


科学知识图谱绘制的大数据挖掘方法-2
新兴学科科学知识图谱绘制的大数据挖掘方法和实现 -2
金刀客
4 开发工具和开发环境搭建
4.1 开发工具简介
开发中使用的软件如下表所示:
表4.1 开发环境列表
| 软件 | 版本 |
|---|---|
| Windows 10 | 64bit |
| Hadoop | 2.6.2 |
| Spark | 1.6.3 |
| JDK | 1.8.0 |
| Eclipse | Oxygen |
| Python | 3.5 |
| Flask | 0.12.2 |
| HBase | 1.2 |
| Scala | 2.11 |
| Maven | 0.12 |
| Cmder | 17.10 |
| SecureCRT | 7.1 |
| VMware | 14.1 |
4.1.1 Scala语言
Scala是一门多范式的编程语言,一种类似java的编程语言,设计初衷是实现可伸缩的语言、并集成面向对象编程和函数式编程的各种特性。
-
面向对象特性, Scala是一种纯面向对象的语言,每一个值都是对象。对象的数据类型以及行为由类和特征(Trait)描述。类抽象机制的扩展有两种途径。一种途径是子类继承,另一种途径是灵活的混入(Mixin)机制。这两种途径能避免多重继承的种种问题。
-
函数式编程, Scala也是一种函数式语言,其函数也能当成值来使用。Scala提供了轻量级的语法用以定义匿名函数,支持高阶函数,允许嵌套多层函数,并支持柯里化 。Scala的Case Class及其内置的模式匹配相当于函数式编程语言中常用的代数类型(Algebraic Type)。
更进一步,程序员可以利用Scala的模式匹配,编写类似正则表达式的代码处理XML数据。在这些情形中,顺序容器的推导式(comprehension)功能对编写公式化查询非常有用。
Scala很容易与Java进行互调用。
本书中使用的最主要的语言就是Scala。
4.1.2 Java
Java是一门面向对象编程语言,不仅吸收了C++语言的各种优点,还摒弃了C++里难以理解的多继承、指针等概念,因此Java语言具有功能强大和简单易用两个特征。Java语言作为静态面向对象编程语言的代表,极好地实现了面向对象理论,允许程序员以优雅的思维方式进行复杂的编程。
Java具有简单性、面向对象、分布式、健壮性、安全性、平台独立与可移植性、多线程、动态性等特点。Java可以编写桌面应用程序、Web应用程序、分布式系统和嵌入式系统应用程序等
Java由四方面组成:
-
- Java编程语言
-
- Java类文件格式
-
- Java虚拟机
-
- Java应用程序接口[21]
当编辑并运行一个Java程序时,需要同时涉及到这四种方面。使用文字编辑软件(例如记事本、写字板、UltraEdit等)或集成开发环境(Eclipse、MyEclipse等)在Java源文件中定义不同的类[22] ,通过调用类(这些类实现了Java_API)中的方法来访问资源系统,把源文件编译生成一种二进制中间码,存储在class文件中,然后再通过运行与操作系统平台环境相对应的Java虚拟机来运行class文件,执行编译产生的字节码,调用class文件中实现的方法来满足程序的Java_API调用
4.1.3 Python
Python是一种解释型、面向对象、动态的高级程序设计语言。自上个世纪九十年代,Python语言诞生至今,逐渐被广泛应用于处理系统管理任务和开发web系统。目前Python已经成为最受欢迎的程序设计语言之一。
由于Python1语言的简洁、易读以及扩展性,配合经典的科学计算扩展库NumPy(数组快速处理)、SciPy(数值计算)、Maplotlib(绘图功能)和数据分析扩展库Pandas、机器学习扩展库Scikit-learn以及IPython_NoteBook交互式编程环境,python逐渐成为数据分析领域首选的工具。
Python的众多扩展库由许多社区分别维护和发布,因此要一一将其收集齐全并非易事。本书将使用CONTINUUM公司开发的Anaconda(https://www.continuum.io/downloads)Python科学计算软件集成包。读者只需要下载并并执行安装程序,就可安装好本书涉及的所有扩展库。Anaconda支持Windows、Linux和Mac OSX三种桌面环境。安装时会提示是否修改PATH环境变量和注册表,如希望手动激活Anaconda开发环境,请取消这两个选项。
4.1.4 Eclipse
Eclipse 是一个开放源代码的、基于Java的可扩展开发平台。就其本身而言,它只是一个框架和一组服务,用于通过插件组件构建开发环境。Eclipse最初是由IBM公司开发的替代商业软件Visual_Age_for_Java的下一代IDE开发环境,2001年11月贡献给开源社区,现在它由非营利软件供应商联盟Eclipse基金会(Eclipse_Foundation)管理。
4.1.5 Maven
Maven项目对象模型(POM),可以通过一小段描述信息来管理项目的构建,报告和文档的软件项目管理工具。Maven 除了以程序构建能力为特色之外,还提供高级项目管理工具。由于Maven的缺省构建规则有较高的可重用性,所以常常用两三行Maven构建脚本就可以构建简单的项目。Maven作为构建工具已经成为事实的标准。
Maven和 Ant有什么不同呢?在回答这个问题以前,首先要强调一点:Maven和Ant针对构建问题的两个不同方面。Ant为Java技术开发项目提供跨平台构建任务。Maven本身描述项目的高级方面,它从 Ant 借用了绝大多数构建任务。两者对比如图所示。
| Maven | Ant | |
|---|---|---|
| 标准构建文件 | project.xml 和 maven.xml | build.xml |
| 特性处理顺序 | ${maven.home}/bin/driver.properties, ${project.home}/project.properties, ${project.home}/build.properties, ${user.home}/build.properties, 通过 -D 命令行选项定义的系统特性, 最后一个定义起决定作用。 |
通过 -D 命令行选项定义的系统特性, 由任务装入的特性,第一个定义最先被处理。 |
| 构建规则 | 构建规则更为动态(类似于编程语言);它们是基于 Jelly 的可执行 XML | 构建规则或多或少是静态的,除非使用<script>任务 |
| 扩展语言 | 插件是用 Jelly(XML)编写的。 | 插件是用 Java 语言编写的。 |
| 构建规则可扩展性 | 通过定义 <preGoal> 和 <postGoal> , 使构建 goal 可扩展。 | 构建规则不易扩展;可通过使用<script> 任务模拟 <preGoal> 和 <postGoal> 所起的作用。 |
Maven的两个主要特征:
- 约定优于配置,如下表展示了通用目录位置
| 名称 | 位置 |
|---|---|
| Scala源码 | /src/main/scala |
| Java源码 | /src/main/java |
| 源代码所需要资源 | /src/main/resources |
| Scala测试代码 | /src/test/scala |
| Java测试代码 | /src/test/java |
| 测试代码需要资源 | /src/test/resources |
- 声明依赖管理。在maven中每个库都依赖三层坐标定义,如下表所示:
| 名称 | 功能 |
|---|---|
| groupId | 和java、scala包类似的分组管理库的逻辑方式,其中至少有你的域 |
| artifactId | 项目或Jar包的名字 |
| Version | 版本号 |
在pom.xml(Maven项目的配置文件)中,用以上三层坐标方式定义依赖关系。没有必要搜索互联网再下载、解压和复制库。只需要提供依赖关系的Jar的三层坐标,剩下的Maven会为你做好。下面是JUnit依赖例子:
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
Maven之后的构建工具如SBT和Gradle都遵循这些原则。
4.2 开发环境
4.2.1 安装JDK8
Variable:JAVA_HOME
Value:D:\BigData\jdk1.8.0_152
Variable:PATH
Value:%JAVA_HOME%\bin
- 检验
4.2.2 安装Maven
具体实现:
-
- 下载Apache-Maven-3.3,解压到指定目录
-
- 设置环境变量
MAVEN_HOME,PATH:
- 设置环境变量
Variable:MAVEN_HOME
Value:D:\apache-maven-3.3.9
Variable:PATH
Value:%MAVEN_HOME%\bin
-
- 检验(最近版Eclipse中已经集成了m2e插件,可以直接使用)
4.2.3 安装Scala
-
- 下载Scala2.11,并安装
-
- 设置环境变量
SCALA_HOME,PATH:
- 设置环境变量
Variable:SCALA_HOME
Value:D:\scala
Variable:PATH
Value:%SCALA_HOME%\bin
-
- 检验
- 检验
4.2.4 安装Hadoop
-
- 下载 Hadoop-2.6.x: hadoop
-
- 从GitHub上下载: hadoop-common-2.6.0-bin-master
将下载到的文件夹下的 11个文件一起放到Hadoop-2.6-x的 “bin”目录下。
- 从GitHub上下载: hadoop-common-2.6.0-bin-master
-
- 在”Hadoop-2.6-x” 内部创建文件夹“data”; 在“data”文件夹下创建子文件夹 “data” 和 “name”;创建临时文件夹, 如 “D:\Bigdata\temp”;创建日志文件夹,如 “D:\Bigdata\userlog”
-
- 编辑四个Hadoop配置文件
Core-site.xml,hdfs-site.xml,mapred.xml,yarn.xml(Hadoop-2.6.x\etc\Hadoop)
- 编辑四个Hadoop配置文件
Core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>D:\BigData\hadoop\temp</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:50071</value>
</property>
</configuration>
Hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///D:/hdp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///D:/tmp/hdp/dfs/data</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///D:/tmp/hdp/dfs/namesecondary</value>
</property>
</configuration>
Mapred.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/hadoop-2.6.2/share/hadoop/mapreduce/*,
/hadoop-2.6.2/share/hadoop/mapreduce/lib/*,
/hadoop-2.6.2/share/hadoop/common/*,
/hadoop-2.6.2/share/hadoop/common/lib/*,
/hadoop-2.6.2/share/hadoop/yarn/*,
/hadoop-2.6.2/share/hadoop/yarn/lib/*,
/hadoop-2.6.2/share/hadoop/hdfs/*,
/hadoop-2.6.2/share/hadoop/hdfs/lib/*,
</value>
</property>
</configuration>
Yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandle</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>D:\BigData\hadoop\userlog</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>D:\BigData\hadoop\temp\nm-local-dir</value>
</property>
<property>
<name>yarn.nodemanager.delete.debug-delay-sec</name>
<value>600</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>
/hadoop-2.6.2/,
/hadoop-2.6.2/share/hadoop/mapreduce/*,
/hadoop-2.6.2/share/hadoop/mapreduce/lib/*,
/hadoop-2.6.2/share/hadoop/common/*,
/hadoop-2.6.2/share/hadoop/common/lib/*,
/hadoop-2.6.2/share/hadoop/yarn/*,
/hadoop-2.6.2/share/hadoop/yarn/lib/*,
/hadoop-2.6.2/share/hadoop/hdfs/*,
/hadoop-2.6.2/share/hadoop/hdfs/lib/*,
</value>
</property>
</configuration>
编辑 hadoop-env.cmd (Hadoop-2.6.0\etc\hadoop)文件
设置 JAVA_HOME= D:\BigData\jdk1.8.0_152
- 设置 环境变量
Variables: HADOOP_HOME
Value:D:\Bigdata\hadoop-2.6.2
Variable: PATH
Value:
D:\Bigdata\hadoop-2.6.2\bin
D:\Bigdata\hadoop-2.6.2\sbin
D:\Bigdata\hadoop-2.6.2\share\hadoop\common\*
D:\Bigdata\hadoop-2.6.2\share\hadoop\hdfs
D:\Bigdata\hadoop-2.6.2\share\hadoop\hdfs\lib\*
D:\Bigdata\hadoop-2.6.2\share\hadoop\yarn\*
D:\Bigdata\hadoop-2.6.2\share\mapreduce\*
D:\Bigdata\hadoop-2.6.2\common\lib\*
- check configure检验设置
- 格式化 name-node: 定位
Hadoop-2.6.2\bin
命令如下:
> hdfs namenode -format
- 启动Hadoop
进入hadoop-2.6.0\bin目录,以系统管理员身份分别运行start-dfs.cmd和start-yarn.cmd,启动dfs和mapreduce进程。运行结果如下图所示:
4.2.5 安装Spark
到Spark主页下载对应版本的Hadoop相对应版本,如本书使用的是Spark1.6.3和Hadoop2.6,如下图所示,并解压到指定文件夹。

4.2.6 安装Eclipse
-
- 下载Eclipse ,最新版本为
Oxygen,新版有很多变化,安装时可以选择多个版本,我们选择JAVA开发版:
- 下载Eclipse ,最新版本为
-
- set environmental variables:
Variable: ECLIPSE_HOME
Value: D:\Bigdata\Eclipse
Variable: PATH
Value: %ECLIPSE_HOME%\bin
-
- 下载“hadoop2x-eclipse-plugin-master”。将release文件夹下的三个jar包都拷贝到eclipse的dropins文件夹中。MapReduce开发环境
-
- 在Help->Eclipse MarketPlace中分别安装maven、scala IDE和PyDev
-
- MapReduce Project in Eclipse
1)创建JavaProject
2)添加外部的Jars,“D:\Bigdata\hadoop-2.6-0”所有Jar包
3)在Eclipse连接DFS
Eclipse->Window->Perspective->Open Perspective->other->MapReduce
- MapReduce Project in Eclipse
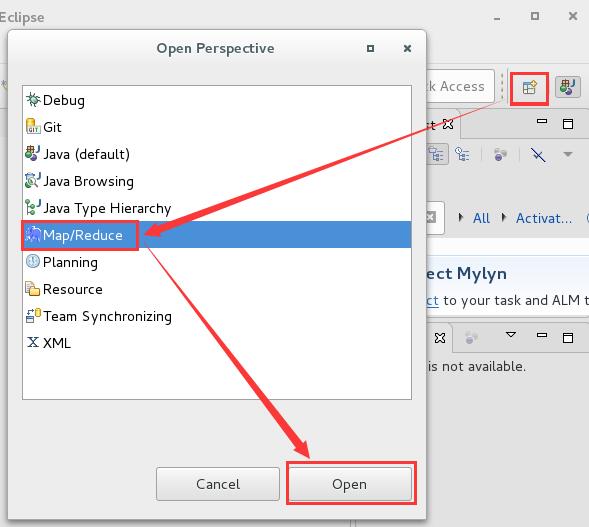
按照如下设置:
MapReduce(V2)Master
a. Host:localhost
b. Port:9001
DFS Master
a: Host:localhost
b: 50071
然后就可以上传扩下文件到Hadoop上了。
(6)Spark Project in Eclipese
下面使用Maven构建一个Spark版本的Wordcount应用,测试在Eclipse开发Spark是否可用。
-
1)打开Eclipse,File->New->project->选择Maven Project,可以看到如下图的新项目创建向导:
-
2)下一步,选择quickstart 1.1 版本
-
3)输入Group id,Airtfact id,点击Finish
-
4)编辑pom.xml文件,输入以下代码:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.robin</groupId>
<artifactId>sparkWC</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>sparkWC</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.2.0</version>
</dependency>
</dependencies>
<dependencies>
<dependency>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.3</version>
</dependency>
</dependencies>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</project>
5)将wordcount示例代码拷贝到该项目中
6)命令行中进入新建的项目目录,使用mvn package命令进行编译:
定位到spark-1.6.2-bin-hadoop2.6\bin目录下,输入:
spark-submit --class sparkWCexample.spWCexample.WC --master local[2]
/hadoop/examples/spWCexample/target/spWCexample-1.0-SNAPSHOT.jar
/hadoop/examples/spWCexample/how.txt /hadoop/examples/spWCexample/anwer.txt
结果会输出到anwer.txt目录下
7)可以通过http://localhost:4040/jobs看到执行进程
六 yarn-client开发者模式
四 开发模式
4.1 使用Spark-shell
Spark绑定了REPL shell功能,是使用Scala shell进行封装的。虽然Spark-shell看起来是简单的命令行,但实际上可以完成复杂的查询工作,可以用于开发的前期试探性开发。下面以一个例子说明使用Spark-shell完成Hadoop Mapreduce的经典的字数统计
- (1) 创建文本文件并上传到上传Hadoop HDFS上
$ mkdir words
$ cd words
$ echo “big data mining, mining data” > data.txt
$ hadoop dfs –put ../words /user/hduser
- (2) 进入Spark-shell统计字数
$ spark-shell
#将words目录载入RDD
Scala> val words = sc.textFile(“hdfs://localhost:9000/user/hduser/words”)
#计算行数
Scala> words.count
#把单行(或多行)分割为多个单词
Scala> val wordsFlatMap = words.flatmap(_.split(“\\W+”))
#转换单词为键值形式(word, 1)
Scala> val wordsMap = wordsFlatMap.map( w => (w,1))
#以单词为键进行求和
Scala> val wordCount = wordsMap.reduceByKey((a,b) = > (a+b))
#对结果进行排序
Scala> val wordCountSorted = wordCount.sortByKey(true)
#输出RDD
Scala> wordCountSorted.collect.foreach(println)
- (3) 综合上面步骤为一步
Scala> sc.textFile(“hdfs://localhost:9000/user/hduser/words”).flatMap(_.split(\\W+)).map( w => (w,1).reduceByKey((a,b) => (a+b)).sortByKey(true).collect.foreach(println))
- (4) 输出结果
(big, 1)
(data, )
4.2.7安装其他工具
本书使用的其他工具还有用于远程连接linux服务器的SecureCRT、用于远程传输文件到Linux服务器的SecureSFTP、用于Window命令行多开的cmder、开源的关系数据库MariaDB、虚拟机软件VMware、简易程序编辑器VScoder、Web调试工具chrome、R语言IDE工具RStudio、python命令行工具iPython等等,均可直接从其官方网站下载使用。
5 期刊元数据抓取
传统期刊元数据方法中数据获取主要使用手工下载导入,大数据处理方法已经完全不可能胜任。我们需要使用自动化的方法来批量快速的下载所需要的期刊数据,使用网络爬虫可以很好的解决这个问题。
5.1 网络爬虫概述
网络爬虫又称为网络蜘蛛、网络蚂蚁或网络机器人。网络爬虫是一种能够。爬虫可以将多个站点的信息收集起来,并通过在线(网页被下载后)或离线(网页被存储后)的方式,集中进行进一步分析和挖掘。网络爬虫可以分为通用网络爬虫、聚焦网络爬虫、增量式网络爬虫和深层网络爬虫。
5.1.1 通用网络爬虫
网络爬虫的最主要的应用在搜索引擎中,google和百度都有自己的功能强大的网络爬虫。网络爬虫还可以应用在商业智能上,企业可以利用它收集对手的情报以及潜在合作信息; 也可以应用于监视用户感兴趣的网站和网页,当特定位置出现新信息时,用户可以得到提醒。Web爬虫也有危害,如用于收集用户信息或电子邮件信息,用于诈骗。
网络爬虫由控制节点、爬虫节点、资源库组成。
通用网络爬虫又称为全网爬虫,可以爬取整个互联网上的资源。通用网络爬虫所爬取的目标数据庞大,爬行范围非常广,可以爬取海量数据,因此要求其性能要非常高。这种爬虫主要应用于Google、baidu等搜索引擎中,有非常高的应用价值。
通用网络爬虫主要由初始URL集合、URL队列、页面爬行模块、页面分析模块、页面数据库、链接过滤模块等构成。通用爬虫会采用如深度优先或广度优先等爬行策略。传统网络爬虫流程如图4.1所示。
图5.1 传统爬虫结构图
5.1.2 聚焦网络爬虫
通用性网络爬虫针对特定的数据爬取问题,存在着以下局限性:
- (1) 不同领域、不同背景的用户往往具有不同额检索目的和需求,通用网络爬虫抓取很多用户不关心的网页数据
- (2) 通用性网络爬虫其目标是尽可能大的网络覆盖率,但这与有限的服务器资源和近乎无限的网络资源产生了很大的矛盾
- (3) 互联网数据形式不断丰富、技术不断发展。图片、数据库、音视频多媒体等大量新兴的数据的大量涌现,通用网络爬虫并不能很好的发现和获取这些数据。
- (4) 通用网络爬虫大多基于关键字无法针对语义进行相关数据的爬取
针对以上问题,提出了聚焦网络爬虫。
聚焦网络爬虫又称为主题网络爬虫。本书中对于期刊数据库的论文题录数据的爬取就是使用聚焦爬虫。因此我们详细介绍以下聚焦爬虫。
聚焦网络爬虫是按照预先定义好的主题有选择的进行网页爬取的一种网络爬虫。聚焦网络爬虫不像通用网络爬虫一样将目标资源定位在整个互联网中,而是将爬虫的目标网页定位在与主题相关的页面中。这将大大节省爬虫爬取时说需要的带宽资源和服务器资源。聚焦网络爬虫主要应用在对特定信息的爬取中,主要为某一类特定的人群提供服务。
聚焦网络爬虫主要由初始URL合集、URL队列、页面爬行模块、页面分析模块、页面数据库、链接过滤模块、内容评价模块、链接评价模块等构成。内容评价模块可以评价内容的重要性,同理,链接评价模块也可以评价链接的重要性,然后根据链接和内容的重要性,可以确定哪些页面优先访问。聚焦爬虫的爬行策略主要由四种,即基于内容评价的爬行策略、基于链接评价的爬行策略、基于增量学习的爬行策略和基于语境图的爬行策略。
通用网络爬虫和聚焦网络爬虫的对比。
图4.2 通用爬虫和主题爬虫对比
主题爬虫具有以下特征:
- (1)产生冗余信息较少。主题爬虫采用一定策略对数据进行抓取,减少了大量无关的数据;
- (2)各个主题间有着紧密联系。主题爬虫根据策略选取内容比较相关的数据进行抓取,增加了准确率。
- (3)搜索效率高。主题爬虫选择内容相关的数据进行抓取,舍去了大量无关的数据,从而加快了搜索速度。
5.1.3 增量式网络爬虫
增量式网络爬虫是指对已下载网页采取增量式更新和只爬取尽可能新的页面。和周期性爬行和刷新页面的网络爬虫相比,增量式网络爬虫只会再需要的时候才爬行新产生或发生更新的页面,并不重新下载没有没有发生变化的页面,可有效的减少数据下载量,及时更新已经爬行的网页数据,减小时间和空间上的耗费,但增加了爬行算法复杂度和实现难度。
5.1.4 深层网络爬虫
Web页面存在方式可以分为表层网页和深层网页。表层网页是指传统搜索引擎可以索引的页面,以超链接可以到达的静态页面为主构成的Web页面。深层网络是指大部分内容不能通过静态链接获取、隐藏再搜索表单后,只有用户提交一些关键词才能获得的Web页面。例如用户登录或者注册才能访问的页面,如贴吧或论坛中的数据。
5.2 Scrapy简介和核心架构
Scrapy框架时其中最为成熟、使用最为广泛的Python爬虫框架。相对于其他基于Python语言的网络爬虫框架如crawley、poria、newspaper和python-goose等。Scrapy具有开发的快速、高层次的信息爬取框架等特点,可以高效率的爬取Web页面并提取出我们关注的结构化数据。Scrapy框架使用的领域十分广发,比如网络爬虫开发、数据挖掘、数据监控和自动化测试等等。Scrapy框架网址为: http://scrapy.org。官方界面如图所示
Scrapy核心架构如图所示。图中处于中心位置的Scrapy引擎为Scrapy框架架构的核心。Scrapy的组件主要包括:Scrapy引擎、调度器、下载器、下载中间件、蜘蛛(或称为爬虫,一个Scrapy项目中可以有多个Spiders爬虫文件)、爬虫中间件、实体管道等。
其中,Scrapy引擎为整个架构的核心,调度器、实体管道、下载器和蜘蛛等组件都通过Scrapy引擎来调控。在Scrapy引擎和下载器之间,可以通过下载中间件的组件进行信息的传递,在下载中间件中,可以插入一些自定义的代码来轻松扩展Scrapy的功能。Scrapy引擎和爬虫之间也可以通过爬虫中间件与Scrapy引擎的信息传递,可以轻松的添加,扩展。
5.2.1 Scrapy引擎
Scrapy引擎是整个Scrapy架构的核心,负责控制整个数据处理流程,以及触发一些事务处理。Scrapy引擎与调度器、实体管道、中间件、下载器、蜘蛛等组件都有关系,Scrapy引擎处于Scapy框架的中心位置,对各组件进行控制和协调。
5.2.2 调度器
调度器主要实现存储带爬取的网址,并确定这些网址的优先级,决定下一次爬取哪个网址等。调度器的存储结构可以看成为一个优先队列,调度器会从引擎中接受request请求并存入优先队列中,在队列中可能会有多个带爬取的网址,但这些网址各自具有一定的优先级,同时调度器会过滤掉一些重复的网址,避免重复爬取。
当引擎发出请求之后,调度器将优先队列中的xia’yi’ci要爬取的网址返回给引擎,以供引擎进行进一步处理。
5.2.3 下载器
下载器主要实现对网络上要爬取的网页资源进行高速下载,由于该组件需要通过网络进行大量数据传输,所以该组件的压力负担一般会比其他组件中。下载器下载了对应的网页资源后,会将这些数据传递给scrapy引擎,再由Scrapy引擎传递给对应的爬虫进行处理。
5.2.4 下载中间件
下载中间件是处于下载器和Scrapy引擎之间的一个特定组件,主要用于对下载器和Scrapy引擎之间的通信进行处理,在下载中间件,可以添加自定义代码,轻松实现Scrapy功能的扩展。如添加IP池和用户代理池。
5.2.5 蜘蛛
蜘蛛组件,也称作爬虫,该组件是Scrapy框架中爬虫实现的核心。在一个Scrapy项目中,可以有多个蜘蛛,每个蜘蛛可以负责一个或多个特定的网站。蜘蛛组件主要负责接收Scrapy引擎中的response响应,在接受了response响应后,蜘蛛会对这些response响应进行分析处理,然后可以提取出对应的关注数据,也可以提取出接下来需要处理的新网址等信息
5.2.6 爬虫中间件
爬虫中间件是处于Scrapy引擎和爬虫组件之间的一个特定的组件,主要用于对爬虫组件和scrapy引擎之间的通信进行处理,在爬虫中间件中可以加入自定义代码,轻松实现Scrapy引擎与爬虫组件进行通信的时候调用。
5.2.7 实体管道
实体管道主要用于接收从蜘蛛组件中提取出来的项目(item),接收后会对一些item进行对应的处理,如清洗、验证、存储到数据库中等。
5.3 Scrapy安装和使用
5.3.1 Scrapy安装
安装配置Scrapy有很多方式如下载安装包安装、编译源码安装、使用pip命令进行安装,当我们更加推荐使用Anaconda进行安装,这样可以避免一些莫名的错误信息。
我们使用python3版本的Scrapy进行开发。在Windows、Mac或Linux均可以通过如下方式安装Scrapy。
首先安装好Anacoda3,Anacoda是Python开发环境软件包集合,集成了众多开发Python用的库和包。然后使用命令conda进行安装。命令如下:
$ conda install -c conda-forge scrapy
使用如下命令进行验证,安装正确不会报错:
$ python –c ‘import scrapy’
5.3.2 Scrapy结构
首先我们了解一下Scrapy的目录结构。使用Scrapy创建爬虫项目,默认会创建成一个与爬虫项目名称相同的文件夹。文件夹下会有一个与项目同名的文件夹,文件夹下拥有一个同名子文件夹和一个scrapy.cfg文件。
该同名子文件夹下放置爬虫项目的核心代码,scrapy.cfg为爬虫项目的配置文件。其中核心代码包括一个spiders文件夹,以及__init__.py、items.py、pipelines.py、setting.py等文件。其中__init__.py为项目的初始化文件,主要写的是一些项目的初始化信息。Items.py为爬虫项目的数据容器文件,主要用来定义我们要获取的数据。Pipeline.py文件为爬虫项目的管道文件,主要用来对items.py定义的数据进行进一步的加工和处理。Setting.py文件为爬虫项目的设置文件,主要为爬虫项目的一些设置信息。Spiders文件夹下放置的是爬虫项目中的爬虫部分相关的文件。init.py文件为爬虫项目中爬虫部分的初始化文件,主要对spiders进行初始化。
5.3.3 scrapy命令使用
- 全局命令
-
(1)帮助命令
scrapy –h 获取命令帮助信息,如图所示。可以获取诸如fetch、runspider、shell、setting、startprojetct、version、view等名令的帮助信息。 -
(2)fetch名令
fetch命令主要用于显示爬虫爬取的过程,如图所示: -
(3)runspider命令
通过Scrapy中的runspider命令我们可以实现不依托Scrapy的爬虫项目,直接运行一个爬虫文件。如运行first.py爬虫文件:
from scrapy.spiders import Spider
class FirstSpider(Spider):
name = "first"
allowed_domains = ["baidu.com"]
start_urls = [
"http://www.baidu.com",
]
def parse(self, response):
pass
-
(4)settings命令
我们可以通过settings命令查看Scrapy对应的配置信息。如果在Scrapy项目目录中使用settings命令,查看对应项目的配置信息;如在项目目录外需要使用settings命令,查看Scrapy默认配置信息。 -
(5)shell命令
通过shell命令可以启动Scrapy的交互终端。经常在开发或调试的时候会用到交互终端。使用Scrapy交互终端可以实现在不启动Scrapy爬虫的情况下,对网站响应进行调试,同样,在交互终端中,可以写一些python的代码进行响应的测试。
如可以使用shell命令,为爬取百度首页创建一个交互终端环境,并设置为不输出日志信息,如下图所示。
(6)startproject 命令
Startproject可以常见一个爬虫项目,进入该爬虫项目后可以对其进行管理。如下图所示:
- 项目命令
项目命令是指在进入一个已经创建好的Scrapy爬虫项目后使用的命令。包括:Bench、GenSpider、Check、Crawl、List、Edit、Parse等命令,下面将逐一进行介绍。
-
(1)Bench命令
利用Bench命令可以测试本地硬件的性能。当我们运行Scrapy bench时,会创建一个本地服务器并且会以最大的速度爬行,在此测试本地硬件的性能,避免其他过多因素的影响,所以仅进行链接跟进,不进行内容的处理。运行结果如图所示。 -
(2)Genspider命令
可以使用genspider命令来创建Scrapy爬虫文件,这是一种快速创建爬虫文件的方式。使用该命令可以基于现有的爬虫模板直接生成一个新的爬虫文件,非常方便。默认安装的模板有basic、crawl、csvfeed、xmlfeed。
使用“scrapy genspider –t 模板 爬虫名 爬虫爬取的域名”创建爬虫,默认模板为basic,如图所示:
使用“scrapy genspider –d 模板”,查看模板内容,查看csvfeed模板的具体内容为:scrapy genspider –d cvsfeed
-
(3)Check命令
爬虫测试比较麻烦,因此Scrapy使用contract方式对爬虫进行测试,命令为check。如对于crawler.py进行contract检查,可以使用命令:scrapy check crawler。如图所示: -
(4)Crawl命令
通过crawl命令来启动某个爬虫,启动结果如下图所示: -
(5)List命令
List命令可以列出当前可以使用的爬虫文件。 -
(6)Edit命令
Edit命令可以直接打开指定爬虫的爬虫文件进行编辑。 -
(7)parse命令
Parse命令可以实现获取指定URL的网址,并使用对应的爬虫文件进行分析和处理,如下图所示,使用example爬虫来爬取http://www.sina.com
5.3.4 使用XPath进行数据筛选和提取
XPath是一种XML路径语言。通过该语言可以在XML文档中迅速地查找到相应的信息,XPath表达式通常叫作XPath selector。在XPath表达式中,使用”/”可以选择某个标签,并且可以使用“/”进行多层标签的查找。
代码:
<html>
<head>
<title> 首页</title>
</head>
<body>
<h2>
大数据与网络爬虫关系?
</h2>
<p>在大数据处理中,数据源是很重要的,如果数据无法直接获取使用网络爬虫可以轻松的获取大量的数据 </p>
</p>他们的关系还有</p>
</body>
</html>
如果我们提取
标签对应的内容,可以使用“/”选择某个标签。如下XPath表达式即可实现/html/body/h2,如果想获取该标签中的文本信息,可以通过text()实现,/html/body/h2/text()
该表达式会提却如下信息:
“大数据与网络爬虫关系?”
使用“//”可以提取某个标签的所有信息。比如上方代码中出现了多个
标签,如果想将这所有
标签的所有信息都提取出来,可以使用“//”实现。
对网页中如果想获得X的值为Y的
如希望获取所有class属性为“f1”的标签中的内容,可以通过以下XPath表达式获取:
//img[@class=” f1”]
以上简要的介绍了XPath的使用方法,更加详细的使用方法可以参考XPath官方使用手册。
5.3.5 Scrapy使用技巧
(1)多开Scrapy进程
如果需要将Scrapy项目中的爬虫文件批量运行,需要使用CrawProcess来实现。
(2)避免被禁止爬取
在运行爬虫时,如果爬取的网页较多,经常会遇到网络爬虫在网站被禁止的效果这种问题。因为很多网站都有相应的反爬虫机制,避免爬虫的恶意爬取。
所以当我要抓取大量网页的时候,很可能会受到对方服务器的限制,从而被禁止。因此我们非常需要用一些方法来避免被禁。我们经常使用的防止禁止爬虫的方法有:禁止Cookie、设置下载延时、使用IP池和用户代理池四种方法来阻止禁用网络爬虫。
-
1) 禁止Cookies
有的网站会通过用户的Cookie信息对用户进行识别和分析,此时我们可以通过禁用本地Cookie信息的方式让对方无法识别我们的对话信息,从而无法禁止我们的爬取。
我们可以在Scrapy项目中的设置setting.py文件中:
COOKIES_ENABLED = False
即可以实现禁用本地的Cookie,rang那些通过用户Cookie信息对用户进行识别和分析的网站无法识别我们,即无法禁止我们爬取。 -
2) 设置延时下载
有的网站会通过我们对网页的访问(爬取)频率进行分析,如果爬取频率过快,则判断为爬虫自动爬取行为,识别后对我们进行相应的限制,比如禁制我们再爬取该服务器上的网页。
对于这类网站,我们需要控制一下爬行时间间隔。在Scrapy项目中,我们可以直接在对应的setting.py文件中设置:
DOWNLOAD_DELAY=0.7
即爬虫下载网页的时间间隔设置为0.7秒。 -
3) 使用IP资源池
有的网站会对用户的IP进行检测,如果同一个IP在短时间内对服务器上的网页进行大量的爬取,那么就将其判为爬虫,加以限制。
如果爬虫的IP被封,我们就需要更改IP,普通用户的IP资源池有限,需要使用代理服务器。将代理服务器的IP组成一个IP池,爬虫每次对网页进行爬取的时候,可以随机选择IP资源池中的IP进行。
在Scrapy项目中,在setting.py中配置好中间件,并配置好IP资源池。
在setting.py中设置:
IPPOOL=[
{“ipaddr”: “112..33.226.167:3128”},
{“ipaddr”: “118.187.10.11:80”},
{“ipaddr”: “123.57.190.51:7777”}
]
此时IPPOOL是对应的代理服务器IP池,外层通过列表形式存储,里层通过字典的形式存储。
设置好setting.py后,我们需要编写下载中间件文件,该文件将使用中间件“HpptProxyMiddeware”在设置中间层。
在scrapy项目中, 创建middlewares.py,需要在下载中间件文件中写入具体的程序实现:
# middlewares 下载中间件
# 导入随机模块,目的是随机挑选一个IP池中的IP
import random
#从setting文件中导入设置好的IPPOOL
From myfirstpjt.setting import IPPOOL
#导入官方文档中HttpProxyMiddleware对应的模块
from scrapy.contrib.downloadmiddleware.httpproxy
import HttpProxyMiddleware
#导入HttpProxyMiddleWare对应的模块
from scrapy.contrib.downloadermiddleware.httpproxy
import HttpProxyMiddleware
class IPPOOLs(HttpProxyMiddleware):
#初始化方法
def __init__(self, ip=’’):
self.ip = ip
#process_request()方法,主要进行请求处理
def process_request(self, request, spider):
#先随机选择一个IP
Thisip = random.choice(IPPOOL)
print(“当前ip为:” + thisip[“ipaddr”])
#将获取的IP添加到代理中,用该IP进行爬取
request.meta[“proxy”] = “http://” + thisip[“ipaddr”]
编写好下载中间件后将其添加到,setting.py中的相应的配置中:
DOWNLOAD_MIDDLEWARES = {
‘scrapy.contrib.downloadmiddleware.httpproxy.HttpProxyMiddleware’:123,
‘myfirstpjt.middlewares.IPPOOLS’:125
}
- 4) 使用用户代理池
有些网站可以识别用户代理信息,通过用户代理信息可以判断出我们使用的是什么浏览器,什么形式的客户端。网站服务器可以更具我们的User-Agent信息,对我们的爬行行为进行分析,以此来实现反爬虫处理。
破解这种限制,可以通过搜集多种浏览器的信息,以此建立一个用户代理池,然后再建立一个下载中间件,在下载中间件中设置每次随机选择用户代理池中的一个用户代理进行爬行。
与IP代理池不同的地方是,我们使用下载中间件的类型为UserAgentMiddleware,而在IP代理池中我们使用的是HttpProxyMiddleware。
首先,在setting.py配置文件中设置好用户代理池,代理池的名称可以自己定义,如下所示:
用户代理池设置
UAPOOL=[
“Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebkit/537.36 (KHTML, like Gecko) Chrome/49.0.26 Safari/537.36 SE 2.X MetaSr 1.0”,
“Mozilla/5.0 (Windows NT 6.1; WOW64; rv:48.0) Gecko/20100101 Firefox/48.0”,
“Mozilla/5.0 ”
]
通过以上代码我们设置了一个名为UAPOOL的用户代理池,接下来我们创建一个下载中间件uamid.py,其内容如下:
import random
From myfirstpjt.setting import UAPOOL
From scrapy.contrib.downloadermiddleware.useragent
import UserAgentMiddleware
class Uamid(UserAgentMiddleware):
def
def process_request(self, request, spider):
thisua = random.choice(UAPOOL)
print(“当前使用的User-Agent:” +thisua)
request.headers.setdefault(‘User-Agent’, thisua)
然后需要在setting.py文件中设置下载中间件:
DOWNLOAD_MIDDLEWARES = {
‘scrapy.contrib.downloadmiddleware.useragent.UserAgentMiddleware’:2,
‘myfirstpjt.uamid.Uamid’:1
}
设置好后,我们可以运行该Scrapy项目下的爬虫文件,可以看到通过下载中间件自动的随机切换用户代理进行网页爬取,这样就可以很好的避免网站服务器通过识别用户代理来屏蔽我们的爬虫。
- 5)Tor代理
Tor是洋葱路由器,通过分布式系统方式,允许用户通过中继网络连接,而无需建立直接连接,这样就可以对访问网站隐藏IP地址,因为连接是在不同服务器之间随意变换的,无法追踪你的踪迹,使人们可以匿名浏览互联网。在国内使用Tor需要先用VPN连接到国外服务器,然后再配置Tor。由于Scrapy只支持Http代理,但Tor使用的是sock5代理方式,绑定在9050端口。因此需要用polipo将sock5代理转换为Http代理。修改polipo配置文件config.sample为:
socksParentProxy = "localhost:9050"
socksProxyType = sock5
diskCacheRoot = ""
运行命令: polipo.exe –c config.sample, 完成以上工作后我们需要在RandomProxy中间件中将process_request方法代码修改为:
def process_request(self, request, spider):
request.meta['proxy'] = 'http://127.0.0.1:8123'
-
6)分布式下载器:Crawlera
Scrapy官方提供一个分布式下载器Crawlera,用来帮助我们躲避反爬虫的封锁,但需要付费,具体参考官方文档。 -
7)Goolge Cache
Google Cache是指使用Google的快照功能。Google是目前最强大的搜索引擎,可以将爬取到的网页缓存到服务器中。因此我们可以不用直接访问目的站点,访问缓存也可以达到提取数据的目的。访问Google cache的方式:http://webcache.googleuserconent.com/search?q=cache:查询的网址
然后我们只需要写个中间件将Request中的URL替换成Goolge Cache下的URL即可。
5.4 Scrapy 爬取期刊元数据
期刊元数据爬虫可以遵循标准Scrapy项目方法,使用startproject创建scrapy项目方法。编写至少items.py、pipelines.py、settings.py三个文件修改,编写蜘蛛spider.py,调试并运行。下面实例是对cnki中文期刊上地方特产频道所有文章题录信息进行爬取,用于当当网文章题录信息全面数据分析。
创建cnki的Scrapy项目:
$ scrapy startproject cnki
创建好项目后,我们分别修改item、pipeline和setting文件
5.4.1 编写items.py
dangdang项目的items.py修改为:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class paperItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field() #论文名
writer = scrapy.Field() #作者
keywords = scrapy.Field() #关键字
abstract = scrapy.Field() #摘要
publisher = scrapy.Field() #出版社
reference = scrapy.Field() #参考文献
Items.py编写好后,就定义好了我们需要关注的结构化数据。
5.4.2 编写pipelines
对抓取的数据进行进一步处理,需要修改pipelines.py,我们将爬取到的数据保存到JSON文件中,pipelines.py需要修改为:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import codecs
import json
class DangdangPipeline(object):
def __init__(self):
#打开data.json文件
self.jsonfile = codecs.open("dangdang.json", "wb", encoding="utf-8")
def process_item(self, item, spider):
#
i = json.dumps(dict(item), ensure_ascii=False)
line = i + '\n'
#将数据写入mydata.json文件
self.jsonfile.write(line)
return item
def close_spider(self, spider):
#关闭data.json文件
self.jsonfile.close()
5.4.3 编写setting
修改setting配置文件,开启pipelines:
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'cnki.pipelines.CnkiPipeline': 300,
}
禁用cookies:
# Disable cookies (enabled by default)
COOKIES_ENABLED = False
解除robots.txt 文件禁制我们爬取:
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
5.4.4 编写自动爬虫
当当spider.py爬虫代码如下:
# -*- coding: utf-8 -*-
import scrapy
from cnki.items import cnkiItem
from scrapy.http import Request
class DangspiderSpider(scrapy.Spider):
name = 'ckiSpider'
allowed_domains = ['cnki.net']
start_urls = ['http://cnki.net/']
def parse(self, response):
item = CnkiItem()
item["title"] = response.xpath("//a[@class='pic']/@title").extract()
item["writer"] = response.xpath(
"//span[@class='writer_n']/text()").extract()
item["keywords"] = response.xpath("//a[@class='pic']/@title").extract()
item["abstract"] = response.xpath("//a[@class='pic']/@title").extract()
item["publisher"] = response.xpath("//a[@class='pic']/@title").extract()
item["reference"] = response.xpath("//a[@class='pic']/@title").extract()
# 提取完后返回item
yield item
# 接下来,通过循环自动爬取100页数据
for i in range(1, 101):
url = "http://ccnki.net/" + \
str(i) + "-cid4002203.html"
# 通过yield返回Request, 并指定要抓取的网址和回掉函数,实现自动爬取
yield Request(url, callback=self.parse)
5.4.5 调试和运行
使用Scrapy crawl命令运行爬虫,可能会失败,这时我们需要查找问题。打开爬取到的数据cnki.json,如下表所示:
观察结果,我们发现每一行存储一页文章题录的数据,而每一页会有多个,comnum键中存储的每一页中所有的文章题录评论数信息,comnum键对应的值是一个列表,列表中分别存储当前页中各文章题录的评论数,每个元素对应一个文章题录。同样,price键中存储每一页中所有文章题录的信息,link键中存储的是每一页中所有文章题录的信息,name键中存储的是每一页中所有文章题录的名称信息。
我们觉得结果混乱,希望title、writer、abstract、keywords、reference、publisher等键值只对应一个文章题录的信息。需要修改pipelines.py文件,修改结果如下:
import codecs
import json
class CnkiPipeline(object):
def __init__(self):
# 存储在文件dangdang-2.json
self.jsonfile = codecs.open("cnki.json", "wb", encoding="utf-8")
def process_item(self, item, spider):
#item = dict(item)
#price(len(item["name"]))
#每一页中包含多个文章题录信息,所以可以通过循环,每一次处理一个文章题录
#其中len(item["name"])为当前页中文章题录的总数,依次遍历
for j in range(0, len(item["name"])):
#当前的第j个文章题录的名称为name,...
title = item["title"][j]
writer = item["writer"][j]
keywords = item["keywords"][j]
abstract = item["abstract"][j]
pulisher = item["publisher"][j]
reference = item["reference"][j]
#重新组合一个字典
goods = {"title":title, "writer":writer, "keywords"
:keywords, "abstract": abstract,"publisher":publisher, "reference"
:reference }
i = json.dumps(dict(goods), ensure_ascii=False)
line = i + '\n'
# 将数据写入mydata.json文件
self.jsonfile.write(line)
return item
def close_spider(self, spider):
# 关闭data.json文件
self.jsonfile.close()
再次运行该爬虫,输出结果cnki.json。可以看到,爬取的数据每一行存储一个文章题录的信息,分别包含该文章题目、作者、关键字、摘要、参考文献、出版社等信息。

