博观约取系列 ~ 探测Bert Finetune对向量空间的影响
 模型微调一定比直接使用预训练模型效果好么?微调究竟对Bert的向量空间产生了哪些影响?A Closer Look at How Fine-tuning Changes Bert论文中,作者结合文本分类任务,和DirectProb这两种探测任务,直观展现了模型微调对Bert向量空间的影响
模型微调一定比直接使用预训练模型效果好么?微调究竟对Bert的向量空间产生了哪些影响?A Closer Look at How Fine-tuning Changes Bert论文中,作者结合文本分类任务,和DirectProb这两种探测任务,直观展现了模型微调对Bert向量空间的影响
熟悉NLP的同学对Bert Finetune一定不陌生,基本啥任务上来都可以Bert Finetune试一把。可是模型微调一定比直接使用预训练模型效果好么?微调究竟对Bert的向量空间产生了哪些影响嘞?考虑到Bert的高维向量无法直接观测,下面这篇paper中,作者结合文本分类任务,和DirectProb这两种探测任务,直观展现了模型微调对Bert向量空间的影响
Paper: A Closer Look at How Fine-tuning Changes Bert
Duang~Duang~Duang~敲黑板~先来看下paper的几个核心结论
- Finetune对文本表征的空间分布做了简化,增加了空间的线形可分性
- Finetune把分类任务中,不同Label的向量之间推的更远,增加了下游分类器的容错度
- Finetune会在尽可能保存预训练原始空间分布的前提下,调整输出层分布适应下游任务
- Finetune会记忆训练集特征,导致训练集和OOB样本间的表征差异变大,会存在一定的过拟合风险
探测任务
研究文本向量空间的paper,核心都在于如何使用探测任务来观察向量空间的分布,和分布在训练过程中的变化。这里作者用了两类探测任务,一类是传统的分类任务,统一是Bert后接两层的Relu全联接层,作者总共选取了4个任务:两个语法任务,词性分类(POS)和依赖分类(DEP)任务,两个语义任务分别是介词消歧PS-Role和PS-fxn任务。如果你对上面的NLP任务不熟悉也没关系,这里不同探测任务的选择更多只是为了增加实验的多样性,保证结论可泛化。在后面的分析中我们基本只用到分类任务标签的数量,所以知道用了这几类任务就哦了。
除了分类任务,作者还使用了直接分析空间分布的聚类任务DirectProb。哈哈这个方法就是字面意思,‘Direct’就是抛开下游分类任务,直接对向量表征进行探测。这里DirectProb的输入是Bert输出层向量,和下游分类任务的标签,采用bottom-up的聚类方法,在保证同一个cluster只能有1个Label,且不同cluster不重叠的前提下,把尽可能多的同类别向量聚合在一起。这种有监督的聚类方案保证最后得到的不同Label的clsuter,两两之间一定是线性可分的,如下图
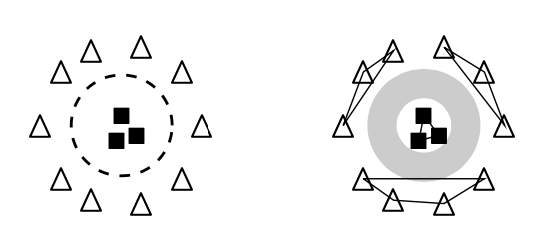
那DirectProb得到的聚类结果要怎么用呢?感觉文章比较有意思的结论都和下面聚类结果的使用方式相关,作者可以说是把聚类结果玩出了花,主要有三种用法
-
cluster的数量:如果 \(N_{cluster} = N_{Label}\) ,意味着两两Label之间只需要简单的线性分割器,就可以完成下游分类任务,则文本表征是线性可分的,如果\(N_{cluster} > N_{Label}\),则必然存在不是线性可分的Label(如上图),则下游分类器必须是非线性的
-
cluster间的距离:作者训练了线性的SVM作为max-margin分割器,cluster间的距离=2*margin。通过追踪Finetune过程中距离的变化,来观察绝对位置空间分布的变化
-
空间相似度:以上cluster两两间距离矩阵(n个Label对应\(\frac{n*(n-1)}{2}\)的矩阵)刻画了cluster间的相对位置关系。通过计算Finetune前后距离矩阵的相关性,来观察相对位置空间分布的变化
记住这三个特征,后面的实验分析都会基于它们展开,探测任务咱就说这么多,下面来看下具体的实验结果
实验&分析
作者选取了从小到大5个不同参数的Bert模型,来分析模型微调对不同大小Bert模型文本表征的影响。为了便于理解,下面的实验结果都做了截断,完整的实验结果见paper附录哟~
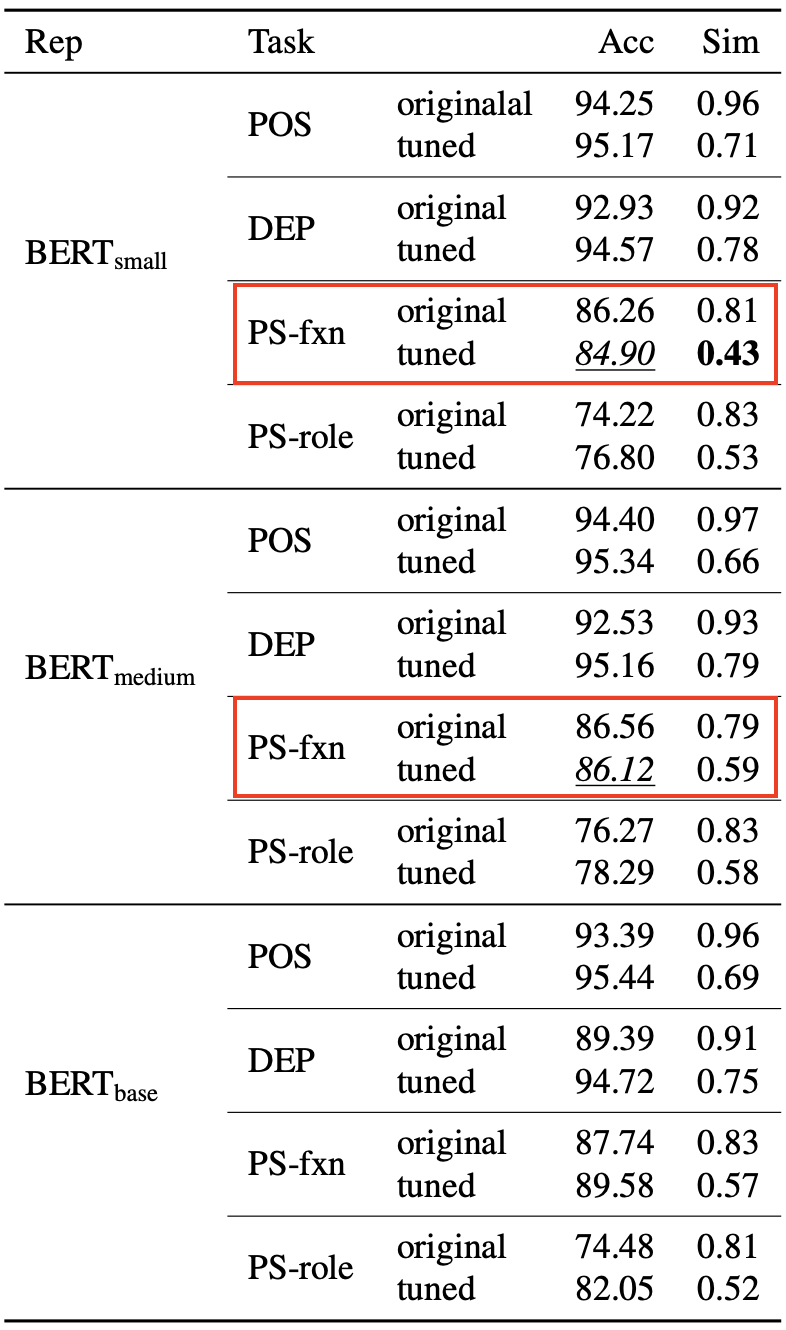
Finetune一定会提高模型表现?Nope!
整体上模型表现在预期之中,Bert模型越大表现越好。两个语法任务(DEP,POS)难度较小,小模型表现就很好,且Finetune带来的额外提升不多,两个语义任务(PS_fxn,PS-role)难度更大,Finetune带来的提升更多。不过有两个奇怪的点就是\(Bert_{small}\) 和 \(Bert_{medium}\)在PS-fxn任务上,微调反而导致效果下降。微调效果不好最先想到的就是过拟合,以及灾难遗忘。作者通过DirectProb计算了Finetune前后,训练集和测试集Cluster的空间相似度,发现训练集和测试集的空间相似度在Finetune之后都发生了下降,而Finetune表现不好的模型,空间相似度最低,这个现象指向Finetune可能导致向量空间记忆了部分训练集独有特征,导致了模型泛化的下降,也就是Finetune可能过拟合的风险。不过这里只是针对现象提出了一种可能,毕竟Finetune效果显著差的只有1个任务,且更小的模型\(Bert_{mini}\)和\(Bert_{tiny}\)在这个任务上并没有发生效果下降。所以这里作者更多只是抛出了一个idea,具体什么情况下微调效果会不好,还需要更多的research~哈哈不过这里不是paper的亮点,后面直接对向量空间的探测更有趣,接着看~接着看~
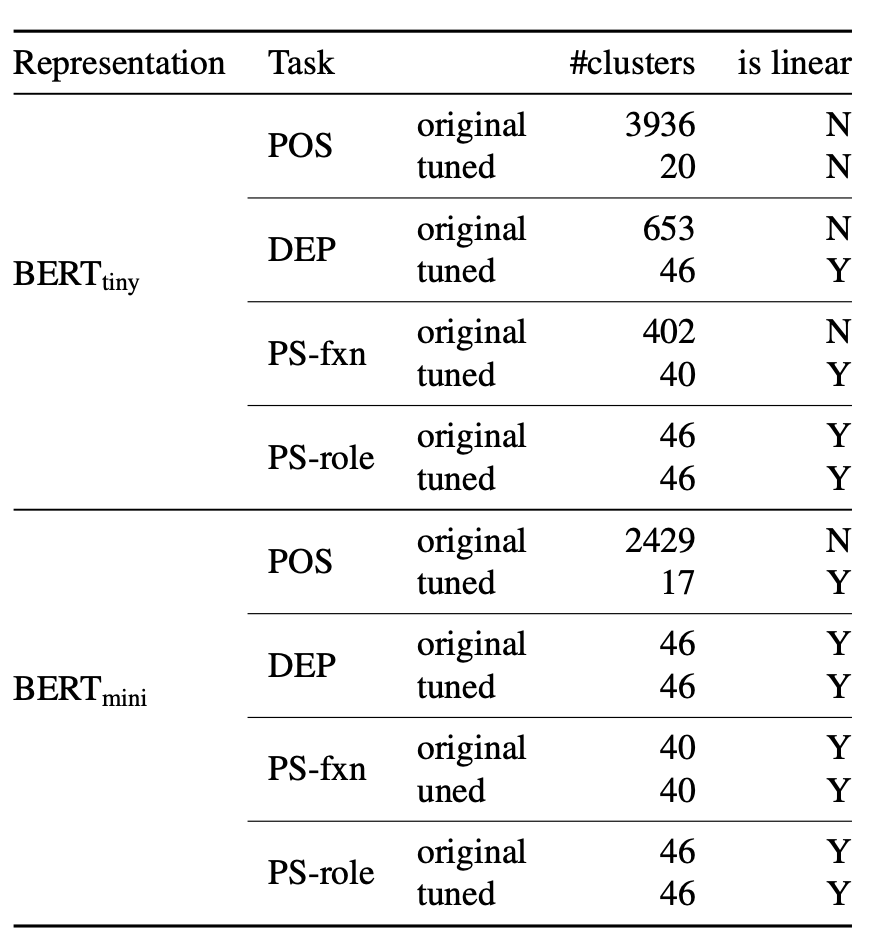
Finetune让向量空间更加线性可分
通过观察Finetune前后,DirectProb得到的聚类cluster的数量和Label数量是否相同,作者发现,Bert模型越大,预训练的向量空间线性程度越高,Finetune之后空间变得更加线性可分。怎么理解这个现象呢?我的理解是,Bert预训练是对大量的通用语义,语法特征进行了记忆和抽象,然后把信息编码到模型输出的向量中,那向量(Dim)越大需要的信息压缩程度越小,下游使用时对信息解码也就越容易。反之向量越小需要更大程度的信息压缩,才能尽可能多的保留语言信息,也就导致下游使用需要更复杂(非线性)的解码过程来获取信息。Finetune更像是针对下游任务先适应性的进行了一步信息重排列,帮助分类器更容易地提取出所需特征
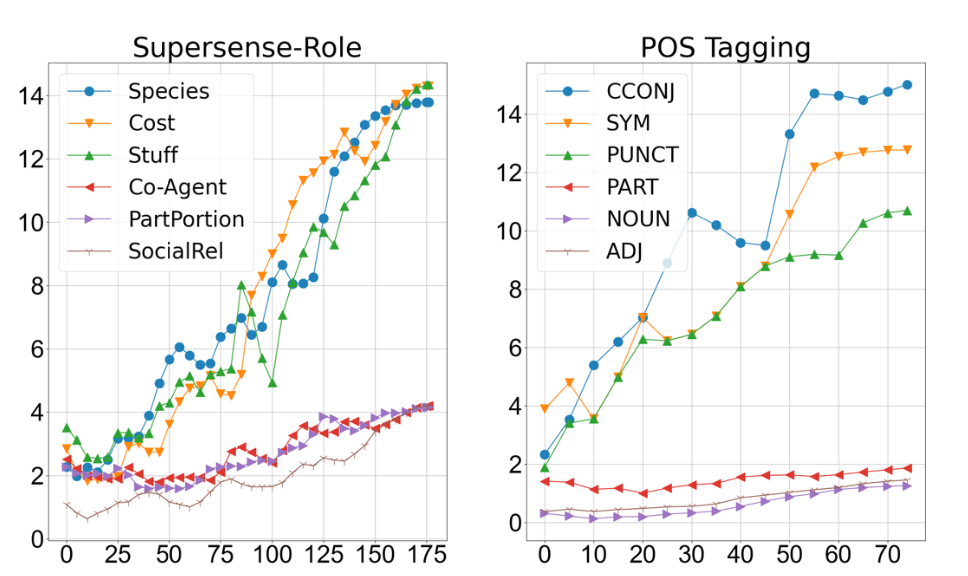
Finetune把不同Label的空间分布推的更远
这里用了\(Bert_{base}\)模型,该模型预训练的空间向量在DirectProb聚类中是线性可分的,所以一个cluster对应一个Label的样本。通过观察每个cluster和其他所有cluster最小距离的变化,作者发现随着微调训练,最小距离会不断增大。下图作者给了两个任务中,距离变化最大和最小的3个Label,最小距离随fintune step的变化,其他任务的Label都存在这一现象。Finetune带来的Label间距离上升,意味着两个Label之间的分类器容错率更高,样本外泛化性更好。
Fintune对Bert不同层影响不同
以上都是对输出层的分析,Let's Dig Deeper! 我们来看下微调对Bert其他层的影响,尤其是底层Layer,如果底层Layer没变,说明微调只是对预训练学到的信息进行了重新排列,调整了信息提取的方式,如果底层Layer发生了剧烈变化,就有灾难遗忘的可能性。作者应用DirectProb的聚类结果给出了以下几点发现
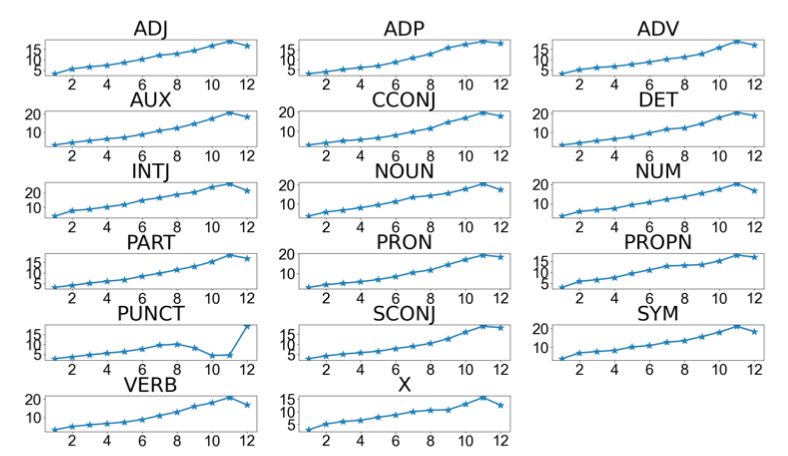
越接近顶层,Finetune带来的绝对位移幅度更大
这里作者对Bert每一层的空间向量,都用DirectProb分进行聚类,计算每个cluster的中心点。通过对比Finetune前后中心点移动的欧式距离,来衡量Bert不同层空间表征的变化幅度。下图选了\(Bert_{base}\)在POS任务上每一个Label,Finetune前后,Bert 12层Layer (x-axis)的绝对位移 (y-axis),可以看到在所有Label上,越接近顶层,绝对位移的幅度会越大
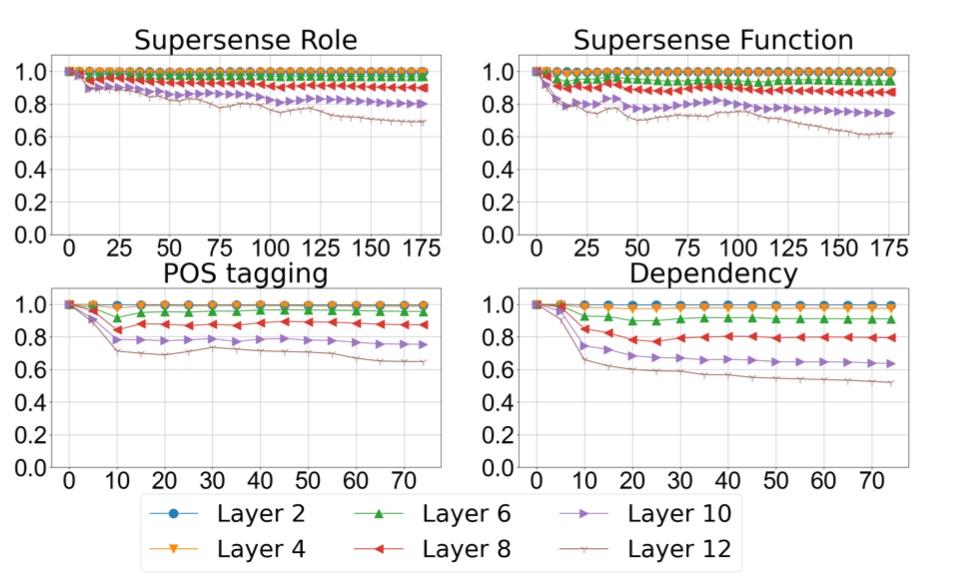
Finetune保留了和预训练空间分布的相似性
看了各个cluster绝对位置变化,我们再来看下cluster整体相对位置的改变。作者通过追踪Finetune过程中,cluster间两两距离矩阵和预训练距离矩阵的相关性,来刻画相对位置的改变。下图给出\(Bert_{base}\)在4个任务中,随着Finetune的训练 (x-axis),不同层和预训练空间的相似度 (y-axis)并不会持续下降,而是先下降后趋于平稳,虽然越接近顶层相关性下降幅度更大,但都至少保证了>0.5的相关性
底层Layer并非完全没变,只是在很小的范围内朝着相似的方向移动
在上述两张图上,底层Layer不论是相对位置,还是绝对位移变化都不太大,但底层Layer完全没变么?不是的!作者通过对每层各个cluster的中心点进行PCA降维,在二维空间上对Finetune前后,各层向量的移动做了可视化。可以发现底层Layer也有移动,只是方向相对单一,且绝对移动幅度较小 (x,y轴的取值范围是随Layer上升变大的),而越接近顶层,移动幅度更大,且方向更分散~
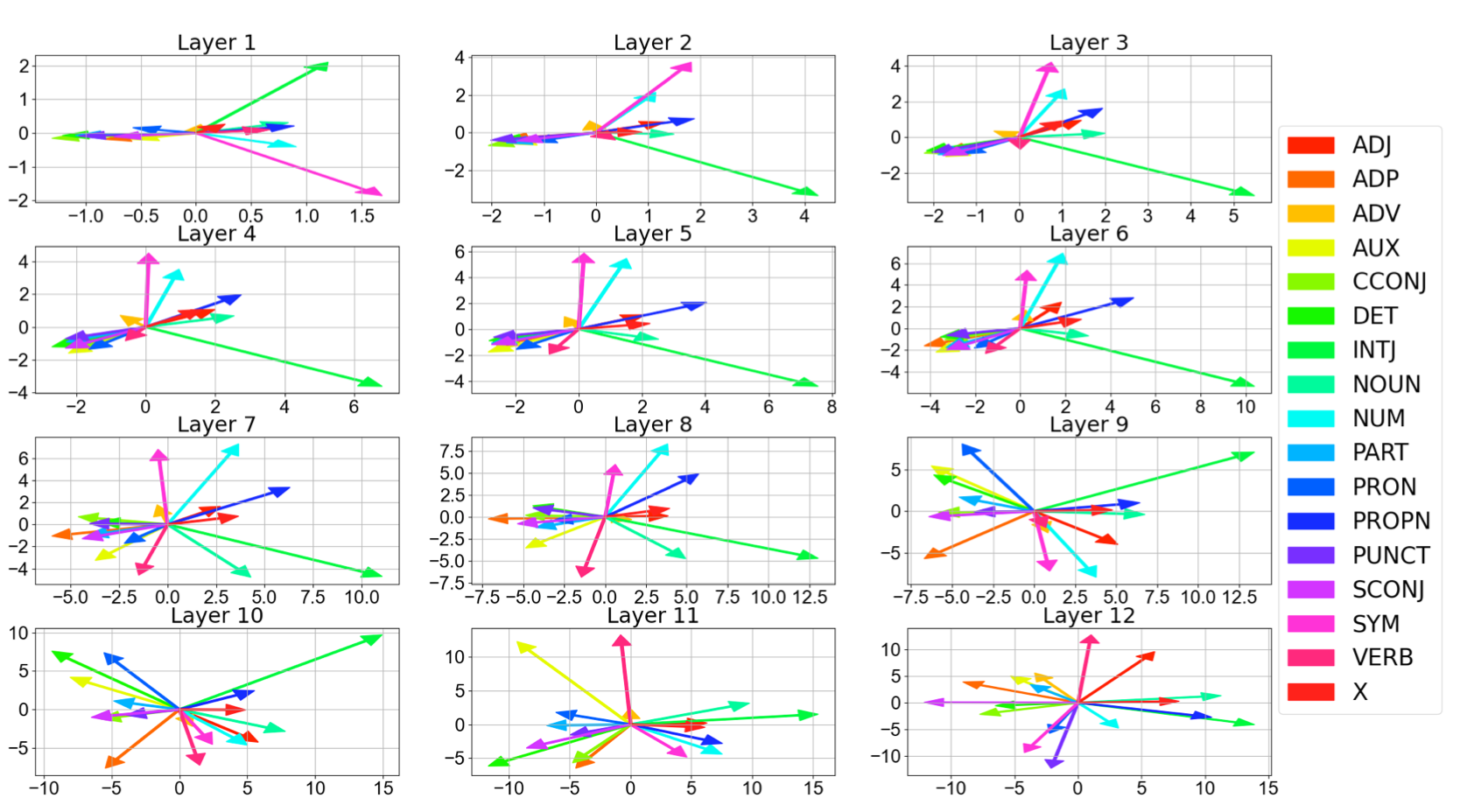
结合以上三点微调对Bert不同层的影响,一定程度上能佐证Finetune是在尽可能保存预训练信息的前提下,针对下游任务来调整输出的空间分布。
这个paper我们就聊这么多啦~新开这个系列就是字面意思,之后看到有意思有价值的paper就简单梳理下和大家一起分享~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号