浅入了解NOSQL
NOSQL
NoSQL概述
发展历程
1、单机MySQL的年代
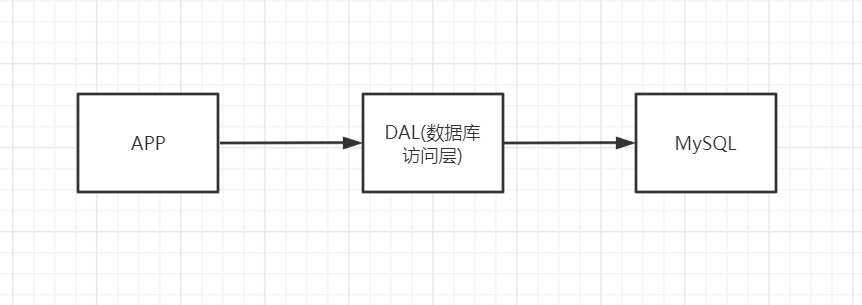
90年代,一个网站访问量不会太大,单个数据库就足够了,并且使用静态网页html更多,服务器没有压力
这种情况下,整个网站的瓶颈:
1.数据量太大,一个机器放不下
2.数据的索引(B+Tree),一个机器内存也放不下
3.访问量(读写混合),一个服务器承受不了
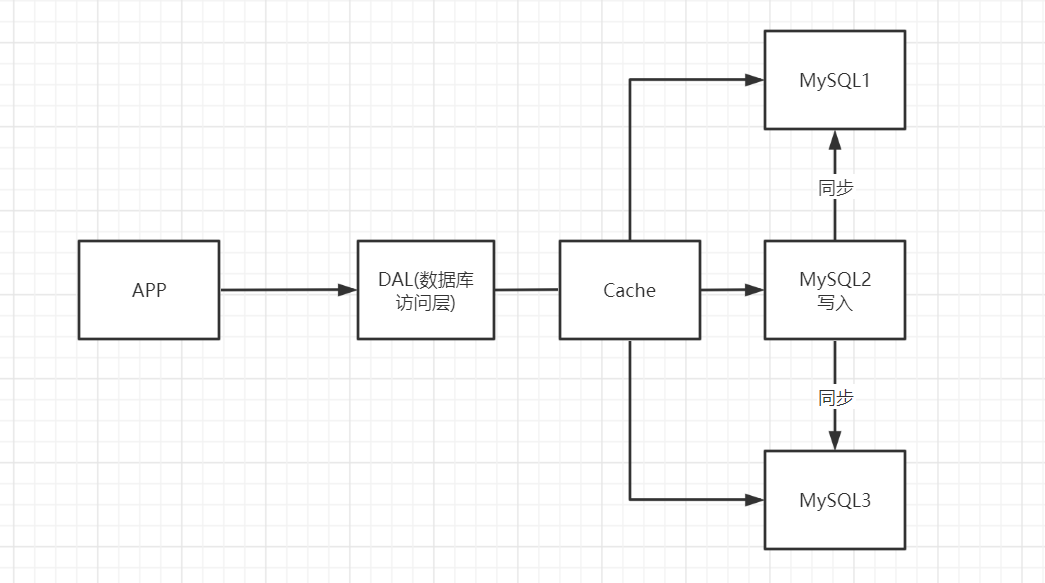
2、Memcached(缓存)+MySQL+垂直拆分(读写分离)
网站80%的情况都是在读,每次查询数据库十分麻烦,可以使用缓存来保证效率,减轻数据的压力
发展过程:优化数据结构—>文件缓存(IO)—>Memcached
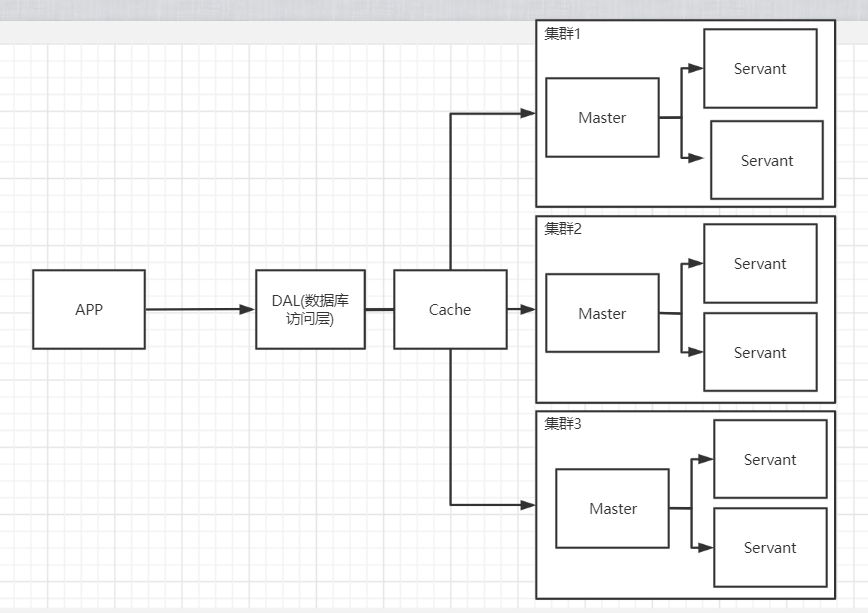
3.分库分表+水平拆分+MySQL集群
早些年MySAM:表锁,影响效率,高并发出现严重的锁问题
Innodb:行锁
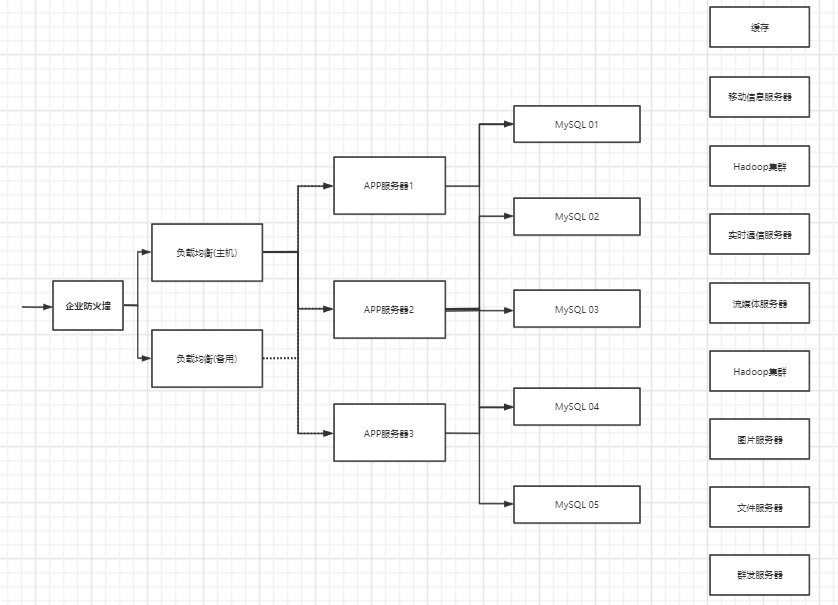
4.如今的年代
数据量很多,变化快。MySQL等关系型数据库不够用
目前一个基本互联网项目的架构
为什么要用NoSQL
用户的个人信息,社交网络,地理位置,用户产生的数据,日志等等数据爆发式增长!
什么是NoSQL
NoSQL=Not Only SQL(不仅仅是SQL),泛指非关系型数据库
关系型数据库:表格,行,列
用户的个人信息,社交网络,地理位置这些数据类型不需要一个固定的格式,不需要多个操作就可以实现横向扩展,Map<String,Object> 使用键值对来控制
NoSQL特点
1、方便扩展,数据之间没有关系,好扩展
2、大数据高性能,一秒写8w+,读取11w。NoSQL的缓存记录级,是一种细腻度的缓存,性能比较高
3、数据类型多样(不需要事先设计数据库,随取随用)
4.传统的 RDBMS和NoSQL
传统的 RDBMS
- 结构化组织
- SQL
- 数据和关系都在单独的表中
- 数据操作,数据定义语言
- 严格的一致性
- 基础的事务
- …………
NoSQL
- 不仅仅是数据
- 没有固定的查询语言
- 键值对存储,列存储,文档存储,图形数据库(社交关系)
- 最终一致性
- CAP定理和 BASE 理论 (异地多活)
- 高性能,高可用,可扩展性强
- …………
3V+3高
大数据时代的3V:描述问题
- 海量Volume
- 多样Variety
- 实时Velocity
大数据时代的3高:对程序的要求
- 高并发
- 高可扩
- 高性能
阿里巴巴数据架构演进
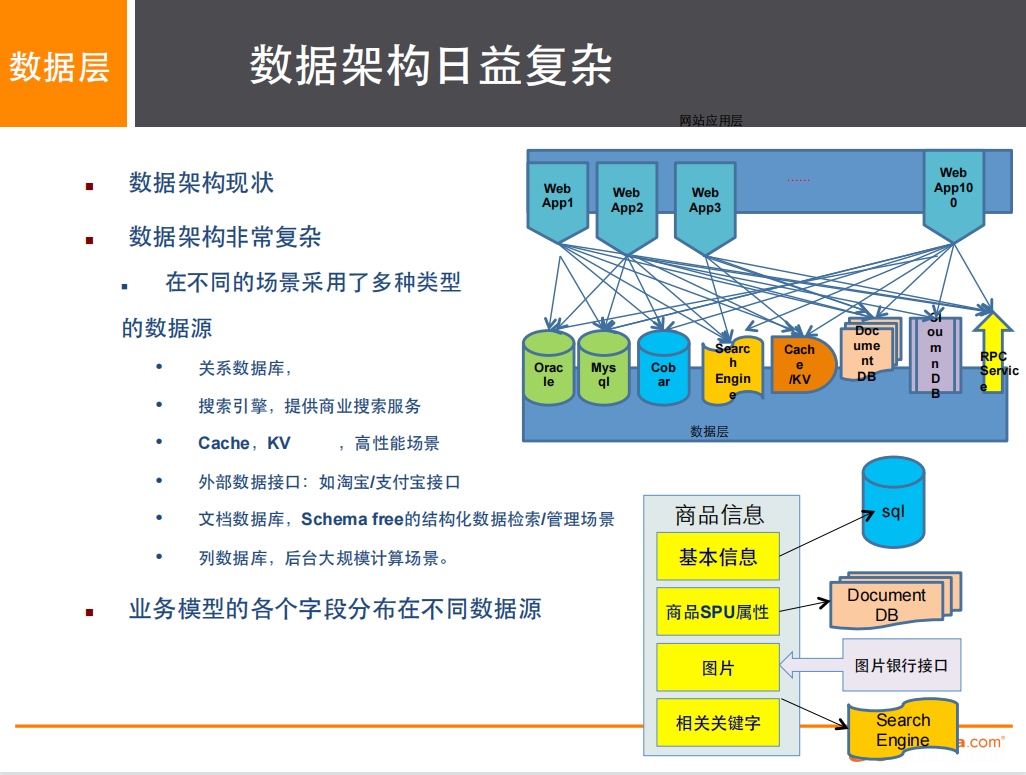
#1、商品的基本信息
名称、价格、商家信息
关系型数据库:MySQL/Oracle
#2、商品的描述评论(文字比较多)
文档型数据库:MongoDB
#3、图片
分布式文件系统:FastDFS
—— 淘宝 TFS
—— Google GFS
—— Hadoop HDFS
—— 阿里云 oss
#4、商品的关键字(搜索)
——搜索引擎:solr ElasticSearch
——淘宝 Isearch
#5、商品热门的波段信息
——内存数据库:redis Tair Memcache……
#6、商品的交易,外部的交付接口
——第三方应用
大型互联网应用的问题
- 数据类型太多
- 数据源繁多,经常重构
- 数据需要大面积改造
解决方案: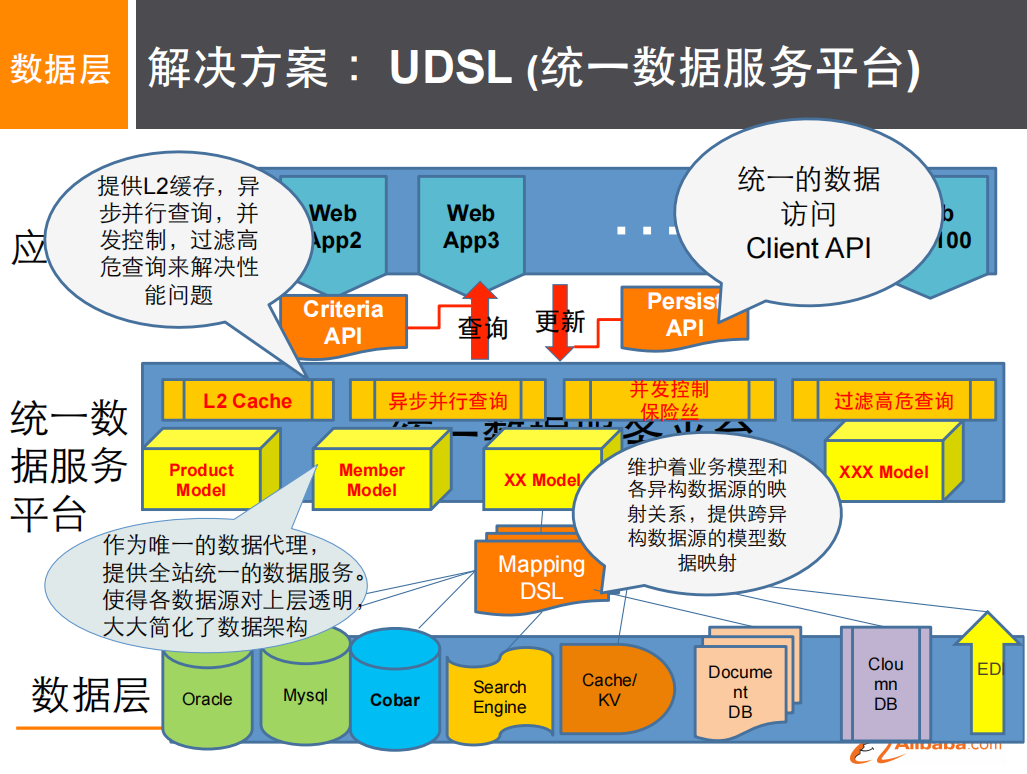
问题1:性能问题
- 数据架构大幅简化,开发便捷,但性能问题也很严重
- 业务模型的不同字段可能会来自不同的数据源,组装对象成本也很高
- 延迟加载和按需返回设置不当会加载冗余数据,导致性能问题
- 呼唤缓存
问题2:网站数据非常庞大,缓存过多数据消费比不高,只能缓存热点数据
解决方案: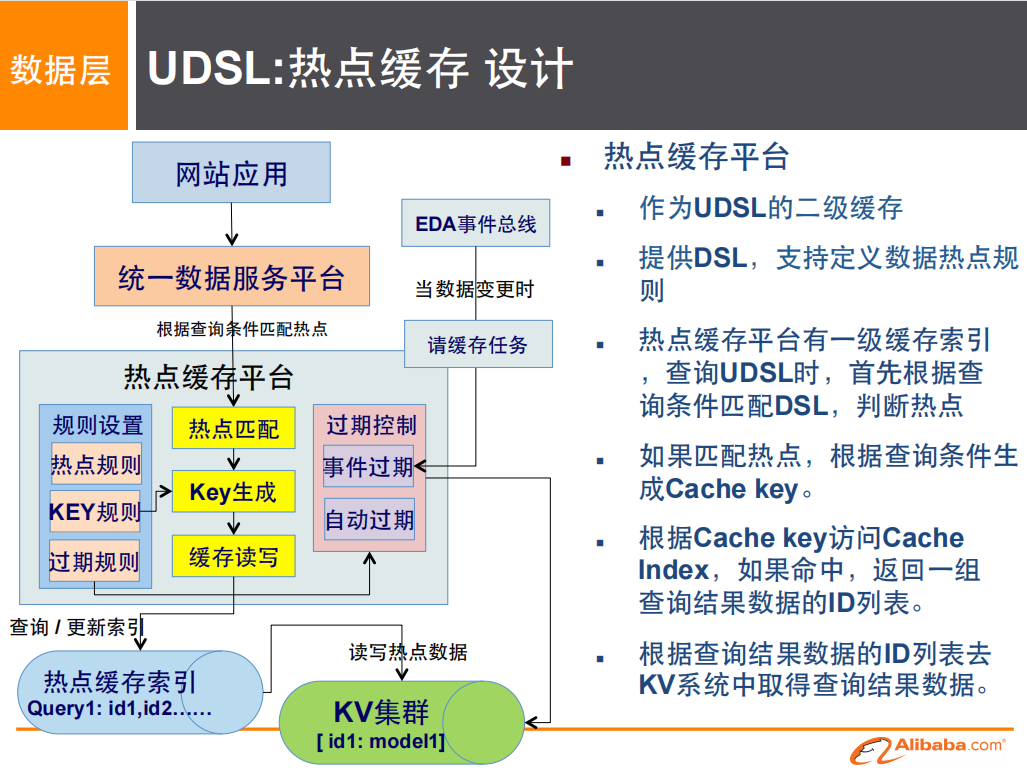
NoSQL四大分类
KV键值对:
- 新浪:Redis
- 美团:Redis+Tair
- 阿里、百度:Redis+Memcache
文档型数据库
- bson格式,和json一样
- MongoDB
- MongoDB是一个基于分布式文件存储的数据库,c++编写
- 主要用于处理大量文档
- MongoDB是一个介于关系型数据库和非关系型数据库中间的产品,非关系数据库中最像关系型数据库的
- ConthDB
列存储数据库
- HBase
- 分布式文件系统
图关系数据库
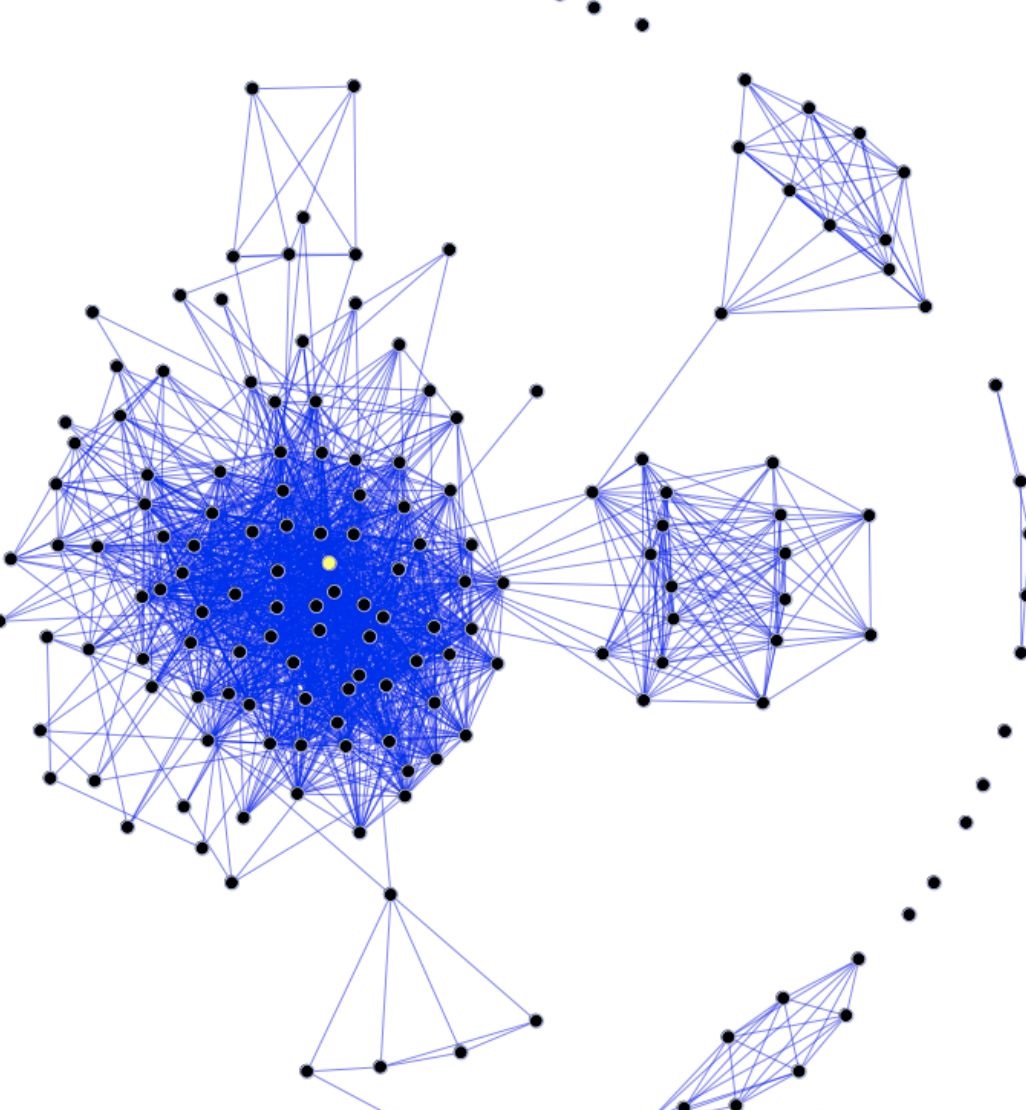
- 存储的是关系,比如:朋友圈社交网络,广告推荐
- Neo4j,InfoGrid
四者对比
| 分类 | Examples举例 | 典型应用场景 | 数据模型 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 键值(key-value) | Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB | 内容缓存,主要用于处理大量数据的高访问负载,也用于一些日志系统等等。 | Key 指向 Value 的键值对,通常用hash table来实现 | 查找速度快 | 数据无结构化,通常只被当作字符串或者二进制数据 |
| 列存储数据库 | Cassandra, HBase, Riak | 分布式的文件系统 | 以列簇式存储,将同一列数据存在一起 | 查找速度快,可扩展性强,更容易进行分布式扩展 | 功能相对局限 |
| 文档型数据库 | CouchDB, MongoDb | Web应用(与Key-Value类似,Value是结构化的,不同的是数据库能够了解Value的内容) | Key-Value对应的键值对,Value为结构化数据 | 数据结构要求不严格,表结构可变,不需要像关系型数据库一样需要预先定义表结构 | 查询性能不高,而且缺乏统一的查询语法。 |
| 图形(Graph)数据库 | Neo4J, InfoGrid, Infinite Graph | 社交网络,推荐系统等。专注于构建关系图谱 | 图结构 | 利用图结构相关算法。比如最短路径寻址,N度关系查找等 | 很多时候需要对整个图做计算才能得出需要的信息,而且这种结构不太好做分布式的集群 |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通