科学知识图谱绘制的大数据挖掘方法-1
新兴学科科学知识图谱绘制的大数据挖掘方法和实现 -1
金刀客
0. 科学知识图谱
0.1 科学知识图谱概念
学知识图谱(下简称知识图谱)是以科学文献知识为对象,以文献计量学、信息计量学、网络计量学、知识计量学和科学计量学的理论方法为基础,显示学科或领域发展进程与结构关系的一种图形,具有“图”和“谱”的双重性质与特征,是一种复杂网络结构图。知识图谱作为一种有效的、综合性的可视化分析方法和工具,被广泛应用并取得了较可靠的结论,被越来越多的学者所重视。通过知识图谱较形象、定量、客观、真实地显示一个学科的结构、热点、演化与趋势,无疑为学科的基础研究提供了一种新的视角。
与一般计算机图的结构相比,复杂网络的复杂性最主要表现在节点数目庞大,通常达到几千甚至几万个。因此,复杂网络的结构比一般的计算机图的结构要复杂得多。复杂网络可以用来描述人与人之间的社会关系、物种之间的捕食关系、计算机之间的网络联接、词与词之间的语义联系、科学家之间的合作关系、科研文章之间的引用关系,以及网页的链接结构等等。
科学知识图谱主要用于对研究热点、研究前沿、研究趋势、知识结构和科学领域结构进行探索。研究前沿是正在兴起的理论趋势和新主题的涌现,共引网络则组成了知识基础。在分析中可以利用从文献题目、摘要等部分提取的突发性术语与共引网络的混合网络来进行分析。
研究热点可以认为是在某个领域中学者共同关注的一个或者多个话题,从“研究热点”的字面理解,它具有很强的时间特征。一个专业领域的研究热点保持的时间可能有长有短,在分析时要加以注意。
关于学科领域结构的研究视角,笔者认为最直接的方法是是使用科学领域的贡献网络进行分析,但这些结果是宏观的,还可以结合期刊的共被引聚类进行分析。
目前应用领域主要集中在图书馆与档案管理、管理科学与工程、安全科学以及教育学等领域。
0.2 知识图谱主要工具
围绕科学知识图谱的绘制,学者和工程师们开发了很多有用的绘制工具,如Citespcae、Bibexcel、Pajek、Ucinet、HistCite和Sci2等
| 软件名称 | 开发者 | 功能描述 | 推荐指数 |
|---|---|---|---|
| CiteSpace | Chaomei Chen | 科学计量与可视化分析 | ★★★★★ |
| VOSViewer | Van Eck, N.J | 科学计量与可视化分析 | ★★★★★ |
| SCI2 | Katy Borner团队 | 科学计量与可视化分析 | ★★★★★ |
| SciMat | M.J.Cobo,A.G | 科学计量与可视化分析 | ★★★★ |
| Loet_Tools | Leydesdorff | 科学计量与可视化分析 | ★★★★ |
| BibExcel | Olle Persson | 科学计量与可视化分析 | ★★★★ |
| HistCite | Eugene Garfield | 科学计量与引证网络 | ★★★★ |
| CiteNetExplore | Van Eck, N.J等 | 引证网络及可视化 | ★★★★★ |
| Publish or Perish | Anne Wil Harzing | 谷歌学术数据采集及分析 | ★★★ |
| Mapequation | Daniel Edler等 | 网络及演化的可视化 | ★★★ |
| Gephi | 网络可视化分析 | ★★★★★ | |
| Pajek | V Batagelj等 | 网络可视化分析 | ★★★★★ |
| NetDraw | Borgatti, S.P | 网络可视化分析 | ★★★ |
| Cyoscape | 网络可视化分析 | ★★★ | |
| Ucinet | Borgatti, S.P | 网络文件的统计分析 | ★★★ |
| BICOMB | 崔雷等 | 矩阵的提取和统计 | ★★★ |
| SATI | 刘启元 | 矩阵的提取和统计 | ★★★ |
| Carrot2 | Audilio Gonzales | 辅助文本可视化 | ★★★ |
| Jigsaw | John Stasko团队 | 辅助文本可视化 | ★★★ |
| GPS Visualizer | 辅助地理可视化 | ★★★ |
0.3 CiteSpace
CiteSpace 是国际著名信息可视化专家、美国德雷塞尔大学(Drexel_University)信息科学与技术学院陈超美教授和团队研发的一款用于分析和可视共现网络的Java应用程序。CiteSpace近年来在中国广泛使用,大连理工大学等多所中国院校使用CiteSpace展开了不同程度的研究,并将国内的CNKI、CSSCI等数据源成功应用到了CiteSpace中。
有学者认为,根据引文半衰期的明显不同,科学文献可分为持续高被引的经典文献和在短暂时间内达到被引峰值的过渡文献。研究前沿可以被理解为过渡文献,知识基础则是这些过渡文献的引文。CiteSpace就是利用“研究前沿术语的贡献网络”、“知识基础文章的同被引网络”、“研究前沿术语引用知识基础论文网络”这三个网络随着时间演变来寻找研究热点和趋势,并用可视化方式展示出来。
CiteSpace最初以Webof Science导出的题录数据为主要数据源,探讨科学文献可视化的模式和发展趋势。使用的题录字段主要有:Author(作者)、Title(标题)、Abstract(摘要)、Keyword(关键字)、Country(国家)、Institution(机构)、Reference_Cited(参考文献)、Journal(期刊)、Category(分类)等。
CiteSpace不仅适用于自然科学领域还适用于社会科学领域,但自然科学的新理论、新发现要比社会科学相对频繁,研究内容变化幅度要比社会科学相对较大,变化趋势较容易捕捉。
0.4 Bibexcel
Bibexcel软件是瑞典于默奥大学(Umeå_University)Olle_Persson教授设计开发的一款软件,主要用于辅助用户分析书目数据或者格式相近的自然语言文本,生成的数据文件可导出到Excel或其他可以处理Tab键隔开数据的程序中。Bibexcel是免费软件,包括一系列工具,这些工具一些可以在程序窗口中看到,一些被设置在菜单中。
Bibexcel软件与其帮助文档均可从于默奥大学官方网站进行下载,http://www.soc.umu.se/english/research/bibexcel/。早期在Windows系统中安装Bibexcel软件需要将Bibexcel程序放在C:\bibexcel目录下,但现在可以将其放在任何磁盘和目录下。Bibexcel还可以在Linux系统利用“wine”命令进行运行。如果运行中需要附加文件,可以根据提示在互联网中进行下载。
Bibexcel利用汤森路透旗下Web_of_Science平台中的SCI、SSCI和A&HCI3个引文库中的数据进行分析,也可以转换其他格式的数据。利用Bibexcel可以进行文献计量分析(bibliometric)、书目计量分析(bibliometry)、引文分析(citation_analysis)、共引分析(co-citation)、文献共享(shared_references)、书目耦合(bibliographic_coupling)、聚类分析(cluster_analysis)、绘制文献图谱(prepare_bibliometric_maps)等。
Bibexcel软件可视化功能不够强大,但是研究人员可以将输出数据应用到Pajek、Ucinet、NetDraw或者SPSS中。Bibexcel软件只能得到共现矩阵,可以生成作者合作、文献共引的共现文件,可以将这些文件转换成Pajek(免费软件)可用的文件,以便利用其进行分析和可视化。Bibexcel还可以为Pajek生成clu-files和vec-files。
0.5 Pajek
Pajek在斯洛文尼亚语中是“蜘蛛”的意思。Pajek软件是有斯洛文尼亚卢布尔雅纳大学的Vladimir Batagelj和Andrej Mrvar两位教授共同编写的免费软件。
下载地址:http://mrvar.fdv.uni-lj.si/pajek/
wos2pajek(以下简称w2p)是pajek 的作者Vladimir_Batagelj为了更加有效的处理wos上的记录数据而开发出的一款小程序,用它可以对从wos上下载的全纪录进行预处理,生成若干直接用pajek进行分析的文件,如果没有这款软件,用pajek对大型引文网络的分析将是几乎不可能的(不排除还有其他软件,但我目前还不知道)。目前w2p目前最新的版本是0.8版wos2pajek8.zip,下载地址:http://vlado.fmf.uni-lj.si/pub/networks/pajek./WoS2Pajek/default.htm
费弗尔(Jurgen Pfeffer)编写了两个Windows应用程序,用于帮助创建Pajek网络文件。Txt2pajek 下载地址:http://www.pfeffer.at/txt2pajek/
Pajek软件的结构基于六大数据类型:
- (1)Networks(网络)Networks主要对象是结点和边,数据文件的默认扩展名是.net。
- (2)Partitions(分区)Partition指明了每个结点分别属于哪个区,数据文件的默认扩展名是.clu。
- (3)Permutations(排序)Permutations将结点重新排列,数据文件的默认扩展名是.per。
- (4)Cluster(类)Cluster是指结点的子集,数据文件的默认扩展名是.cls。
- (5)Hierarchy(层次)Hierarchy是指按层次关系排列的结点,数据文件的默认扩展名是.hie。
- (6)Vectors(向量)Vectors是指每个结点具有的数字属性(实数),数据文件的默认扩展名是.vec。
Pajek可以读取多种纯文本格式的网络数据或含有未格式化文本(ASCII)的文件,Pajek2.0以上版本还支持Unicode UTF-8编码格式的标签,这可以让用户用任何语言文字系统来编辑标签。
创建Pajek数据输入文件有多种方法,用户可以在Pajek软件中手动创建,可以利用辅助软件创建,还可以利用关系型数据库创建。
Pajek软件操作基本流程:
- (1)在Pajek软件中选择Network—Create Random Network—Total No. of Arcs命令生成一个含指定数量顶点但不含连线的网络文件,然后在字处理软件中编辑顶点标签和增加连线即可;
- (2)Jurgen Pfeffer编写了两个Pajek辅助软件createPajek.exe和txt2Pajek.exe,前者可以从Microsoft Excel工作表中读取数据,后者可以从纯文本文件中读取数据,比前者提供了更灵活的设置和选项,运算速度也比前者快;
- (3)Pajek官网提供了一个Microsoft Acess空白数据库模板(network.mdb),用户可以构建1-Mode和2-Mode网络所需的“表”、“查询”、“报表”三种内容。
Pajek可处理结点数高达百万的大型网络,同时具有网络分析和可视化功能,还可以将一个大型网络分解为多个、可以独立显示的子网络,有助于进行进一步的精确分析;它还为使用者提供了有效的分析算法和强大的可视化工具,提供给了一个可视化的界面,帮助用户更加直观地了解各种复杂网络的结构。
与其他社会网络可视化软件相比较,Pajek具有以下特点:
- (1)快速有效
一个算法的复杂度主要表现时间复杂度和存储空间复杂度两个方面。Pajek为用户提供了一整套快速有效的、分析复杂网络的算法,用以计算和分析数以万计结点数的大型复杂网络。 - (2)可视化
Pajek为用户提供了一个界面友好的可视化平台。用户不仅可以快速绘制出一张网络图,还可以根据自己的需要对网络图进行精细调整,从而允许用户从视觉的角度更加直观的分析复杂网络特性。 - (3)抽象化
Pajek可以将复杂网络的全局结构进行抽象,将联系紧密的结点归为一类。每个类看成一个整体,将它作为新的结点得到一个新的网络图。新的网络图中各个类之间通过少数几条边相连接,可以很容易看出整个网络的整体结构。
0.6 Ucinet
Ucinet(University_of_California_at_Irvine_NETwork)是目前流行一种功能强大的社会网络分析软件,它最初由加州大学欧文(Irvine)分校的社会网络研究学者Linton_Freeman编写,后来主要由美国波士顿大学的Steve_Borgatti和英国威斯敏斯特大学(Westminister_University)的Martin Everett 维护更新。下载地址:http://www.analytictech.com/downloaduc6.htm。
该软件集成了一维和二维数据分析工具NetDraw、三维数据分析工具Mage,同时集成了用于大型网络分析的Pajek。利用UCINET可以读取文本文件、数据语言数据(DL)、初始数据(RAW)、KrackPlot、Pajek、Negopy、VNA等格式的文件,还能读取Excel数据,但Ucinet处理的Excel数据最多只能有255列。利用Ucinet可以输出数据语言数据(DL)、初始数据(RAW)、Excel数据和图形。
Ucinet包括大量的网络分析指标(如中心度,二方关系凝聚力测度,位置分析算法,派系的探查等),随机二方关系模型(stochastic_dyad_models),对网络假设进行检验的程序(包括QAP 矩阵相关和回归,定类数据和连续数据的自相关检验等),还包括一般的统计和多元统计分析工具,如多维量表multidimensional_scaling),对应分析(correspondence_analysis)、因子分析(factor_analysis)、聚类分析(cluster_analysis)、多元回归(multiple_regression)等。除此之外,UCINET 还提供大量数据管理和转换的工具,可以从图论程序转换为矩阵代数语言。
Ucinet可以处理32767个网络节点,但从实际操作来看,当节点数在5000~10000之间时,一些程序的运行就会很慢。在Ucinet6.0中,全部数据都用矩阵形式存储、展示和描述。
Ucinet提供大量的数据管理和转换工具,如选择子集、合并数据集、序化、转化或者记录数据。Ucinet不包含可视化的过程,但是它与软件Mage、NetDraw和Pajek集成在一起,从而能够实现可视化。NetDraw是简单的绘制网络图的工具,它可以读取Ucinet系统文件、Ucinet文本文件、Pajek文本文件等。它可以同时处理多种关系,并可以根据结点的特性设置结点的颜色、形状和大小,并可做数据分析,如中心性分析、子图分析、角色分析等,也具有很强的矩阵运算能力,是一个非常灵活的可视化软件。
Ucinet在进行任何分析之前,必须创建一个Ucinet数据集。Ucinet有三种常用数据结构:初始数据文件(Raw Data File)、Excel文件数据、数据语言文件(DL File):
- (1)初始数据文件(Raw_Data_File),仅仅包含数字,不包含数据的行数、列数、标签、标题等信息,因而只能以矩阵的形式输入。
- (2)Excel文件数据,可以通过Excel数据进行编辑,但最多能支持65536行和255列。
- (3)数据语言文件(DL_File),包含一系列数字(数据)、描述数据的很多关键词和语句等,都是关于数据的基本信息。数据文件正文的内容一定要用DL表明该文件是数据文件。DL数据文件的格式还有全矩阵格式、长方形矩阵、多个矩阵、对角线缺失值矩阵、左半矩阵或者右半矩阵、块矩阵、关联列格式等。各个形式的矩阵都有表示矩阵类型的关键字和输入模式。
1. 大数据分析和挖掘简介
1.1 数据挖掘
大数据分析的基础是数据挖掘。数据挖掘的基本任务包括分类与预测、聚类分析、关联规则、时序模式、偏差检测和智能推荐等。本过程为:定义目标、数据采集、数据整理、构建模型、模型评价和模型发布。数据挖掘建模过程如图所示:
定义数据挖掘目标
针对具体的挖掘应用需求,首先明确本次挖掘目标,要达到的挖掘效果。
- 数据抽样
对数据进行抽样需要注意相关性、可靠性和有效性。衡量采样数据质量的标准包括:资料完整无缺、数据准确无误、随机抽样、等距抽样、分成抽样、顺序抽样和分析类抽样
- 数据探索
数据探索分为:数据质量分析和数据特征分析
数据质量分析包括:缺失值分析、异常值分析、数据一致性分析
数据特征分析包括:分布分析、对比分析、统计量分析、周期分析、贡献度分析和相关性分析
- 数据预处理
数据预处理主要包括:数据清洗、数据集成、数据变换、数据规约
数据清洗主要是删除原始数据集中的无关数据、重复数据,平滑噪声数据,筛选数据,处理缺失和异常值等。
数据集成是将多个数据源合并放在一个一致的数据存储(如数据仓库)中的过程。
数据变换主要是对数据进行规范化处理,将数据转换为“适当的”形式,以适用于数据挖掘任务及算法的需要。常用的数据变换方法有:简单函数变换、规范化、连续属性离散化、属性构造和小波变换等。
数据规约可以降低无效、错误数据对模型的影响,提高建模的准确性;缩减数据挖掘所需时间;降低存储数据成本。其方法主要有:属性规约和数值规约。
- 构建模型
经过数据探索和数据预处理,得到可以直接建模的数据。根据挖掘目标和数据形式可以建立分类与预测、聚类分析、关联规则、智能推荐等模型。
这四种模型在学科知识图谱绘制的过程中都有涉及。
- 模型评价
模型评价的目的就是从建立的各种模型中找出最好的模型,并根据业务要求对模型进行解释和应用。分类与预测模型的评测方法是:用没有参与建模的评测数据集评价预测的准确率。模型预测效果评价通常用相对绝对误差、平均绝对误差、根均方差、相对平方根误差等指标来衡量。聚类分析根据样本数据本身将样本分组。其目标是,组内的对象相互之间是相似的(相关的),而不同组的对象是不同的(不相关的)。组内相似性越大,组间差别越大,聚类效果越好。
- 可视化展示
1.2 大数据挖掘
大数据指无法在一定时间内用常规软件工具对其内容进行处理的数据集。大数据主要特点是4V,即数据量大(Volumn)、数据类型复杂(Variety)、数据处理数据块(Velocity)、数据真实性高(Veracity)。大数据分析是指不用随机分析法(抽样调查),而采用所有数据进行分析处理。(《大数据时代》)。大数据技术包括大规模并行处理数据库、大数据挖掘、分布式文件系统、分布数据库、云计算平台等等。
在大数据处理上,Hadoop已经成为事实上的标准。几乎所有的大型软件提供商都采用Hadoop作为其架构基础。Spark作为用来替代Map_Reduce的大数据内出计算框架,也是目前流行的框架。后面我们会对这两种技术分别作以介绍。
2 大数据处理技术
2.1 Hadoop大数据平台
Hadoop是Apache基金会旗下的一个开源分布式计算平台。Hadoop以分布式文件系统HDFS和Map_Reduce为核心,为用户提供系统底层细节透明的分布式基础架构。分布式文件系统HDFS的高容错性、高伸缩性等优点允许用户将Hadoop部署在低廉的硬件上,形成分布式文件系统;MapReduce分布式编程模型允许用户在不了解分布式系统底层细节的情况下开发并行应用程序。所以用户可以利用Hadoop轻松地组织计算机资源,简便、快速地搭建分布式计算平台,并且可以充分利用集群的计算和存储能力,完成海量数据的处理。
Hadoop2.x版本包含以下模块:Hadoop通用模块,支持其他Hadoop模块的通用工具集;Hadoop分布式文件系统Hadoop_HDFS,支持对应用数据高吞吐量访问的分布式文件系统;Hadoop_YARN,用于作业调度和集群资源管理的框架;Hadoop_MapReduce,基于YARN的大数据平行处理系统。
Hadoop生态系统主要包括:Hive、HBase、Pig、Sqoop、Flume、Zookeeper、Mahout、Spark、Storm、Shark、Phoenix、Tez、Ambari等。下图为Hadoop的整个生态系统。

- Hive:用于Hadoop的一个数据仓库系统,提供类似于SQL的查询语言,通过使用该语言,可以方便地进行数据汇总,特定查询以及分析存放在Hadoop兼容文件系统中的大数据。
- HBase:一种分布的、可伸缩的、大数据存储库,支持随机、实时读写访问
- Pig:分析大数据集的一个平台,该平台由一种表达数据分析程序的高级语言和对这些程序进行评估的基础设施一起组成。
- Sqoop:为高效传输批量数据而设计的一种工具,其用于Hadoop和结构化数据存储数据库如关系数据库之间的数据传输。
- Flume:一种分布式的、可靠的、可用的服务,其用于高效搜集、汇总、移动大量日志数据
- Zookeeper:一种集中服务,其用于维护配置信息,命名,提供分布式同步,以及提供分组服务。
- Mahout:一种基于Hadoop的机器学习和数据挖掘的分布式计算框架算法集,实现了多种MapReduce模式的数据挖掘算法。
- Spark:一个开源的数据分析集群计算框架,最初由加州大学伯克利分校AMPLab实验室开发。Spark与Hadoop一样,用于构建大规模、低延时的数据分析应用。Spark采用Scala语言实现,使用Scala最为应用框架。
- Shark:即Hive on Spark, 一个专门为Spark打造的大规模数据仓库系统,兼容Apache Hive。无需修改现有的数据,就可以实现相对于Hive SQL100倍的提升。Shark支持 Hive查询语言、元存储、序列化格式以及自定义函数、与现有Hive部署无缝集成,是一个更快、更强大的替代方案。
- Phoenix:一个构建在HBase之上的SQL中间层,完全使用Java编写,提供一个客户端可嵌入的JDBC驱动。
- Tez:一个基于Hadoop YARN之上的DAG(有向无环图)计算框架。它把Map/Reduce过程拆分成若干个子过程,同时可以把多个Map/Reduce任务组合成一个较大的DAG任务,减少MapReduce之间的文件存储。同时合理组合其子过程,减少任务的运行时间。
- Ambari:一个供应、管理和监视Hadoop集群的开源框架,它提供一个直观的操作工具和一个健壮的Hadoop API, 可以隐藏复杂的Hadoop操作,使集群操作大大简化。
2.1.1 HDFS分布式文件系统
Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件上的分布式文件系统。它和现有的分布式文件系统有很多共同点,但也有很明显的区别。HDFS是一个高容错的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。HDFS开始是作为Apache Nutch搜索引擎项目的基础架构而开发的,目前HDFS是Hadoop Core的一个重要部分。
HDFS采用master/slave架构。一个HDFS集群是由一个Name_Node和一定数量的Data_Node组成的。Name Node是中心服务器,负责管理文件系统的名字空间(name_space)以及客户端对文件的访问。集群中的Data Node一本是一个节点,负责管理它所在的存储。HDFS暴露文件系统的名字空间,用户能够以文件的形式在上面存储数据。从内部看,一个文件其实被分为一个或多个数据块,这些数据块存储在一组Data_Node上。Name_Node执行文件系统的名字空间操作,例如打开、关闭、重命名文件或目录。它也负责确定数据块到具体Data_Node节点映射。Data_Node负责处理文件系统客户端的读写请求。在Name_Node的统一调度下进行数据块的创建、删除和复制。HDFS架构如下图所示:

HDFS数据上传过程如下:
-
- Client端发送一个添加文件到HDFS请求给Name_Node
-
- Name Node告诉Client端如何来分发数据块以及分发的位置
-
- Client端把数据分为块(block),然后把这些块分发到Data_Node中
-
- Data_Node在Name Node的指导复制这些块,保持冗余
2.1.2 MapReduce工作原理
Hadoop_MapReduce是一个快速、高效、简单用于编写并行处理大数据程序并应用在大集群上的编程框架。其前身Google公司MapReduce,MapReduce是Google公司的核心计算模型,它将复杂、运行于大规模集群上的并行计算过程高度地抽象到两个函数:Map和Reduce。适合用MapReduce来处理的数据集,需要满足一个基本要求:待处理数据可以分解成许多小的数据集,并且每个小数据集都可以完全并行地进行处理。概念“Map”(映射)和“Reduce”(规约),都是从函数式编程中借用的,同时也包含从矢量编程中借来的特性。Map_Reduce极大方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
一个Map_Reduce作业通常会把输入的数据集且分为若干独立的数据块,由map任务以完全并行的方式处理它们。框架会对map的输出先进行排序,然后把结果输入给reduce任务。通常,作业的输入和输出都会被存储在文件系统中。整个框架负责任务的调度和监控,以及重新执行已经失败的任务。
通常,MapReduce框架的计算节点和存储节点是运行在一组相同的节点上的,也就是说,运行MapReduce框架和运行HDFS文件系统的节点通常是一起的。这种配置允许框架在那些已经存好数据节点上高效地调度任务,这可以使整个集群的网络带宽被非常高效的利用。
MapReduce框架包括一个主节点(Resource_Manager)、MRAppMaster(每个任务一个)和多个子节点(Node_Manager)共同组成。应用程序至少应该指明输入/输出的位置(路径),并通过实现合适的接口或抽象类提供map和reduce函数,再加上其他作业的参数,就构成了作业配置。Hadoop的job client提交作业和配置信息给Resource_Manager,后者负责分发这些软件和配置信息给slave、调度任务且监控它们的执行,同时提供状态和诊断信息给job_client。
虽然Hadoop框架是用Java实现,但MapReduce应用程序则不一定用Java,可以使用Ruby、Python和C++来编写。MapReduce框架流程图如图所示。

Map阶段:
- InputFormat根据输入文件产生键值对,并传送到
Mapper类的map函数中; - Map输出键值对到一个没有排序的缓存内存中;
- 当缓冲内存到达给定值或map任务完成,在缓冲内存中的键值对就会被排序,然后输出到磁盘中的溢出文件;
- 如果有多个溢出文件,那么就会整合这些文件到一个文件,并排序;
- 这些排序过的、在溢出文件中的键值对会等待Reducer的获取。
Reduce阶段:
- Reducer获取Mapper的记录,然后产生另外的键值对,最后输出到HDFS中;
- shuffle:相同的key被传送到同一个Reducer中
- 当有一个Mapper完成后,Reducer就开始获取相关数据,所有的溢出文件会被排序到一个内存缓冲区中
- 当内存缓冲区满了后,就会产生溢出文件到本地磁盘
- 当Reducer所有相关的数据都传输完成后,所有溢出文件就会被整合和排序-+
- Reducer中的reduce方法针对每个key调用一次
- Reducer的输出到HDFS
2.1.3 YARN工作原理
经典的Map_Reduce的最严重的限制主要关系到可伸缩性、资源利用和对与MapReduce不同的工作负载的支持。在Map_Reduce框架中,作业执行受到两种类型的进程控制:一个称为Job_Tracker的主要进程,它协调在集群上运行的所有作业,分配要在Task_Tracker上运行的map和reduce任务。另一个就是许多Task_Tracker的下级进程,它们运行分配的任务并定期向Job_Tracker报告进出。
为了解决该瓶颈,Yahoo工程师提出了一种新的架构YARN(MPv2).YARN是下一代Hadoop计算平台,主要包括Resource_Manager、Application_Master、Node_Manager,其中Resource_Manager用来代替集群管理器,Application_Master代替一个专用且短暂的Job_Tracker, Node_Tracker代替Task_Tracker。
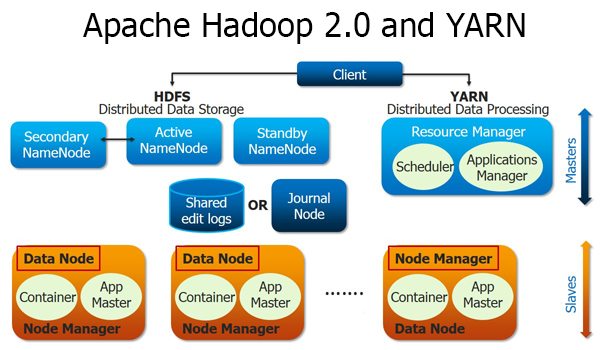
YARN最核心的思想就是将Job_Tracker两个主要的功能分离成单独的组件,这两个功能是资源管理和任务监控和调度。新的资源管理器全局管理所有应用程序计算资源的分配,每个应用的Application_Master负责响应的调度和协调。一个应用程序要么是一个单独的传统的Map_Reduce任务或者是一个DAG(有向无环图图)任务。Resource_Manager和每一台机器的节点管理服务器(Node_Manager)能够管理用户再那台机器的进程并能对计算进行组织。事实上,每个应用的Application_Master是一个特定的框架库,它和Resource_Manager来协调资源,和Node_Manager的协同工作以运行和监控任务。
Resource_Manager有两个重要的组件:Scheduler和Application_Manager。
-
Scheduler负责分配资源给每个正在运行的应用,同时需要注意Scheduler是一个单一的分配资源的组件,不负责监控或者跟踪任务状态的任务,而且它不保证重启失败任务。
-
Application_Manager注意负责接受任务的提交和执行应用的第一个容器Application_Master协调,同时提供当任务失败时重启的服务。
客户端提交任务到Resource_Manager的Application_Manager,然后Scheduler在获得集群各个节点的资源后,为每个应用启动一个Application_Master,用于执行任务。每个Application_Master启动一个或多个Container用于实际执行任务。
2.1.4 HBase
HBase是一个分布式的、面向列的开源数据库,该技术来源于Fay_Chang所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File_System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
HBase是Google_Bigtable的开源实现,类似Google_Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop_HDFS作为其文件存储系统;Google运行Map_Reduce来处理Bigtable中的海量数据,HBase同样利用Hadoop_MapReduce来处理HBase中的海量数据;Google_Bigtable利用 Chubby作为协同服务,HBase利用Zookeeper作为对应。

上图描述Hadoop_EcoSystem中的各层系统。其中,HBase位于结构化存储层,Hadoop_HDFS为HBase提供了高可靠性的底层存储支持,Hadoop_MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和failover故障恢复机制。
此外,Pig和Hive还为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变的非常简单。 Sqoop则为HBase提供了方便的RDBMS数据导入功能,使得传统数据库数据向HBase中迁移变的非常方便。
2.1.5 Impala
Impala是Cloudera公司主导开发的新型查询系统,它提供SQL语义,能查询存储在Hadoop的HDFS和HBase中的PB级大数据。已有的Hive系统虽然也提供了SQL语义,但由于Hive底层执行使用的是MapReduce引擎,仍然是一个批处理过程,难以满足查询的交互性。相比之下,Impala的最大特点也是最大卖点就是它的快速。Impala架构如下所示:

其优点:
-
- Impala不需要把中间结果写入磁盘,省掉了大量的I/O开销。
-
- 省掉了MapReduce作业启动的开销。MapReduce启动task的速度很慢(默认每个心跳间隔是3秒钟),Impala直接通过相应的服务进程来进行作业调度,速度快了很多。
-
- Impala完全抛弃了Map_Reduce这个不太适合做SQL查询的范式,而是像Dremel一样借鉴了MPP并行数据库的思想另起炉灶,因此可做更多的查询优化,从而省掉不必要的shuffle、sort等开销。
-
- 通过使用LLVM来统一编译运行时代码,避免了为支持通用编译而带来的不必要开销。
-
- 用C++实现,做了很多有针对性的硬件优化,例如使用SSE指令。
-
- 使用了支持Data_locality的I/O调度机制,尽可能地将数据和计算分配在同一台机器上进行,减少了网络开销。
2.2 Spark大数据计算引擎
Apache_Spark是专为大规模数据处理而设计的快速通用的计算引擎。它也是本书使用的核心计算框架,几乎所有的流程都在该框架完成。
Spark是UC_Berkeley_AMP_lab(加州大学伯克利分校的AMP实验室)所开源的类Hadoop_MapReduce的通用并行框架,Spark拥有Hadoop_MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的Map_Reduce的算法。Spark主要特点是进行内存计算,但即使必须在磁盘上进行复杂计算,Spark也比Map_Reduce更加高效。
Spark适用于各种各样的分布式应用场景,如批处理、迭代计算、交互式查询、流处理。通过在一个统一的框架支持这些不同的计算,Spark使我们可以简单而低耗的把各种流程整合在一起。
Spark提供丰富的借口。Spark除提供基于Pyton、Java、Scala、R和SQL等语言的简单易用的API还内建了丰富的函数库,还可以和其他大数据工具密切配合使用。如spark可以运行在Hadoop集群上,本书就是用这种模式。
Spark 主要有三个特点:
- 高级 API 剥离了对集群本身的关注,Spark 应用开发者可以专注于应用所要做的计算本身。
- Spark 很快,支持交互式计算和复杂算法。
- Spark 是一个通用引擎,可用它来完成各种各样的运算。
Spark的基本架构如下图所示:

Spark可以分为Spark_Core、Spark_SQL、Spark_Streaming、Spark_GraphX、Spark_MLlib和集群管理器组成。
2.2.1 Spark Core
Spark_Core实现了Spark的基本功能,包括任务调度、内存管理、错误恢复和与存储系统交互等模块。Spark Core中还包括对弹性分布式数据集(RDD)API定义。RDD表示分布在多个计算节点上可以并行操作的元素集合,是Spark主要的编程抽象。它提供了创建和操作这些集合的多个API。
2.2.2 Spark SQL
Spark_SQL是Spark用来操作结构化数据的程序包。通过它我们可以使用SQL或Hive版本的HQL来查询数据。Spark SQL提供多种数据源,比如Hive表和JSON等。除了为Spark提供一个SQL接口,它还支持开发者将SQL和传统的RDD编程数据操作方式相结合,无论Scala、Pyton还是JAVA,开发者都可以在单个应用中同事使用SQL和复杂的数据分析。
2.2.3 Spark Streaming
Spark_Streaming提供了对实时数据进行流式计算的组件,如日志或队列消息等。Spark_Streaming提供了用来操作数据流的API,并且与RDD_API高度对应。
2.2.4 Spark MLlib
Spark_MLlib是Spark提供的机器学习功能库。MLlib提供了多种机器学习算法,包括分类、回归、聚类和协同过滤等,还提供了模型评估、数据导入等额外的功能支持。MLlib还提供了一些更底层的机器学习原语,包括一个通用的梯度下降优化算法。所有这些方法都被设计为可以在集群上轻松伸缩的架构。
2.2.5 Spark GraphX
Spark_GraphX是用来操作图(如社交关系图)的程序库,可以进行并行的图计算。GraphX也扩展了RDD_API,能用来创建一个顶点和边都包括任意属性的有向图。GraphX还支持针对图的各种操作,比如进行图分割subgraph和操作所有与顶点map_Vertices,以及PageRank和三角计数等。
2.2.6 集群管理器
对于底层而言,Spark被设计成可以高效在一个到数千个计算节点之间进行伸缩计算。为了实现这样的要求,同时获得最大的灵活性,Spark支持在各种集群管理器上运行,如Hadoop_Yarn、Apache_Mesos、以及Spark自有的简单调度器。本书采用的就是Yarn集群管理器,它也是目前主流的集群管理器。
3 大数据挖掘方法
大数据挖掘基本可继续使用数据挖掘中成熟的方法,但要在实现中体现大数据海量存储和分布式、并行化处理的特点。常用的方法是有:统计学分析、分类和回归分析、聚类分析、图分析和关联规则分析等。
3.1 大数据分析统计学方法
Spark中的mllib.stat.Statistcs类中提供了几个常用的统计学函数包括:统计综述、平均值、求和、相关矩阵、皮尔森独立性测试。
- Statistics.colStats(rdd) 计算由向量组成的RDD的统计性综述,包括:每列的最小值、最大值、平均值和方差,信息十分丰富。
- Statistics.corr(rdd, method) 计算由向量组成的RDD中的列间的相关矩阵,可以使用皮尔森或斯皮尔斯曼相关中的一种
- Statistics.corr(rdd1, rdd2, method) 计算两个由浮点组成的RDD的相关矩阵,可以使用皮尔森或斯皮尔斯曼相关中的一种
- Statistics.chiSqTest(rdd)计算由LabeledPoint对象组成的RDD中每个特征与标签的皮尔森独立性测试结果。返回一个ChiSqTestRest对象,其中有p值、测试统计以及每个特征的自由度。
另外还有mean(), stdev(), sum(), sample(), sample_By_Key等统计函数
3.2 大数据分类和回归分析
分类与回归是监督学习的两种主要形式。监督学习指算法尝试使用有标签的训练数据根据对象的特征预测结果。分类是预测分类编号(离散属性),回归主要是建立连续值函数模型,预测给定自变量对应的因变量的值。常用的分类和回归算法有:回归分析、决策树、随机森林、贝叶斯网络和支持向量机。
分类和回归都会使用MLlib中的labelPoint类。这个类在mllib.regression包中。一个LabelPoint其实就是一个label(label总是一个Double值,但也可以为分类算法设为离散整数如二元分类中MLlib标签为0或1;多元分类中,MLlib预测标签范围从0到C-1, C为分类数)
MLlib中包含多个分类和回归方法,其中常用的是简单的线性方法、决策树方法和决策森林方法。
3.2.1 线性回归
线性回归是回归中的一种常用方法,指用特征的线性组合来预测输出值。MLlib支持L1和L2的正则回归,通称为Lasso和ridge回归。
线性回归算法可以使用的类包括:
- mllib.regression.LinearRegressionWithSGD
- LassoWithSGD
- RidgeRegressionWithSGD(SGD称为梯度下降算法)
可以优化的参数有
- numIterations:迭代次数(默认:100)
- stepSize:梯度下降的步长(默认:1.0)
- intercept:是否给数据加上一个干扰特征或偏差特征(默认:false)
- regParam:Lasso和Ridge的正则化参数(默认:1.0)
调用算法的方式在Scala中为:
import org.apache.spark.mllib.regression.LableedPoint
import org.apache.spark.mllib.regression.LinearRegressionWithSGD
val points: RDD[LabeledPoint] =
val lr = new LinearRegressionWithSGD().setNumIterations(200).setIntercept(True)
val model = lr.run(points)
println("weight: %s, intercept: %s".format(model.weights, model.intercept))
一旦训练完成,将返回LinearRegressionModel都会包含一个predict函数,可以用来对单个特征向量预测一个值。RidgeRegressionWithSGD和LassoWithSGD相类似,并且会返回一个类似的模型。事实上这种通过setter方法调节算法参数,然后返回一个带有predict方法的Model对象的模式在MLlib中十分常见。
3.2.2 逻辑回归
逻辑回归是一种二分类方法,用来寻找一个分隔阳性和阴性的线性分隔平面。在MLlib中,它接受组标签为0和1的LabeledPoint,返回可以预测新点的分类的LogisticsRegressionModel对象。
逻辑回归算法API和线性回归API十分相似,却别在于两种用来解决逻辑回归的算法:SGD和LBFGS。LBFGS一般是最好的,这个算法通过mllib.classification.LogisticRegressionWithLBFGS和mllib.classification.LogisticRegressionWithSGD类提供给用户,接口和LinearRegressionWithSGD相似,接受的参数这完全一样。这个算法得出的LogisticRegressionModel可以为每个点求出一个在0-1之间的得分,之后会基于一个阈值返回0或1的类别。默认阈值为0.5。可以通过setThreshold设置阈值,可以通过clearThreshold清除阈值。
3.2.3 支持向量机
支持向量机是一种常用的分类方法,使用SVMWithSGD类参数与前面相似,返回SVMModel和LogisticRegressionModel一样使用阈值进行预测。支持向量机被认为是最好的现成分类器,但在大数据计算中却很少使用,因为运算量太大。
3.2.4 朴素贝叶斯
朴素贝叶斯是一种多元分类算法,它使用基于特征的线性函数计算讲一个点分到各类中的得分。MLlib中实现了多项贝叶斯算法,需要非负频次作为输入特征。使用mllib.classification.NaiveBaye类进行分类。它支持一个参数lambda用来进行平滑。可以使用一个LabeledPoint组成的RDD调用朴素贝叶斯算法,对于C个分类。返回的NaiveBayesModel让我们可以使用predict()预测对某个点最合适的分类,也可以访问训练好的模型的两个参数:各特征与各分类的可能性矩阵theta以及表示先验概率的C维向量pi
3.2.5 决策树和决策森林
决策树是一个灵活的模型,可以用来进行分类,也可以用来进行回归。决策树以节点树的形式表示,每个节点基于数据的特征作出一个二元决策,而每个树的叶子节点包含一个预测结果。
在MLlib中使用mllib.tree.DecisionTree类中的静态方法trainClassifier()和trainRegressor()来训练决策树。和其他有些算法不同的是,不适用setter方法定制DecisionTree对象。可调整参数包括:
- data :LabeledPoint组成的RDD
- numClasses:使用类别数量
- impurity:节点不纯净度测量分类为gini或entrogy,回归为variance
- maxDepth:树最大深度(默认为5)
- maxBins:构建各节点将数据分到多少个箱子(推荐:32)
- categoricalFeaturesInfo:一个映射表,用来指定哪些特征是分类的,以及每个多少各类。
- numTree:构建树的数量,提高可以降低过度拟合可能性
- featureSubsetStrategy:每个节点上作决定需要考虑的特征数量,auto、all、sqrt、log2以及onethird中选择,数字越大话费计算越大。
3.3 大数据降维
3.3.1 主成分分析
主成分分析(PCA)会将特征映射到低维空间,让数据在低维空间表示的方差最大化,从而忽略一些无用的维度。要计算出映射,我们要构建出正则化的相关矩阵,并使用这个矩阵的奇异向量和奇异值。与最大部分奇异值和对应的奇异向量可以用来重建原始数据的主要成分。使用mllib.linalg.distributed.RowMatrix类表示矩阵,然后存储为一个Vector组成的RDD,每行一个。下面例子投影RDD包含原始RDD中的points的二维版本,可以用于作图或进行其他MLlib算法如进行聚类。
import org.apache.spark.mllib.linalg.Matrix
import org.apache.spark.mllin.linalg.distributed.RowMatrix
val points: RDD[Vector] = //….
val mat: RowMatrix = new RowMatrix(points)
val pc:Matrx = mat.computePricipalComponents(2)
//投影到低维
val projected = mat.multiply(pc).rows
//在低维进行聚类运算
val model = Kmeans.train(projected, 10)
3.3.2 奇异值分解
奇异值分解也是一种行之有效的降维方法。MLlib提供奇异值分解(SVD)方法。
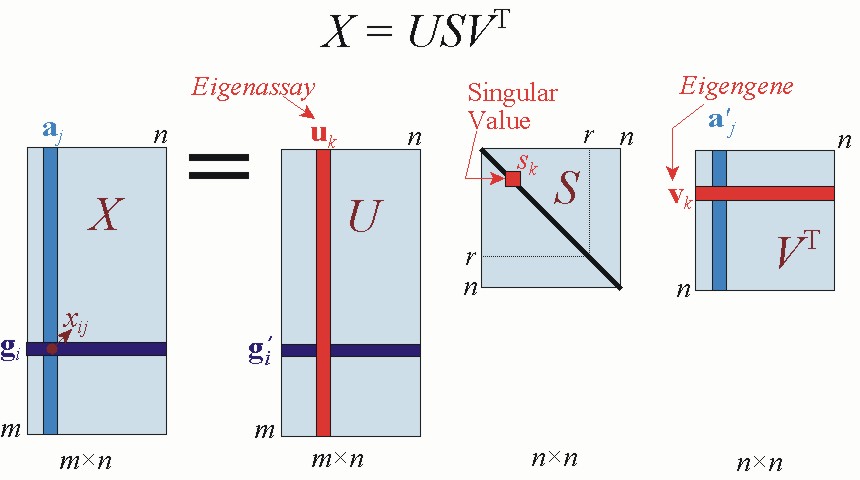
对于大型矩阵,通常不需要进行完全分解,只需要分解出靠前的奇异值与对应的奇异向量即可。这样可以节省存储空间、降噪,并有利于恢复低秩矩阵。
在MLlib中调用RowMatrix类的computeSVD方法
//计算前二十个奇异值
val svd: SingularValueDecomposition[RowMatrix, Matrix] =
mat.computSVD(20, compute=true)
val U:RowMatrix = svd.U
val s: Vector = svd.s
val V: Matrix =svd.V
3.4 基于大数据挖掘的科学知识图谱绘制系统架构
基于大数据挖掘的科学知识图谱绘制系统架构如下图所示:
该系统包括期刊论文元数据抓取、数据预处理、数据存储、大数据分析和大数据可视化等几个模块。后面会对几个模块进行详细介绍。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号