摘要:  本文不输出权威指南,只是一位一线算法工程师和AI不算peace的合作场景还原。系列第一篇,我们将从最基础的“磨合期”开始聊起。
技术标签:#opencode,#browser-use,#单智能体,#Agents.md 阅读全文
本文不输出权威指南,只是一位一线算法工程师和AI不算peace的合作场景还原。系列第一篇,我们将从最基础的“磨合期”开始聊起。
技术标签:#opencode,#browser-use,#单智能体,#Agents.md 阅读全文
本文不输出权威指南,只是一位一线算法工程师和AI不算peace的合作场景还原。系列第一篇,我们将从最基础的“磨合期”开始聊起。
技术标签:#opencode,#browser-use,#单智能体,#Agents.md 阅读全文
posted @ 2026-03-10 07:41
风雨中的小七
阅读(87)
评论(0)
推荐(0)
 在 LLM 发展的上半场,我们执着于不断拉长 Context Window,从 8K 到 128K 甚至百万级别。但在下半场我们围绕Coding这个核心视角来寻找一些新的上下文管理的思路
在 LLM 发展的上半场,我们执着于不断拉长 Context Window,从 8K 到 128K 甚至百万级别。但在下半场我们围绕Coding这个核心视角来寻找一些新的上下文管理的思路 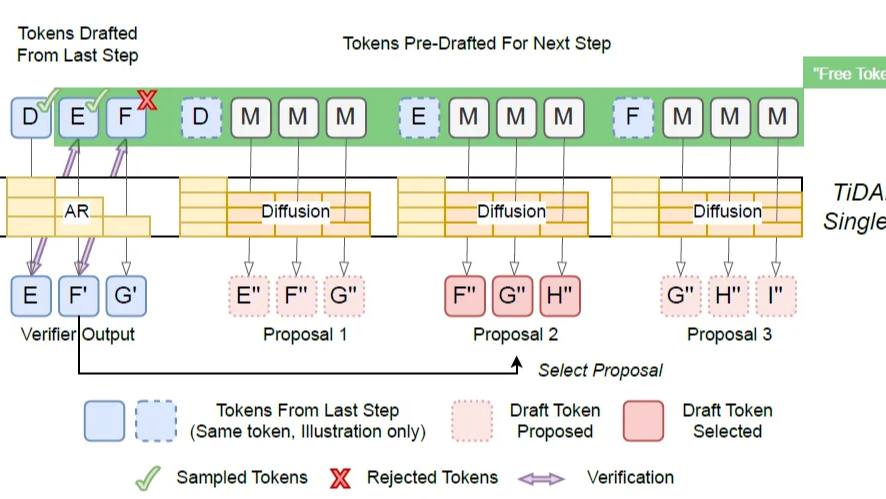 慢思考的本质依然是通过生成更多的显性 Token 来换取计算时间。为了想得深,必须说得多。这一章的四篇论文都在尝试:能否在不输出废话的情况下,让模型在内部“空转”思考? 甚至打破自回归全局规划?
慢思考的本质依然是通过生成更多的显性 Token 来换取计算时间。为了想得深,必须说得多。这一章的四篇论文都在尝试:能否在不输出废话的情况下,让模型在内部“空转”思考? 甚至打破自回归全局规划? 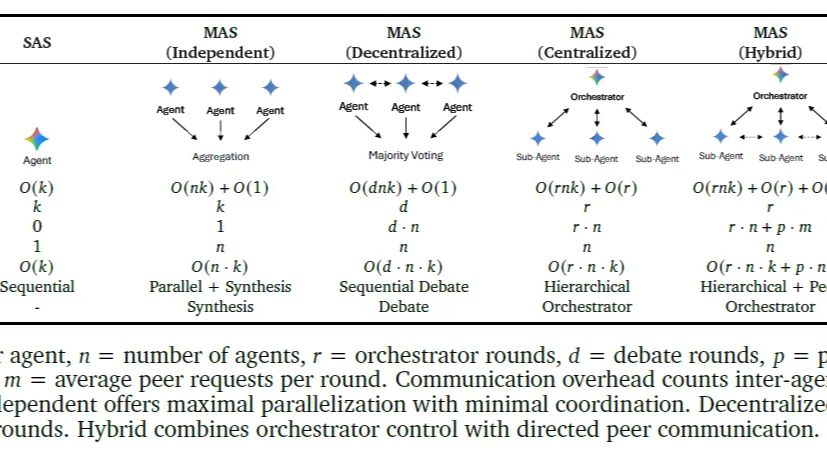 随着模型能力的提升,工业界开始反思:盲目增加智能体、盲目增加工具调用次数真的能“大力出奇迹”吗?本文串联了两篇Google论文,从宏观的架构选择到微观的工具预算感知,探讨如何科学地构建高效的Agent系统。
随着模型能力的提升,工业界开始反思:盲目增加智能体、盲目增加工具调用次数真的能“大力出奇迹”吗?本文串联了两篇Google论文,从宏观的架构选择到微观的工具预算感知,探讨如何科学地构建高效的Agent系统。 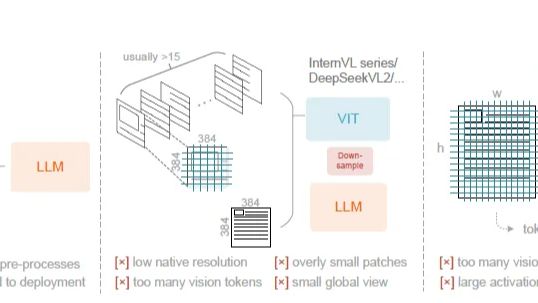 很多人认为:图像Token的信息密度和效率远不如文本。但 DeepSeek-OCR的核心价值就是它通过一套巧妙的*串行视觉压缩架构*,实现1个视觉Token近乎无损地承载10个文本Token的惊人效率。本文我们借着DeepSeek-OCR回顾下多模态的底层技术演进。
很多人认为:图像Token的信息密度和效率远不如文本。但 DeepSeek-OCR的核心价值就是它通过一套巧妙的*串行视觉压缩架构*,实现1个视觉Token近乎无损地承载10个文本Token的惊人效率。本文我们借着DeepSeek-OCR回顾下多模态的底层技术演进。 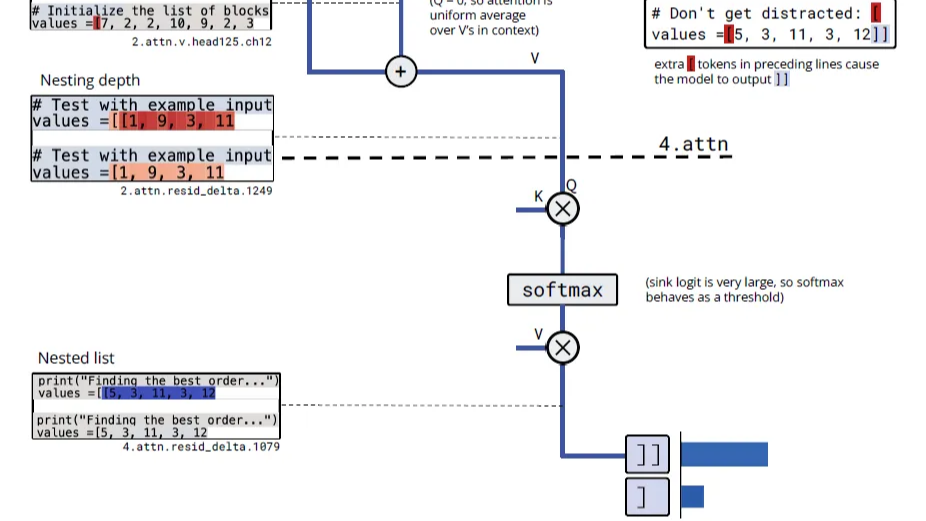 这一章我们通过三巨头 Google、OpenAI、Anthropic 三篇充满脑洞的论文,深入探讨模型内部状态的可访问性与可操控性。我们将从三个维度展开:模型是否有自我认知?如何引导这种认知?如何从数学和电路层面解释这种认知?
这一章我们通过三巨头 Google、OpenAI、Anthropic 三篇充满脑洞的论文,深入探讨模型内部状态的可访问性与可操控性。我们将从三个维度展开:模型是否有自我认知?如何引导这种认知?如何从数学和电路层面解释这种认知? 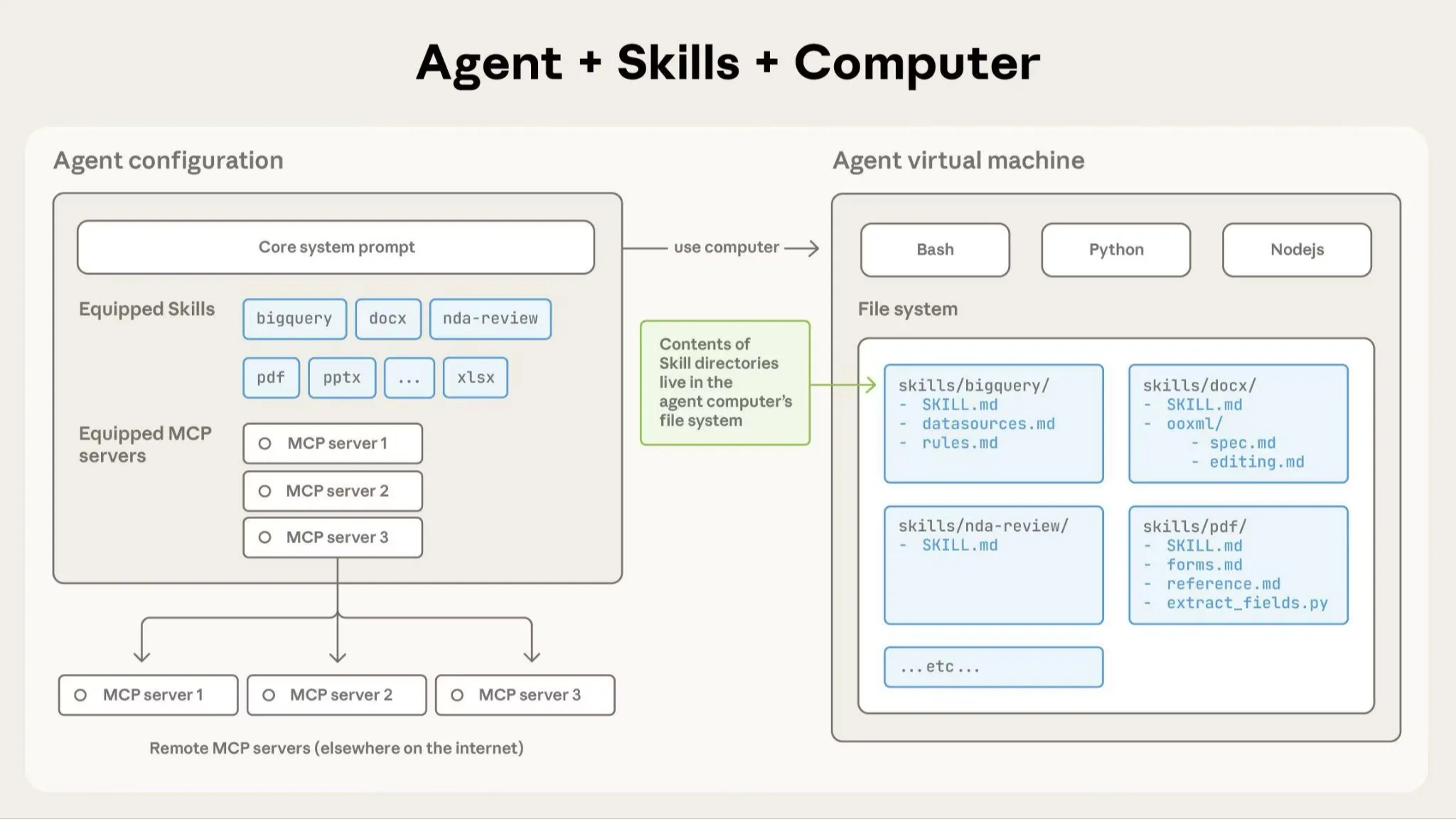 本文将深入解构 SKILLS 的三层分层加载架构,探讨它如何解决传统 Agent 上下文膨胀、领域任务成功率低的核心痛点。我们将通过一个完整流程展示 SKILLS 如何工作,并延伸思考它对现有 MCP、工作流和多智能体范式带来的冲击与重构可能。
本文将深入解构 SKILLS 的三层分层加载架构,探讨它如何解决传统 Agent 上下文膨胀、领域任务成功率低的核心痛点。我们将通过一个完整流程展示 SKILLS 如何工作,并延伸思考它对现有 MCP、工作流和多智能体范式带来的冲击与重构可能。  当大模型成为Agent,我们该如何教会它“行动”?我们将看到一条演进路线:从优化单一动作(ReTool),到学习长程规划(RAGEN),再到提升思考质量本身(RStar2),最后到一种不依赖外部奖励的、更底层的经验内化方式(Early Experience)。
当大模型成为Agent,我们该如何教会它“行动”?我们将看到一条演进路线:从优化单一动作(ReTool),到学习长程规划(RAGEN),再到提升思考质量本身(RStar2),最后到一种不依赖外部奖励的、更底层的经验内化方式(Early Experience)。 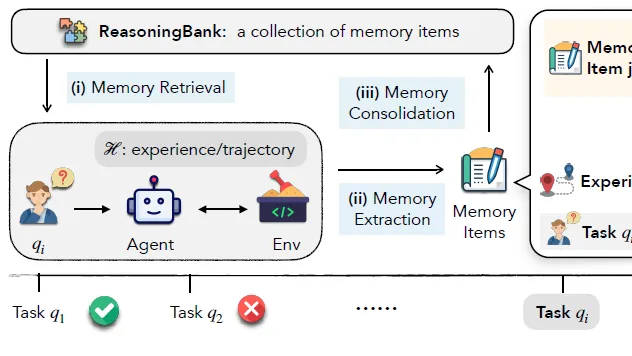 最近Agent Memory的论文如雨后春笋,我们将重点分析三篇代表性工作:
- CFGM:离线轨迹经验提取
- ReasoningBank:轨迹经验提取和test-time scaling结合
- MIRIX:提供完整记忆工程方案和全面记忆分类
最近Agent Memory的论文如雨后春笋,我们将重点分析三篇代表性工作:
- CFGM:离线轨迹经验提取
- ReasoningBank:轨迹经验提取和test-time scaling结合
- MIRIX:提供完整记忆工程方案和全面记忆分类  浙公网安备 33010602011771号
浙公网安备 33010602011771号