
数据库优化--使用索引优化存储过程
【IT168技术】数据库优化--使用索引优化存储过程
现有数据库中有一个存储过程的查询时间为25s,最大的一个表的数据记录在70-80万条记录,感觉还有潜力可以挖掘。
经过一系列的优化最后,这个存储过程的执行时间为3s-4s。下面就讲讲此次优化的过程。
首先是要讲一下,这次主要使用到了索引这一个工具。先说一下索引。
一、聚集索引基于数据行的键值在表内排序和存储这些数据行。每个表只能有一个聚集索引,因为数据行本身只能按一个顺序存储。
对表中的什么样的列来定义聚集索引呢,有以下三个原则:
1)可用于经常使用的查询。
2)提供高度唯一性。
3)可用于范围查询。
定义聚集索引的列需要注意的事项:
1)定义聚集索引键时使用的列越少越好。考虑具有下列一个或多个属性的列:
2)唯一或包含许多不重复的值
3)按顺序被访问
4)经常用于对表中检索到的数据进行排序。
5)按该列对表进行聚集(即物理排序)是一个好方法,它可以在每次查询该列时节省排序操作的成本。
聚集索引不适用于具有下列属性的列:
1)频繁更改的列
二、非聚集索引包含索引键值和指向表数据存储位置的行定位器。
可以对表或索引视图创建多个非聚集索引。通常,设计非聚集索引是为改善经常使用的、没有建立聚集索引的查询的性能。
与使用新华字典的方式相似,查询优化器在搜索数据值时,先搜索非聚集索引以找到数据值在表中的位置,然后直接从该位置检索数据。
这使非聚集索引成为完全匹配查询的最佳选择,因为索引包含说明查询所搜索的数据值在表中的精确位置的项。
定义非聚集索引时需要注注意事项:
1) 更新要求较低但包含大量数据的数据库或表可以从许多非聚集索引中获益从而改善查询性能。
2) 联机事务处理应用程序和包含大量更新表的数据库应避免使用过多的索引。
3) 索引应该是窄的,即列越少越好。
在创建非聚集索引之前,应先了解访问数据的方式。考虑对具有以下属性的查询使用非聚集索引:
1) 使用 JOIN 或 GROUP BY 子句。
2) 应为联接和分组操作中所涉及的列创建多个非聚集索引,为任何外键列创建一个聚集索引。
3) 不返回大型结果集的查询。
4) 包含经常包含在查询的搜索条件(例如返回完全匹配的 WHERE 子句)中的列。
注意:索引不是越多越好,任何东西都有个度。
一个表如果建有大量索引会影响 INSERT、UPDATE 和 DELETE 语句的性能,因为所有索引都必须随表中数据的更改进行相应的调整。
三、下面我们来看一个实例
(一)
----1创建临时表
create table #tt2(area_no nvarchar(50) COLLATE Chinese_PRC_CI_AS,gc_name2 nvarchar(50) COLLATE Chinese_PRC_CI_AS,cost1 decimal(18,2))
create table #t3(acc_no nvarchar(50) COLLATE Chinese_PRC_CI_AS,cost1 decimal(18,2),area_no nvarchar(50) COLLATE Chinese_PRC_CI_AS,description nvarchar(50) COLLATE Chinese_PRC_CI_AS)
........

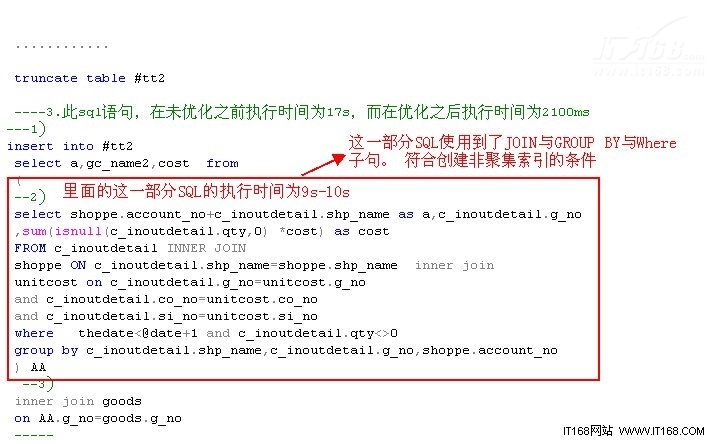
---分析一下这条sql语句,符合上面建立非聚集索引来提高查询性能的情况。见上面1)与4)
---此SQL中使用到了monthunitstock表,goods表,unitcost表,其中表monthunitstock的数据最多,而且要与unitcos进行联接
---monthunitstock与unitcost表的联接条件有三个g_no,co_no,si_no同时使用到了monthunitstock表中的qty字段与unitcost表中的cost字段
(二)创建索引以提高查询速度,以下索引是使用“数据库引擎优化顾问”生成了相应的索引,然后根据实际情况进行选择或增减
/*
CREATE NONCLUSTERED INDEX [index_monthunitstock_7_1585037028__K1_K2_K3_K5_7] ON [dbo].[monthunitstock]
(
[g_no] ASC,
[co_no] ASC,
[si_no] ASC,
[area_no] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF
, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE NONCLUSTERED INDEX [index_UnitCost_g_co_si_cost] ON [dbo].[UnitCost]
(
[g_no] ASC,
[si_no] ASC,
[co_no] ASC
)
INCLUDE ( [Cost]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF,
IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE NONCLUSTERED INDEX [index_goods_7_626621821__K2_K13] ON [dbo].[goods]
(
[g_no] ASC,
[gc_name2] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF,
DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
*/
-----
-----1。现在来分析这一段SQL语句,问题出在什么地方呢?
-----2. 首先看一下面的SQL语句,即2)这一部分,这部分在SQL中执行时间为9s-10s,那么能不能优化呢?
----- 这2)这部分的SQL,符合上面建立非聚集索引来提高查询性能的情况。见上面1)与4)
----- 我们仔细看一下这段SQL,发现他的查询条件为小于输入的参数日期,与数量不为0,而且这两个查询条件都是表
----- c_inoutdetail中的,而且这张表中在进行联接是还会用到g_no,co_no,si_no,那么在这些字段上建立索引,结果
----- 会如何,见下面的SQL语句。结果相当不错,时间缩短到了2s左右.
(四)创建索引以提高查询速度,以下索引是使用“数据库引擎优化顾问”生成了相应的索引,然后根据实际情况进行选择或增减
/*
CREATE CLUSTERED INDEX [index_c_inoutdetail_c_7_453381180__K6_K7_K8_K5_K9_K3] ON [dbo].[c_inoutdetail]
(
[g_no] ASC,
[co_no] ASC,
[si_no] ASC,
[thedate] ASC,
[qty] ASC,
[shp_name] ASC
)WITH (SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF) ON [PRIMARY]
*/
............
set nocount off
五、 最终通过一系统的索引创建,把这个存储过程的执行时间由25s缩减到3s-4s
/*
最后记录一点,以备查:查询中多用Exists,少用 in 以提高查询速度
Exists只检查存在性,性能比in强很多,有些朋友不会用Exists,就举个例子
例,想要得到有电话号码的人的基本信息,table2有冗余信息
select * from table1;--(id,name,age)
select * from table2;--(id,phone)
in:
select * from table1 t1 where t1.id in (select t2.id from table2 t2 where t1.id=t2.id);
Exists:
select * from table1 t1 where Exists (select 1 from table2 t2 where t1.id=t2.id);
*/
