
论文赏析[TACL19]生成模型还在用自左向右的顺序?这篇论文教你如何自动推测最佳生成顺序
论文地址:Insertion-based Decoding with automatically Inferred Generation Order
介绍
大多数的生成模型(例如seq2seq模型),生成句子的顺序都是从左向右的,但是这不一定是最优的生成顺序。
可能有人要说,反正最终都是生成一个句子,跟生成顺序有啥关系?
但是大量实验确实表明了从左向右生成不一定是最好的,比如先生成句子中的核心词(出现词频最高的词,或者动词等)可能效果会更好。
于是这篇论文就提出了自动推测最佳的生成顺序,考虑所有顺序的概率,优化概率之和。
但是对于任意一个生成顺序,如何还原原本的句子呢?
本文又提出了一个相对位置编码的方案,并且融合到了Transformer里。
传统序列生成模型
给定一个输入句子,生成的句子的概率可以被建模为:
其中规定输出句子的首尾单词和是特殊记号。
那么模型最大化正确输出的概率就行了。
解码的时候在每个时刻取概率最大的输出单词就行了,当然也可以加上beam search等方法提高性能。
InDIGO
本文将生成顺序看作隐变量,那么对于一个输出句子,他的隐变量可能取值是阶乘级别的。
我们取所有顺序的概率之和,作为输出的概率:
而每个生成顺序的概率被定义为:
这里多了一个变量,用来表示生成的单词在原句子中的绝对位置。
还多了一项,表示句子生成结束。
为什么要用这一项呢?因为原来的结束符号< /s>被当作第二项输入进序列了。
这里就会出现一个问题,在每一步预测的时候,都不知道最终句子长度是多少。
那么怎么知道绝对位置是多少呢?所以要用相对位置来进行编码。
假设在时刻,对于第个单词,采用一个向量来表示它的相对位置,每个维度取值只有-1,0和1三种。
定义为:如果绝对位置在的左边,就取-1;如果是一个词,就取0;如果在右边,就取1。
可以观察到这个时刻向量长度其实只有,而且下个时刻长度就会加1。
将这些向量拼接成一个矩阵,每一列表示一个单词的位置向量,这个矩阵关于主对角线对称的元素其实是相反数。
那么下一个时刻是不是这个矩阵得重算呢?不需要。
因为下一个单词无论插在哪里,都不会影响之前的单词的相对顺序,所以只要给这个矩阵新增一行一列即可:
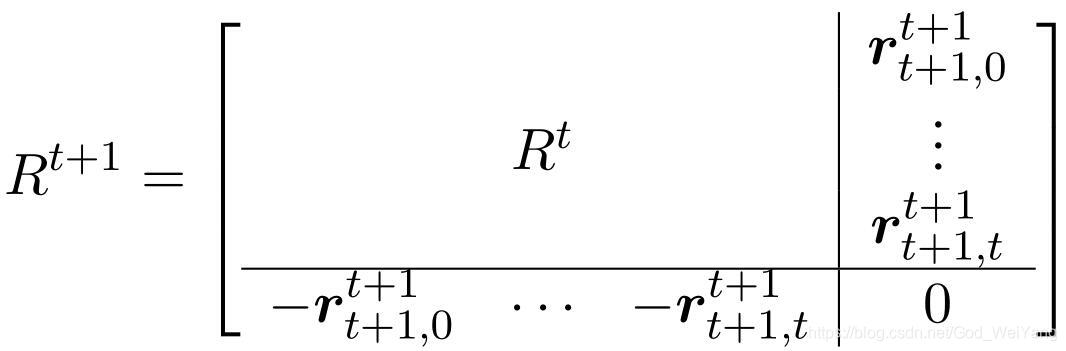
但是不能随便取值,不然可能是非法的,没办法还原到绝对位置。
所以这里定义这么算:
首先预测一个单词,然后预测插入到它的左边还是右边。
如果,那么如果插入到左边,值取-1,插入到右边取1。
如果,那么和前面单词的相对顺序其实是和和他们的相对顺序完全相同的,那么直接取就行了。
伪代码如下:

最后得到了相对位置之后,怎么还原为绝对位置呢?
只需要用下面式子就行了:
也就是看每个单词前面有多少单词。
模型
本文只修改了Transformer的解码器部分,因为对于随机的生成顺序,解码的时候绝对位置未知,所以传统的绝对位置编码行不通。
稍稍修改attention的计算方式:
其中是输出的隐层表示,是参数,根据相对位置不同分为三个向量表示。
经过attention计算之后,得到了当前已预测词的表示矩阵,那么下一个词和对应相对位置概率为:
也就是先预测下一个单词是什么,再预测它的相对位置。当然也可以倒过来,只是实验效果不如这个。
预测单词的概率:
预测下一个词应该插在哪个位置:
注意到这里不仅拼接上了下一个词的词向量,还区分了每个词左边和右边的隐层表示。
其实这里有个问题,一个词在的右边不就等价于在的左边吗?那其实这两个预测结果都是对的。虽然最后的向量都是一样的。
目标函数
因为一个句子的可能排列顺序太多了,不可能一一枚举,所以这里最大化ELBO来代替最开始的概率之和。
对于输入和生成,首先定义一个生成顺序的近似后验。
然后ELBO可以表示为:

注意这里如果近似后验训练中固定不变的话,第二项可以忽略。
然后就可以根据近似后验来进行采样,优化这个函数了,那么这个近似后验怎么定义呢?
第一种方法是定义为一个常见的确定的顺序,比如从左向右、从右向左等等,详见下表:

这种情况下,模型其实就变成了和普通的序列生成模型差不多了,只用最大化一个生成顺序的概率就行了,区别就是多了相对位置编码。
第二种方法是用beam search,这里称作Searched Adaptive Order (SAO)。
传统的序列生成模型其实也有beam search,不过那是在每个时刻解码概率最大那些子序列。
而这里的beam search空间更大,搜索的是整个排列的空间。
也就是在每个时刻,遍历所有的下一个单词和它的相对位置,找出最大的个子序列。
最后的目标函数变为了:
这里近似后验被定义为了:如果在中,概率为,否则为0。
还有一些小trick,比如beam search加入噪声,这样可能采样到概率比较小的那些排列。
还有位置预测模块收敛的比单词预测模块更快,这就会导致模型最后总是先预测出高频词或功能词(大雾。。。)。
解决方法是先用给定的顺序(例如从左向右)预训练一遍模型,然后再训练beam search模型。
最终解码还是用上面的伪代码,只是加入了beam search。
但是这里是先预测的单词,再预测的位置,和训练时的beam search略有不同。
实验
实验主要做了几组机器翻译、词序还原、代码生成和图像标签生成,这里就简单看一下机器翻译结果,其他的详见论文。
机器翻译结果如下:
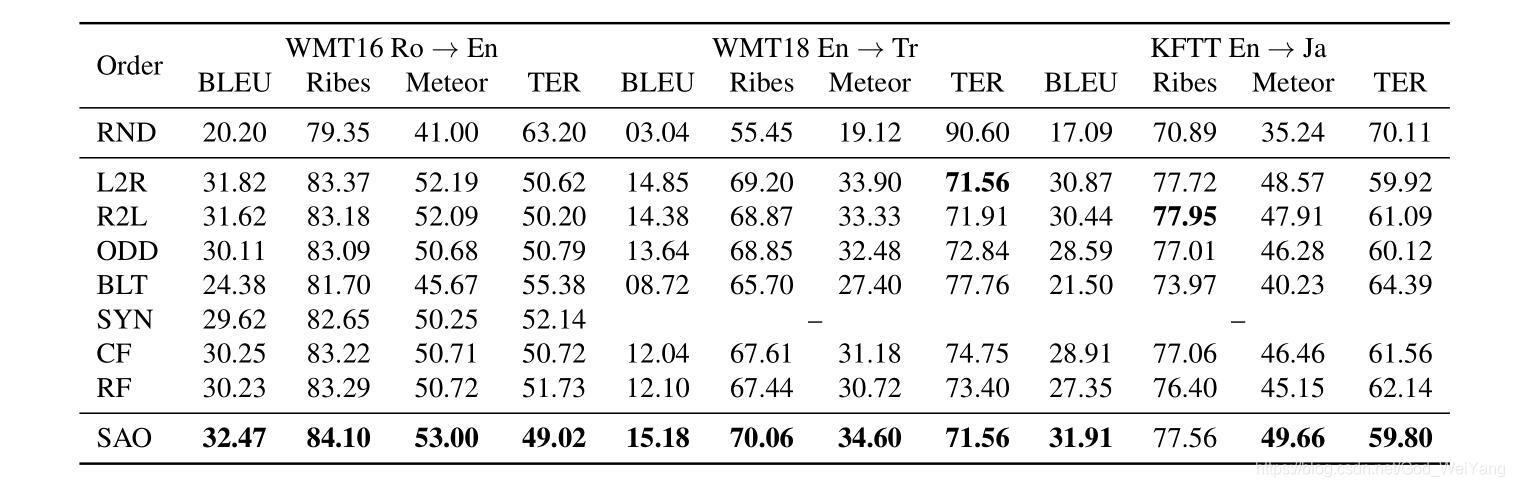
可以看出beam search的提升还是挺大的,而用随机顺序生成序列效果很差,用句法树的遍历顺序生成也挺差的。
其他的实验细节和结果详见论文,这里就不展开分析了。
总结
这篇论文提出了考虑多种序列生成的顺序,以此提升最终生成的效果,实验证明还是有效的。
为了记住这种顺序,还提出了相对位置表示,用来解决原始Transformer无法表示随机排列的问题。
但是总感觉beam search和相对位置表示的矩阵不是很优雅,很繁琐。
后续工作也提到了直接预测排列,而不是用beam search。
还有这种相对位置表示能否用在其他任务上,比如做成通用的位置表示?
不过这种“打乱顺序”的思想倒是挺不错的,很多地方可以用,毕竟人类看句子第一眼可能也会看到核心关键词嘛。
posted on 2020-01-17 01:02 godweiyang 阅读(262) 评论(0) 编辑 收藏 举报

