

Redis源码阅读(二)高可用设计——复制
Redis源码阅读(二)高可用设计-复制
复制的概念:Redis的复制简单理解就是一个Redis服务器从另一台Redis服务器复制所有的Redis数据库数据,能保持两台Redis服务器的数据库数据一致。
使用场景:复制机制很实用,在客户端并发访问量很大,单台Redis扛不住的情况下,可以部署多台Redis复制相同的数据,共同对外提供服务,提高Redis并发访问处理能力。当然这种通过复制方式部署多台Redis以提高并发处理能力的方式只适用于客户端大部分访问为读数据请求的场景。此外,Redis从2.8版本以后支持的Sentinel高可用机制(热备)也需要依赖复制功能来同步几台机器的Redis数据。
个人在阅读源码时比较关心的几个复制问题如下:
- Redis复制时,机器之间传递的数据结构是怎样的?
- 为保证各节点的数据一致,应该要经常进行数据同步,Redis数据量很大时,每次同步都全量肯定不现实,那Redis中的增量同步是如何实现的?
- 如果从节点断线后重连到主节点,是否会触发全量同步,在网络状况不好的情况下可能会出现频繁的重连,如果每次重连再进行全量同步会加重网络负担,Redis是否在这种情况下做了增量同步?
接下来会介绍Redis复制的主要流程,并针对这几个问题来看Redis源码的实现。
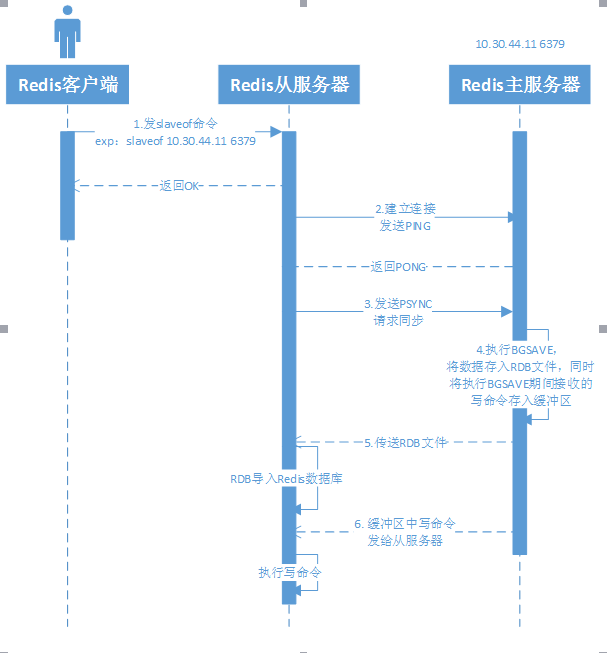
1. 初次复制的流程
- 客户端发slaveof命令给从服务器,给从服务器指定需要复制的主服务器ip和端口
- 从服务器收到slaveof命令后,创建到主服务器的连接并发送PING来确认连接有效
- 从服务器接收到主服务器返回PONG,确认可以和主服务器通信后,向主服务器发送”PSYNC ? -1”命令,申请执行初次的全量同步
- 主服务器收到PSYNC,开始在内部执行BGSAVE命令,将数据库写到RDB文件中;注意,在执行BGSAVE期间,主服务器还可接收客户端的写命令,这些命令会向缓冲区中写一份,确保在执行BGSAVE期间发生的写命令也可以同步给从服务器
- 主服务器执行BGSAVE后,发送RDB文件给从服务器,从服务器导入RDB文件
- 发送RDB完成后,主服务器将缓冲区中的写命令也发送给从服务器,从服务器执行这些写命令
备注:这里介绍的是主要流程,忽略了身份认证的步骤
复制时机器间传递的数据结构是RDB文件;RDB是Redis持久化的一种方式;RDB文件中记录的是Redis数据库中所有的key-value对;这种持久方式在任意时刻开启都能保证持久化的数据是Redis中完整数据,与此相对的AOF持久化方式则是将所有写命令计入到文件中,这种文件保留的数据只是从开启AOF的那一刻开始,开启之前的数据是无法保存的,所以复制机制没有使用AOF文件。
源码中,服务器处理slaveof命令的处理器是slaveofCommand()函数
void slaveofCommand(redisClient *c) { //想让一个节点A通过slaveof成为另一个节点B的slave,则必须是B在单机模式下 // ....... /* Check if we are already attached to the specified slave */ // 检查输入的 host 和 port 是否服务器目前的主服务器 // 如果是的话,向客户端返回 +OK ,不做其他动作 //说明之前已经slaveof ip port过,这次又执行该命令,说明之前已经连接建立成功过了 if (server.masterhost && !strcasecmp(server.masterhost,c->argv[1]->ptr) && server.masterport == port) { redisLog(REDIS_NOTICE,"SLAVE OF would result into synchronization with the master we are already connected with. No operation performed."); addReplySds(c,sdsnew("+OK Already connected to specified master\r\n"));//向从服务器的redis-cli客户端发送该命令 return; } //第一次执行slaveof ip port,新的ip或者port /* There was no previous master or the user specified a different one, * we can continue. */ // 没有前任主服务器,或者客户端指定了新的主服务器 // 开始执行复制操作 replicationSetMaster(c->argv[1]->ptr, port); redisLog(REDIS_NOTICE,"SLAVE OF %s:%d enabled (user request)", server.masterhost, server.masterport); } addReply(c,shared.ok); }
在该函数中通过replicationSetMaster()函数设置要连接的主服务器的IP和端口,并将服务器连接状态server.repl_state置为REDIS_REPL_CONNECT。从而会触发connectWithMaster()函数将连接状态置为REDIS_REPL_CONNECTING,继而触发slaveTryPartialResynchronization()函数来发送PSYNC命令。connectWithMaster函数创建连接套接字专门用于主备数据同步
// 以非阻塞方式连接主服务器 int connectWithMaster(void) { int fd; // 连接主服务器 fd = anetTcpNonBlockConnect(NULL,server.masterhost,server.masterport); if (fd == -1) { redisLog(REDIS_WARNING,"Unable to connect to MASTER: %s", strerror(errno)); return REDIS_ERR; } // 监听主服务器 fd 的读和写事件,并绑定文件事件处理器 if (aeCreateFileEvent(server.el,fd,AE_READABLE|AE_WRITABLE,syncWithMaster,NULL) == AE_ERR) { close(fd); redisLog(REDIS_WARNING,"Can't create readable event for SYNC"); return REDIS_ERR; } // 初始化统计变量 server.repl_transfer_lastio = server.unixtime; server.repl_transfer_s = fd; // 将状态改为已连接 server.repl_state = REDIS_REPL_CONNECTING; return REDIS_OK; }
看下slaveTryPartialResynchronization()的具体实现实现
int slaveTryPartialResynchronization(int fd) { char *psync_runid; char psync_offset[32]; sds reply; server.repl_master_initial_offset = -1; //例如从服务器之前和主服务器连接上,并同步了数据,中途端了,则连接断了后会在replicationCacheMaster把server.cached_master = server.master; //表示之前有连接到过服务器 if (server.cached_master) { // 缓存存在,尝试部分重同步 // 命令为 "PSYNC <master_run_id> <repl_offset>" psync_runid = server.cached_master->replrunid; snprintf(psync_offset,sizeof(psync_offset),"%lld", server.cached_master->reploff+1); redisLog(REDIS_NOTICE,"Trying a partial resynchronization (request %s:%s).", psync_runid, psync_offset); } else { // 缓存不存在 // 发送 "PSYNC ? -1" ,要求完整重同步 redisLog(REDIS_NOTICE,"Partial resynchronization not possible (no cached master)"); psync_runid = "?"; memcpy(psync_offset,"-1",3); // } /* Issue the PSYNC command */ // 向主服务器发送 PSYNC 命令 reply = sendSynchronousCommand(fd,"PSYNC",psync_runid,psync_offset,NULL); // 接收到 FULLRESYNC ,进行 full-resync if (!strncmp(reply,"+FULLRESYNC",11)) { char *runid = NULL, *offset = NULL; /* FULL RESYNC, parse the reply in order to extract the run id * and the replication offset. */ // 分析并记录主服务器的 run id runid = strchr(reply,' '); if (runid) { runid++; offset = strchr(runid,' '); if (offset) offset++; } // 检查 run id 的合法性 if (!runid || !offset || (offset-runid-1) != REDIS_RUN_ID_SIZE) { redisLog(REDIS_WARNING, "Master replied with wrong +FULLRESYNC syntax."); // 主服务器支持 PSYNC ,但是却发来了异常的 run id // 只好将 run id 设为 0 ,让下次 PSYNC 时失败 memset(server.repl_master_runid,0,REDIS_RUN_ID_SIZE+1); } else { // 保存 run id memcpy(server.repl_master_runid, runid, offset-runid-1); server.repl_master_runid[REDIS_RUN_ID_SIZE] = '\0'; // 以及 initial offset server.repl_master_initial_offset = strtoll(offset,NULL,10); // 打印日志,这是一个 FULL resync redisLog(REDIS_NOTICE,"Full resync from master: %s:%lld", server.repl_master_runid, server.repl_master_initial_offset); } /* We are going to full resync, discard the cached master structure. */ // 要开始完整重同步,缓存中的 master 已经没用了,清除它 replicationDiscardCachedMaster(); sdsfree(reply); // 返回状态 return PSYNC_FULLRESYNC; } // 接收到 CONTINUE ,进行 partial resync if (!strncmp(reply,"+CONTINUE",9)) { /* Partial resync was accepted, set the replication state accordingly */ redisLog(REDIS_NOTICE, "Successful partial resynchronization with master."); sdsfree(reply); // 将缓存中的 master 设为当前 master replicationResurrectCachedMaster(fd); // 返回状态 return PSYNC_CONTINUE; } // 接收到错误? if (strncmp(reply,"-ERR",4)) { /* If it's not an error, log the unexpected event. */ redisLog(REDIS_WARNING, "Unexpected reply to PSYNC from master: %s", reply); } else { redisLog(REDIS_NOTICE, "Master does not support PSYNC or is in " "error state (reply: %s)", reply); } //如果从服务器发送PSYNC上去后或者其他原因返回错误,然后在serverCron中重新建立连接再次从新走一次PSYNC或者SYNC流程 sdsfree(reply); replicationDiscardCachedMaster(); // 主服务器不支持 PSYNC return PSYNC_NOT_SUPPORTED; }
为什么设置了server.repl_state状态,就可以触发Redis服务器进行各种相应操作呢? 很明显Redis内部有定时轮询server.repl_state的逻辑存在。实现定时轮询其实就是Redis时间事件的一个实际的应用,感兴趣可以看下源码中ServerCron()函数的处理。
2. 增量同步
增量同步的两个常用场景:
- 初次全量同步之后,主服务器在收到写命令时,会将写命令传播给从服务器,而不是全量发送给从服务器(从服务器只读,不处理非主节点发来的写命令)
- 从服务器断线重连之后,从服务器与主服务器之间的数据差异只有断线期间主服务器接收到的写命令所执行的对数据的修改部分,此时只需要增量同步这部分数据即可。
写命令的传播比较容易理解,主服务器收到写命令,可能导致主从服务器数据不一致,那么主服务器在执行命令之外还会转发这个写命令给从服务器,让从服务器也执行相同的写命令,做到数据的一致。
另一个场景断线重连,Redis是由PSYNC命令来实现的,该功能也是在2.8版本后加入到Redis中的,老版本不兼容该命令。PSYNC的实现依赖于两个重要的概念:复制偏移量和复制积压缓冲区。
复制偏移量,指主服务器传播给从服务器的写命令的偏移量;主服务器和从服务器分别维护各自的偏移量。主服务器每传播N字节的写命令,偏移量就自增N;从服务器在接收到N字节写命令后也会将偏移量增N,这样就能保证主从节点的偏移量始终保持一致。(从服务器初始的复制偏移量是从哪里获取的呢?很明显应该是在初次全量同步时将主服务器的复制偏移量也同步给从服务器)
用示例图片来表示复制偏移量的变化

图1 主从服务器复制偏移量一致
开始阶段主从服务器的偏移量均为10086
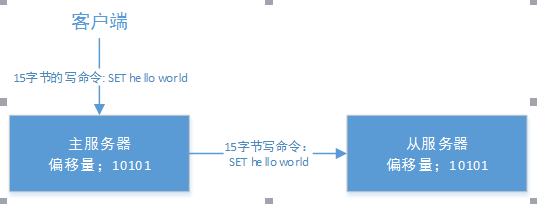
图2 客户端发来写命令后,偏移量的变化
主服务器执行写命令后更新了自身的偏移量到10101;同时传播写命令给从服务器,从服务器接收命令后也会更新自己的同步偏移量使得主从保持一致。
有了这个概念,一旦从服务器断线重连时就可以在同步命令中带上偏移量,主服务器根据偏移量是否一致来判断是否需要增量同步,以及增量哪些写命令。偏移量在服务器启动时初始化为0,后面可以一直递增不用考虑循环,因为偏移量是long long类型的,上限很大很大(9223372036854775807),基本不会撑爆。
那需要增量的写命令时保存在哪里的呢?这里就引入了另一个概念:复制积压缓冲区(server.backlog)
复制积压缓冲区,在Redis中是一个先进先出的定长队列,默认长度是1M。数据结构就是一个带标签的字符串数组。每次写命令都会直接从index开始进行拷贝, 达到缓冲区尾部就从缓冲区头开始拷贝,对原有数据直接覆盖。
3. 心跳检测
心跳检测是由从服务器发起的,默认情况下是每隔1s发送一次;发送的命令是:
REPLCONF ACK <replication_offset>
Replication_offset是从服务器的复制偏移量;这样主服务器收到该命令后可以比较从服务器的Replication_offset是否和自身的一致,如果不一致这说明需要同步数据。主节点此时的处理方式类似于从服务器断线重连时的处理,将偏移量多出来的写命令发送给从节点执行,保持两者的数据一致。
由此可见心跳检测的一个重要功能就是防止命令传播过程中有消息未送达从服务器而导致的主从数据不一致。这也是2.8版本以后新增的异常处理逻辑,很大的提高了复制机制的可用性。
4. 总结
以上就是复制机制的一些关键点,总结一下主要包括以下几点:
- 复制机制下,只有主服务器才可以接收普通客户的写命令,从服务器只能接收普通客户端的读命令;且主服务器每接收到一个写命令,都会讲该命令传播给从服务器,保证主从数据一致
- Redis使用复制偏移量和复制积压缓冲区来实现PSYNC的增量复制,在从服务器断线重连后避免了进行全同步,效率提升明显。
- 心跳检测可以检查主从服务器数据是否一致,利用的也是从服务器发送给主服务器的复制偏移量,主服务器可以尽早的发现传播过程中丢掉的命令,并发起补充的命令传播。
Redis自带的高可用解决方案Sentinel也是以复制机制为基础的,增加了Sentinel监控节点,可以及时检查到失效的主服务器,在从服务器中选出新的主服务器。当原有的主服务器恢复后会成为从服务器加进来。

