合集-DecryptPrompt
摘要: 这一章我们聊聊有哪些方案可以不用微调直接让大模型支持超长文本输入,分别介绍显式搜索,unlimiformer隐式搜索,并行输入的PCW,和并行解码的NBCE方案
阅读全文
这一章我们聊聊有哪些方案可以不用微调直接让大模型支持超长文本输入,分别介绍显式搜索,unlimiformer隐式搜索,并行输入的PCW,和并行解码的NBCE方案
阅读全文
这一章我们聊聊有哪些方案可以不用微调直接让大模型支持超长文本输入,分别介绍显式搜索,unlimiformer隐式搜索,并行输入的PCW,和并行解码的NBCE方案
阅读全文
摘要: 上一章介绍了如何基于APE+SELF自动化构建指令微调样本。这一章咱就把微调跑起来,主要介绍以Lora为首的低参数微调原理,环境配置,微调代码,以及大模型训练中显存和耗时优化的相关技术细节
阅读全文
上一章介绍了如何基于APE+SELF自动化构建指令微调样本。这一章咱就把微调跑起来,主要介绍以Lora为首的低参数微调原理,环境配置,微调代码,以及大模型训练中显存和耗时优化的相关技术细节
阅读全文
上一章介绍了如何基于APE+SELF自动化构建指令微调样本。这一章咱就把微调跑起来,主要介绍以Lora为首的低参数微调原理,环境配置,微调代码,以及大模型训练中显存和耗时优化的相关技术细节
阅读全文
摘要: RLHF是针对有用,无害,事实性等原则,把模型输出和人类偏好进行对齐的一种方案。以OpenAI为基础,本章会对比DeepMind, Anthropic在RLHF步骤中的异同,试图理解RLHF究竟做了啥
阅读全文
RLHF是针对有用,无害,事实性等原则,把模型输出和人类偏好进行对齐的一种方案。以OpenAI为基础,本章会对比DeepMind, Anthropic在RLHF步骤中的异同,试图理解RLHF究竟做了啥
阅读全文
RLHF是针对有用,无害,事实性等原则,把模型输出和人类偏好进行对齐的一种方案。以OpenAI为基础,本章会对比DeepMind, Anthropic在RLHF步骤中的异同,试图理解RLHF究竟做了啥
阅读全文
摘要: 把AutomaticPromptEngineer指令逆向工程,SELFInstruct指令扩充组个CP,完全依LLM来构建指令微调样本集!在医疗领域经初步尝试了下,附代码和可视化应用
阅读全文
把AutomaticPromptEngineer指令逆向工程,SELFInstruct指令扩充组个CP,完全依LLM来构建指令微调样本集!在医疗领域经初步尝试了下,附代码和可视化应用
阅读全文
把AutomaticPromptEngineer指令逆向工程,SELFInstruct指令扩充组个CP,完全依LLM来构建指令微调样本集!在医疗领域经初步尝试了下,附代码和可视化应用
阅读全文
摘要: 这一章我们聊聊指令微调,模型还是那个熟悉的模型,核心的差异在于指令集和评估侧重点的不同,每个模型只侧重介绍差异点。按时间顺序分别是Flan,T0,InstructGPT, Tk-Instruct
阅读全文
这一章我们聊聊指令微调,模型还是那个熟悉的模型,核心的差异在于指令集和评估侧重点的不同,每个模型只侧重介绍差异点。按时间顺序分别是Flan,T0,InstructGPT, Tk-Instruct
阅读全文
这一章我们聊聊指令微调,模型还是那个熟悉的模型,核心的差异在于指令集和评估侧重点的不同,每个模型只侧重介绍差异点。按时间顺序分别是Flan,T0,InstructGPT, Tk-Instruct
阅读全文
摘要: 这一章我们介绍在下游任务微调中固定LM参数,只微调Prompt的相关模型。这类模型的优势很直观就是微调的参数量小,能大幅降低LLM的微调参数量,是轻量级的微调替代品
阅读全文
这一章我们介绍在下游任务微调中固定LM参数,只微调Prompt的相关模型。这类模型的优势很直观就是微调的参数量小,能大幅降低LLM的微调参数量,是轻量级的微调替代品
阅读全文
这一章我们介绍在下游任务微调中固定LM参数,只微调Prompt的相关模型。这类模型的优势很直观就是微调的参数量小,能大幅降低LLM的微调参数量,是轻量级的微调替代品
阅读全文
摘要: 这一章我们介绍固定prompt微调LM的相关模型,他们的特点都是针对不同的下游任务设计不同的prompt模板,在微调过程中固定模板对预训练模型进行微调。以下按时间顺序介绍,支持任意NLP任务的T5,针对文本分类的两篇PET和LM-BFF。
阅读全文
这一章我们介绍固定prompt微调LM的相关模型,他们的特点都是针对不同的下游任务设计不同的prompt模板,在微调过程中固定模板对预训练模型进行微调。以下按时间顺序介绍,支持任意NLP任务的T5,针对文本分类的两篇PET和LM-BFF。
阅读全文
这一章我们介绍固定prompt微调LM的相关模型,他们的特点都是针对不同的下游任务设计不同的prompt模板,在微调过程中固定模板对预训练模型进行微调。以下按时间顺序介绍,支持任意NLP任务的T5,针对文本分类的两篇PET和LM-BFF。
阅读全文
摘要: 借着ChatGPT的东风,我们来梳理下prompt范式的相关模型,你还以其他形式看到过prompt概念,例如Demonstration,Instruction,In-Context learning,few-shot learning等等~开篇我们简单介绍下Prompt范式,并以其中的冻结参数Tunning-Free Prompt为线索串联GPT2,GPT3,LAMA和AutoPrompt这四种冻结参数的基础模型
阅读全文
借着ChatGPT的东风,我们来梳理下prompt范式的相关模型,你还以其他形式看到过prompt概念,例如Demonstration,Instruction,In-Context learning,few-shot learning等等~开篇我们简单介绍下Prompt范式,并以其中的冻结参数Tunning-Free Prompt为线索串联GPT2,GPT3,LAMA和AutoPrompt这四种冻结参数的基础模型
阅读全文
借着ChatGPT的东风,我们来梳理下prompt范式的相关模型,你还以其他形式看到过prompt概念,例如Demonstration,Instruction,In-Context learning,few-shot learning等等~开篇我们简单介绍下Prompt范式,并以其中的冻结参数Tunning-Free Prompt为线索串联GPT2,GPT3,LAMA和AutoPrompt这四种冻结参数的基础模型
阅读全文
摘要: 这一篇真的是解密prompt!我们会讨论下思维链(chain-of-Thought)提示词究竟要如何写,如何写的更高级,介绍包括few-shot,zero-shot,循序渐进式和一致性COT的写法
阅读全文
这一篇真的是解密prompt!我们会讨论下思维链(chain-of-Thought)提示词究竟要如何写,如何写的更高级,介绍包括few-shot,zero-shot,循序渐进式和一致性COT的写法
阅读全文
这一篇真的是解密prompt!我们会讨论下思维链(chain-of-Thought)提示词究竟要如何写,如何写的更高级,介绍包括few-shot,zero-shot,循序渐进式和一致性COT的写法
阅读全文
摘要: 本章介绍如何和搜索引擎进行交互的LLM Agent设计,主要包含以下几个模块:搜索改写,事实抽取,聚合推理,行为交互。我们会以WebCPM为基础,同时介绍WebGPT,WebGLM的异同
阅读全文
本章介绍如何和搜索引擎进行交互的LLM Agent设计,主要包含以下几个模块:搜索改写,事实抽取,聚合推理,行为交互。我们会以WebCPM为基础,同时介绍WebGPT,WebGLM的异同
阅读全文
本章介绍如何和搜索引擎进行交互的LLM Agent设计,主要包含以下几个模块:搜索改写,事实抽取,聚合推理,行为交互。我们会以WebCPM为基础,同时介绍WebGPT,WebGLM的异同
阅读全文
摘要: 这一章我们追本溯源,讨论下COT的哪些元素是提升模型表现的核心。结合两篇论文的实验结论,可能导致思维链比常规推理拥有更高准确率的因素有:思维链的推理过程会重复问题中的核心实体;正确逻辑推理顺序的引入
阅读全文
这一章我们追本溯源,讨论下COT的哪些元素是提升模型表现的核心。结合两篇论文的实验结论,可能导致思维链比常规推理拥有更高准确率的因素有:思维链的推理过程会重复问题中的核心实体;正确逻辑推理顺序的引入
阅读全文
这一章我们追本溯源,讨论下COT的哪些元素是提升模型表现的核心。结合两篇论文的实验结论,可能导致思维链比常规推理拥有更高准确率的因素有:思维链的推理过程会重复问题中的核心实体;正确逻辑推理顺序的引入
阅读全文
摘要: 现实场景中考虑成本和推理延时,大家还是希望能用6B的模型就不用100B的大模型。但在前两章反复提到小模型不具备思维链推理能力,那这个能力有可能通过后天训练来获得么?如何让小模型具备COT能力呢?
阅读全文
现实场景中考虑成本和推理延时,大家还是希望能用6B的模型就不用100B的大模型。但在前两章反复提到小模型不具备思维链推理能力,那这个能力有可能通过后天训练来获得么?如何让小模型具备COT能力呢?
阅读全文
现实场景中考虑成本和推理延时,大家还是希望能用6B的模型就不用100B的大模型。但在前两章反复提到小模型不具备思维链推理能力,那这个能力有可能通过后天训练来获得么?如何让小模型具备COT能力呢?
阅读全文
摘要: 这一章我们正式进入大模型应用,聊聊如何把思维链和工具使用结合得到人工智能代理。先介绍基于Prompt的零微调方案Self Ask和React,我们会结合langchain写个简单的Agent来玩一玩
阅读全文
这一章我们正式进入大模型应用,聊聊如何把思维链和工具使用结合得到人工智能代理。先介绍基于Prompt的零微调方案Self Ask和React,我们会结合langchain写个简单的Agent来玩一玩
阅读全文
这一章我们正式进入大模型应用,聊聊如何把思维链和工具使用结合得到人工智能代理。先介绍基于Prompt的零微调方案Self Ask和React,我们会结合langchain写个简单的Agent来玩一玩
阅读全文
摘要: 本章介绍基于模型微调,支持任意多工具组合调用,复杂工具调用的方案。工具调用的核心是3个问题:在哪个位置使用工具,使用什么工具,如何生成调用语句 - Gorilla & Toolformer
阅读全文
本章介绍基于模型微调,支持任意多工具组合调用,复杂工具调用的方案。工具调用的核心是3个问题:在哪个位置使用工具,使用什么工具,如何生成调用语句 - Gorilla & Toolformer
阅读全文
本章介绍基于模型微调,支持任意多工具组合调用,复杂工具调用的方案。工具调用的核心是3个问题:在哪个位置使用工具,使用什么工具,如何生成调用语句 - Gorilla & Toolformer
阅读全文
摘要: 这一章我们来唠唠大模型和DB数据库之间的交互方案,除了基于Spider数据集的SOTA方案DIN之外,还会介绍两个改良方案C3和SQL-Palm,以及更贴合实际应用的大规模复杂SQL数据集BIRD。
阅读全文
这一章我们来唠唠大模型和DB数据库之间的交互方案,除了基于Spider数据集的SOTA方案DIN之外,还会介绍两个改良方案C3和SQL-Palm,以及更贴合实际应用的大规模复杂SQL数据集BIRD。
阅读全文
这一章我们来唠唠大模型和DB数据库之间的交互方案,除了基于Spider数据集的SOTA方案DIN之外,还会介绍两个改良方案C3和SQL-Palm,以及更贴合实际应用的大规模复杂SQL数据集BIRD。
阅读全文
摘要: 总结下指令微调、对齐样本筛选相关的方案包括LIMA,LTD等。论文都是以优化指令样本为核心,提出对齐阶段的数据质量优于数量,少量+多样+高质量的对齐数据,就能让你快速拥有效果杠杠的模型
阅读全文
总结下指令微调、对齐样本筛选相关的方案包括LIMA,LTD等。论文都是以优化指令样本为核心,提出对齐阶段的数据质量优于数量,少量+多样+高质量的对齐数据,就能让你快速拥有效果杠杠的模型
阅读全文
总结下指令微调、对齐样本筛选相关的方案包括LIMA,LTD等。论文都是以优化指令样本为核心,提出对齐阶段的数据质量优于数量,少量+多样+高质量的对齐数据,就能让你快速拥有效果杠杠的模型
阅读全文
摘要: 这一章介绍通过扩写,改写,以及回译等半监督样本挖掘方案对种子样本进行扩充,提高种子指令样本的多样性和复杂度,这里我们分别介绍Microsoft,Meta和IBM提出的三个方案。
阅读全文
这一章介绍通过扩写,改写,以及回译等半监督样本挖掘方案对种子样本进行扩充,提高种子指令样本的多样性和复杂度,这里我们分别介绍Microsoft,Meta和IBM提出的三个方案。
阅读全文
这一章介绍通过扩写,改写,以及回译等半监督样本挖掘方案对种子样本进行扩充,提高种子指令样本的多样性和复杂度,这里我们分别介绍Microsoft,Meta和IBM提出的三个方案。
阅读全文
摘要: 前四章不论是和数据库和模型还是和搜索引擎交互,更多还是大模型和人之间的交互。这一章我们来唠唠只有大模型智能体的世界!分别基于源码介绍斯坦福小镇和Chatdev两篇论文
阅读全文
前四章不论是和数据库和模型还是和搜索引擎交互,更多还是大模型和人之间的交互。这一章我们来唠唠只有大模型智能体的世界!分别基于源码介绍斯坦福小镇和Chatdev两篇论文
阅读全文
前四章不论是和数据库和模型还是和搜索引擎交互,更多还是大模型和人之间的交互。这一章我们来唠唠只有大模型智能体的世界!分别基于源码介绍斯坦福小镇和Chatdev两篇论文
阅读全文
摘要: 这一章我们聊聊大模型在数据分析领域的应用。数据分析主要是指在获取数据之后的数据清洗,数据处理,建模,数据洞察和可视化的步骤。这里我们聊两篇论文:Data-Copilot 和 InsightPilot
阅读全文
这一章我们聊聊大模型在数据分析领域的应用。数据分析主要是指在获取数据之后的数据清洗,数据处理,建模,数据洞察和可视化的步骤。这里我们聊两篇论文:Data-Copilot 和 InsightPilot
阅读全文
这一章我们聊聊大模型在数据分析领域的应用。数据分析主要是指在获取数据之后的数据清洗,数据处理,建模,数据洞察和可视化的步骤。这里我们聊两篇论文:Data-Copilot 和 InsightPilot
阅读全文
摘要: 看完openai闭门会议对RAG又有些新的思考。这一章我们参考主流的搜索框架,结合新老论文,和langchain新功能聊聊RAG框架中召回多样性的优化方案,包括如何提高query多样性和索引多样性
阅读全文
看完openai闭门会议对RAG又有些新的思考。这一章我们参考主流的搜索框架,结合新老论文,和langchain新功能聊聊RAG框架中召回多样性的优化方案,包括如何提高query多样性和索引多样性
阅读全文
看完openai闭门会议对RAG又有些新的思考。这一章我们参考主流的搜索框架,结合新老论文,和langchain新功能聊聊RAG框架中召回多样性的优化方案,包括如何提高query多样性和索引多样性
阅读全文
摘要: 话接上文的召回多样性优化,这一章我们唠唠召回的信息密度和质量。同样参考经典搜索和推荐框架,这一章对应排序+重排环节。我们先对比下经典框架和RAG的异同,再分别介绍几种适用大模型的排序和重排方案~
阅读全文
话接上文的召回多样性优化,这一章我们唠唠召回的信息密度和质量。同样参考经典搜索和推荐框架,这一章对应排序+重排环节。我们先对比下经典框架和RAG的异同,再分别介绍几种适用大模型的排序和重排方案~
阅读全文
话接上文的召回多样性优化,这一章我们唠唠召回的信息密度和质量。同样参考经典搜索和推荐框架,这一章对应排序+重排环节。我们先对比下经典框架和RAG的异同,再分别介绍几种适用大模型的排序和重排方案~
阅读全文
摘要: 当前RAG多数只让模型基于检索内容回答,其实限制了模型自身知识压缩形成的智能。既要事实性又要模型智能,需要最大化使用模型内化到参数中的信息,只在必要时调用外部知识,这里介绍前置和后置处理的几种方案~
阅读全文
当前RAG多数只让模型基于检索内容回答,其实限制了模型自身知识压缩形成的智能。既要事实性又要模型智能,需要最大化使用模型内化到参数中的信息,只在必要时调用外部知识,这里介绍前置和后置处理的几种方案~
阅读全文
当前RAG多数只让模型基于检索内容回答,其实限制了模型自身知识压缩形成的智能。既要事实性又要模型智能,需要最大化使用模型内化到参数中的信息,只在必要时调用外部知识,这里介绍前置和后置处理的几种方案~
阅读全文
摘要: 这一章我们单独针对大模型的幻觉问题,从幻觉类型,幻觉来源,幻觉检测,幻觉缓解这四个方向进行整理。这里就不细说任意一种方法了,直接用脑图概览地看下整个大模型幻觉领域
阅读全文
这一章我们单独针对大模型的幻觉问题,从幻觉类型,幻觉来源,幻觉检测,幻觉缓解这四个方向进行整理。这里就不细说任意一种方法了,直接用脑图概览地看下整个大模型幻觉领域
阅读全文
这一章我们单独针对大模型的幻觉问题,从幻觉类型,幻觉来源,幻觉检测,幻觉缓解这四个方向进行整理。这里就不细说任意一种方法了,直接用脑图概览地看下整个大模型幻觉领域
阅读全文
摘要: 这几章我们会针对经典RLHF算法存在的不稳定,成本高,效率低等问题聊聊新方案。第一章我们先说RLHF训练策略相关的方案,包括SLiC-HF,DPO,RRHF和RSO,他们之间有很多相似之处~
阅读全文
这几章我们会针对经典RLHF算法存在的不稳定,成本高,效率低等问题聊聊新方案。第一章我们先说RLHF训练策略相关的方案,包括SLiC-HF,DPO,RRHF和RSO,他们之间有很多相似之处~
阅读全文
这几章我们会针对经典RLHF算法存在的不稳定,成本高,效率低等问题聊聊新方案。第一章我们先说RLHF训练策略相关的方案,包括SLiC-HF,DPO,RRHF和RSO,他们之间有很多相似之处~
阅读全文
摘要: 在Chain of Thought出来后,出现过许多的优化方案,这一章我们类比人类已有的思维方式,就抽象思维和发散思维这两个方向,聊聊step back和diversity prompt
阅读全文
在Chain of Thought出来后,出现过许多的优化方案,这一章我们类比人类已有的思维方式,就抽象思维和发散思维这两个方向,聊聊step back和diversity prompt
阅读全文
在Chain of Thought出来后,出现过许多的优化方案,这一章我们类比人类已有的思维方式,就抽象思维和发散思维这两个方向,聊聊step back和diversity prompt
阅读全文
摘要: 之前我们主要唠了RLHF训练相关的方案,这一章我们主要针对RLHF的样本构建阶段,引入机器标注来降低人工标注的成本。主要介绍两个方案:RLAIF,和IBM的SALMON
阅读全文
之前我们主要唠了RLHF训练相关的方案,这一章我们主要针对RLHF的样本构建阶段,引入机器标注来降低人工标注的成本。主要介绍两个方案:RLAIF,和IBM的SALMON
阅读全文
之前我们主要唠了RLHF训练相关的方案,这一章我们主要针对RLHF的样本构建阶段,引入机器标注来降低人工标注的成本。主要介绍两个方案:RLAIF,和IBM的SALMON
阅读全文
摘要: 这一章我们重点讨论下如何注入某一类任务或能力的同时,尽可能不损失模型原有的通用指令理解能力。这里我们讨论两种方案,来尽可能降低通用能力的损失,一种数据方案,一种训练方案。
阅读全文
这一章我们重点讨论下如何注入某一类任务或能力的同时,尽可能不损失模型原有的通用指令理解能力。这里我们讨论两种方案,来尽可能降低通用能力的损失,一种数据方案,一种训练方案。
阅读全文
这一章我们重点讨论下如何注入某一类任务或能力的同时,尽可能不损失模型原有的通用指令理解能力。这里我们讨论两种方案,来尽可能降低通用能力的损失,一种数据方案,一种训练方案。
阅读全文
摘要: 本章介绍金融领域大模型智能体,并梳理金融LLM相关资源。大模型智能体当前集中在个股交易决策场景,而使用大模型智能体最显著的优势在于对海量信息的高效处理,存储和信息联想。FinMEM和FinAgent
阅读全文
本章介绍金融领域大模型智能体,并梳理金融LLM相关资源。大模型智能体当前集中在个股交易决策场景,而使用大模型智能体最显著的优势在于对海量信息的高效处理,存储和信息联想。FinMEM和FinAgent
阅读全文
本章介绍金融领域大模型智能体,并梳理金融LLM相关资源。大模型智能体当前集中在个股交易决策场景,而使用大模型智能体最显著的优势在于对海量信息的高效处理,存储和信息联想。FinMEM和FinAgent
阅读全文
摘要: 这一章我们针对真实世界中工具调用的多个问题,介绍微调(ToolLLM)和prompt(AnyTool)两种方案
阅读全文
这一章我们针对真实世界中工具调用的多个问题,介绍微调(ToolLLM)和prompt(AnyTool)两种方案
阅读全文
这一章我们针对真实世界中工具调用的多个问题,介绍微调(ToolLLM)和prompt(AnyTool)两种方案
阅读全文
摘要: 这一章介绍自主浏览操作网页的WebAgent和数据集:初级MiniWoB++,高级MIND2WEB,可交互WEBARENA,多模态WebVoyager,多轮对话WebLINX,复杂AutoWebGLM
阅读全文
这一章介绍自主浏览操作网页的WebAgent和数据集:初级MiniWoB++,高级MIND2WEB,可交互WEBARENA,多模态WebVoyager,多轮对话WebLINX,复杂AutoWebGLM
阅读全文
这一章介绍自主浏览操作网页的WebAgent和数据集:初级MiniWoB++,高级MIND2WEB,可交互WEBARENA,多模态WebVoyager,多轮对话WebLINX,复杂AutoWebGLM
阅读全文
摘要: 模型想要完成自主能力进化和自主能力获得,需要通过Self-Reflection from Past Experience来实现。那如何获得经历,把经历转化成经验,并在推理中使用呢?本章介绍三种方案
阅读全文
模型想要完成自主能力进化和自主能力获得,需要通过Self-Reflection from Past Experience来实现。那如何获得经历,把经历转化成经验,并在推理中使用呢?本章介绍三种方案
阅读全文
模型想要完成自主能力进化和自主能力获得,需要通过Self-Reflection from Past Experience来实现。那如何获得经历,把经历转化成经验,并在推理中使用呢?本章介绍三种方案
阅读全文
摘要: 这一章我们聊聊大模型表格理解任务,在大模型时代主要出现在包含表格的RAG任务,以及表格操作数据抽取文本对比等任务中。这一章先聊单一的文本模态,我们分别介绍微调和基于Prompt的两种方案。
阅读全文
这一章我们聊聊大模型表格理解任务,在大模型时代主要出现在包含表格的RAG任务,以及表格操作数据抽取文本对比等任务中。这一章先聊单一的文本模态,我们分别介绍微调和基于Prompt的两种方案。
阅读全文
这一章我们聊聊大模型表格理解任务,在大模型时代主要出现在包含表格的RAG任务,以及表格操作数据抽取文本对比等任务中。这一章先聊单一的文本模态,我们分别介绍微调和基于Prompt的两种方案。
阅读全文
摘要: 这一章我们聚焦多模态图表数据。先讨论下单纯使用prompt的情况下,图片和文字模态哪种表格模型理解的效果更好更好,再说下和表格相关的图表理解任务的微调方案
阅读全文
这一章我们聚焦多模态图表数据。先讨论下单纯使用prompt的情况下,图片和文字模态哪种表格模型理解的效果更好更好,再说下和表格相关的图表理解任务的微调方案
阅读全文
这一章我们聚焦多模态图表数据。先讨论下单纯使用prompt的情况下,图片和文字模态哪种表格模型理解的效果更好更好,再说下和表格相关的图表理解任务的微调方案
阅读全文
摘要: 前几章我们讨论了RLHF的样本构建优化和训练策略优化,这一章我们讨论两种不同的RL训练方案,分别是基于过程训练,和使用弱Teacher来监督强Student 循序渐进:PRM & ORM 想要获得过程
阅读全文
前几章我们讨论了RLHF的样本构建优化和训练策略优化,这一章我们讨论两种不同的RL训练方案,分别是基于过程训练,和使用弱Teacher来监督强Student 循序渐进:PRM & ORM 想要获得过程
阅读全文
前几章我们讨论了RLHF的样本构建优化和训练策略优化,这一章我们讨论两种不同的RL训练方案,分别是基于过程训练,和使用弱Teacher来监督强Student 循序渐进:PRM & ORM 想要获得过程
阅读全文
摘要: 这一章我们会先梳理DSPy相关的几篇核心论文了解下框架背后的设计思想和原理,然后以FinEval的单选题作为任务,从简单指令,COT指令,到采样Few-shot和优化指令给出代码示例和效果评估。
阅读全文
这一章我们会先梳理DSPy相关的几篇核心论文了解下框架背后的设计思想和原理,然后以FinEval的单选题作为任务,从简单指令,COT指令,到采样Few-shot和优化指令给出代码示例和效果评估。
阅读全文
这一章我们会先梳理DSPy相关的几篇核心论文了解下框架背后的设计思想和原理,然后以FinEval的单选题作为任务,从简单指令,COT指令,到采样Few-shot和优化指令给出代码示例和效果评估。
阅读全文
摘要: 这一章我们就重点关注描述性指令优化。我们先简单介绍下结构化Prompt编写,再聊聊从结构化多角度进行Prompt最优化迭代的算法方案UniPrompt
阅读全文
这一章我们就重点关注描述性指令优化。我们先简单介绍下结构化Prompt编写,再聊聊从结构化多角度进行Prompt最优化迭代的算法方案UniPrompt
阅读全文
这一章我们就重点关注描述性指令优化。我们先简单介绍下结构化Prompt编写,再聊聊从结构化多角度进行Prompt最优化迭代的算法方案UniPrompt
阅读全文
摘要: 前置判断模型回答是否需要联网,之前介绍了自我矛盾和自我拒绝者两个方案。这一章我们再补充几种基于微调,模型回答置信度和小模型代理回答的方案。
阅读全文
前置判断模型回答是否需要联网,之前介绍了自我矛盾和自我拒绝者两个方案。这一章我们再补充几种基于微调,模型回答置信度和小模型代理回答的方案。
阅读全文
前置判断模型回答是否需要联网,之前介绍了自我矛盾和自我拒绝者两个方案。这一章我们再补充几种基于微调,模型回答置信度和小模型代理回答的方案。
阅读全文
摘要: 常见的多智能体框架有协作模式,路由模式,复杂交互模式等等,这一章我们围绕智能体路由,也就是如何选择解决当前任务最合适的智能体展开,介绍基于领域,问题复杂度,和用户偏好进行智能体选择的几种方案
阅读全文
常见的多智能体框架有协作模式,路由模式,复杂交互模式等等,这一章我们围绕智能体路由,也就是如何选择解决当前任务最合适的智能体展开,介绍基于领域,问题复杂度,和用户偏好进行智能体选择的几种方案
阅读全文
常见的多智能体框架有协作模式,路由模式,复杂交互模式等等,这一章我们围绕智能体路由,也就是如何选择解决当前任务最合适的智能体展开,介绍基于领域,问题复杂度,和用户偏好进行智能体选择的几种方案
阅读全文
摘要: RAG这一章我们集中看下精排的部分。粗排和精排的主要差异其实在于效率和效果的balance。粗排和精排的主要差异其实在于效率和效果的balance。粗排模型复杂度更低,需要承上启下,用较低复杂度的模型
阅读全文
RAG这一章我们集中看下精排的部分。粗排和精排的主要差异其实在于效率和效果的balance。粗排和精排的主要差异其实在于效率和效果的balance。粗排模型复杂度更低,需要承上启下,用较低复杂度的模型
阅读全文
RAG这一章我们集中看下精排的部分。粗排和精排的主要差异其实在于效率和效果的balance。粗排和精排的主要差异其实在于效率和效果的balance。粗排模型复杂度更低,需要承上启下,用较低复杂度的模型
阅读全文
摘要: OpenAI的O-1出现前,其实就有大佬开始分析后面OpenAI的技术路线,其中一个方向就是从Pretrain-scaling,Post-Train-scaling向Inference Scaling的转变,这一章我们挑3篇inference-scaling相关的论文来聊聊,前两篇分别从聚合策略和搜索策略来优化广度推理,最后一篇全面的分析了各类广度深度推理策略的最优使用方案。
阅读全文
OpenAI的O-1出现前,其实就有大佬开始分析后面OpenAI的技术路线,其中一个方向就是从Pretrain-scaling,Post-Train-scaling向Inference Scaling的转变,这一章我们挑3篇inference-scaling相关的论文来聊聊,前两篇分别从聚合策略和搜索策略来优化广度推理,最后一篇全面的分析了各类广度深度推理策略的最优使用方案。
阅读全文
OpenAI的O-1出现前,其实就有大佬开始分析后面OpenAI的技术路线,其中一个方向就是从Pretrain-scaling,Post-Train-scaling向Inference Scaling的转变,这一章我们挑3篇inference-scaling相关的论文来聊聊,前两篇分别从聚合策略和搜索策略来优化广度推理,最后一篇全面的分析了各类广度深度推理策略的最优使用方案。
阅读全文
摘要: 这一章我们介绍GraphRAG范式,Graph RAG虽好但并非RAG的Silver Bullet,它有特定适合的问题和场景,更适合作为RAG中的一路召回,用来解决实体密集,依赖全局关系的信息召回。所以这一章我们来聊聊GraphRAG的实现和具体解决哪些问题。
阅读全文
这一章我们介绍GraphRAG范式,Graph RAG虽好但并非RAG的Silver Bullet,它有特定适合的问题和场景,更适合作为RAG中的一路召回,用来解决实体密集,依赖全局关系的信息召回。所以这一章我们来聊聊GraphRAG的实现和具体解决哪些问题。
阅读全文
这一章我们介绍GraphRAG范式,Graph RAG虽好但并非RAG的Silver Bullet,它有特定适合的问题和场景,更适合作为RAG中的一路召回,用来解决实体密集,依赖全局关系的信息召回。所以这一章我们来聊聊GraphRAG的实现和具体解决哪些问题。
阅读全文
摘要: 想要更优的Inference Time Scaling曲线,前提是模型本身是一个很强的Generator,已经拥有足够的生成合理推理过程的能力,同时还拥有很强的Verifier模型来对推理节点进行打分决策,并且二者可以在少人类监督的条件下不断迭代优化。这一章我们先聊聊如何让大模型"自学"推理思考,从而得到思考推理能力更强的Generator。
阅读全文
想要更优的Inference Time Scaling曲线,前提是模型本身是一个很强的Generator,已经拥有足够的生成合理推理过程的能力,同时还拥有很强的Verifier模型来对推理节点进行打分决策,并且二者可以在少人类监督的条件下不断迭代优化。这一章我们先聊聊如何让大模型"自学"推理思考,从而得到思考推理能力更强的Generator。
阅读全文
想要更优的Inference Time Scaling曲线,前提是模型本身是一个很强的Generator,已经拥有足够的生成合理推理过程的能力,同时还拥有很强的Verifier模型来对推理节点进行打分决策,并且二者可以在少人类监督的条件下不断迭代优化。这一章我们先聊聊如何让大模型"自学"推理思考,从而得到思考推理能力更强的Generator。
阅读全文
摘要: 在模型持续提升的道路上,只提升Generator能力是不够的,需要同步提升Supervisor、Verifier的能力,才能提供有效的监督优化信号。人类提供的监督信号有几类,包括人工直接生成最优回答
阅读全文
在模型持续提升的道路上,只提升Generator能力是不够的,需要同步提升Supervisor、Verifier的能力,才能提供有效的监督优化信号。人类提供的监督信号有几类,包括人工直接生成最优回答
阅读全文
在模型持续提升的道路上,只提升Generator能力是不够的,需要同步提升Supervisor、Verifier的能力,才能提供有效的监督优化信号。人类提供的监督信号有几类,包括人工直接生成最优回答
阅读全文
摘要: 前一阵多步RAG的风吹入了工业界,kimi推出了探索版本,各应用都推出了深度搜索,You.COM更是早就有了Genius的多步模式。其实都是类似multi-hop RAG的实现
阅读全文
前一阵多步RAG的风吹入了工业界,kimi推出了探索版本,各应用都推出了深度搜索,You.COM更是早就有了Genius的多步模式。其实都是类似multi-hop RAG的实现
阅读全文
前一阵多步RAG的风吹入了工业界,kimi推出了探索版本,各应用都推出了深度搜索,You.COM更是早就有了Genius的多步模式。其实都是类似multi-hop RAG的实现
阅读全文
摘要: 以上两个方向相对正交分别从Verifier和Generator两个方去尝试解决Scalable Oversight的问题,今天再聊一个相对Hybrid的方向,通过Verifier和Generator相互博弈来同时提升双方实力。这里分别介绍Anthropic的辩论法,和OpenAI的博弈法
阅读全文
以上两个方向相对正交分别从Verifier和Generator两个方去尝试解决Scalable Oversight的问题,今天再聊一个相对Hybrid的方向,通过Verifier和Generator相互博弈来同时提升双方实力。这里分别介绍Anthropic的辩论法,和OpenAI的博弈法
阅读全文
以上两个方向相对正交分别从Verifier和Generator两个方去尝试解决Scalable Oversight的问题,今天再聊一个相对Hybrid的方向,通过Verifier和Generator相互博弈来同时提升双方实力。这里分别介绍Anthropic的辩论法,和OpenAI的博弈法
阅读全文
摘要: 这一章我们先结合demo看下开源和闭源对结构化输出的支持,随后会介绍Constrained Decoding和Format Restricting Instructions 两种结构化输出约束方案,最后会给出结构化输出对比自然语言输出的一些观点。
阅读全文
这一章我们先结合demo看下开源和闭源对结构化输出的支持,随后会介绍Constrained Decoding和Format Restricting Instructions 两种结构化输出约束方案,最后会给出结构化输出对比自然语言输出的一些观点。
阅读全文
这一章我们先结合demo看下开源和闭源对结构化输出的支持,随后会介绍Constrained Decoding和Format Restricting Instructions 两种结构化输出约束方案,最后会给出结构化输出对比自然语言输出的一些观点。
阅读全文
摘要: O1之后,思维链的一个简单但之前都没进入视野的特征引起了大家的注意,那就是思考的长度对推理效果的影响,更准确来说是通过哪些思考步骤来有效延长思维长度对推理的影响。这一章我们着重讨论思考长度
阅读全文
O1之后,思维链的一个简单但之前都没进入视野的特征引起了大家的注意,那就是思考的长度对推理效果的影响,更准确来说是通过哪些思考步骤来有效延长思维长度对推理的影响。这一章我们着重讨论思考长度
阅读全文
O1之后,思维链的一个简单但之前都没进入视野的特征引起了大家的注意,那就是思考的长度对推理效果的影响,更准确来说是通过哪些思考步骤来有效延长思维长度对推理的影响。这一章我们着重讨论思考长度
阅读全文
摘要: 春节前DeepSeek R1和Kimi1.5炸翻天了,之前大家推测的O1的实现路径,多数都集中在MCTS推理优化,以及STaR等样本自优化方案等等,结果DeepSeek和Kiim直接出手揭示了reasoning的新路线不一定在SFT和Inference Scaling,也可以在RL。也算是Post Train阶段新的Scaling方向,几个核心Take Away包括
阅读全文
春节前DeepSeek R1和Kimi1.5炸翻天了,之前大家推测的O1的实现路径,多数都集中在MCTS推理优化,以及STaR等样本自优化方案等等,结果DeepSeek和Kiim直接出手揭示了reasoning的新路线不一定在SFT和Inference Scaling,也可以在RL。也算是Post Train阶段新的Scaling方向,几个核心Take Away包括
阅读全文
春节前DeepSeek R1和Kimi1.5炸翻天了,之前大家推测的O1的实现路径,多数都集中在MCTS推理优化,以及STaR等样本自优化方案等等,结果DeepSeek和Kiim直接出手揭示了reasoning的新路线不一定在SFT和Inference Scaling,也可以在RL。也算是Post Train阶段新的Scaling方向,几个核心Take Away包括
阅读全文
摘要: 我先按照自己的思路来梳理下R1之前整个模型思维链的发展过程,可以分成3个阶段:大模型能思考,外生慢思考,内生慢思考
阅读全文
我先按照自己的思路来梳理下R1之前整个模型思维链的发展过程,可以分成3个阶段:大模型能思考,外生慢思考,内生慢思考
阅读全文
我先按照自己的思路来梳理下R1之前整个模型思维链的发展过程,可以分成3个阶段:大模型能思考,外生慢思考,内生慢思考
阅读全文
摘要: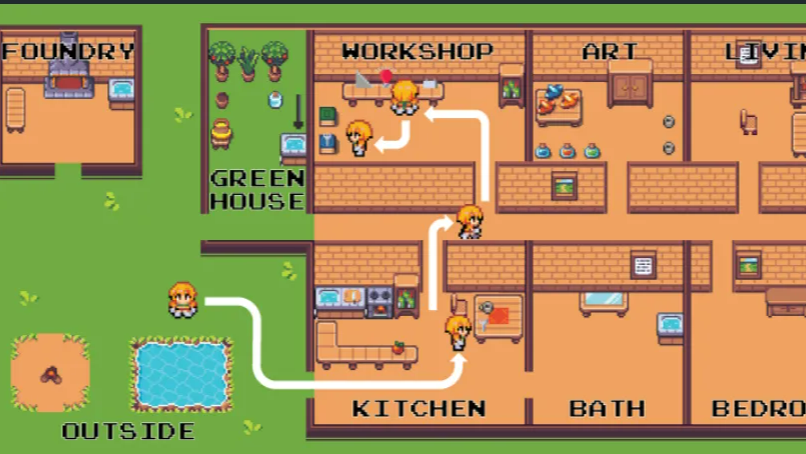 而Deep Research的效果类似O1的长思考是非常长的行为链,OpenAI也直接表明Deep Research是使用和O1相同的RL训练得到的。但这里比O1更难的就是数据集的设计,训练过程动态行为数据的引入和RL目标的选择。这一章我们分别介绍从两个不同角度使用RL优化Agent行为链路的方案,其中PaSa更类似Deep Research的链式行为链使用RL直接优化行为路径,而ARMAP则是使用RL优化Verifier指导行为链的生成。
阅读全文
而Deep Research的效果类似O1的长思考是非常长的行为链,OpenAI也直接表明Deep Research是使用和O1相同的RL训练得到的。但这里比O1更难的就是数据集的设计,训练过程动态行为数据的引入和RL目标的选择。这一章我们分别介绍从两个不同角度使用RL优化Agent行为链路的方案,其中PaSa更类似Deep Research的链式行为链使用RL直接优化行为路径,而ARMAP则是使用RL优化Verifier指导行为链的生成。
阅读全文
而Deep Research的效果类似O1的长思考是非常长的行为链,OpenAI也直接表明Deep Research是使用和O1相同的RL训练得到的。但这里比O1更难的就是数据集的设计,训练过程动态行为数据的引入和RL目标的选择。这一章我们分别介绍从两个不同角度使用RL优化Agent行为链路的方案,其中PaSa更类似Deep Research的链式行为链使用RL直接优化行为路径,而ARMAP则是使用RL优化Verifier指导行为链的生成。
阅读全文
摘要: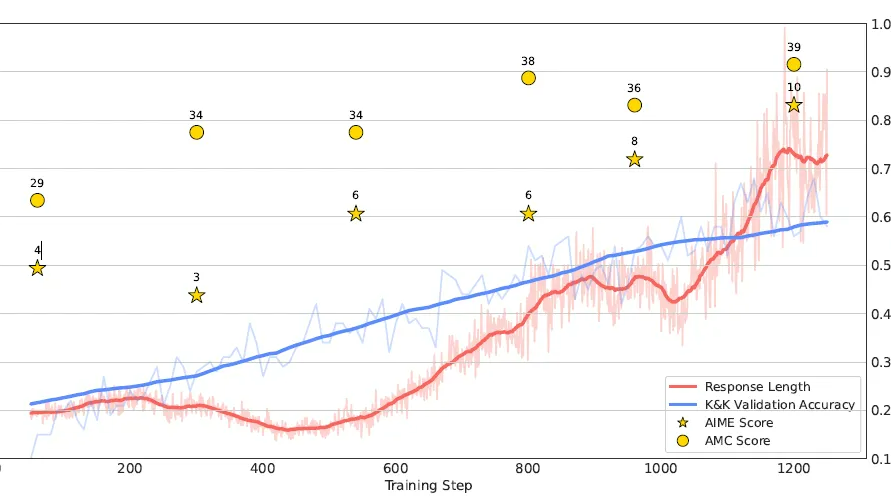 DeepSeek R1出来后业界都在争相复现R1的效果,这一章我们介绍两个复现项目SimpleRL和LogicRL,还有研究模型推理能力的Cognitive Behaviour,项目在复现R1的同时还针对R1训练策略中的几个关键点进行了讨论和消融实验,包括
阅读全文
DeepSeek R1出来后业界都在争相复现R1的效果,这一章我们介绍两个复现项目SimpleRL和LogicRL,还有研究模型推理能力的Cognitive Behaviour,项目在复现R1的同时还针对R1训练策略中的几个关键点进行了讨论和消融实验,包括
阅读全文
DeepSeek R1出来后业界都在争相复现R1的效果,这一章我们介绍两个复现项目SimpleRL和LogicRL,还有研究模型推理能力的Cognitive Behaviour,项目在复现R1的同时还针对R1训练策略中的几个关键点进行了讨论和消融实验,包括
阅读全文
摘要: 在DeepSeek-R1的开源狂欢之后,感觉不少朋友都陷入了**技术舒适区**,但其实当前的大模型技术只是跨进了应用阶段,可以探索的领域还有不少,所以这一章咱不聊论文了,偶尔不脚踏实地,单纯仰望天空,聊聊还有什么有趣值得探索的领域,哈哈有可能单纯是最近科幻小说看太多的产物~
阅读全文
在DeepSeek-R1的开源狂欢之后,感觉不少朋友都陷入了**技术舒适区**,但其实当前的大模型技术只是跨进了应用阶段,可以探索的领域还有不少,所以这一章咱不聊论文了,偶尔不脚踏实地,单纯仰望天空,聊聊还有什么有趣值得探索的领域,哈哈有可能单纯是最近科幻小说看太多的产物~
阅读全文
在DeepSeek-R1的开源狂欢之后,感觉不少朋友都陷入了**技术舒适区**,但其实当前的大模型技术只是跨进了应用阶段,可以探索的领域还有不少,所以这一章咱不聊论文了,偶尔不脚踏实地,单纯仰望天空,聊聊还有什么有趣值得探索的领域,哈哈有可能单纯是最近科幻小说看太多的产物~
阅读全文
摘要: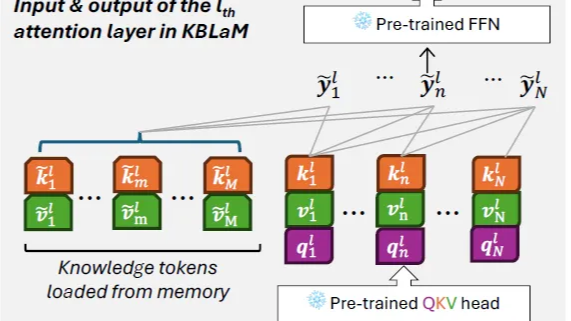 上一章畅想里面我们重点提及了大模型的记忆模块,包括模型能否持续更新记忆模块,模型能否把持续对记忆模块进行压缩更新在有限的参数中存储更高密度的知识信息,从而解决有限context和无限知识之间的矛盾。这一章我们分别介绍两种方案,一种是基于模型结构的Google提出的Titan模型结构,另一种是基于外挂知识库表征对齐的Kbalm
阅读全文
上一章畅想里面我们重点提及了大模型的记忆模块,包括模型能否持续更新记忆模块,模型能否把持续对记忆模块进行压缩更新在有限的参数中存储更高密度的知识信息,从而解决有限context和无限知识之间的矛盾。这一章我们分别介绍两种方案,一种是基于模型结构的Google提出的Titan模型结构,另一种是基于外挂知识库表征对齐的Kbalm
阅读全文
上一章畅想里面我们重点提及了大模型的记忆模块,包括模型能否持续更新记忆模块,模型能否把持续对记忆模块进行压缩更新在有限的参数中存储更高密度的知识信息,从而解决有限context和无限知识之间的矛盾。这一章我们分别介绍两种方案,一种是基于模型结构的Google提出的Titan模型结构,另一种是基于外挂知识库表征对齐的Kbalm
阅读全文
摘要: Context Cache的使用几乎已经是行业共识,目标是优化大模型首Token的推理延时,在多轮对话,超长System Prompt,超长结构化JSON和Few-shot等应用场景,是不可或缺的。这一章我们主要从原理、一些论文提出的优化项和VLLM开源项目入手,分析下context Cache的实现和适合场景。
阅读全文
Context Cache的使用几乎已经是行业共识,目标是优化大模型首Token的推理延时,在多轮对话,超长System Prompt,超长结构化JSON和Few-shot等应用场景,是不可或缺的。这一章我们主要从原理、一些论文提出的优化项和VLLM开源项目入手,分析下context Cache的实现和适合场景。
阅读全文
Context Cache的使用几乎已经是行业共识,目标是优化大模型首Token的推理延时,在多轮对话,超长System Prompt,超长结构化JSON和Few-shot等应用场景,是不可或缺的。这一章我们主要从原理、一些论文提出的优化项和VLLM开源项目入手,分析下context Cache的实现和适合场景。
阅读全文
摘要: 记忆存储是构建智能个性化、越用越懂你的Agent的核心挑战。上期我们探讨了模型方案实现长记忆存储,本期将聚焦工程实现层面。
- What:记忆内容(手动管理 vs 自动识别)
- How:记忆处理(压缩/抽取 vs 直接存储)
- Where:存储介质(内存/向量库/图数据库)
- Length:记忆长度管理(截断 vs 无限扩展)
- Format:上下文构建方式
- Retrieve:记忆检索机制
阅读全文
记忆存储是构建智能个性化、越用越懂你的Agent的核心挑战。上期我们探讨了模型方案实现长记忆存储,本期将聚焦工程实现层面。
- What:记忆内容(手动管理 vs 自动识别)
- How:记忆处理(压缩/抽取 vs 直接存储)
- Where:存储介质(内存/向量库/图数据库)
- Length:记忆长度管理(截断 vs 无限扩展)
- Format:上下文构建方式
- Retrieve:记忆检索机制
阅读全文
记忆存储是构建智能个性化、越用越懂你的Agent的核心挑战。上期我们探讨了模型方案实现长记忆存储,本期将聚焦工程实现层面。
- What:记忆内容(手动管理 vs 自动识别)
- How:记忆处理(压缩/抽取 vs 直接存储)
- Where:存储介质(内存/向量库/图数据库)
- Length:记忆长度管理(截断 vs 无限扩展)
- Format:上下文构建方式
- Retrieve:记忆检索机制
阅读全文
摘要: 无论智能体是1个还是多个,是编排驱动还是自主决策,是静态预定义还是动态生成,Context上下文的管理机制始终是设计的核心命脉。它决定了:每个节点使用哪些信息?分别更新或修改哪些信息?多步骤间如何传递?智能体间是否共享、如何共享?后续篇章我们将剖析多个热门开源项目,一探它们如何驾驭Context。
阅读全文
无论智能体是1个还是多个,是编排驱动还是自主决策,是静态预定义还是动态生成,Context上下文的管理机制始终是设计的核心命脉。它决定了:每个节点使用哪些信息?分别更新或修改哪些信息?多步骤间如何传递?智能体间是否共享、如何共享?后续篇章我们将剖析多个热门开源项目,一探它们如何驾驭Context。
阅读全文
无论智能体是1个还是多个,是编排驱动还是自主决策,是静态预定义还是动态生成,Context上下文的管理机制始终是设计的核心命脉。它决定了:每个节点使用哪些信息?分别更新或修改哪些信息?多步骤间如何传递?智能体间是否共享、如何共享?后续篇章我们将剖析多个热门开源项目,一探它们如何驾驭Context。
阅读全文
摘要: 承接上篇对Context Engineering的探讨,本文将聚焦多智能体框架中的上下文管理实践。我们将深入剖析两个代表性框架:字节跳动开源的基于预定义角色与Supervisor-Worker模式的 Deer-Flow ,以及在其基础上引入动态智能体构建能力的清华CoorAgent。通过对它们设计思路和实现细节的拆解,提炼出多智能体协作中高效管理上下文的关键策略。
阅读全文
承接上篇对Context Engineering的探讨,本文将聚焦多智能体框架中的上下文管理实践。我们将深入剖析两个代表性框架:字节跳动开源的基于预定义角色与Supervisor-Worker模式的 Deer-Flow ,以及在其基础上引入动态智能体构建能力的清华CoorAgent。通过对它们设计思路和实现细节的拆解,提炼出多智能体协作中高效管理上下文的关键策略。
阅读全文
承接上篇对Context Engineering的探讨,本文将聚焦多智能体框架中的上下文管理实践。我们将深入剖析两个代表性框架:字节跳动开源的基于预定义角色与Supervisor-Worker模式的 Deer-Flow ,以及在其基础上引入动态智能体构建能力的清华CoorAgent。通过对它们设计思路和实现细节的拆解,提炼出多智能体协作中高效管理上下文的关键策略。
阅读全文
摘要: 作为`结构化推理`的坚定支持者,我一度对MCP感到困惑:Agent和工具调用的概念早已普及,为何还需要MCP这样的额外设计呢?本文就来深入探讨MCP,看看它究竟解决了什么问题。我们将分几章解析MCP:本章理清基础概念和逻辑,后面我们直接以一个Agent为例演示全MCP接入的实现方案。
阅读全文
作为`结构化推理`的坚定支持者,我一度对MCP感到困惑:Agent和工具调用的概念早已普及,为何还需要MCP这样的额外设计呢?本文就来深入探讨MCP,看看它究竟解决了什么问题。我们将分几章解析MCP:本章理清基础概念和逻辑,后面我们直接以一个Agent为例演示全MCP接入的实现方案。
阅读全文
作为`结构化推理`的坚定支持者,我一度对MCP感到困惑:Agent和工具调用的概念早已普及,为何还需要MCP这样的额外设计呢?本文就来深入探讨MCP,看看它究竟解决了什么问题。我们将分几章解析MCP:本章理清基础概念和逻辑,后面我们直接以一个Agent为例演示全MCP接入的实现方案。
阅读全文
摘要: 🚀 核心挑战:如何为复杂数据分析任务构建可扩展的代码沙箱工具?本文将以E2B沙箱为例,通过对比Low-Level与FastMCP两种MCP-Server实现方案,深入剖析:
- Resource/Tool/Prompt的高阶应用场景
- 数据分析coding任务的难点和解决方案
- FastMCP在原有mcp-server的基础上做了哪些开发简化
阅读全文
🚀 核心挑战:如何为复杂数据分析任务构建可扩展的代码沙箱工具?本文将以E2B沙箱为例,通过对比Low-Level与FastMCP两种MCP-Server实现方案,深入剖析:
- Resource/Tool/Prompt的高阶应用场景
- 数据分析coding任务的难点和解决方案
- FastMCP在原有mcp-server的基础上做了哪些开发简化
阅读全文
🚀 核心挑战:如何为复杂数据分析任务构建可扩展的代码沙箱工具?本文将以E2B沙箱为例,通过对比Low-Level与FastMCP两种MCP-Server实现方案,深入剖析:
- Resource/Tool/Prompt的高阶应用场景
- 数据分析coding任务的难点和解决方案
- FastMCP在原有mcp-server的基础上做了哪些开发简化
阅读全文
摘要: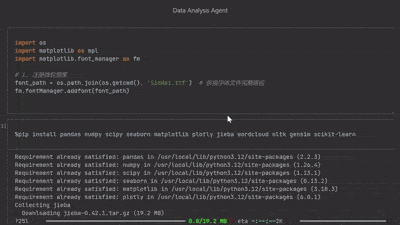 本文将带你从零搭建一个数据分析智能体,实现用户上传Excel并给出指令后,智能体能够深入分析数据、进行可视化,并以Jupyter Notebook形式返回结果。我们将重点讨论以下核心要点:智能体设计模式、Context Engineering、复杂任务Prompt设计
阅读全文
本文将带你从零搭建一个数据分析智能体,实现用户上传Excel并给出指令后,智能体能够深入分析数据、进行可视化,并以Jupyter Notebook形式返回结果。我们将重点讨论以下核心要点:智能体设计模式、Context Engineering、复杂任务Prompt设计
阅读全文
本文将带你从零搭建一个数据分析智能体,实现用户上传Excel并给出指令后,智能体能够深入分析数据、进行可视化,并以Jupyter Notebook形式返回结果。我们将重点讨论以下核心要点:智能体设计模式、Context Engineering、复杂任务Prompt设计
阅读全文
摘要:前两章我们讨论了JupyterAgent,当时用的是E2B的代码沙箱。这次我决定自己动手,用字节的TRAE从头构建一个Python代码沙箱,并加入MCP支持。完整代码已经开源在github.com/DSXiangLi/simple_sandbox
阅读全文
摘要: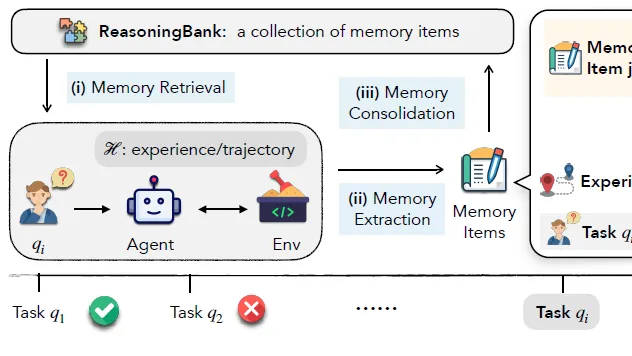 最近Agent Memory的论文如雨后春笋,我们将重点分析三篇代表性工作:
- CFGM:离线轨迹经验提取
- ReasoningBank:轨迹经验提取和test-time scaling结合
- MIRIX:提供完整记忆工程方案和全面记忆分类
阅读全文
最近Agent Memory的论文如雨后春笋,我们将重点分析三篇代表性工作:
- CFGM:离线轨迹经验提取
- ReasoningBank:轨迹经验提取和test-time scaling结合
- MIRIX:提供完整记忆工程方案和全面记忆分类
阅读全文
最近Agent Memory的论文如雨后春笋,我们将重点分析三篇代表性工作:
- CFGM:离线轨迹经验提取
- ReasoningBank:轨迹经验提取和test-time scaling结合
- MIRIX:提供完整记忆工程方案和全面记忆分类
阅读全文
摘要: 当大模型成为Agent,我们该如何教会它“行动”?我们将看到一条演进路线:从优化单一动作(ReTool),到学习长程规划(RAGEN),再到提升思考质量本身(RStar2),最后到一种不依赖外部奖励的、更底层的经验内化方式(Early Experience)。
阅读全文
当大模型成为Agent,我们该如何教会它“行动”?我们将看到一条演进路线:从优化单一动作(ReTool),到学习长程规划(RAGEN),再到提升思考质量本身(RStar2),最后到一种不依赖外部奖励的、更底层的经验内化方式(Early Experience)。
阅读全文
当大模型成为Agent,我们该如何教会它“行动”?我们将看到一条演进路线:从优化单一动作(ReTool),到学习长程规划(RAGEN),再到提升思考质量本身(RStar2),最后到一种不依赖外部奖励的、更底层的经验内化方式(Early Experience)。
阅读全文
摘要: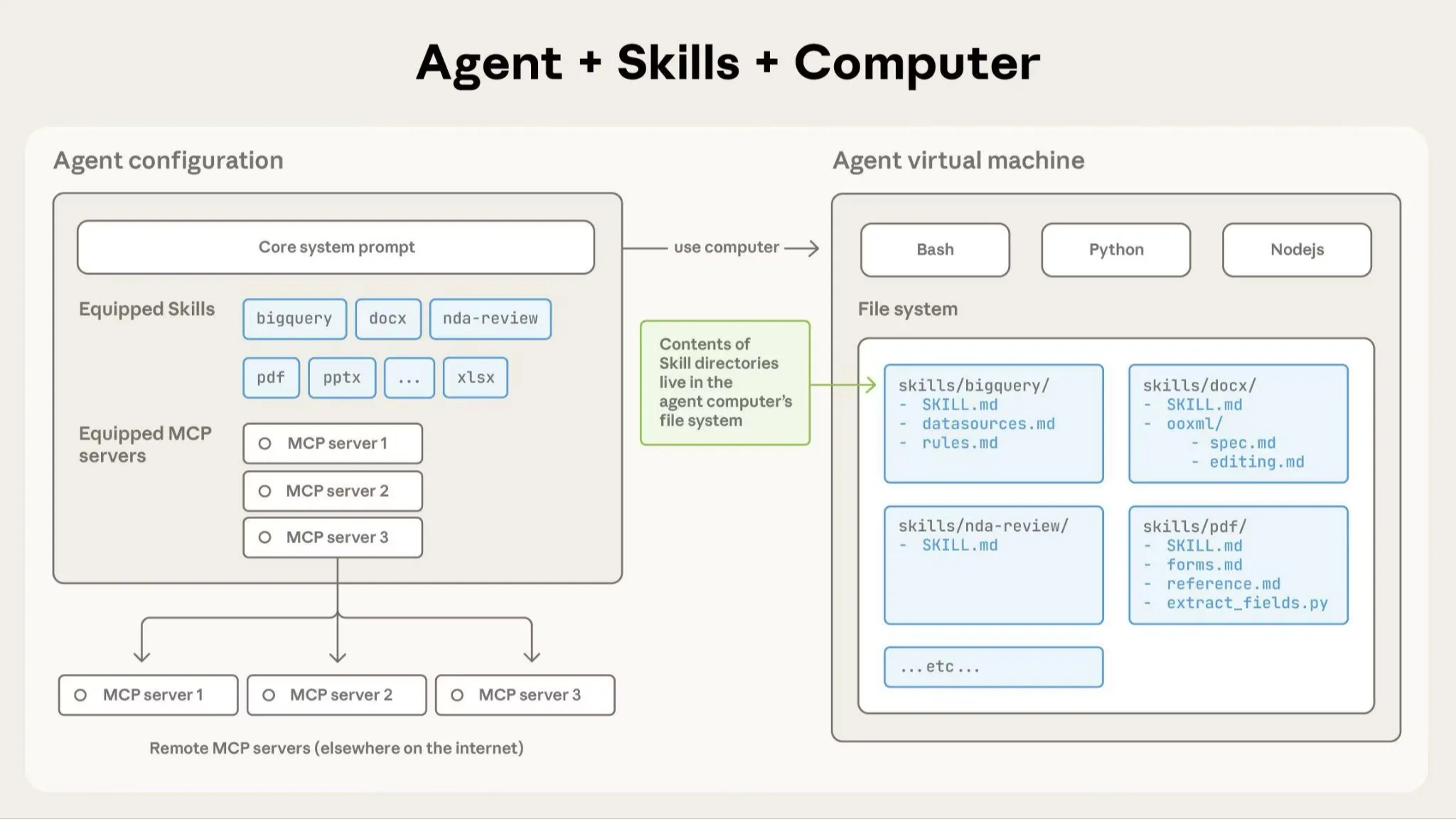 本文将深入解构 SKILLS 的三层分层加载架构,探讨它如何解决传统 Agent 上下文膨胀、领域任务成功率低的核心痛点。我们将通过一个完整流程展示 SKILLS 如何工作,并延伸思考它对现有 MCP、工作流和多智能体范式带来的冲击与重构可能。
阅读全文
本文将深入解构 SKILLS 的三层分层加载架构,探讨它如何解决传统 Agent 上下文膨胀、领域任务成功率低的核心痛点。我们将通过一个完整流程展示 SKILLS 如何工作,并延伸思考它对现有 MCP、工作流和多智能体范式带来的冲击与重构可能。
阅读全文
本文将深入解构 SKILLS 的三层分层加载架构,探讨它如何解决传统 Agent 上下文膨胀、领域任务成功率低的核心痛点。我们将通过一个完整流程展示 SKILLS 如何工作,并延伸思考它对现有 MCP、工作流和多智能体范式带来的冲击与重构可能。
阅读全文
摘要: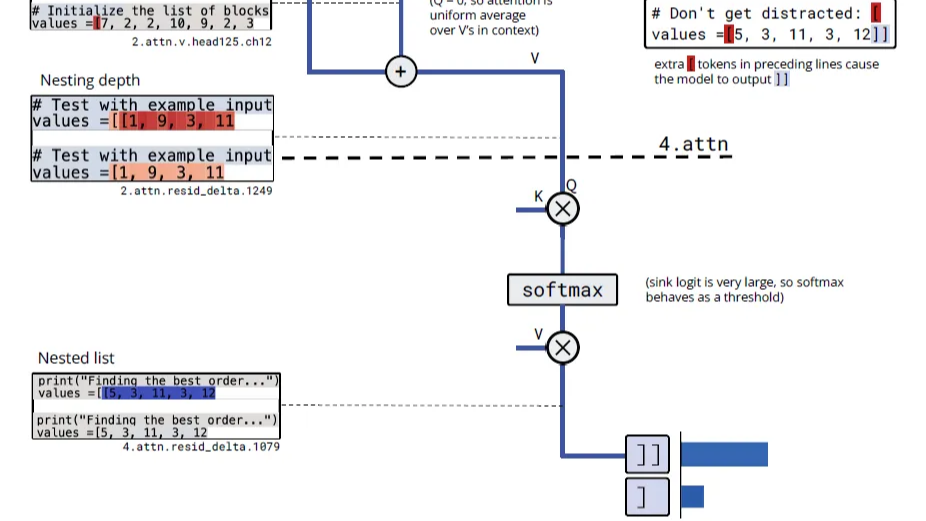 这一章我们通过三巨头 Google、OpenAI、Anthropic 三篇充满脑洞的论文,深入探讨模型内部状态的可访问性与可操控性。我们将从三个维度展开:模型是否有自我认知?如何引导这种认知?如何从数学和电路层面解释这种认知?
阅读全文
这一章我们通过三巨头 Google、OpenAI、Anthropic 三篇充满脑洞的论文,深入探讨模型内部状态的可访问性与可操控性。我们将从三个维度展开:模型是否有自我认知?如何引导这种认知?如何从数学和电路层面解释这种认知?
阅读全文
这一章我们通过三巨头 Google、OpenAI、Anthropic 三篇充满脑洞的论文,深入探讨模型内部状态的可访问性与可操控性。我们将从三个维度展开:模型是否有自我认知?如何引导这种认知?如何从数学和电路层面解释这种认知?
阅读全文
摘要: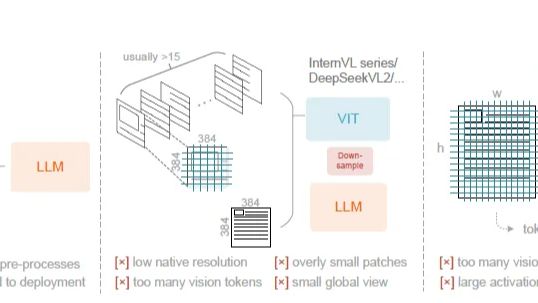 很多人认为:图像Token的信息密度和效率远不如文本。但 DeepSeek-OCR的核心价值就是它通过一套巧妙的*串行视觉压缩架构*,实现1个视觉Token近乎无损地承载10个文本Token的惊人效率。本文我们借着DeepSeek-OCR回顾下多模态的底层技术演进。
阅读全文
很多人认为:图像Token的信息密度和效率远不如文本。但 DeepSeek-OCR的核心价值就是它通过一套巧妙的*串行视觉压缩架构*,实现1个视觉Token近乎无损地承载10个文本Token的惊人效率。本文我们借着DeepSeek-OCR回顾下多模态的底层技术演进。
阅读全文
很多人认为:图像Token的信息密度和效率远不如文本。但 DeepSeek-OCR的核心价值就是它通过一套巧妙的*串行视觉压缩架构*,实现1个视觉Token近乎无损地承载10个文本Token的惊人效率。本文我们借着DeepSeek-OCR回顾下多模态的底层技术演进。
阅读全文
摘要: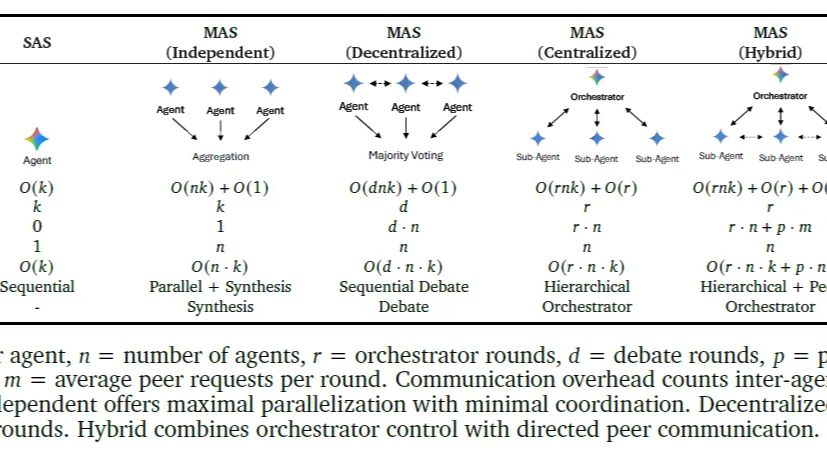 随着模型能力的提升,工业界开始反思:盲目增加智能体、盲目增加工具调用次数真的能“大力出奇迹”吗?本文串联了两篇Google论文,从宏观的架构选择到微观的工具预算感知,探讨如何科学地构建高效的Agent系统。
阅读全文
随着模型能力的提升,工业界开始反思:盲目增加智能体、盲目增加工具调用次数真的能“大力出奇迹”吗?本文串联了两篇Google论文,从宏观的架构选择到微观的工具预算感知,探讨如何科学地构建高效的Agent系统。
阅读全文
随着模型能力的提升,工业界开始反思:盲目增加智能体、盲目增加工具调用次数真的能“大力出奇迹”吗?本文串联了两篇Google论文,从宏观的架构选择到微观的工具预算感知,探讨如何科学地构建高效的Agent系统。
阅读全文
摘要: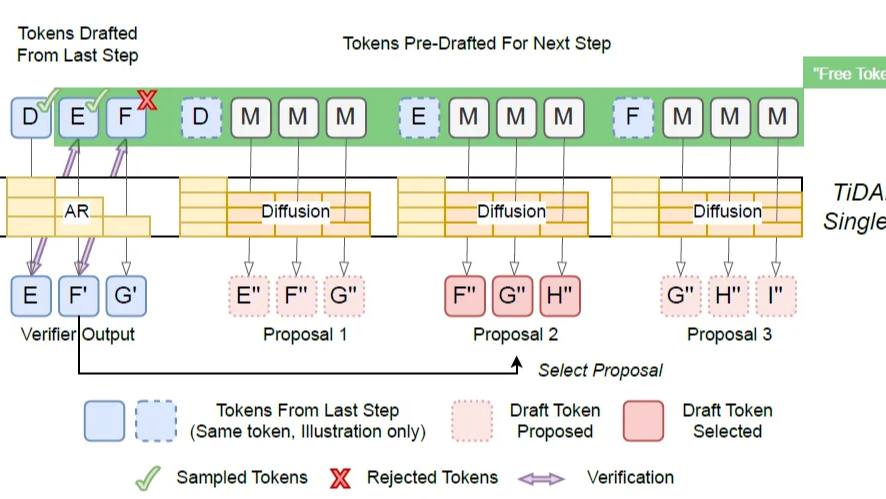 慢思考的本质依然是通过生成更多的显性 Token 来换取计算时间。为了想得深,必须说得多。这一章的四篇论文都在尝试:能否在不输出废话的情况下,让模型在内部“空转”思考? 甚至打破自回归全局规划?
阅读全文
慢思考的本质依然是通过生成更多的显性 Token 来换取计算时间。为了想得深,必须说得多。这一章的四篇论文都在尝试:能否在不输出废话的情况下,让模型在内部“空转”思考? 甚至打破自回归全局规划?
阅读全文
慢思考的本质依然是通过生成更多的显性 Token 来换取计算时间。为了想得深,必须说得多。这一章的四篇论文都在尝试:能否在不输出废话的情况下,让模型在内部“空转”思考? 甚至打破自回归全局规划?
阅读全文
摘要: 在 LLM 发展的上半场,我们执着于不断拉长 Context Window,从 8K 到 128K 甚至百万级别。但在下半场我们围绕Coding这个核心视角来寻找一些新的上下文管理的思路
阅读全文
在 LLM 发展的上半场,我们执着于不断拉长 Context Window,从 8K 到 128K 甚至百万级别。但在下半场我们围绕Coding这个核心视角来寻找一些新的上下文管理的思路
阅读全文
在 LLM 发展的上半场,我们执着于不断拉长 Context Window,从 8K 到 128K 甚至百万级别。但在下半场我们围绕Coding这个核心视角来寻找一些新的上下文管理的思路
阅读全文
摘要: 本文不输出权威指南,只是一位一线算法工程师和AI不算peace的合作场景还原。系列第一篇,我们将从最基础的“磨合期”开始聊起。
技术标签:#opencode,#browser-use,#单智能体,#Agents.md
阅读全文
本文不输出权威指南,只是一位一线算法工程师和AI不算peace的合作场景还原。系列第一篇,我们将从最基础的“磨合期”开始聊起。
技术标签:#opencode,#browser-use,#单智能体,#Agents.md
阅读全文
本文不输出权威指南,只是一位一线算法工程师和AI不算peace的合作场景还原。系列第一篇,我们将从最基础的“磨合期”开始聊起。
技术标签:#opencode,#browser-use,#单智能体,#Agents.md
阅读全文
摘要: 这一章我们演示用龙虾制作我的专属技能-“中医方剂卡片”的全过程,同时轻度解密龙虾的几个核心设计,看看龙虾为何俘获了这么多人的心~
阅读全文
这一章我们演示用龙虾制作我的专属技能-“中医方剂卡片”的全过程,同时轻度解密龙虾的几个核心设计,看看龙虾为何俘获了这么多人的心~
阅读全文
这一章我们演示用龙虾制作我的专属技能-“中医方剂卡片”的全过程,同时轻度解密龙虾的几个核心设计,看看龙虾为何俘获了这么多人的心~
阅读全文
摘要: 这一章我们会解锁 Claude 的 teammate 模式,尝试开发一款 AI-oriented + 中医学习小游戏。在遍地都是“成功学”的今天,第一版游戏更像是大型事故现场>_<
阅读全文
这一章我们会解锁 Claude 的 teammate 模式,尝试开发一款 AI-oriented + 中医学习小游戏。在遍地都是“成功学”的今天,第一版游戏更像是大型事故现场>_<
阅读全文
这一章我们会解锁 Claude 的 teammate 模式,尝试开发一款 AI-oriented + 中医学习小游戏。在遍地都是“成功学”的今天,第一版游戏更像是大型事故现场>_<
阅读全文
摘要: 话接上回,咱继续做中医小游戏,正所谓关关难过关关过,踩完这坑踩那坑。咱一边用Claude code构建我心中的“药灵山谷”,一边聊聊开发过程中碰到的好用的技能!
阅读全文
话接上回,咱继续做中医小游戏,正所谓关关难过关关过,踩完这坑踩那坑。咱一边用Claude code构建我心中的“药灵山谷”,一边聊聊开发过程中碰到的好用的技能!
阅读全文
话接上回,咱继续做中医小游戏,正所谓关关难过关关过,踩完这坑踩那坑。咱一边用Claude code构建我心中的“药灵山谷”,一边聊聊开发过程中碰到的好用的技能!
阅读全文
摘要: 话接上文,咱接着做中医小游戏。这一章我们会聊到:
- 开发流程中的核心实践:重构、版本控制、进度管理
- 技能进阶:创建技能、测试技能、提高技能引用率
- Claude Design 使用体验
阅读全文
话接上文,咱接着做中医小游戏。这一章我们会聊到:
- 开发流程中的核心实践:重构、版本控制、进度管理
- 技能进阶:创建技能、测试技能、提高技能引用率
- Claude Design 使用体验
阅读全文
话接上文,咱接着做中医小游戏。这一章我们会聊到:
- 开发流程中的核心实践:重构、版本控制、进度管理
- 技能进阶:创建技能、测试技能、提高技能引用率
- Claude Design 使用体验
阅读全文
摘要: 本章我们尝试复现“图像文字元素编辑”功能,代码已经上传到Github。AI 生图配合文字元素编辑,确实能解决很多场景上AI生图无法直接落得的业务问题,感兴趣的朋友可以clone直接使用。
阅读全文
本章我们尝试复现“图像文字元素编辑”功能,代码已经上传到Github。AI 生图配合文字元素编辑,确实能解决很多场景上AI生图无法直接落得的业务问题,感兴趣的朋友可以clone直接使用。
阅读全文
本章我们尝试复现“图像文字元素编辑”功能,代码已经上传到Github。AI 生图配合文字元素编辑,确实能解决很多场景上AI生图无法直接落得的业务问题,感兴趣的朋友可以clone直接使用。
阅读全文
摘要: 有一阵没做游戏了,咱接着回来做中医游戏,这期咱们聊聊怎么给游戏NPC装个"智能大脑",顺便看看开发过程中Hook这个老朋友的新玩法。项目代码在这里[tcm_odyssey]
阅读全文
有一阵没做游戏了,咱接着回来做中医游戏,这期咱们聊聊怎么给游戏NPC装个"智能大脑",顺便看看开发过程中Hook这个老朋友的新玩法。项目代码在这里[tcm_odyssey]
阅读全文
有一阵没做游戏了,咱接着回来做中医游戏,这期咱们聊聊怎么给游戏NPC装个"智能大脑",顺便看看开发过程中Hook这个老朋友的新玩法。项目代码在这里[tcm_odyssey]
阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号