

linux 内核 --- 临界区关抢占/关中断的区别
preempt_disable() local_irq_disable()/local_irq_save(flags) spin_lock() spin_lock_irq()/spin_lock_irqsave(lock, flags)
spin_lock()会调用preempt_disable() 导致本核的抢占调度被关闭(preempt_disable函数实际增加preempt_count来达到此效果),spin_lock_irq()是local_irq_disable()+preempt_disable()的合体。
local_irq_disable()/local_irq_save()的disable和save版的唯一区别是,要不要保存CPU对中断的屏蔽状态。
spin_lock_irq()/spin_lock_irqsave(lock, flags)的唯一区别是,要不要保存CPU对中断的屏蔽状态。
Kernel的代码明确显示,执行抢占调度的时候,会同时检测“non-zero preempt_count or interrupts are disabled”:

asmlinkage __visible void __sched notrace preempt_schedule(void) { /* * If there is a non-zero preempt_count or interrupts are disabled, * we do not want to preempt the current task. Just return.. */ if (likely(!preemptible())) return; preempt_schedule_common(); }
对于ARM处理器而言,判断irqs_disabled(),其实就是判断CPSR中的IRQMASK_I_BIT是否被设置。
最开始列出的所有函数,都能关闭本核的抢占调度。因为,无论是preempt_count计数状态,还是中断被关闭,都会导致kernel认为无法抢占!
既然都关闭了抢占,那么区别在哪里呢?
我们看两段代码,假设下面的代码都发生在NICE为0的普通进程:
preempt_disable() xxx(1) preempt_enable() 和 local_irq_disable() xxx(2) local_irq_enable()
首先,xxx(1)和xxx(2)里面,都是不可以抢占的。一个搞定了preempt_count,一个搞定了中断。
但是假设xxx(1)内唤醒了一个高优先级的RT任务,那么在preempt_enable()的时刻,直接就是一个抢占点,这个时候,发生schedule,高优先级RT任务进来跑;假设xxx(2)内唤醒了一个高优先级的RT任务,那么在local_irq_enable()的时刻,不是一个抢占点,高优先级RT的任务必须等待下一个抢占点。下一个抢占点,可能是时钟tick处理返回、中断返回、软中断结束、yield()等等多种情况。
在preempt_enable()中,会执行一次preempt_schedule():
#define preempt_enable() \ do { \ barrier(); \ if (unlikely(preempt_count_dec_and_test())) \ __preempt_schedule(); \ } while (0)
而local_irq_enable()只是单纯的开启CPU对中断的响应,对于ARM而言,它就是:
#define arch_local_irq_enable arch_local_irq_enable static inline void arch_local_irq_enable(void) { asm volatile( " cpsie i @ arch_local_irq_enable" : : : "memory", "cc"); }
再来看大boss,spin_lock_irq是同时调用了preempt_disable和local_irq_disable:
static inline void __raw_spin_lock_irq(raw_spinlock_t *lock) { local_irq_disable(); preempt_disable(); spin_acquire(&lock->dep_map, 0, 0, _RET_IP_); LOCK_CONTENDED(lock, do_raw_spin_trylock, do_raw_spin_lock); }
而对应的spin_unlock_irq()则同时调用了local_irq_enable()和preempt_enable():
static inline void __raw_spin_unlock_irq(raw_spinlock_t *lock) { spin_release(&lock->dep_map, _RET_IP_); do_raw_spin_unlock(lock); local_irq_enable(); preempt_enable(); }
为何preempt_enable()比local_irq_enable()后发生呢?如果代码顺序是这样的:
preempt_enable()
local_irq_enable()
第一句preempt_enable()想执行抢占调度的话,即便调用了preempt_schedule(),但是由于IRQ还是关门的,preempt_schedule()函数会立即返回,所以无法抢占;后一句local_irq_enable()不会执行抢占调度。所以,如果这么干的话,
spin_lock_irq() xxx(3) spin_unlock_irq()
如果xxx(3)唤醒了高优先级的RT,在spin_unlock_irq()的时刻,将无法直接抢占!
还好,真正的顺序是:
local_irq_enable()
preempt_enable()
所以,在spin_unlock_irq()的时刻,RT进程就换入执行了。
看小一点的boss,spin_lock():
spin_lock() xxx(4) spin_unlock()
如果xxx(4)唤醒了RT进程,在spin_unlock()的时刻,会立即抢入。因为spin_unlock()会调用preempt_enable()。
而抢占又杀了谁?
理论上,关抢占,并没有彻底的关闭调度器,因为进程还是可以主动地sleep:

上述代码,在spin_lock的区间里面,调用了msleep(),这个时候,不属于抢占,Linux还是会pick下一个task来跑
不过这样的代码,一般在后期蕴藏着巨大的风险,导致后期的莫名崩溃。所以呢,实际的工程里面,我们是严格地禁止的。
建议大家打开Kernel里面的config里面的DEBUG_ATOMIC_SLEEP,一旦出现这种情况,让kernel去汇报错误。
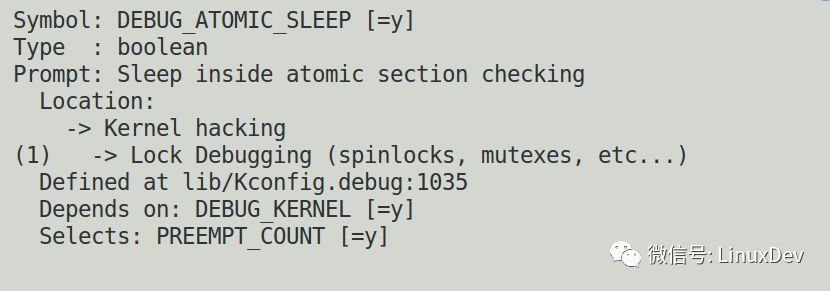
这种情况下,kernel检测到有人在atomic上下文里面执行可能睡眠的行为,会直接报执行的栈回溯。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· 写一个简单的SQL生成工具
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
2017-10-19 matlab --- 无约束遗传算法
2017-10-19 matlab --- 矩阵的操作
2016-10-19 Altium Designer 15 --- 元器件编号及命名