小样本利器5. 半监督集各家所长:MixMatch,MixText,UDA,FixMatch
 在前面章节中,我们介绍了几种半监督方案包括一致性正则,FGM对抗,最小熵原则,mixup增强。MixMatch则是集各家所长,把上述方案中的SOTA都融合在一起实现了1+1+1>3的效果。我们以MixMatch为基准,一并介绍几种衍生方案MixText,UDA,FixMatch
在前面章节中,我们介绍了几种半监督方案包括一致性正则,FGM对抗,最小熵原则,mixup增强。MixMatch则是集各家所长,把上述方案中的SOTA都融合在一起实现了1+1+1>3的效果。我们以MixMatch为基准,一并介绍几种衍生方案MixText,UDA,FixMatch
在前面的几个章节中,我们介绍了几种基于不同半监督假设的模型优化方案,包括Mean Teacher等一致性正则约束,FGM等对抗训练,min Entropy等最小熵原则,以及Mixup等增强方案。虽然出发点不同但上述优化方案都从不同的方向服务于半监督的3个假设,让我们重新回顾下(哈哈自己抄袭自己):
- moothness平滑度假设:近朱者赤近墨者黑,两个样本在高密度空间特征相近,则label应该一致。优化方案如Mixup,一致性正则和对抗学习
- Cluster聚类假设:高维特征空间中,同一个簇的样本应该有相同的label,这个强假设其实是Smoothness的特例
- Low-density Separation低密度分离假设:分类边界应该处于样本空间的低密度区。这个假设更多是以上假设的必要条件,如果决策边界处于高密度区,则无法保证簇的完整和边缘平滑。优化方案入MinEntropy
MixMatch则是集各家所长,把上述方案中的SOTA都融合在一起实现了1+1+1>3的效果,主要包括一致性正则,最小熵,Mixup正则这三个方案。想要回顾下原始这三种方案的实现可以看这里
本章介绍几种半监督融合方案,包括MixMatch,和其他变种MixText,UDA,FixMatch
MixMatch
- Paper: MixMatch: A Holistic Approach to
Semi-Supervised Learning- Github: https://github.com/YU1ut/MixMatch-pytorch
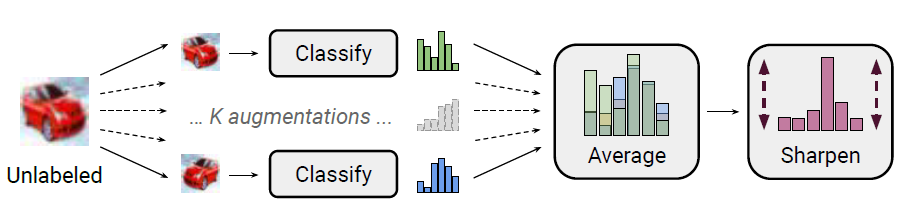
针对无标注样本,MixMatch融合了最小熵原则和一致性正则, 前者最小化模型预测在无标注样本上的熵值,使得分类边界远离样本高密度区,后者约束模型对微小的扰动给出一致的预测,约束分类边界平滑。实现如下
- Data Augmentation: 对batch中每个无标注样本做K轮增强\(\hat{u_{b,k}}=Augment(u_b)\),每轮增强得到一个模型预测\(P_{model}(y|u_{b,k};\theta)\)。针对图片作者使用了随机翻转和裁剪作为增强方案。
- Label Guessing: Ensemble以上k轮预测得到无标注样本的预估标签
- Sharpening:感觉Sharpen是搭配Ensemble使用的,考虑K轮融合可能会得到置信度较低的标签,作者使用Temperature来降低以上融合标签的熵值,促使模型给出高置信的预测
针对有标注样本,作者在原始Mixup的基础上加入对以上无标注样本的使用。
- 拼接:把增强后的标注样本\(\hat{X}\)和K轮增强后的无标注样本\(\hat{U}\)进行拼接得到\(W=Shuffle(Concat(\hat{X},\hat{U}))\)
- Mixup:两两样本对融合特征和标签得到新样本\(X^`,U^`\),这里在原始mixup的基础上额外约束mixup权重>0.5, 感觉这个约束主要针对引入的无标注样本,保证有标注样本的融合以原始标签为主,避免引入太多的噪声
最终的损失函数由标注样本的交叉熵和无标注样本在预测标签上的L2正则项加权得到
Mixmath因为使用了多种方案融合因子引入了不少超参数,包括融合轮数K,温度参数T,Mixup融合参数\(\alpha\), 以及正则权重\(\lambda_u\)。不过作者指出,多数超惨不需要根据任务进行调优,可以直接固定,作者给的参数取值,T=0.5,K=2。\(\alpha=0.75,\lambda_u=100\)是推荐的尝试取值,其中正则权重作者做了线性warmup。
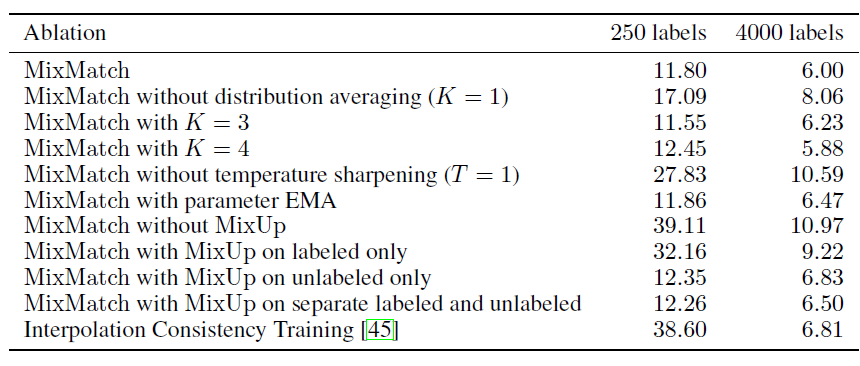
通过消融实验,作者证明了LabelGuessing,Sharpening,Mixup在当前的方案中缺一不可,且进一步使用Mean Teacher没有效果提升。

MixText
- Paper: MixText: Linguistically-Informed Interpolation of Hidden Space for Semi-Supervised Text Classification
- Github:https://github.com/SALT-NLP/MixText
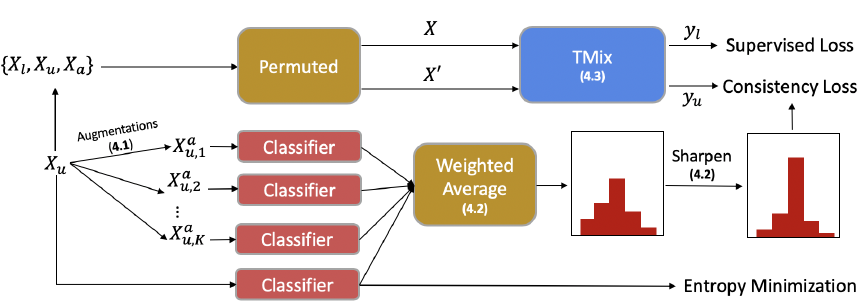
MixText是MixMatch在NLP领域的尝试,关注点在更适合NLP领域的Mixup使用方式,这里只关注和MixMatch的异同,未提到的部分基本上和MixMatch是一样的
- TMix:Mixup融合层
这一点我们在Mixup章节中讨论过,mixup究竟应该对哪一层隐藏层进行融合,能获得更好的效果。这里作者使用了和Manifold Mixup相同的方案,也就是每个Step都随机选择一层进行融合,只不过对选择那几层进行了调优(炼丹ing。。。), 在AG News数据集上选择更高层的效果更好,不过感觉这个参数应该是task specific的

- 最小熵正则
MixText进一步加入了最小熵原则,在无标注数据上,通过penalize大于\(\gamma\)的熵值(作者使用L2来计算),来进一步提高模型预测的置信度
- 无标注损失函数
MixMatch使用RMSE损失函数,来约束无标注数据的预测和Guess Label一致,而MixText使用KL-Divergance, 也就是和标注样本相同都是最小化交叉熵
UDA
- Paper:Unsupervised Data Augmentation for Consistency Training
- official Github: https://github.com/google-research/uda
- pytorch version: https://github.com/SanghunYun/UDA_pytorch
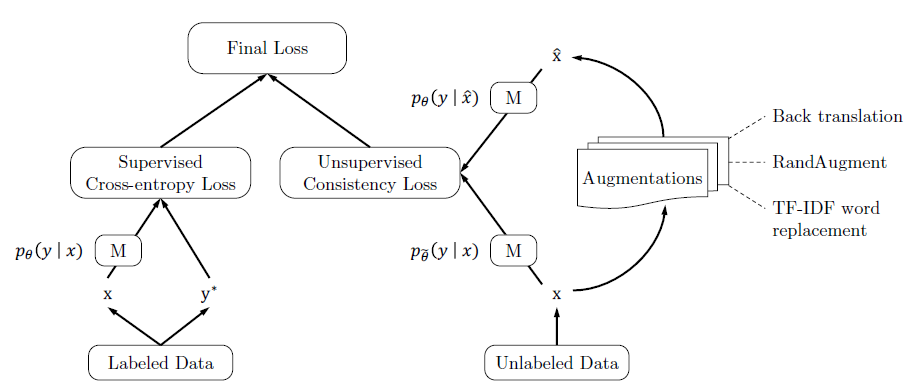
同样是MixMatch在NLP领域的尝试,不过UDA关注点在Data Augmentation的难易程度对半监督效果的影响,核心观点是难度高,多样性好,质量好的噪声注入,可以提升半监督的效果。以下只总结和MixMatch的异同点
-
Data Augmentation
MixMatch只针对CV任务,使用了随机水平翻转和裁剪进行增强。UDA在图片任务上使用了复杂度和多样性更高的RandAugment,在N个图片可用的变换中每次随机采样K个来对样本进行变换。原始的RandAugment是搜索得到最优的变换pipeline,这里作者把搜索改成了随机选择,可以进一步增强的多样性。
针对文本任务,UDA使用了Back-translation和基于TF-IDF的词替换作为增强方案。前者通过调整temperature可以生成多样性更好的增强样本,后者在分类问题中对核心关键词有更好的保护作用,生成的增强样本有效性更高。这也是UDA提出的一个核心观点就是数据增强其实是有效性和多样性之间的Trade-off -
Pseudo Label
针对无标注样本,MixMatch是对K次弱增强样本的预测结果进行融合得到更准确的标签。UDA只对一次强增强的样本进行预测得到伪标签。 -
Confidence-Based Maskin & Domain-relevance Data Filtering
UDA对无标注样本的一致性正则loss进行了约束,包括两个方面
- 置信度约束:在训练过程中,只对样本预测概率最大值>threshold的样本计算,如果样本预测置信度太低则不进行约束。这里的约束其实和MixMatch的多次预测Ensemble+Sharpen比较类似,都是提高样本的置信度,不过实现更简洁。
- 样本筛选:作者用原始模型在有标注上训练,在未标注样本上预测,过滤模型预测置信度太低的样本
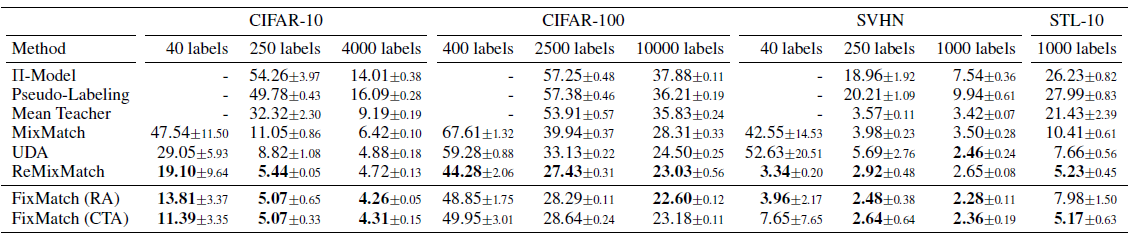
核心是为了从大量的无标注样本中筛选和标注样本领域相似的样本,避免一致性正则部分引入太多的样本噪声。效果上UDA比MixMatch有进一步的提升,具体放在下面的FixMatch一起比较。
FixMatch
- Paper:FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence
- official Github: https://github.com/google-research/fixmatch
- pytorch version: https://github.com/kekmodel/FixMatch-pytorch
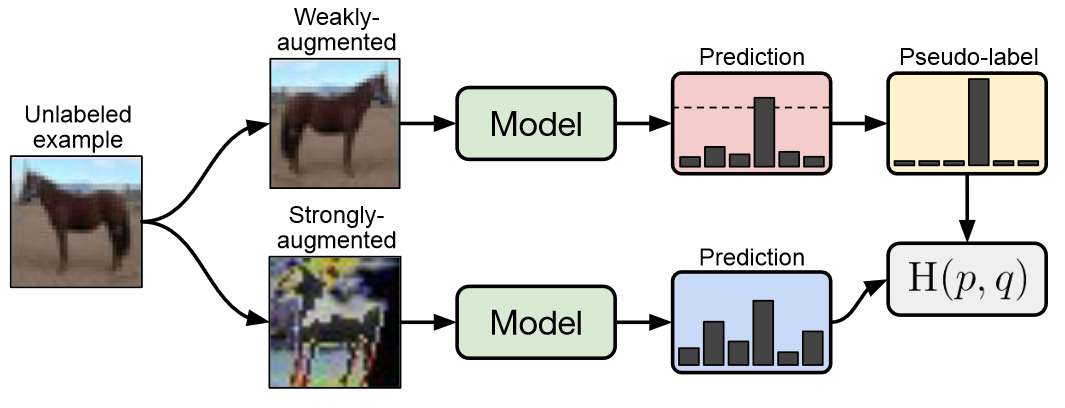
- Pseudo Label
在生成无标注样本的伪标签时,FixMatch使用了UDA的一次预测,和MixMatch的弱增强Flip&Shift来生成伪标签,同时应用UDA的置信度掩码,预测置信度低的样本不参与loss计算。
- 一致性正则
一致性正则是FixMatch最大的亮点,它使用以上弱增强得到的伪标签,用强增强的样本去拟合,得到一致性正则部分的损失函数。优点是弱增强的标签准确度更高,而强增强为一致性正则提供更好的多样性,和更大的样本扰动覆盖区域,使用不同的增强方案提高了一致性正则的效果
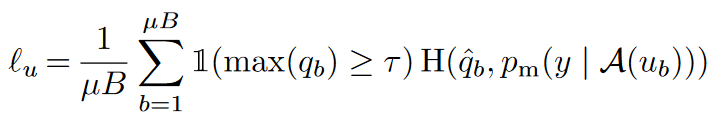

 浙公网安备 33010602011771号
浙公网安备 33010602011771号