数据筛选,清洗,汇总
数据的筛选
# 列的筛选
df.column_name df['column_name']
# 行的筛选
df.loc[condition,:]
# 行列的筛选
df.loc[condition,:colunm_list]
# example
sec_buildings.size
sec_buildings['size']
sec_buildings[['name','tot_amt','price_unit']]
sec_buildings.loc[sec_buildings.region == '浦东',:]
sec_buildings.loc[(sec_buildings.region == '浦东') & (sec_buildings['size'] > 150),:]
sec_buildings.loc[(sec_buildings.region == '浦东') & (sec_buildings['size'] > 150),['name','tot_amt','price_unit']]
数据的清洗
# 数据类型的修改
pd.to_datetime
df.column.astype
# 冗余数据的识别与处理
df.duplicated(subset=)
df.drop_duplicates(inplace=)
# 异常值的识别与处理
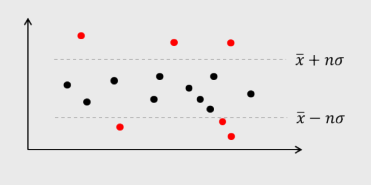
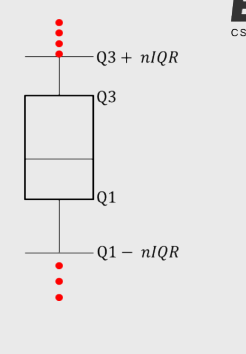
1.Z得分法
2.分位数法
3.距离法
参考文档
https://mp.weixin.qq.com/s/aWTDJtafY9XHZdHdOUaqXw
mp.weixin.qq.com/s/728HfX6VFi0tN6MBkFrTsA
# 缺失值的识别与处理
df.isnull()
df.fillna(value={})
df.dropna()
Example
cars = pd.read_csv('sec_cars.csv',sep=',',engine='python', encoding='utf8')
cars.head()
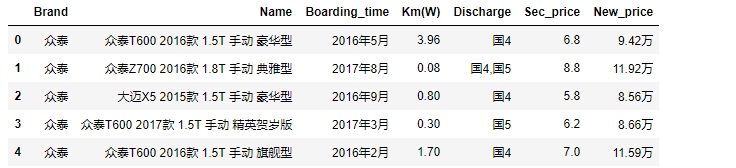
cars.dtypes

cars.Boarding_time = pd.to_datetime(cars.Boarding_time, format='%Y年%m月')
cars.head()
cars.dtypes
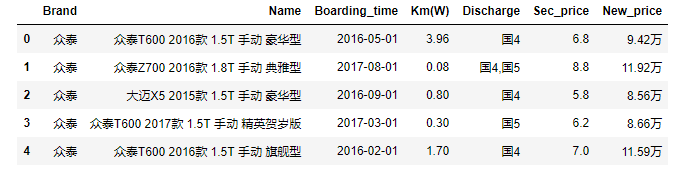
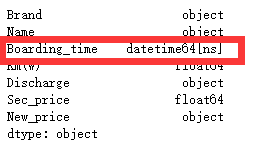
cars.New_price = cars.New_price.str[:-1].astype(float)
cars.head()

# 冗余数据的识别和处理
online = pd.read_excel('data_test04.xlsx', )
online
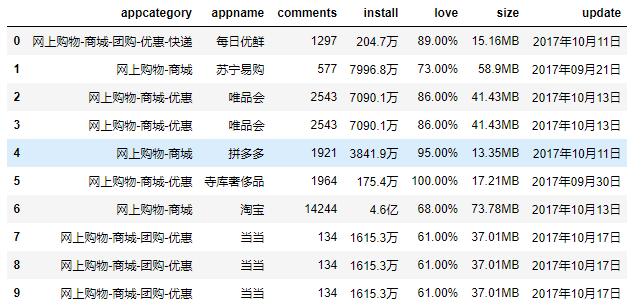
online.duplicated(subset='appname')
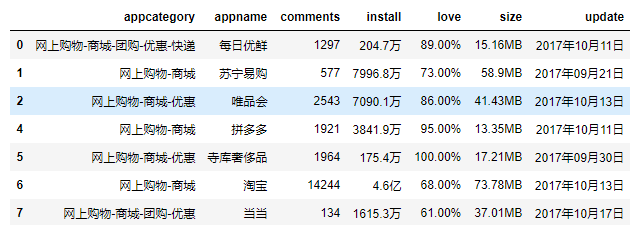
online.drop_duplicates(inplace=True)
online
# 缺失数据的筛选与清洗
test = pd.read_excel('data_test05.xlsx', )
test
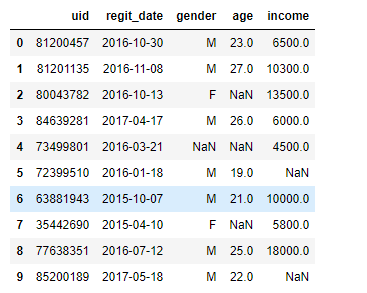
test.isnull().any(axis=0)
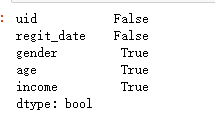
# 处理方式:删除
test.dropna()
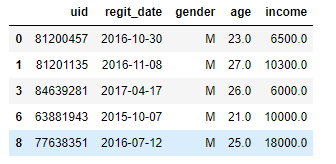
# 处理方式:填充
test.fillna(value = {'gender':test.gender.mode()[0], 'age':test.age.mean(),'income':test.income.median()}, inplace = True)
test
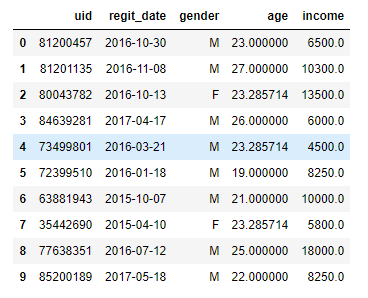
数据的汇总

# 分组汇总
groupby "方法":用于汇总前,设定被分组的变量
arrgrgate "方法":可基于groupby的结果做进一步的统计汇总
ps:在aggregate阶段,需以字典的形式传递参数,用于选择被统计的变量和对应的统计方法
# example
# 通过groupby方法,指定分组变量
grouped = diamonds.groupby(by = ['color','cut'])
# 对分组变量进行统计汇总
result = grouped.aggregate({'color':np.size, 'carat':np.min,
'price':np.mean, 'table ':np.max})
result
# 调整变量名的顺序
result = pd.DataFrame(result, columns=['color','carat','price','table '])
result
# 数据集重命名
result.rename(columns={'color':'counts','carat':'min_weight','price':'avg_price',
'table ':'max_face_width'}, inplace=True)
数据的合并与连接



Example
# 构造数据集
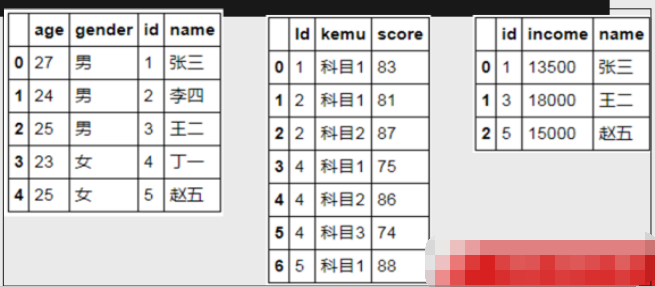
df3 = pd.DataFrame({'id':[1,2,3,4,5],'name':['张三','李四','王二','丁一','赵五'],
'age':[27,24,25,23,25],'gender':['男','男','男','女','女']})
df4 = pd.DataFrame({'Id':[1,2,2,4,4,4,5], 'score':[83,81,87,75,86,74,88]
'kemu':['科目1','科目1','科目2','科目1','科目2','科目3','科目1']})
df5 = pd.DataFrame({'id':[1,3,5],'name':['张三','王二','赵五'],
'income':[13500,18000,15000]})
# 三表的数据连接
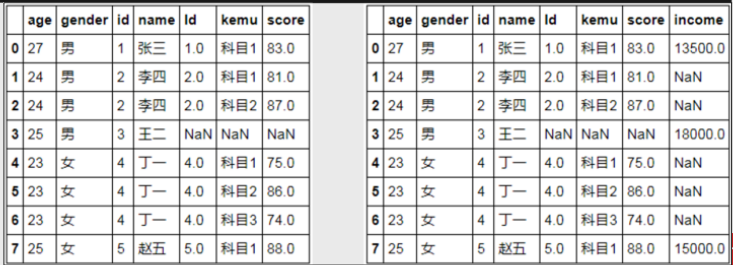
# 首先df3和df4连接
merge1 = pd.merge(left = df3, right = df4, how = 'left', left_on='id', right_on='Id')
merge1
# 再将连接结果与df5连接
merge2 = pd.merge(left = merge1, right = df5, how = 'left')
merge2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号