小样本利器2.文本对抗+半监督 FGSM & VAT & FGM代码实现
 这一章我们结合FGSM,FGM,VAT看下如何使用对抗训练,以及对抗训练结合半监督来提升模型的鲁棒性。其中FGSM主要论述了对抗样本存在性和对抗训练提升模型鲁棒性的原因,VAT的两篇是对抗在CV领域应用的论文,而FGM是CV迁移到NLP的实现方案,一作都是同一位作者大大,在施工中的Simple Classification提供了FGM的tensorflow实现~
这一章我们结合FGSM,FGM,VAT看下如何使用对抗训练,以及对抗训练结合半监督来提升模型的鲁棒性。其中FGSM主要论述了对抗样本存在性和对抗训练提升模型鲁棒性的原因,VAT的两篇是对抗在CV领域应用的论文,而FGM是CV迁移到NLP的实现方案,一作都是同一位作者大大,在施工中的Simple Classification提供了FGM的tensorflow实现~
小样本利器2.文本对抗+半监督 FGSM & VAT & FGM代码实现
上一章我们聊了聊通过一致性正则的半监督方案,使用大量的未标注样本来提升小样本模型的泛化能力。这一章我们结合FGSM,FGM,VAT看下如何使用对抗训练,以及对抗训练结合半监督来提升模型的鲁棒性。本章我们会混着CV和NLP一起来说,VAT的两篇是CV领域的论文,而FGM是CV迁移到NLP的实现方案,一作都是同一位作者大大。FGM的tensorflow实现详见Github-SimpleClassification
我们会集中讨论3个问题
- 对抗样本为何存在
- 对抗训练实现方案
- 对抗训练为何有效
存在性

对抗训练
下面我们看下如何在模型训练过程中引入对抗样本,并训练模型给出正确的预测
监督任务
这里的对抗训练和GAN这类生成对抗训练不同,这里的对抗主要指微小扰动,在CV领域可以简单解释为肉眼不可见的轻微扰动(如下图)

不过两类对抗训练的原理都可以被经典的min-max公式涵盖
- max:对抗的部分通过计算delta来最大化损失
- min:训练部分针对扰动后的输入进行训练最小化损失函数
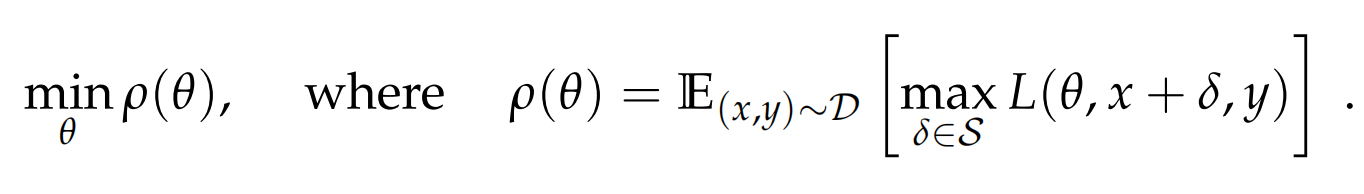
以上损失函数的视角,也可以切换成成极大似然估计的视角,也就是FGM中如下的公式,通过计算r,来使得扰动后y的条件概率最小化

于是问题就被简化成了如何计算扰动。最简单的方案就是和梯度下降相同沿用当前位置的一阶导数,梯度下降是沿graident去最小化损失,那沿反方向进行扰动不就可以最大化损失函数。不过因为梯度本身是对当前位置拟合曲线的线性化,所以需要控制步长来保证局部的线性,反向传播中我们用learning rate来控制步长,这里则需要控制扰动的大小。同时对抗扰动本身也需要控制扰动的幅度,不然就不符合微小扰动这个前提,放到NLP可以理解为为了防止扰动造成语义本身产生变化。
FGSM使用了\(l_{\infty}\) norm来对梯度进行正则化,只保留了方向信息丢弃了gradient各个维度上的scale
![]()
而FGM中作者选择了l2 norm来对梯度进行正则化,在梯度上更多了更多的信息,不过感觉在模型初始拟合的过程中也可能引入更多的噪音。

有了对抗样本,下一步就是如何让模型对扰动后的样本给出正确的分类结果。所以最简单的训练方式就是结合监督loss,和施加扰动之后的loss。FGSM中作者简单用0.5的权重来做融合。所以模型训练的方式是样本向前传递计算Loss,冻结梯度,计算扰动,对样本施加扰动再计算Loss,两个loss加权计算梯度。不过部分实现也有只保留对抗loss的操作,不妨作为超参对不同任务进行调整~
![]()
在使用对抗扰动时有两个需要注意的点
- 施加扰动的位置:对输入层扰动更合理
- 扰动和扰动层的scale:扰动层归一化
对于CV任务扰动位置有3个选择,输入层,隐藏层,或者输出层,对于NLP任务因为输入离散,所以输入层被替换成look up之后的embedding层。
作者基于万能逼近定理【简单说就是一个线性层+隐藏层如果有unit足够多可以逼近Rn上的任意函数0】指出因为输出层本身不满足万能逼近定理条件,所以对输出层(linear-softmax layer)扰动一般会导致模型underfit,因为模型会没有足够的能力来学习如何抵抗扰动。
而对于激活函数范围在[-inf, inf]的隐藏层进行扰动,会导致模型通过放大隐藏层scale来忽略扰动的影响。
因此一般是对输入层进行扰动,在下面FGM的实现中作者对word embedding进行归一化来规避上面scale的问题。不过这里有一个疑问就是对BERT这类预训练模型是不能对输入向量进行归一化的,那么如何保证BERT在微调的过程中不会通过放大输入层来规避扰动呢?后来想到的一个点是在探测Bert Finetune对向量空间的影响中提到的,微调对BERT各个层的影响是越接近底层影响越小的,所以从这个角度来说也是针对输入层做扰动更合理些~
半监督任务
以上的对抗训练只适用于标注样本,因为需要通过loss来计算梯度方向,而未标注样本无法计算loss,最简单的方案就是用模型预估来替代真实label。于是最大化loss的扰动,变成使得预测分布变化最大的扰动。
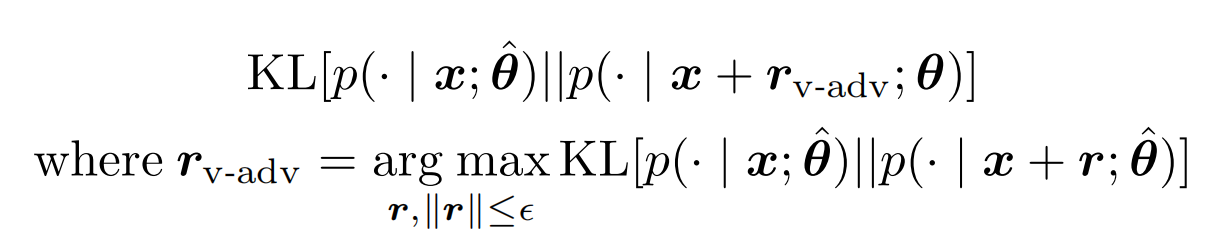
以上的虚拟扰动r无法直接计算,于是泰勒展开再次登场,不过这里因为把y替换成了模型预估p,所以一阶导数为0,于是最大化KL近似为最大化二阶导数的部分
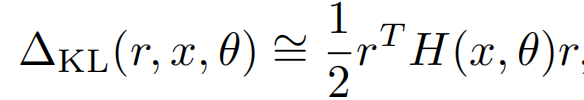
而以上r的求解,其实就是求解二阶海森矩阵的最大特征值对应的特征向量,以下u就是最大特征值对应的单位特征向量
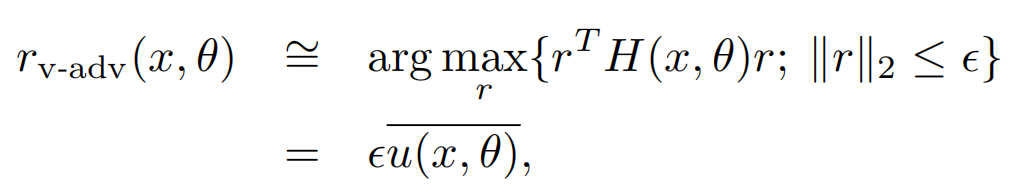
因为海森矩阵的计算复杂度较高,一般会采用迭代近似的方式来计算(详见REF12),简单说就是随机向量d(和u非正交),通过反复的下述迭代会趋近于u

而以上Hd同样可以被近似计算,因为上面KL的一阶导数为0,所以我们可以用KL~rHr的一阶差分来估计Hd,于是也就得了d的近似值
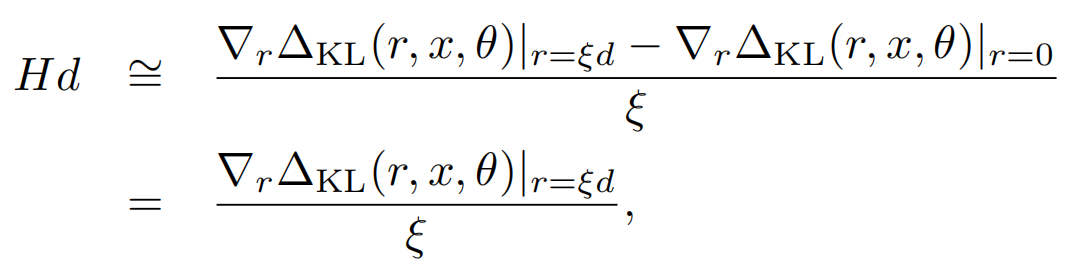
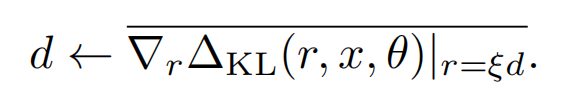

哈哈近似了一圈估计有的盆友们已经蒙圈了,可以对照着下面的计算方案再回来理解下上面的公式,计算虚拟扰动的算法如下(其中1~4可以多次迭代)
- 对embedding层施加随机扰动d
- 向前传递计算扰动后的logit
- 扰动logit和原始logit计算KL距离
- 对KL计算梯度
- 对梯度做归一化得到虚拟扰动的近似
- 对embedding层施加虚拟扰动,再计算一遍KL作为虚拟对抗部分的loss
这里暂时没有实现VAT因为时间复杂度有些高,之后有需要再补上VAT的部分
合理性
对抗扰动可以理解为一种正则方案,核心是为了提高模型鲁棒性,也就是样本外的泛化能力,这里给出两个视角
- 对比L1正则

- 对比一致性正则
这里和上一章我们提到的半监督之一致性正则有着相通之处,一致性正则强调模型应该对轻微扰动的样本给出一致的预测,但并没有对扰动本身进行太多的探讨,而对抗训练的核心在于如何对样本进行扰动。但核心都是扩充标注样本的覆盖范围,让标注样本的近邻拥有一致的模型预测。
效果
FGM论文是在LSTM,Bi-LSTM上做的测试会有比较明显的2%左右ErrorRate的下降。我在BERT上加入FGM在几个测试集上尝试指标效果并不明显,不过这里开源数据上测试集和训练集相似度比较高,而FGM更多是对样本外的泛化能力的提升。不过我在公司数据上使用FMG输出的预测概率的置信度会显著下降,一般bert微调会容易得到0.999这类高置信度预测,而加入FGM之后prob的分布变得更加合理,这个效果更容易用正则来进行解释。以下也给出了两个比赛方案链接里面都是用fgm做了优化也有一些insights,感兴趣的朋友可能在你的测试集上也实验下~
不过一言以蔽之,FGM的对抗方案,主要通过正则来约束模型学习,更多是锦上添花,想要学中送碳建议盆友们脚踏实地的去优化样本,优化标注,以及确认你的任务目标定义是否合理~
Reference
- FGSM- Explaining and Harnessing Adversarial Examples, ICLR2015
- FGM-Adversarial Training Methods for Semi-Supervised Text Classification, ICLR2017
- VAT-Virtual adversarial training: a regularization method for supervised and semi-supervised learning
- VAT-Distributional Smoothing with Virtual Adversarial Training
- Min-Max公式 Towards Deep Learning Models Resistant to Adversarial Attacks
- FGM-TF实现
- VAT-TF实现
- NLP中的对抗训练
- 苏神yyds:对抗训练浅谈:意义、方法和思考(附Keras实现)
- 天池大赛疫情文本挑战赛线上第三名方案分享
- 基于同音同形纠错的问题等价性判别第二名方案
- Eigenvalue computation in the 20th century

 浙公网安备 33010602011771号
浙公网安备 33010602011771号