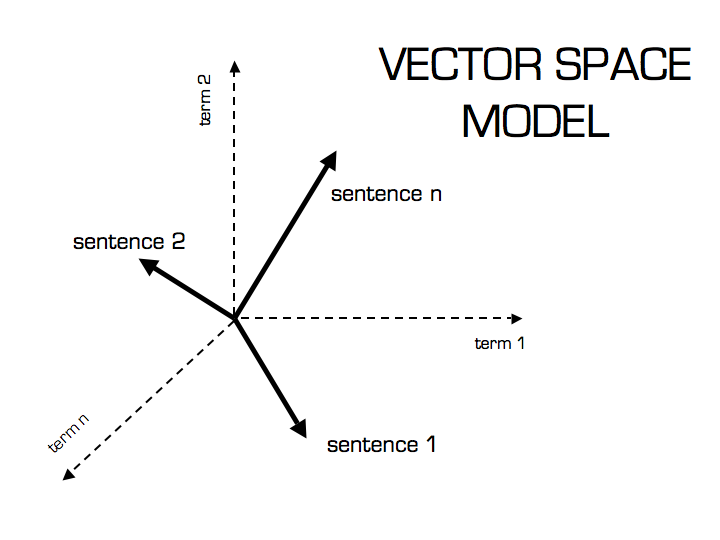
向量空间模型 (或词组向量模型)是一个应用于信息过滤,信息撷取,索引以及评估相关性的代数模型。SMART是首个使用这个模型的信息检索系统。文件(语料)被视为索引词(关键词)形成的多次元向量空间,索引词的集合通常为文件中至少出现过一次的词组。搜寻时,输入的检索词也被转换成类似于文件的向量,这个模型假设,文件和搜寻词的相关程度,可以经由比较每个文件(向量)和检索词(向量)的夹角偏差程度而得知。
实际上,计算夹角向量之间的余弦比直接计算夹角容易:余弦为零表示检索词向量垂直于文件向量,即没有符合,也就是说该文件不含此检索词。通过上述的向量空间模型,文本数据就转换成了计算机可以处理的结构化数据,两个文档之间的相似性问题转变成了两个向量之间的相似性问题。
8.1.2 TF-IDF提取特征
词频逆文本频率(简称TF-IDF)是一种从文本文档中生成特征向量的方法。它为文档中每一个词计算两个统计值:词频(TF)即每个词语在文档中出现的次数,另一个逆文本频率(IDF)用来衡量一个词语在整个文档语料库中出现的逆频繁程度。两者的积即TF*IDF表示一个词语特定文档的相关程度。
MLlib中有两种算法可以计算TF-IDF:HashingTF和IDF,它们都在mllib.feature包内。HashingTF从一个文档中计算给定大小的词频向量,为了将词与向量顺序对应起来,它使用Hash方法。但在类似英语这种语言里,有数十万的单词,因此对于单词映射到向量中的一个独立维度上需要付出很大代价。而HashTF使用每个单词对所需向量长度S取模得出的哈希值,把所有单词映射到一个0到S-1的数字上。由此我们保证生成一个S维的向量。在实践中推荐奖S设置为218到220之间。
HashingTF可以一次只运行一个文档中,也可以运行于整个RDD中。它要求每个文档都是用响亮的可迭代序列来表示如python中的list。在进行TF计算之前先要进行数据预处理如单词小写、去标点、词根化。实践中,我们在map()中调用NLTK进行英文处理调用Stanford NLP进行中文处理。
当构建好词频向量后,就可以使用IDF来计算逆文档频率,然后当它们乘以词频来计算TF-IDF。首先,对IDF对象调用fit()方法获取一个IDFmodel,它代表语料库中的逆文本频率。接下来,对模型调用transform()方法来把TF向量转换为IDF向量。计算代码如下:
#!/usr/bin/python
from pyspark.mllib.feature import HashingFT, IDF
rdd = sc.wholeTextFiles(“data”).map(lambda(name,text): text.split())
tf = HashingTF()
tfVectors = tf.transform(rdd).cache()
idf=IDF()
idfModel=idf.fit(tfVectors)
tfIdfVectors = idfModel.transform(tfVectors)
代码中我们调用cache()方法,因为它被两次调用(一次训练IDF模型,一次用IDF乘以TF向量)
8.1.3 Word2Vec提取特征
Word2Vec是google提出的一种基于神经网络的文本特征化计算方法。Spark在mllib.feature.Word2Vec引入了该方法的实现。
要训练Word2Vec需要给它一个String类(每个单词用一个)的Iterable表示的语料库。当模型训练好后(通过Word2Vec.fit(rdd)),会得到Word2VecModel,它可以用来将每个单词通过transform()转化为一个向量。注意,Word2Vec算法规模大小等于你的词库中单词数乘以向量大小(默认为100),一般比较合适的词库大小为100000个单词。
8.1.4 优化处理
- 缩放处理
构建好特征向量后,需要使用MLlib中的StandardScaler类进行缩放,同时控制均值和标准差。你需要创建一个StandardScalar类,对数据集调用fit()函数来获取一个StandardScalerModel,也就是为每一列计算平均值和标准差。然后使用模型对象的transform()方法来伸缩特征向量集,示例代码如下:
#!/usr/bin/python
from pysparkmllib.feature import StandardScaler
vector = [Vectors.dense(-2.0, 5.0, 1.0), Vectors.dense(2.0, 0.0, 1.0)]
dataset = sc.parallelize(vectors)
scaler = StandardScaler(withMean=true, withStd=True)
model = scaler.fit(dataset)
result = model.transform(dataset)
- 正则化处理
在某些情况下,在准备输入数据时,把向量正规化为长度1也是有用的,可以使用Normalizer类来实现,只要使用Normalizer.transform(rdd)就可以了。默认情况下,Normalizer使用欧氏距离,也可以通过P值传递其他距离计算方法。
8.2 聚类方法分析
8.2.1 聚类方法简介
聚类分析是无监督学习任务。是在没有给定划分类别的情况下,根据数据相似度进行样本分组的数据挖掘方法。与分类模型需要使用有类标记样本构成的训练数据不同,聚类模型可以建立在无类标记的数据上,是一种非监督学习算法。聚类根据数据自身的距离和相似度将它们划分为若干组,划分的原则是组内样本距离最小化而组间距离最大化。该算法主要用于数据探索或者异常点检测(识别与任意聚类都比较远的点)
聚类方法如表1所示,基于划分的聚类方法如表2所示
| 类别 | 主要算法 |
|---|---|
| 基于划分的方法 | K-Means(K均值)、K-Medoids(K中心)、CLARANS(基于选择) |
| 基于密度的方法 | BIRCH、CURE、CHAMELEON |
| 基于密度的方法 | DBSCAN、DENCLUE、OPTICS |
| 基于网格的方法 | STING、CLIOUE、WAVE-CLUSTER |
| 基于模型的方法 | 统计学方法、神经网络方法 |
| 算法 | 算法描述 |
|---|---|
| K-Means | K均值聚类又称为快速聚类,在最下化误差函数的基础上,将数据划分为预定的类数K。该算法原理简单,而且便于处理大量数据。 |
| K-Medoids | K均值算法对孤立点有较强的敏感性。而K中心点算法不用簇中对象的平均值作为簇中心,而选择簇中心平均值最近的对象作为簇中心。 |
| 系统聚类 | 系统聚类又称为多层次聚类,分类的单位由高到低呈树形结构,且所处的位置越低,其包含的对象就越少,但这些对象间的共同特征越多。该聚类方法只适用于小数据量,大数据量速度会非常慢 |
8.2.2 Spark MLlib
MLlib中包含经典的聚类算法K-Means,该方法如图所示。以及一个叫做K-meansII(使用Bahmani的scalable K-means++的初始化过程)的变种,可以为并行环境提供更好的初始化策略。
K-means方法中最重要的参数是生成的聚类中心的目标数量K。事实上,你几乎不可能提前知道聚类的真是数量,所以最佳实践是尝试几个不同的K值,知道聚类内部平均距离不在显著下降为止。MLlib的K-means方法还接受方法:
- (1)initializationMode:用于初始化聚类中心的方法可以是K-meansII或者random,一般K-meansII会带来更好的结果但开销比较大。
- (2)maxIterations:运行最大迭代次数(默认100)
- (3)run:并发运行次数。
当调用K-means算法时,你需要创建mllib.cluster.KMeans对象(Scala或Java)或KMeans.train(在python中)。它接受一个Vector组成的RDD作为参数。K-means返回一个KMeansModel对象,该对象允许你访问其clusterCenters属性或者调用predict()来对新的向量返回它所属于类别。Predict()总会返回和改点距离最近的聚类中心,即使与所有的类都离得很远。
8.2.3 学科流派分析
我们使用MLlib的聚类分析方法分析学科流派,具体就是通过聚类,将文献聚成几个大的类别,每个大类别中在划分出小的类别。这样就将各个类别看做是该学科的各种流派,大的类别为大流派,小的为小流派。文献对应的核心作者为该流派的核心作者,该流派的关键字作为该流派的核心观点。
8.3 图分析方法分析学者之间关系
8.3.1 小世界网络
随着万维网、Facebook和twitter等社交网络的兴起。这些数据描述了真实世界中的网络结构和形态,而不是科学家和图论中的理性网络模型。最早论文真是网络属性的是Duncan_Watts发表的Collective_dynamics_of_‘small_world’_network论文。该论文第一次为具有”小世界”属性的图提出了数学生成模型,其特性:
- (1)网络中大部分节点的度都不高,它们和其他节点形成了相对稠密的簇,即一个节点的邻接节点大多数也是相连的
- (2)虽然图中的大部分节点的度都不高而且相对稠密的簇,但只需经过少数几条边可能从一个网络节点快速到达另一个节点
8.3.2 Spark GraphX和图分析
8.3.3 分析伴生关系和构建伴生网络
8.3.4 理解网络结构
9 数据分析结果的可视化
数据可视化是数据挖掘的一个重要的部分。数据可视化借助图形化手段,清晰有效的传达与沟通信息。数据可视化与信息图形、信息可视化、科学可视化以及统计图形等有密切关系。数据可视化为人类洞察数据的内涵、理解数据蕴藏的规律提供了重要的手段。
9.1 R语言简介
R是用于统计分析、绘图的语言和操作环境。R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。R作为一种统计分析软件,是集统计分析与图形显示于一体的。它可以运行于UNIX,Windows和Macintosh的操作系统上,而且嵌入了一个非常方便实用的帮助系统,相比于其他统计分析软件,R还有以下特点:
- (1)R是自由软件。这意味着它是完全免费,开放源代码的。可以在它的网站及其镜像中下载任何有关的安装程序、源代码、程序包及其源代码、文档资料。标准的安装文件身自身就带有许多模块和内嵌统计函数,安装好后可以直接实现许多常用的统计功能。[2]
- (2)R是一种可编程的语言。作为一个开放的统计编程环境,语法通俗易懂,很容易学会和掌握语言的语法。而且学会之后,我们可以编制自己的函数来扩展现有的语言。这也就是为什么它的更新速度比一般统计软件,如,SPSS,SAS等快得多。大多数最新的统计方法和技术都可以在R中直接得到。[2]
- (3)所有R的函数和数据集是保存在程序包里面的。只有当一个包被载入时,它的内容才可以被访问。一些常用、基本的程序包已经被收入了标准安装文件中,随着新的统计分析方法的出现,标准安装文件中所包含的程序包也随着版本的更新而不断变化。在另外版安装文件中,已经包含的程序包有:base一R的基础模块、mle一极大似然估计模块、ts一时间序列分析模块、mva一多元统计分析模块、survival一生存分析模块等等.[2]
- (4)R具有很强的互动性。除了图形输出是在另外的窗口处,它的输入输出窗口都是在同一个窗口进行的,输入语法中如果出现错误会马上在窗口口中得到提示,对以前输入过的命令有记忆功能,可以随时再现、编辑修改以满足用户的需要。输出的图形可以直接保存为JPG,BMP,PNG等图片格式,还可以直接保存为PDF文件。另外,和其他编程语言和数据库之间有很好的接口。[2]
- (5)如果加入R的帮助邮件列表一,每天都可能会收到几十份关于R的邮件资讯。可以和全球一流的统计计算方面的专家讨论各种问题,可以说是全世界最大、最前沿的统计学家思维的聚集地.[2]
R是基于S语言的一个GNU项目,所以也可以当作S语言的一种实现,通常用S语言编写的代码都可以不作修改的在R环境下运行。 R的语法是来自Scheme。R的使用与S-PLUS有很多类似之处,这两种语言有一定的兼容性。S-PLUS的使用手册,只要稍加修改就可作为R的使用手册。所以有人说:R,是S-PLUS的一个“克隆”。
9.2 用R可视化Spark
Spark本身并没有可视化工具,但我们可以通过HDFS数据导出到R中,使用R进行可视化。R可以绘制二维或三维空间中的点,但通过Spark计算获取的结果通常维度很高,这就需要我们将数据集投影到不超过三维空间上。另一方面R不大适合处理大型数据集,因此需要对数据进行采样,这样才能使用R进行可视化。
下面代码我们从HDFS上读取CSV数据,用sample方法来抽样形成比较小的子集使其可以放到R中进行计算。我们用主成分分析或奇异值分解方法(这两种方法的spark实现在前面已经介绍)将高纬度数据将维到二维或三维空间中,我们使用直接的投影方式。代码如下:
Val sample = data.map(datum =>
Model.predict(datum) + “,” + datum.toArray.mkString(“,”))
.sample(false, 0.05)
Sample.saveAsTextFile(“/user/ds/sample”)
3D交互可视化R代码如下所示:
Install.package(“rgl”)
Library(rgl)
Clusters_data<-read.csv(pipe(“hadoop fs –cat /user/ds/sample/*”))
clusters<-clusters_data[1]
data<-data.mtrix(clusters_data[-c(1)])
rm(clusters_data)
random_projection<-matrix(data=rnorm(3*ncol(data)), ncol=3)
random_projection_normal<-
random_project /
sqrt(rowSums(random_projection*random_projection))
projected_data<-data.frame(data%*%random_projection_norm)
num_clusters<-nrow(unique(clusters))
palette<-rainbow(num_clusters)
colors = sapply(clusters, functions(c), palette[c])
plot3d(projected_data, col = colors, size=10)
9.3 数据可视化Web显示
使用Flask将分析结果可视化。分为以下两步:
9.3.1 flask简介
Flask是一个使用 Python 编写的轻量级 Web 应用框架。其 WSGI 工具箱采用 Werkzeug ,模板引擎则使用 Jinja2 。Flask使用 BSD 授权。
Flask也被称为 “microframework” ,因为它使用简单的核心,用 extension 增加其他功能。Flask没有默认使用的数据库、窗体验证工具。
Flask简单易学,下面是Flask版的hello world(hello.py)代码:
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello():
return "Hello World!"
if __name__ == "__main__":
app.run()
安装Flask:
> pip install Flask
运行hello world程序
> python hello.py
hello.py* Running on http://localhost:5000/
9.3.2 结合R可视化数据
在Flask项目中定义Result_template.html用于显示R可视化结果
# result_template.html
@app.route(‘/make/a/map’)
def make_map:
#读取mySQL数据库中的结果
Data = get_data()
C = Counter
For each in data:
C[“AGE”] = 1
Return render_template(‘result_tempate.html’, json=R_json)
在result_template.html中嵌入JS代码,将可视化结果展示出来。
10 部署
10.1生产环境简介
生产环境列表
| Hadoop生产环境 | Cloudera 5.12 |
|---|---|
| OS | CentOS 7 |
| Hadoop | 2.6.3 |
| Hive | 1.2 |
| Spark | 1.6 |
| Scala | 2.11 |
| Java | 1.8 |
| Python | 3.6 |
| R | 1.4.8 |
| Flask | 0.12.2 |
| Scrapy | 1.5 |
本项目推荐部署环境为两种:一种是读者的Hadoop大数据集群可以使用基于Yarn的部署方式,如果还要提高性能可以考虑加入Tachyon内存管理存储层;另一种是读者希望在公有云上部署,我们为您介绍基于Amazon的EC2解决方案,基于阿里云的解决方案其步骤也差不许多。
10.2 基于Yarn的部署
10.2.1 部署原理
Yarn是基于HDFS的一种分布式资源协调框架,是Hadoop的主要组成部分。Yarn遵从主从架构。主守护进程被称为资源管理器(ResourceManager),从守护进程被称为节点管理器(NodeManager)。除此之外,生命周期由ApplicationMaser负责,它可以被派生到任何从节点上并可以生存一个应用的生命周期时长。Spark如果运行在yarn上,资源管理器充当Spark Master,节点管理器充当执行节点。如果使用Yarn运行Spark,每个Spark执行程序以Yarn容器的形式运行。
部署在Yarn上的Spark应用有两种模式:
(1) yarn-client:Spark驱动运行在Yarn集群之外的客户端进程上,并且ApplicationMaster仅用于协调安排资源管理器的资源。架构图如图所示。
(2) yarn-cluster:Spark驱动运行于由从节点的节点管理器派生的ApplicationMaster上。架构图如图所示。
前一种方式适用于开发和调试,后一种方式适用于生产环境部署。不需要特别指定哪个模式,因为它油Hadoop的配置决定,master的参数是yarn-client为前一种方式,而yarn-cluster为后一种方式。
Yarn模式下,可配置的参数包括:
- num-executors:配置可分配执行程序数
- executor-memory:每个执行程序可使用的内存
- executor-cores:每个执行程序可使用的CPU内核数
10.2.2 具体实施步骤
- 配置参数
编辑spark-env.sh文件(/opt/spark/conf)
添加:
export HADOOP_CONF_DIR=/opt/hadoop/etc/Hadoop
expprt YARN_CONF_DIR=/opt/hadoop/etc/Hadoop
- 以yarn-client模式启动Yarn Spark
$ spark-submit --class path-to-your-class --master yarn-client [option] <app jar> [app options]
如:
$ spark-submit --class com.bigdata --master yarn-client --num-executors 3 --driver-memory 4g --executor-memory 2g --executor-cores 1 target/sparkio.jar 10
- 以Spark-shell方式启动yarn-client:
$ spark-shell --master yarn-client
- 以yarn-cluster模式启动Yarn Spark
$ spark-submit --class path-to-your-class --master yarn-cluster [options] <app jar> [app options]
如:
$ spark-submit --class com.bigdata class --master yarn-cluster --num-executors 3 --driver-memory 4g --executor-memory 2g --executor-cores target/sparkio.jar 10
10.3 基于Tachyon内存存储层的Spark集群部署
Tachyon是一个高性能、高容错、基于内存的开源分布式存储系统[1],并具有类Java的文件API、插件式的底层文件系统、兼容Hadoop_MapReduce和Apache_Spark等特征。Tachyon能够为集群框架(如Spark、MapReduce等)提供内存级速度的跨集群文件共享服务。Tachyon充分使用内存和文件对象之间的世代(Lineage)信息,因此速度很快,官方号称最高比HDFS吞吐量高300倍。目前,很多公司(如Pivotal、EMC、红帽等)已经在使用Tachyon,并且来自20个组织或公司(如雅虎、英特、红帽等)的60多个贡献者都在为其贡献代码。Tachyon是于UC_Berkeley数据分析栈(BDAS)的存储层,它还是Fedroa操作系统自带应用。
Spark平台以分布式内存计算的模式达到更高的计算性能,在最近引起了业界的广泛关注,其开源社区也十分活跃。以百度为例,在百度内部计算平台已经搭建并运行了千台规模的Spark计算集群,百度也通过其BMR的开放云平台对外提供Spark计算平台服务。然而,分布式内存计算的模式也是一柄双刃剑,在提高性能的同时不得不面对分布式数据存储所产生的问题,具体问题主要有以下几个:
-
- 当两个Spark作业需要共享数据时,必须通过写磁盘操作。比如:作业1要先把生成的数据写入HDFS,然后作业2再从HDFS把数据读出来。在此,磁盘的读写可能造成性能瓶颈。
-
- 由于Spark会利用自身的JVM对数据进行缓存,当Spark程序崩溃时,JVM进程退出,所缓存数据也随之丢失,因此在工作重启时又需要从HDFS把数据再次读出。
-
- 当两个Spark作业需操作相同的数据时,每个作业的JVM都需要缓存一份数据,不但造成资源浪费,也极易引发频繁的垃圾收集,造成性能的降低。
仔细分析这些问题后,可以确认问题的根源来自于数据存储,由于计算平台尝试自行进行存储管理,以至于Spark不能专注于计算本身,造成整体执行效率的降低。Tachyon的提出就是为了解决这些问题:本质上,Tachyon是个分布式的内存文件系统,它在减轻Spark内存压力的同时赋予了Spark内存快速大量数据读写的能力。Tachyon把存储与数据读写的功能从Spark中分离,使得Spark更专注在计算的本身,以求通过更细的分工达到更高的执行效率。[2]

图1: Tachyon的部署
图1显示了Tachyon的部署结构。Tachyon被部署在计算平台(Spark,MR)之下以及存储平台(HDFS, S3)之上,通过全局地隔离计算平台与存储平台, Tachyon可以有效地解决上文列
举的几个问题,:
• 当两个Spark作业需要共享数据时,无需再通过写磁盘,而是借助Tachyon进行内存读写,从而提高计算效率。
• 在使用Tachyon对数据进行缓存后,即便在Spark程序崩溃JVM进程退出后,所缓存数据也不会丢失。这样,Spark工作重启时可以直接从Tachyon内存读取数据了。
• 当两个Spark作业需要操作相同的数据时,它们可以直接从Tachyon获取,并不需要各自缓存一份数据,从而降低JVM内存压力,减少垃圾收集发生的频率。
10.4 在Amazon EC2上部署Spark
Amazon弹性计算云(EC2)是一个能够提供可变大小的云计算实例的网络服务,已经有很多机构通过使用它节省了大量的人力和物力资源。EC2包括以下特性:
- (1) 通过互联网按需提供IT资源
- (2) 提供足够多的实例
- (3) 像支付水电费一样,按时按需付费
- (4) 没有配置成本,无需开销,无需大量运维
- (5) 当不需要时,可以立即关闭甚至终止其生命周期
- (6) 支持多种常用的包括Windows和Linux在的操作系统
- (7) EC2提供不同类型的实例,以满足不同的计算需求,如通用实例、微实例、内存优化实例和存储优化实例等,其中微实例提供免费试用
10.4.1 准备工作
Spark有绑定的Spark-ec2脚本使得在Amazon EC2上安装、管理和关闭Spark集群变得十分容易。
开始前需要完成以下工作:
- (1) 登录你的Amazon AWS账号(http://aws.amazon.com/cn)
- (2) 点击右上角的我的账户的下拉菜单的安全证书
- (3) 点击访问秘钥并创建访问秘钥
- (4) 记下访问秘钥ID(Access Key )和私有访问秘钥(Secret Access Key)
- (5) 点击进入EC2
- (6) 点击左侧菜单网络安全下面的密钥对
- (7) 点击创建秘钥对(Create Key Pair),输入kp-spark作为秘钥对名称
- (8) 下载私钥文件并复制到/home/hduser/keypairs文件夹下
- (9) 设置文件权限许600
- (10) 将公钥ID和私钥ID的设置到环境变量中如:
> echo “export AWS_ACCESS_KEY_ID=\”AAJFJAOFJAOFAJ\”” >> /home/hduser/.bashrc
> echo “export AWS_ACCESS_KEY=\”+XrsagsgasgagaeeerCfsf\”” >>
/home/hduser/.bashrc
> echo “export PATH=$PATH:/opt/spark/ec2” >> /home/hduser/.bashrc
10.4.2 具体实施步骤
- Spark绑定在EC2上的安装脚本spark-ec2,使用下面命令部署集群:
$ cd /home/hduser
$ spark-ec2 –k <key-pair> -i <key-file> -s <num-slaves> launch <cluser-name>
- 以下列数值为例部署集群
$ spark-ec2 –k kp-spark –i /home/hduser/keypairs/kp-spark.pem –hadoop-major-version 2 –s 3 launch spark-cluster
- 当缺省值不可用时,需要重新发送请求并定制特定的可用区域
$ spark-ec2 –k kp-spark –i /home/hduser/keypairs/kp-spark.pem –z us-east-1b –hadoop-major-version 2 –s 3 launch spark-cluster
- 如你的应用需要实例关闭后保留数据,就需要增加一个EBS卷(如10G空间)
$ spark-ec2 –k kp-spark –i /home/hduser/keypairs/kp-spark.pem –z us-east-1b –hadoop-major-version 2 –ebs-vol-size –s 3 launch spark-cluster
- 如果使用的时Amazon Spot实例
$ spark-ec2 –k kp-spark –i /home/hduser/keypairs/kp-spark.pem –z us-east-1b –spot-price=0.15 hadoop-major-version 2 –s 3 launch spark-cluster
-
一切部署完毕后,打开网页或命令行查看集群状态
-
在EC2上使用Spark集群,使用SSH登录到主节点
$ spark-ec2 –k kp-spark –i /home/hduser/kp/kp-spark.pem login spark-cluster
- 检查主节点的目录并查看其用途
| 目录 | 用途 |
|---|---|
| Ephemeral-hdfs | 存储临时数据,当重启或关闭机器会被删掉 |
| Persisten-hdfs | 每个节点都有一个很小量的永久空间(约3G)。如果使用的话,数据会被保存在这个目录下 |
| Hadoop-native | 用于支持Hadoop的原生库如Snappy压缩库 |
| Scala | Scala安装目录 |
| Shark | Shark安装目录 |
| Spark | Spark安装目录 |
| Spark-ec2 | 支持该集群部署的文件 |
| Tachyon | Tachyon安装目录 |
- 检查临时实例的HDFS版本
$ ephemermral-hdfs/bin/hadoop version
- 更改日志配置
> cd spark/conf
> mv log4j.properties.template log4j.properties
> vi log4j.properties
Log4j.rootCategory=INFO, console
改为:log4j.rootCategory=ERROR, console
- 修改后将所有的配置复制到所有从节点
$ spark-ec2/copydir spark/conf
- 使用完毕后销毁Spark集群
$ spark-ec2 destroy spark-cluster
11 总结
本书主要介绍和分析了基于大数据分析的学科知识图谱的绘制方法。相比较传统的科学知识图谱的绘制方法,它有很明显的优势,但也存在了一些不足。将两种方法比较如下图所示:
| 学科知识图谱 | 传统绘制方法 | 大数据处理绘制方法 |
|---|---|---|
| 典型软件 | CiteSpace或VOSviewer | Hadoop、Spark、Scripy |
| 方式 | 单机 | 分布式 |
| 数据量 | 少量 | 海量 |
| 数据采集 | 手工采集期刊数据库(如CNKI和WOS)的论文题录 | 使用Scrapy自动爬取期刊数据库(如CNKI)题录信息 |
| 存储方式 | 文本或MySQL数据库 | HDFS和Hive分布式数据库 |
| 计算方式 | 单机自然语言处理或机器学习工具包NLTK或sciki-learn | 分布式机器学习工具包如spark和深度学习工具TansorFlow |
| 应用使用方式 | 单机应用Java GUI | Web应用 Flask |
| 可视化方法 | 基于Java的可视化Process | R工具包 |
| 成熟度 | 十分成熟 | 不十分成熟 |
参考文献
- [1]. Russell M A. Mining the Social Web: Data Mining Facebook, Twitter, LinkedIn, Google+, GitHub, and More[M]. " O'Reilly Media, Inc.", 2013.
- [2]. Choy M, Cheong M, Laik M N, et al. Us presidential election 2012 prediction using census corrected twitter model[J]. arXiv preprint arXiv:1211.0938, 2012.
- [3]. Tumasjan A, Sprenger T O, Sandner P G, et al. Predicting Elections with Twitter: What 140 Characters Reveal about Political Sentiment[J]. ICWSM, 2010, 10: 178-185.
- [4]. Kwak H, Lee C, Park H, et al. What is Twitter, a social network or a news media?[C]//Proceedings of the 19th international conference on World wide web. ACM, 2010: 591-600.
- [5]. Java A, Song X, Finin T, et al. Why we twitter: understanding microblogging usage and communities[C]//Proceedings of the 9th WebKDD and 1st SNA-KDD 2007 workshop on Web mining and social network analysis. ACM, 2007: 56-65.
- [6]. Sakaki T, Okazaki M, Matsuo Y. Earthquake shakes Twitter users: real-time event detection by social sensors[C]//Proceedings of the 19th international conference on World wide web. ACM, 2010: 851-860.
- [7]. Cha M, Haddadi H, Benevenuto F, et al. Measuring User Influence in Twitter: The Million Follower Fallacy[J]. ICWSM, 2010, 10(10-17): 30.
- [8]. Go A, Bhayani R, Huang L. Twitter sentiment classification using distant supervision[J]. CS224N Project Report, Stanford, 2009, 1: 12.
- [9]. Kumar S, Morstatter F, Liu H. Twitter data analytics[M]. New York: Springer, 2014.
- [10].Twitter development document. https://dev.twitter.com/overview/documentation[W]
- [11]. flask: a microframework for python. http://flask.pocoo.org/ [W]
- [12]. Tweepy: an easy-to-use python library for accessing the twitter api. http://www.tweepy.org/ [W]
- [13]. "Twitter's API - HowStuffWorks." HowStuffWorks. N.p., n.d. Web. 24 Oct. 2014.
- [14]. Grinberg M. Flask Web Development: Developing Web Applications with Python[M]. " O'Reilly Media, Inc.", 2014.
- [15]. Ediger D, Jiang K, Riedy J, et al. Massive social network analysis: Mining twitter for social good[C]//2010 39th International Conference on Parallel Processing. IEEE, 2010: 583-593.
- [16]. Jürgens P, Jungherr A. A Tutorial for Using Twitter Data in the Social Sciences: Data Collection, Preparation, and Analysis[J]. Preparation, and Analysis (January 5, 2016), 2016.
- [17].李敏. 互联网舆情监控系统设计与实现 [D]. Diss. 复旦大学, 2009.
- [18]. 曾润喜. "网络舆情管控工作机制研究." 图书情报工作 53.18 (2009): 79-82. [19]. 祝华新, 单学刚, 胡江春. 2011 年中国互联网舆情分析报告[J]. 社会蓝皮书: Z01Z, 2011.
- [20]. Wei W, Xin X. 基于聚类的网络舆情热点发现及分析[J]. 现代图书情报技术, 2009, 3(3): 74-79.
- [21]. 曾润喜, 徐晓林. 网络舆情突发事件预警系统, 指标与机制[J]. 情报杂志, 2009, 28(11): 52-54.
- [22]. Gemsim: topic modelling for humans. https://radimrehurek.com/gensim/ [W]
- [23]. McKinney W. Python for data analysis: Data wrangling with Pandas, NumPy, and IPython[M]. " O'Reilly Media, Inc.", 2012.
- [24]. Pedregosa F, Varoquaux G, Gramfort A, et al. Scikit-learn: Machine learning in Python[J]. Journal of Machine Learning Research, 2011, 12(Oct): 2825-2830.
- [25]. Demšar J, Curk T, Erjavec A, et al. Orange: data mining toolbox in Python[J]. Journal of Machine Learning Research, 2013, 14(1): 2349-2353.
- [26]. Chaurasia S, McDonnell T. Synonymy and Antonymy Detection in Distributional Models[J]. 2016.
- [27]. Hutto C J, Gilbert E. Vader: A parsimonious rule-based model for sentiment analysis of social media text[C]//Eighth International AAAI Conference on Weblogs and Social Media. 2014.
- [28]. Word-clouds. https://amueller.github.io/word_cloud/ [W]
- [29]. Lutz M. Learning python[M]. " O'Reilly Media, Inc.", 2013.
- [30]. Aggarwal C C, Zhai C X. Mining text data[M]. Springer Science & Business Media, 2012.
- [31]. Witten I H, Frank E. Data Mining: Practical machine learning tools and techniques[M]. Morgan Kaufmann, 2005.
- [32]. Han J, Pei J, Kamber M. Data mining: concepts and techniques[M]. Elsevier, 2011.
