


Bert不完全手册2. Bert不能做NLG?MASS/UNILM/BART
 Bert通过双向LM处理语言理解问题,GPT则通过单向LM解决生成问题,那如果既想拥有BERT的双向理解能力,又想做生成嘞?成年人才不要做选择!这类需求,主要包括seq2seq中生成对输入有强依赖的场景,例如翻译,生成式问答,文本摘要等等,本章分别介绍3种不同的方案:UNILM,MASS,BART
Bert通过双向LM处理语言理解问题,GPT则通过单向LM解决生成问题,那如果既想拥有BERT的双向理解能力,又想做生成嘞?成年人才不要做选择!这类需求,主要包括seq2seq中生成对输入有强依赖的场景,例如翻译,生成式问答,文本摘要等等,本章分别介绍3种不同的方案:UNILM,MASS,BART
Bert通过双向LM处理语言理解问题,GPT则通过单向LM解决生成问题,那如果既想拥有BERT的双向理解能力,又想做生成嘞?成年人才不要做选择!这类需求,主要包括seq2seq中生成对输入有强依赖的场景,例如翻译,生成式问答,文本摘要等等
最初Transformer的Encoder+Deocder结构是在机器翻译领域,Encoder的部分通过双向LM来抽取输入的全部上下文信息,Decoder通过单向LM在Encoder抽取信息的基础上完成生成任务。但后续的预训练模型,Bert和GPT各自选取了Transformer的一部分来实现各自的目标。Bert只用了Encoder,核心是基于AutoEncoding reconstruction loss的双向LM,适用于NLU任务。GPT只用了Decoder,核心是基于AutoRegression perplexity loss的单向语言模型,适用于NLG任务。那想要兼顾双向理解和生成能力,就要探索如何能让AE和AR在训练过程进行梦幻联动,以下分别介绍3种不同的方案
UNILM 1.0
UNILM完美诠释了MASK在手,要啥都有的极简设计原理。通过三种不同的attention MASK,使用Multitask的训练方式在相同的Transformer backbone里面实现了三种任务的融合,分别是双向LM(BERT),单向LM(GPT),seq2seqLM(transformer)。管你是Encoder还是Decoder本质只是Attention计算中可见信息的差异,那调整MASK就完事了~

预训练任务
UNILM的预训练任务,都是基于AE的reconstruction任务,和Bert相同的是,都是随机MASK15%的token,其中80%会被MASK替换,10%保留原始token,10%随机token。不同的是UNILM在80%的情况下会MASK1个token,剩余情况下会随机遮盖bigran或者trigram。
那同样是AE,UNILM是如何做到学到AR相关的信息的呢?这和UNILM的训练方式有关,它采用了Multitask的训练方式,在一个batch的样本中,采用三种不同的attention mask,让相同的模型参数分别学习单向,双向,seq2seq的语言信息,包括
- \(\frac{1}{3}\)的时间训练双向LM: 和BERT相同使用self-attention MASK,并且在以上的MLM任务上,同时也加入了NSP任务
- \(\frac{1}{3}\)训练seq2seq LM:segment1使用self-attention MASK, segment2使用Future MASK,同样是对MASK进行还原
- \(\frac{1}{6}\)的时间训练从左->右单向LM,\(\frac{1}{6}\)的时间训练从右->左单向LM:只不过这里没有使用对整个sequence进行还原的perplexity loss,而同样是对MASK进行还原,只不过只使用单向信息
这里感觉虽然UNLIM实现了单向的信息传递,但和AR之间还是有本质差异的,因为并不是对连续token进行递归预测,而依旧条件独立的对MASK token进行还原,虽然引入了bigram和trigram的MASK,但是效果有限,感觉这里限制了生成的效果。所以有没有可能在共享参数的前提下,直接引入perplexity loss进行训练呢?🤔️🤔️🤔️
针对以上三种任务的输入略有差异,其中单向LM只有1个segment ”[SOS] s1 [EOS]“,双向LM和seq2seq LM都是2个segment “[SOS] s1 [EOS] s2 [EOS]”
这里会发现以上EOS token,除了和BERT相同起到分割两个segment的作用,在单向LM任务中还会起到停止符的作用,所以其实在不同LM任务中EOS的作用不同,所以这里作者在不同的LM任务中采用了不同的segment Embedding。
预训练阶段,UNILM的参数使用了Bert Large进行初始化,在以上的三个任务重参数是共享的
下游任务Finetune
在下游fientune中,针对NLU任务,迁移方式和Bert相同,例如对分类任务,UNILM会输出[SOS]token对应的Embedding,后接softmax。针对NLG任务,会随机MASK第二个segment中的token进行还原。
整体效果GLUE Benchmark比Bert略好一丢丢,在生成式问答和摘要上提升更大。哈哈具体数值就不贴了,因为马上就要被下面会提到的BART超越,可以直接在下面BART的对比结果中看UNILM的效果了。。。
MASS
MASS则完美诠释了世界是个圈,Bert和GPT费劲吧啦把Encoder和Decoder拆开,MASS又给拼了回来。所以MASS的模型结构就是经典的Encoder+Decoder的Transformer。MASS通过改良MASK机制和训练目标增强了Encoder和Decoder在预训练阶段的交互
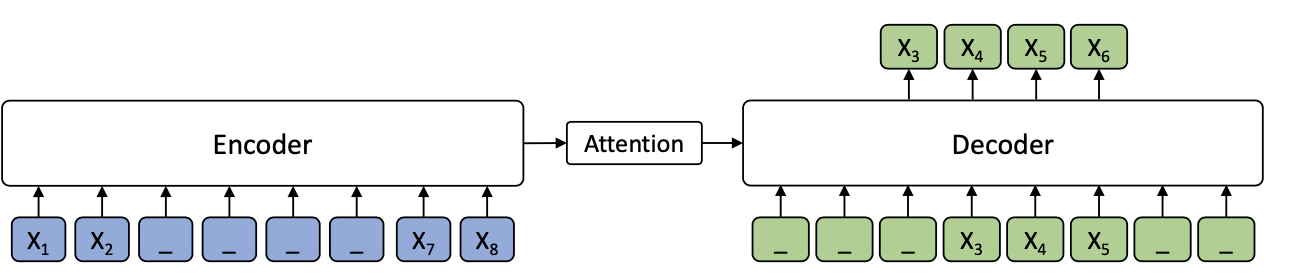
预训练任务
MASS创新了预训练目标,结合了生成和掩码。在Encoder侧随机选取连续K个token,这里k是MASS的超参数,Decoder侧采用互补MASK,遮盖所有在Encoder侧未遮盖的token,使用Auto Regression递归预测这k个token。这种互补掩码的方式,有效增强了Decoder对Encoder的信息依赖,避免Decoder直接依赖上文信息进行预测,进而也推动了Encoder部分去学习上下文双向信息。
都是对连续token进行MASK,和SpanBert不同的是MASS采用的是固定长度,作者测试了k的不同取值对模型效果的影响。整体上K的取值是总长度的50%左右的时候效果最好。哈哈其实感觉如果用一个均值=50%的分布来采样,可能也有效果提升???
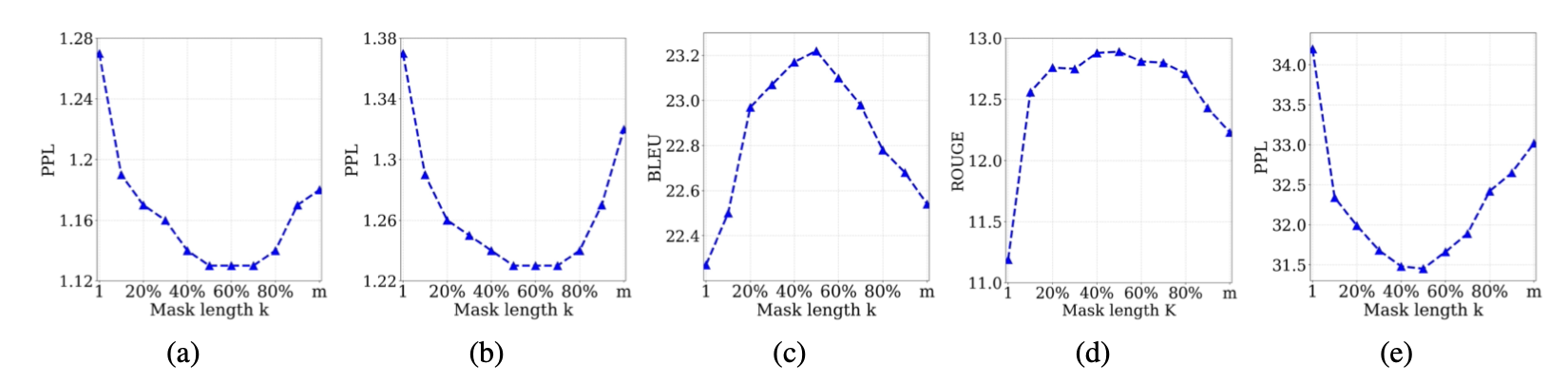
有意思的点在于,这里k的取值其实反映了MASS对Bert和GPT的融合权重,当K=1的时候,MASS其实等同于每次只MASK1个token的BERT模型,这时Decoder全部被MASK没有任何信息,而Encoder包含除MASK的一个token之外其余上下文信息。当K=seq_len的时候,MASS其实等同于GPT,这时Encoder没有任何信息,而Decoder部分就是传统的AR。在开头看到MASS的掩码还觉得有些摸不着头脑,看到这里感觉如果从loss function融合的角度来看,MASS的预训练目标其实可以类比Loss融合,和Huber Loss融合RMSE和MAE,以及Generalized Cross Entropy融合Cross Entropy和MAE,有着同一个世界同一个味道~~~

预训练和迁移细节这里就不多说了,因为MASS本身是为NMT翻译任务设计的,所以不管是评估还是训练都是for翻译任务的,和其他两个模型无法直接比较。不过AR和AE的融合思路设计的很巧妙,而且也不局限于NMT任务
BART
BART的模型结构和MASS相同也是Encoder+Decoder的配置,但是和MASS探索的方向不同,BART主要针对reconstruction任务中对输入信息扰动方式的探索,BERT使用的MASK本身也是一种扰动方式。
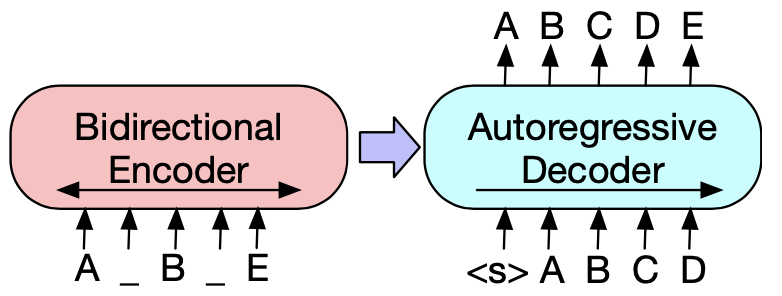
预训练任务
BART的预训练目标是reconstruction loss,通过对输入进行扰动,Encoder的输入是corrupted Sentence,然后Decoder的部分负责还原真实文本,这里只对Decoder的预测计算reconstruction loss。于是当Encoder侧的扰动是删除全部token时,BART->GPT
BART训练策略的设计和MASS相比,对Encoder和Decoder的信息交互要求并不严格,如果Deocder依赖单向信息就能很好完成任务的话,感觉Encoder部分信息会不会变得不太重要???
扰动方式作者尝试了以下方案
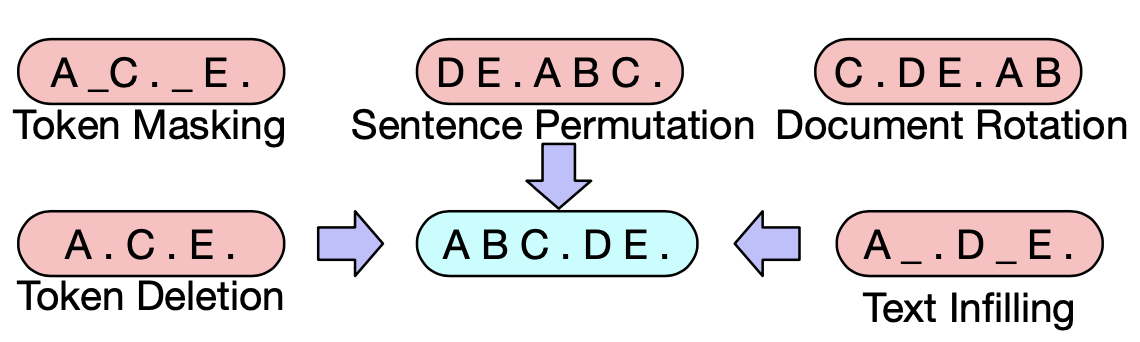
- Token Masking: 和Bert一样对token进行随机Mask,模型需要判断根据上下文还原MASK部分的语义信息
- Token Deletion:随机删除部分token,和MASK的区别在于模型需要去判断哪些位置丢失了信息
- Token Infilling:随机采样0~n个token,用一个MASK进行替换,模型除了学习MASKing部分缺失的语义,还要学习缺失token的数量,其实一定程度上是MASKing和Deletion的组合
- Token Rotation:对句子顺序进行rotate
- Token Shuffling :对句子顺序进行随机shuffle
整体评估如下,rotation和shuffling的表现最差,这个也在预料之中如果对所有语料都完全改变顺序,模型其实就不知道正常文本顺序是什么样子的了。而Deletion比Masking在生成任务上的表现更好,一定程度上是Deletion推进模型更多focus在位置信息上,综合各个任务单一扰动机制,Infilling的效果最优。最终作者选择了Infilling+Shuffling相结合的扰动机制,Infilling会MASK30%的token,并同时对整个句子进行随机打乱。
作者还对比了不同的预训练目标的影响,注意这里和原始的模型存在出入,作者只是使用了训练目标的部分,得到以下几点结论
- 不同训练目标在不同任务下差异较大,多数任务上BART表现略好
- 在生成任务上,尤其是输入和输出关联性较低的ELI5,单向语言模型一骑绝尘
- 对阅读理解,推理任务,MASK策略对应的双向语言模型表现显著更好
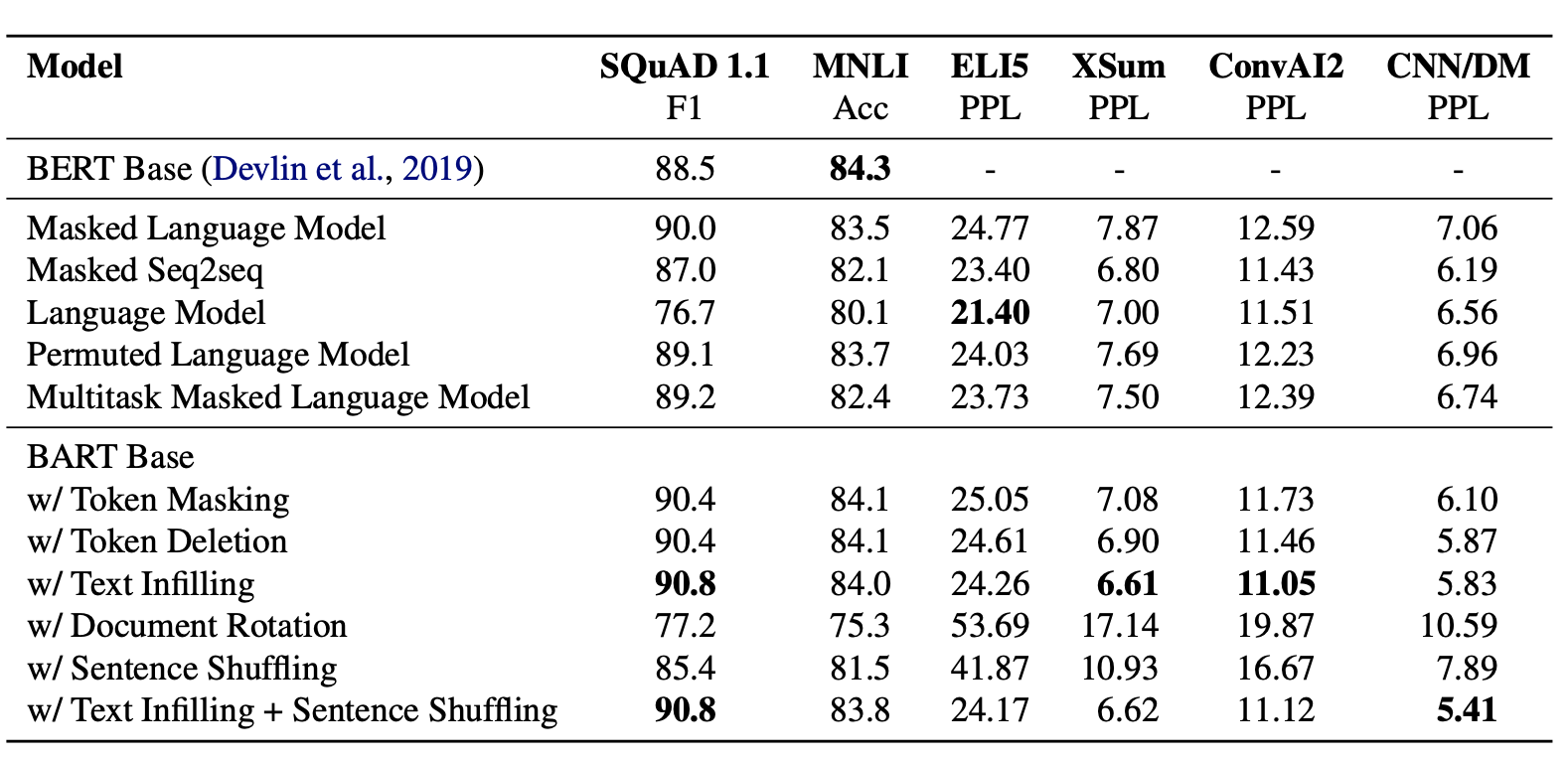
训练细节参考了Roberta,更大的Batch Size训练更多steps,不过因为BART本身是Encoder+Decoder所以参数量级基本上翻了一倍
下游任务迁移
BART同样可以灵活迁移到下游包括分类,序列标注,文本生成等诸多任务,微调方式各有不同。

- 分类任务:Encoder输入,Decoder递归,用BART在Decoder的末尾加入了[END]token的Embedding作为文本表征
- 序列标注任务:Encoder输入,Decoder每个位置的输出作为序列标注任务的输入
- 生成任务:Encoder输入,直接使用Decoder部分进行递归生成
- 翻译任务:翻译任务略有差异,是把BART的Embedding输入替换成一个随机初始化的Encoder,这个Encoder使得翻译任务可以使用和原始BART模型Vocab不同的输入。当然random init的部分需要先进行独立训练,再和BART一同已经微调。不过感觉这部分的调整其实和BART没啥非常紧密的联系~
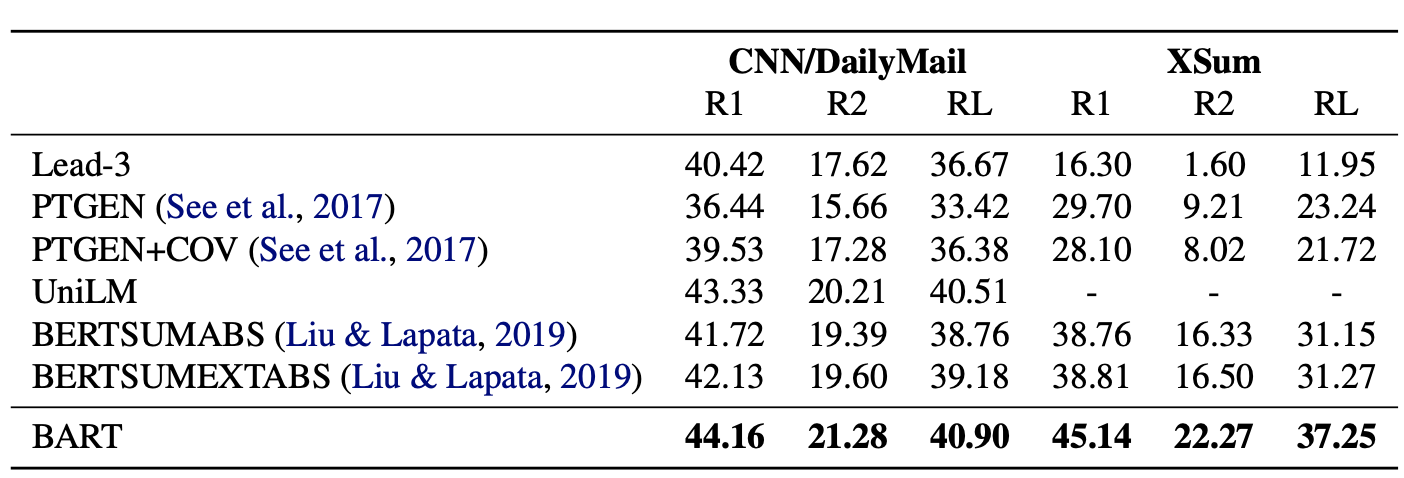
整体效果,在生成任务包括摘要生成和生成式问答上BART的效果都要显著超过之前的模型。
再来关注下阅读理解任务,整体上BART和Roberta效果不相上下,所以BART在生成能力上的提高并没有以牺牲双向理解能力为代价
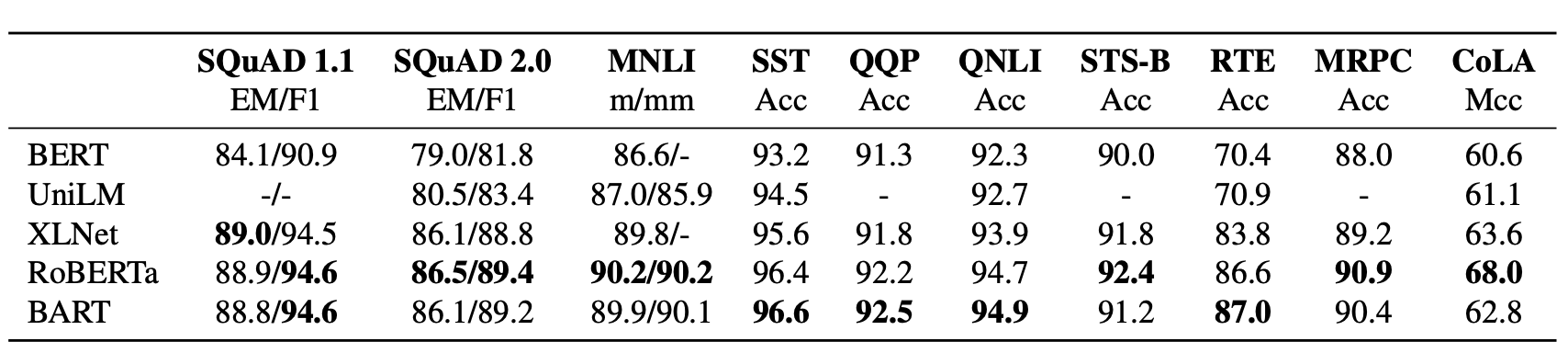
效果上BART自然是力压群雄,但是Encoder+Decoder的设计不管是训练还是推理都比较沉重,相比之下UNILM共享参数的设计感觉更加巧妙,所以如果能进一步在UNILM上提升效果,感觉就完美了~~
BERT手册相关论文和博客详见BertManual
Ref
- MASS: Masked Sequence to Sequence Pre-training for Language Generation, 2019
- UNLIM, Unified Language Model Pre-training for Natural Language Understanding and Generation, 2019
- BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension, 2019
- 苏剑林. (Sep. 18, 2019). 《从语言模型到Seq2Seq:Transformer如戏,全靠Mask 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/6933
- https://www.jiqizhixin.com/articles/2020-09-24

