
dma 和 cache的一致性
CPU写内存的时候有两种方式:
1. write through: CPU同时写内存和写cache。
2. write back: CPU只写到cache中。cache的硬件使用LRU算法将cache里面的内容替换到内存。通常是这种方式。
我们假设MEM里面有一块红色的区域,并且CPU读过它,于是红色区域也进CACHE:
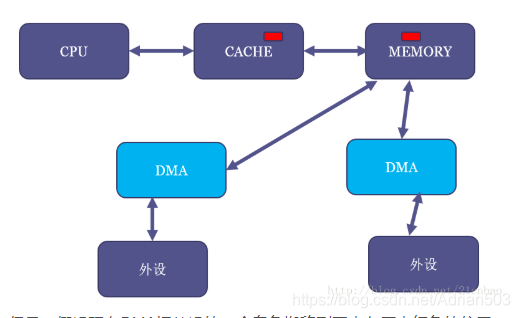
但是,假设现在DMA把外设的一个白色搬移到了内存原本红色的位置:
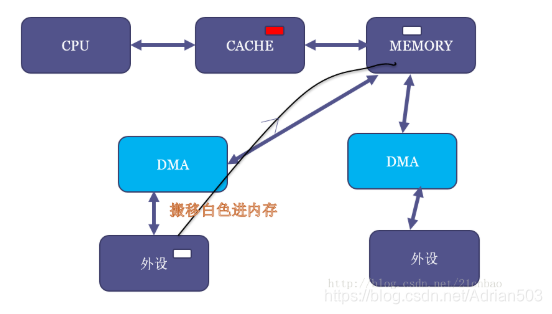
这个时候,内存虽然白了,CPU读到的却还是红色,因为CACHE命中了,这就出现了cache的不coherent。
当然,如果是CPU写数据到内存,它也只是先写进cache(不一定进了内存),这个时候如果做一个内存到外设的DMA操作,外设可能就得到错误的内存里面的老数据。
所以cache coherent的最简单方法,自然是让CPU访问DMA buffer的时候也不带cache。事实上,缺省情况下,dma_alloc_coherent()申请的内存缺省是进行uncache配置的。
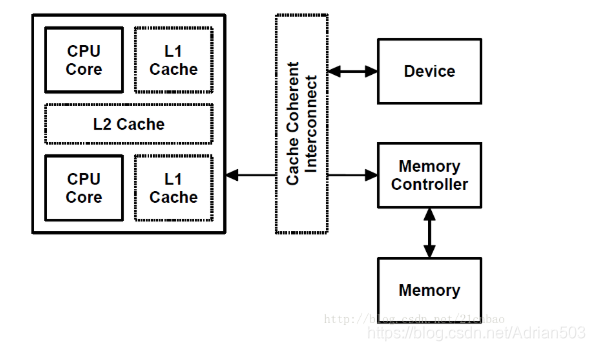
但是,由于现代SoC特别强,这样有一些SoC里面可以用硬件做CPU和外设的cache coherence,如图中的cache coherent interconnect:

这些SoC的厂商就可以把内核的通用实现overwrite掉,变成dma_alloc_coherent()申请的内存也是可以带cache的。这部分还是让大牛Arnd Bergmann童鞋来解释:

来自:https://www.spinics.net/lists/arm-kernel/msg322447.html Arnd Bergmann: dma_alloc_coherent() is a wrapper around a device-specific allocator, based on the dma_map_ops implementation. The default allocator from arm_dma_ops gives you uncached, buffered memory. It is expected that the driver uses a barrier (which is implied by readl/writel but not __raw_readl/__raw_writel or readl_relaxed/writel_relaxed) to ensure the write buffers are flushed. If the machine sets arm_coherent_dma_ops rather than arm_dma_ops, the memory will be cacheable, as it's assumed that the hardware is set up for cache-coherent DMAs.
当我grep内核源代码的时候,我发现部分SoC确实是这样实现的:

所以 dma_alloc_coherent()申请的内存 也是可以带cache的,这个要看硬件的,看厂商的,不过一般默认是不带cache的。
解决 cache 的不一致性 一般有三种方法
1、一种是硬件方案,例如上面介绍的在SoC中集成了叫做“Cache Coherent interconnect”的硬件,它可以做到让DMA踏到CPU的cache或者帮忙做cache的刷新。这样的话,dma_alloc_coherent()申请的内存就没必要是非cache的了。
2、一种是软件上禁用 cache (kernel 机制 ------ 一致性映射)
3、一种是 DMA Streaming Mapping (kernel 机制 ------ 流式映射)
下面主要介绍一下后面两种情况
一般有两种情况,会导致 cache的不一致性,不过kernel都有对应的机制
(1)操作寄存器地址空间
寄存器是CPU与外设交流的接口,有些状态寄存器是由外设根据自身状态进行改变,这个操作对CPU是透明的。有可能这次CPU读入该状态寄存器,下次再读时,该状态寄存器已经变了,但是CPU还是读取的cache中缓存的值。寄存器操作在kernel中是必须保证一致,这是kernel控制外设的基础,IO空间通过ioremap进行映射到内核空间。ioremap在映射寄存器地址时页表是配置为uncached的。数据不走cache,直接由地址空间中读取。保证了数据一致性。
这种情况kernel已经保证了data的一致性,应用场景简单。
(2)DMA申请的内存空间
DMA操作对于CPU来说也是透明的,DMA导致内存中数据更新,对于CPU来说是完全不可见的。反之亦然,CPU写入数据到DMA缓冲区,其实是写到了cache,这时启动DMA,操作DDR中的数据并不是CPU真正想要操作的。
这种情况是,CPU 和DMA 都可以异步的对mem 进行操作,导致data不一致性。
对于cpu 和 dma 都能访问的mem ,kernel有专业的管理方式,分为两种
1. 给DMA申请的内存,禁用 cache ,当然这个是最简单的,不过性能方面是有影响的。
2. 使用过程中,通过flush cache / invalid cache 来保证data 一致性。
通用DMA层主要分为2种类型的DMA映射:
(1)一致性映射,代表函数:
void *dma_alloc_coherent(struct device *dev, size_t size, dma_addr_t *handle, gfp_t gfp); void dma_free_coherent(struct device *dev, size_t size, void *cpu_addr, dma_addr_t handle);
一般驱动使用多,申请一片uncache mem ,这样无需考虑data 一致性。代码流程:对page property,也就是是kernel页管理的页面属性设置成uncache,在缺页异常填TLB时,该属性就会写到TLB的存储属性域中。保证了dma_alloc_coherent映射的地址空间是uncached的。
dma_alloc_coherent首先对分配到的缓冲区进行cache刷新,之后将该缓冲区的页表修改为uncached,以此来保证之后DMA与CPU操作该块数据的一致性。
对于通常的硬件平台(不带硬件cache 一致性的组件),dma_alloc_coherent 内存操作,CPU 直接操作内存,没有cache 参与。
但是也有例外,有的CPU 很强,dma_alloc_coherent 也是可以申请到 带 cache的内存的。
(2)流式DMA映射(DMA Streaming Mapping),
实际工程中,我们自己写的驱动,当然可以使用 dma_alloc_coherent 申请一致性的内存,但是实际工程中,我们并不能使用dma_alloc_coherent, 我们很难控制内存是自己申请的,举个例子:
dma_addr_t dma_map_single(struct device *dev, void *cpu_addr, size_t size, enum dma_data_direction dir) void dma_unmap_single(struct device *dev, dma_addr_t handle, size_t size, enum dma_data_direction dir) void dma_sync_single_for_cpu(struct device *dev, dma_addr_t handle, size_t size, enum dma_data_direction dir) void dma_sync_single_for_device(struct device *dev, dma_addr_t handle, size_t size, enum dma_data_direction dir) int dma_map_sg(struct device *, struct scatterlist *, int, enum dma_data_direction); void dma_unmap_sg(struct device *, struct scatterlist *, int, enum dma_data_direction);
相关接口为 dma_map_sg(), dma_unmap_sg(),dma_map_single(),dma_unmap_single()。
一致性缓存的方式是内核专门申请好一块内存给DMA用。而有时驱动并没这样做,而是让DMA引擎直接在上层传下来的内存里做事情。
例如从协议栈里发下来的一个包,想通过网卡发送出去。
但是协议栈并不知道这个包要往哪里走,因此分配内存的时候并没有特殊对待,这个包所在的内存通常都是可以cache的。传过来的socket的 buffer 并不是你申请的,而且不是 dma_alloc_coherent 申请的一致性内存,这个时候你要把 buffer的内容发出去,或者把收到的报文扔到这个 buffer里面去,那这个时候怎么办呢?
这时,内存在给DMA使用之前,就要调用一次dma_map_sg()或dma_map_single(),取决于你的DMA引擎是否支持聚集散列(DMA scatter-gather),支持就用dma_map_sg(),不支持就用dma_map_single()。DMA用完之后要调用对应的unmap接口。
由于协议栈下来的包的数据有可能还在cache里面,调用dma_map_single()后,CPU就会做一次cache的flush,将cache的数据刷到内存,这样DMA去读内存就读到新的数据了。
dma_map_single (做一遍cache的flush ,将cache的内容flush到内存)
dma 发报文 (由于做过flush ,发的就是正确的包)
dma_unmap_single
dma_map_single (做一遍cache的invalid,将cache的内容无效,重新读取内存)
dma 发报文 (由于做过invalid ,收到的就是正确的包)
dma_unmap_single
dma_map_single 是有一个方向的参数的,来决定是invalid 还是 flush
注意,在map的时候要指定一个参数,来指明数据的方向是从外设到内存还是从内存到外设:
从内存到外设:CPU会做cache的flush操作,将cache中新的数据刷到内存。
从外设到内存:CPU将cache置无效 invalid,这样CPU读的时候不命中,就会从内存去读新的数据。
(CPU读取cache 都是自动硬件完成的,软件不能干预,但是可以控制cache,可以invalid 可以 flush)
还要注意,这几个接口都是一次性的,每次操作数据都要调用一次map和unmap。并且在map期间,CPU不能去操作这段内存,因此如果CPU去写,就又不一致了。
同样的,dma_map_sg()和dma_map_single()的后端实现也都是和硬件特性相关。
其他方式
上面说的是常规DMA,有些SoC可以用硬件做CPU和外设的cache coherence,例如在SoC中集成了叫做“Cache Coherent interconnect”的硬件,它可以做到让DMA踏到CPU的cache或者帮忙做cache的刷新。这样的话,dma_alloc_coherent()申请的内存就没必要是非cache的了。
番外篇
我们在思维上,一定要想到 dma_alloc_coherent 的接口,只是一个前端,它具体的实现是和硬件有关系的,是和平台有关系的。
(1) 下面的例子是 CPU 内部有 保证 cache 一致性的组件,所以dma_alloc_coherent 也是可以申请到 带 cache的内存的。
(2) DMA scatter-gather (DMA引擎是否支持聚集散列) -- 不需要物理内存连续 ,流式映射。
DMA scatter-gather (DMA引擎是否支持聚集散列)
Scatter:离散(不连续)
Gather:聚合 (连续)
这个时候 DMA的内存就可以是物理不连续的了,可以将 连续的内存中的数据 搬移 到 不连续的内存。 可以将不连续的内存 搬移到 连续的内存。
硬件上可以连续传送多个buffer ,不需要物理内存的连续。
这个时候,如果要进行流式映射,要用到 dma_map_sg() , 会将多个不连续的内存,都从 cache 上 flush一下,或者 invalid cache。
(3) 带 MMU 的 DMA引擎 (叫IOMMU 或者 SMMU)
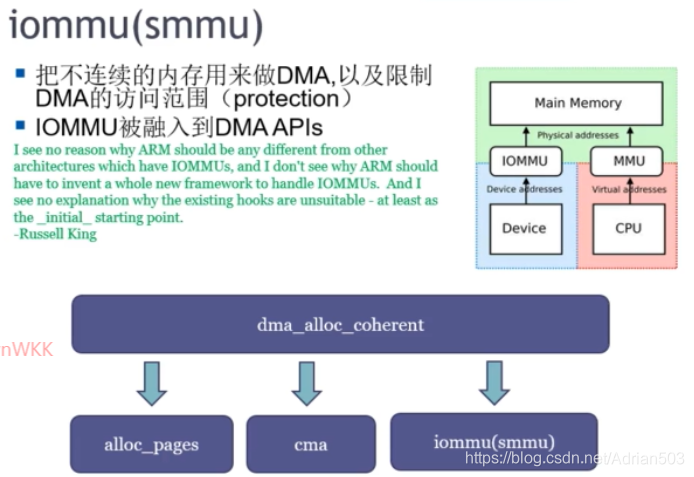
dma_alloc_coherent 只是一个前端,后端直接可以跟 buddy 要内存,也可以跟CMA要内存,也可以通过 IOMMU / SMMU。
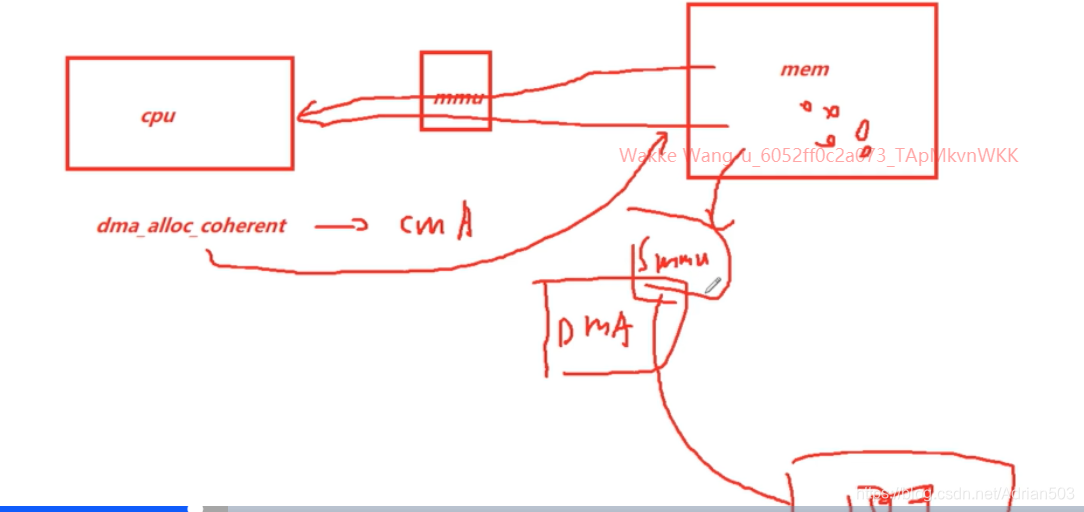
IOMMU 或者 SMMU 会将不连续的物理地址,通过页表映射的方式,统一变成虚拟地址连续的地址,然后给到DMA使用。
这些都是硬件来做的。所以 dma_alloc_coherent 申请到的物理内存是可以不连续的。
具体的dma的使用,可参考一下:
Documentation/Dmaengine.txt
Documentation/DMA-API-HOWTO.txt
Documentation/DMA-API
drivers/dma/dmatest.c
linux下DMA驱动测试代码
DMA传输可以是内存到内存、内存到外设和外设到内存。这里的代码通过dma驱动实现了内存到内存的数据传输。
/* Function description:When we call dmatest_read(),it will transmit src memory data to dst memory,then print dst memory data by dma_callback_func(void) function. */ #include<linux/module.h> #include<linux/init.h> #include<linux/fs.h> #include<linux/sched.h> #include<linux/device.h> #include<linux/string.h> #include<linux/errno.h> #include<linux/types.h> #include<linux/slab.h> #include<linux/dmaengine.h> #include<linux/dma-mapping.h> #include<asm/uaccess.h> #define DEVICE_NAME "dma_test" unsigned char dmatest_major; static struct class *dmatest_class; struct dma_chan *chan; //bus address dma_addr_t dma_src; dma_addr_t dma_dst; //virtual address char *src = NULL; char *dst = NULL ; struct dma_device *dev; struct dma_async_tx_descriptor *tx = NULL; enum dma_ctrl_flags flags; dma_cookie_t cookie; //When dma transfer finished,this function will be called. void dma_callback_func(void) { int i; for (i = 0; i < 512; i++){ printk(KERN_INFO "%c",dst[i]); } } int dmatest_open(struct inode *inode, struct file *filp) { return 0; } int dmatest_release(struct inode *inode, struct file *filp) { return 0; } static ssize_t dmatest_read(struct file *filp, char __user *buf, size_t size, loff_t *ppos) { int ret = 0; //alloc a desc,and set dst_addr,src_addr,data_size. tx = dev->device_prep_dma_memcpy(chan, dma_dst, dma_src, 512, flags); if (!tx){ printk(KERN_INFO "Failed to prepare DMA memcpy"); } tx->callback = dma_callback_func;//set call back function tx->callback_param = NULL; cookie = tx->tx_submit(tx); //submit the desc if (dma_submit_error(cookie)){ printk(KERN_INFO "Failed to do DMA tx_submit"); } dma_async_issue_pending(chan);//begin dma transfer return ret; } static ssize_t dmatest_write(struct file *filp, const char __user *buf, size_t size, loff_t *ppos) { int ret = 0; return ret; } static const struct file_operations dmatest_fops = { .owner = THIS_MODULE, .read = dmatest_read, .write = dmatest_write, .open = dmatest_open, .release = dmatest_release, }; int dmatest_init(void) { int i; dma_cap_mask_t mask; //the first parameter 0 means allocate major device number automatically dmatest_major = register_chrdev(0,DEVICE_NAME,&dmatest_fops); if (dmatest_major < 0) return dmatest_major; //create a dmatest class dmatest_class = class_create(THIS_MODULE,DEVICE_NAME); if (IS_ERR(dmatest_class)) return -1; //create a dmatest device from this class device_create(dmatest_class,NULL,MKDEV(dmatest_major,0),NULL,DEVICE_NAME); //alloc 512B src memory and dst memory src = dma_alloc_coherent(NULL, 512, &dma_src, GFP_KERNEL); printk(KERN_INFO "src = 0x%x, dma_src = 0x%x\n",src, dma_src); dst = dma_alloc_coherent(NULL, 512, &dma_dst, GFP_KERNEL); printk(KERN_INFO "dst = 0x%x, dma_dst = 0x%x\n",dst, dma_dst); for (i = 0; i < 512; i++){ *(src + i) = 'a'; } dma_cap_zero(mask); dma_cap_set(DMA_MEMCPY, mask);//direction:memory to memory chan = dma_request_channel(mask,NULL,NULL); //request a dma channel printk(KERN_INFO "dma channel id = %d\n",chan->chan_id); flags = DMA_CTRL_ACK | DMA_PREP_INTERRUPT; dev = chan->device; return 0; } void dmatest_exit(void) { unregister_chrdev(dmatest_major,DEVICE_NAME);//release major device number device_destroy(dmatest_class,MKDEV(dmatest_major,0));//destroy globalmem device class_destroy(dmatest_class);//destroy globalmem class //free memory and dma channel dma_free_coherent(NULL, 512, src, &dma_src); dma_free_coherent(NULL, 512, dst, &dma_dst); dma_release_channel(chan); } module_init(dmatest_init); module_exit(dmatest_exit); MODULE_LICENSE("GPL");


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
2017-01-20 SecureCRT 出现乱码解决方法
2017-01-20 Sublime Text光标调到行尾,加分号,换行的快捷键设置方法
2017-01-20 Sublime text的文件和linux主机之间的互传
2017-01-20 sublime text软件简单操作