
爬虫实例(一)——爬取微博动态
首语:开始准备认真学习爬虫了,先从基础的开始学起,比如先爬取微博的个人动态。
两个难点:获取动态加载的内容和翻页这两项操作。
对象:何炅的个人
分析过程:
首页url:https://weibo.com/hejiong?is_search=0&visible=0&is_all=1&is_tag=0&profile_ftype=1&page=1#feedtop
我们可以直接用get方法请求该URL,但是注意要带上cookies,这样才能得到网页信息。cookies可以直接使用开发者工具来查找。
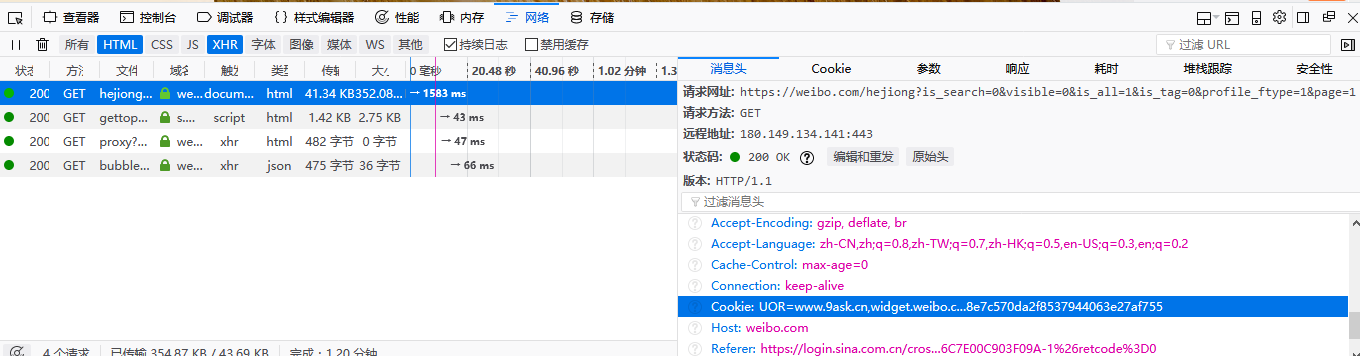
import requests urll="https://weibo.com/hejiong?is_search=0&visible=0&is_all=1&is_tag=0&profile_ftype=1&page=1#feedtop" r=requests.get(urll,cookies=cookiess)#必须带上cookies才能获得网页信息。 print(r.text)
这里就出现了之前讲到的一个难点——页面内容并不是完整显示地,有部分内容动态加载,只有你拉到底部才会加载出来。

而我们之前的代码是爬取不到动态加载的内容的,这里就需要对动态加载的内容进行分析一下了
打开浏览器的开发者工具,查看xhr内容,可以确定下面画红框的就是动态加载的内容。
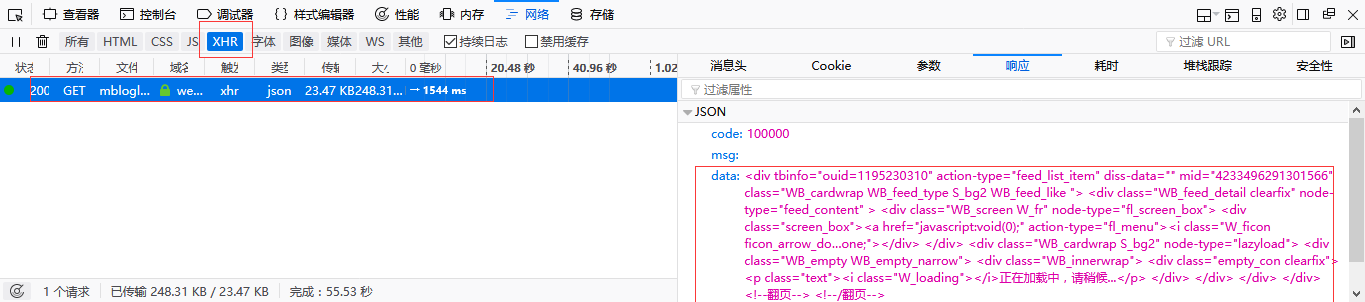
我们可以查看该请求的url,一个页面一般会动态加载两次,我们可以比较一下这两个动态加载的url,可以发现只有两处不同————_rnd和pagebar
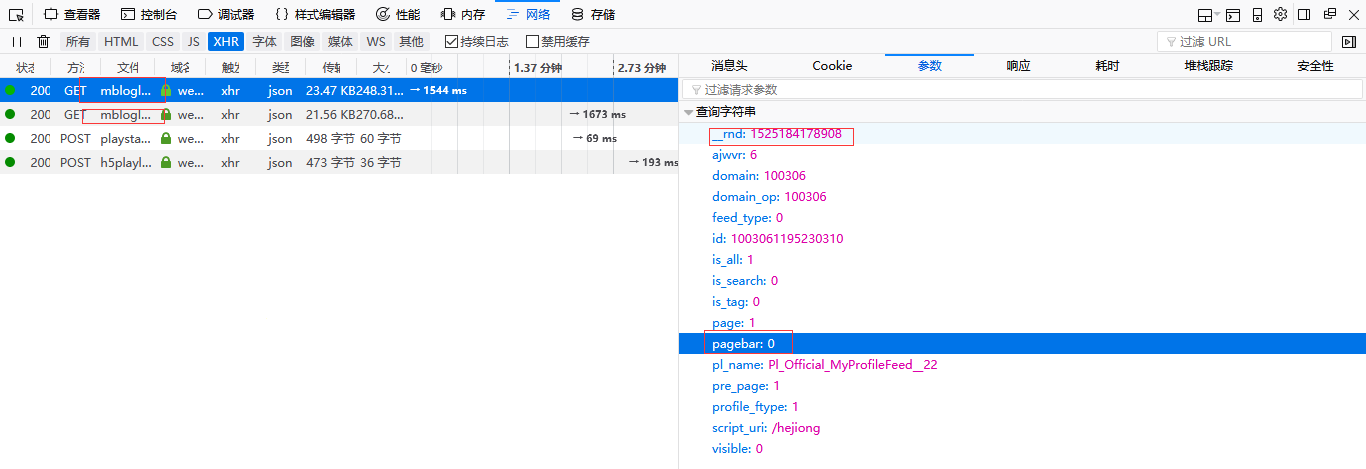
经过自己的试验,可以发现_rnd这个参数根本不起作用,只有pagebar起作用,所以我们可以直接把_rnd这部分给删掉
于是第一个页面的动态加载的url就可以写成:https://weibo.com/p/aj/v6/mblog/mbloglist?ajwvr=6&domain=100306&is_search=0&visible=0&is_all=1&is_tag=0&profile_ftype=1&page=1&pagebar=0&pl_name=Pl_Official_MyProfileFeed__22&id=1003061195230310&script_uri=/hejiong&feed_type=0&pre_page=1&domain_op=100306和https://weibo.com/p/aj/v6/mblog/mbloglist?ajwvr=6&domain=100306&is_search=0&visible=0&is_all=1&is_tag=0&profile_ftype=1&page=1&pagebar=1&pl_name=Pl_Official_MyProfileFeed__22&id=1003061195230310&script_uri=/hejiong&feed_type=0&pre_page=1&domain_op=100306。
第一个难点我们就解决了——获取动态加载内容的url。
接下来看看第二个难点——如何实现翻页
我们打开网络,通过点击其他页面,来查看跳出的请求,就能找到其他页面的url了。
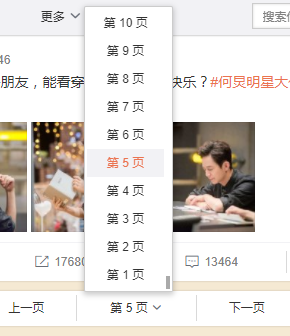
其实通过第一个页面的url推算也能猜出只是更改page参数的值就能实现翻页了,将上面的页面的url不断去除也能得到更好的url:https://weibo.com/hejiong?is_search=0&visible=0&is_all=1&is_tag=0&profile_ftype=1&page=5#feedtop
同样可以得到第五个页面的两个动态加载的url:https://weibo.com/p/aj/v6/mblog/mbloglist?ajwvr=6&domain=100306&is_search=0&visible=0&is_all=1&is_tag=0&profile_ftype=1&page=5&pagebar=0&pl_name=Pl_Official_MyProfileFeed__22&id=1003061195230310&script_uri=/hejiong&feed_type=0&pre_page=5&domain_op=100306&__rnd=1525359568282和https://weibo.com/p/aj/v6/mblog/mbloglist?ajwvr=6&domain=100306&is_search=0&visible=0&is_all=1&is_tag=0&profile_ftype=1&page=5&pagebar=1&pl_name=Pl_Official_MyProfileFeed__22&id=1003061195230310&script_uri=/hejiong&feed_type=0&pre_page=5&domain_op=100306&__rnd=1525359603560
前面讲第一页的时候讲了这两个的区别就是pagebar,一个是0,一个是1;第五页的这两个url和第一页的两个url的区别是page值的不同,所以我们就可以自己手动构造所需要抓取的每个页面的url了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号