
SQL删除指定条件的重复数据,只保留一条
DECLARE @Count INT = 1 WHILE @Count > 0 BEGIN DELETE TB FROM TableName TB WHERE TB.ID IN (SELECT MIN(ID) FROM TableName TB2 GROUP BY TB2.Column1,TB2.Column2,...TB2.ColumnN HAVING COUNT(1) > 1); SET @Count = @@ROWCOUNT; END
这里使用了循环删除,并不是最优的方法,欢迎园友不吝批评指正。
其实还有一种方法是先查询重复的数据,然后在重复数据中保留一条。 下面用例子说明。
例如表City有如下的数据:
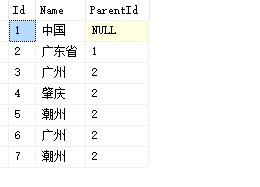
查询出重复的数据,Id只保留其中一个
SELECT MIN(Id) Id,Name FROM dbo.City GROUP BY Name HAVING COUNT(1) > 1
然后使用删除时Join上面的表
DELETE C FROM City C JOIN ( SELECT MIN(Id) Id,Name FROM dbo.City GROUP BY Name HAVING COUNT(1) > 1 ) TMP ON C.Name = TMP.Name AND C.Id <> TMP.Id
另外一种方法是园友Adeal2008指出的使用row_number()来处理,感谢Adeal2008提供思路,这也是一种方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号