

linux进程的管理与调度 --- 调度基础
进程调度含义
进程调度决定了将哪个进程进行执行,以及执行的时间。操作系统进行合理的进程调度,使得资源得到最大化的利用。
在单片机上,常常使用的方式是:系统初始化---->while(1){}。(当然,单片机也可以跑类似 FreeRTOS,也可以有进程切换)
在带操作系统的 CPU 上跑的逻辑是,允许多个进程(其实就是程序) ”同时” 跑。比如,你可以在操作鼠标的同时,进行音乐播放,文字编辑等。宏观上看上去是多个任务并行执行,事实的本质是 CPU 在不断的调度每一个进程,使得每个进程都得以响应,与此同时,还要兼顾不同场景下的响应效率(进程的执行时间)。
进程调度器的任务就是合理分配CPU时间给运行的进程,创造一种所有进程并行运行的错觉。这就对调度器提出了要求:
1、调度器分配的CPU时间不能太长,否则会导致其他的程序响应延迟,难以保证公平性。
2、调度器分配的时间也不能太短,每次调度会导致上下文切换,这种切换开销很大。
而调度器的任务就是:1、分配时间给进程 2、上下文切换
所以具体而言,调度器的任务就明确了:用一句话表述就是在恰当的实际,按照合理的调度算法,选择进程,让进程运行到它应该运行的时间,切换两个进程的上下文。
I/O 消耗型和 CPU 消耗型
运行的进程如果大部分来进行 I/O 的请求或者等待的话,这个进程称之为 I/O 消耗型,比如键盘。这种类型的进程经常处于可以运行的状态,但是都只是运行一点点时间,绝大多数的时间都在处于阻塞(睡眠)的状态。
如果进程的绝大多数都在使用 CPU 做运算的话,那么这种进程称之为 CPU 消耗型,比如开启 Matlab 做一个大型的运算。没有太多的 I/O 需求,从系统响应的角度上来讲,调度器不应该经常让他们运行。对于处理器消耗型的进程,调度策略往往是降低他们的执行频率,延长运行时间。
Linux 系统为了提升响应的速度,倾向于优先调度 I/O 消耗型。
进程的优先级
调度算法中比较基本的就是靠进程的优先级来进行进程的调度,比如 FreeRTOS,靠 task 的优先级来进行进程的抢占。
一、普通进程
在 Linux 中普通进程依赖称之为 nice 值进行进程的优先级描述。nice 值的范围是 [-20, 19]。默认的 default 值为 0;越低的 nice 值,代表着越高的优先级,反之,越高的 nice 值代表着越低的优先级。
越高优先级的普通进程有着越多的执行时间(在一个调度周期内,每个可执行的进程都执行一遍的情况)。可以通过 ps -el 查看系统中进程列表
二、实时进程
实时优先级是可配置的默认情况下的范围是 0~99,与 nice 值相反,越高的数值代表着越高的优先级。与此同时,任何实时进程的优先级都高于普通进程的优先级。
小结
实时进程优先级:value 越高,优先级越大
普通进程优先级:nice值越高,优先级越小
任何实时进程的优先级 > 普通进程
Linux 调度算法
Linux 中有一个总的调度结构,称之为 调度器类(scheduler class),它允许不同的可动态添加的调度算法并存,总调度器根据调度器类的优先顺序,依次从调度器类中取出进程进行调度。挑选了调度器类,再在这个调度器内,使用这个调度器类的算法(调度策略)进行内部的调度
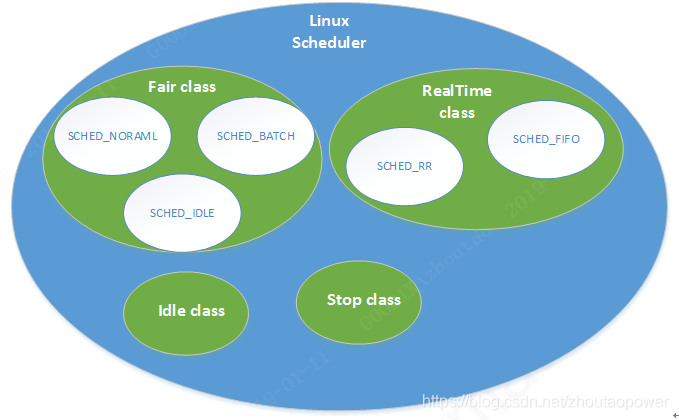
调度器的优先级顺序为:
Scheduling Class 的优先级顺序为 Stop_Task > Real_Time > Fair > Idle_Task,根据设计需求,把Task配置到不同的Scheduling Class中。其中的 Real_time 和 Fair 是最最常用的,下面主要聊聊着两类。
一、普通进程 - CFS 调度算法,即完全公平调度器
对于一个普通进程,CFS 调度器调度它执行(SCHED_NORMAL),需要考虑两个方面维度:
1. 如何挑选哪一个进程进入运行状态?
在 CFS 中,给每一个进程安排了一个虚拟时间 vruntime(virtual runtime),这个变量并非直接等于他的绝对运行时间,而是根据运行时间放大或者缩小一个比例,CFS 使用这个 vruntime 来代表一个进程的运行时间。如果一个进程得以执行,那么他的 vruntime 将不断增大,直到它没有执行。没有执行的进程的 vruntime 不变。调度器为了体现绝对的完全公平的调度原则,总是选择 vruntime 最小的进程,让其投入执行。他们被维护到一个以 vruntime 为顺序的红黑树 rbtree 中,每次取最小的 vruntime 的进程来投入运行。
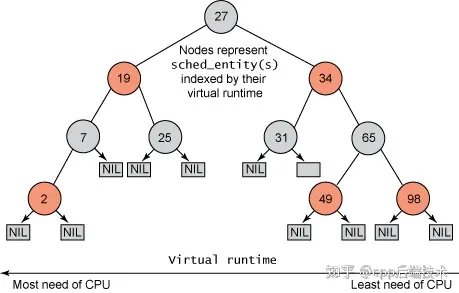
如上图所示,红黑树的左节点比父节点小,而右节点比父节点大。所以查找最小节点时,只需要获取红黑树的最左节点即可。
实际运行时间和 vruntime 的关系为:
[ vruntime = 实际运行时间 * 1024 / 进程权重 ] // 实际运行时间越多,vruntime越大;权重越小,vruntime越大;vruntime越大,越没有机会运行
这里的1024代表nice值为0的进程权重(nice和权重的对应如下数组)。所有的进程都以nice为0的权重1024作为基准,计算自己的vruntime。上面两个公式可得出,虽然进程的权重不同,但是它们的 vruntime增长速度应该是一样的 ,与权重无关。既然所有进程的vruntime增长速度宏观上看应该是同时推进的,那么就可以用vruntime来选择运行的进程,vruntime值较小就说明它以前占用cpu的时间较短,受到了“不公平”对待,因此下一个运行进程就是它。这样既能公平选择进程,又能保证高优先级进程获得较多的运行时间,这就是CFS的主要思想。

const int sched_prio_to_weight[40] = { /* -20 */ 88761, 71755, 56483, 46273, 36291, /* -15 */ 29154, 23254, 18705, 14949, 11916, /* -10 */ 9548, 7620, 6100, 4904, 3906, /* -5 */ 3121, 2501, 1991, 1586, 1277, /* 0 */ 1024, 820, 655, 526, 423, /* 5 */ 335, 272, 215, 172, 137, /* 10 */ 110, 87, 70, 56, 45, /* 15 */ 36, 29, 23, 18, 15, };
所以,优先级高的进程,随着运行时间的加长,vruntime值慢慢变大,从而使没有运行的优先级低的进程得到运行。
2. 挑选的进程进行运行了,它运行多久?
进程运行的时间是根据进程的权重进行分配。
[ 分配给进程的运行时间 = 调度周期 *(进程权重 / 所有进程权重之和) ]
CFS 调度器实体结构作为一个名为 se 的 sched_entity 结构,嵌入到进程描述符 struct task_struct 中
二、实时进程 - 实时调度策略
对于实时调度策略分为两种:SCHED_FIFO 和 SCHED_RR:
这两种进程都比任何普通进程的优先级更高(SCHED_NORMAL),都会比他们更先得到调度。
SCHED_FIFO : 一个这种类型的进程处于可执行的状态,就会一直执行,直到它自己被阻塞或者主动放弃 CPU;只有更高优先级的 SCHED_FIFO 或者 SCHED_RR 才能抢占它的任务,如果有两个同样优先级的 SCHED_FIFO 任务,它们会轮流执行,其他低优先级的只有等它们变为不可执行状态,才有机会执行。
SCHED_RR : 与 SCHED_FIFO 大致相同,只是 SCHED_RR 级的进程在耗尽其时间后,不能再执行,需要接受 CPU 的调度。当 SCHED_RR 耗尽时间后,同一优先级的其他实时进程被轮流调度。
上述两种实时算法都是静态的优先级。内核不为实时优先级的进程计算动态优先级,保证给定的优先级的实时进程总能够抢占比他优先级低的进程。
Linux 调度时机
一、为什么调度
从进程的角度看,CPU是共享资源,由所有的进程按特定的策略轮番使用。一个进程离开CPU、另一个进程占据CPU的过程,称为进程切换(process switch)。进程切换是在内核中通过调用schedule()完成的。
发生进程切换的场景有以下三种:
1、进程运行不下去了
比如因为要等待IO完成,或者等待某个资源、某个事件,典型的内核代码如下:
//把进程放进等待队列,把进程状态置为TASK_UNINTERRUPTIBLE prepare_to_wait(waitq, wait, TASK_UNINTERRUPTIBLE); //切换进程 schedule();
2、进程还在运行,但内核不让它继续使用CPU了
比如进程的时间片用完了,或者优先级更高的进程来了,所以该进程必须把CPU的使用权交出来;
3、进程还可以运行,但它自己的算法决定主动交出CPU给别的进程
用户程序可以通过系统调用sched_yield()来交出CPU,内核则可以通过函数cond_resched()或者yield()来做到。调用cond_resched()不一定就会让出CPU,会判断当前进程是否需要被抢占,需要被抢占才让出CPU。
进程切换分为自愿切换(Voluntary)和强制切换(Involuntary),以上场景1属于自愿切换,场景2和3属于强制切换。
- 自愿切换发生的时候,进程不再处于运行状态,比如由于等待IO而阻塞(TASK_UNINTERRUPTIBLE),或者因等待资源和特定事件而休眠(TASK_INTERRUPTIBLE),又或者被debug/trace设置为TASK_STOPPED/TASK_TRACED状态;
- 强制切换发生的时候,进程仍然处于运行状态(TASK_RUNNING),通常是由于被优先级更高的进程抢占(preempt),或者进程的时间片用完了。
自愿切换也叫主动调取,强制切换也叫抢占式调度。
注意:进程可以通过调用sched_yield()主动交出CPU,这不是自愿切换,而是属于强制切换,因为进程仍然处于运行状态。有时候内核代码会在耗时较长的循环体内通过调用 cond_resched()或yield() ,主动让出CPU,以免CPU被内核代码占据太久,给其它进程运行机会。这也属于强制切换,因为进程仍然处于运行状态。
进程自愿切换(Voluntary)和强制切换(Involuntary)的次数被统计在 /proc/<pid>/status 中,其中voluntary_ctxt_switches表示自愿切换的次数,nonvoluntary_ctxt_switches表示强制切换的次数,两者都是自进程启动以来的累计值。
也可以用 pidstat -w 命令查看进程切换的每秒统计值:
pidstat -w 1 Linux 3.10.0-229.14.1.el7.x86_64 (bj71s060) 02/01/2018 _x86_64_ (2 CPU) 12:05:20 PM UID PID cswch/s nvcswch/s Command 12:05:21 PM 0 1299 0.94 0.00 httpd 12:05:21 PM 0 27687 0.94 0.00 pidstat
自愿切换和强制切换的统计值在实践中有什么意义呢?
大致而言,如果一个进程的自愿切换占多数,意味着它对CPU资源的需求不高。如果一个进程的强制切换占多数,意味着对它来说CPU资源可能是个瓶颈,这里需要排除进程频繁调用sched_yield()导致强制切换的情况。
二、调度时机
自愿切换意味着进程需要等待某种资源,不需要设置重新调度标志,直接调用 schedule() 进行进程切换,强制切换则与抢占(Preemption)有关。
抢占(Preemption)是指内核强行切换正在CPU上运行的进程,在随后的某个时刻被抢占的进程还可以恢复运行。发生抢占的原因主要有:进程的时间片用完了,或者优先级更高的进程来争夺CPU了。
抢占的过程分两步,第一步触发抢占,第二步执行抢占,这两步中间不一定是连续的,有些特殊情况下甚至会间隔相当长的时间:
- 触发抢占:给正在CPU上运行的当前进程设置一个请求重新调度的标志(TIF_NEED_RESCHED),仅此而已,此时进程并没有切换。
- 执行抢占:在随后的某个时刻,内核会检查TIF_NEED_RESCHED标志并调用preempt_schedule_common()执行抢占。
抢占只在某些特定的时机发生,这是内核的代码决定的。
触发抢占的时机
每个进程都包含一个TIF_NEED_RESCHED标志,内核根据这个标志判断该进程是否应该被抢占,设置TIF_NEED_RESCHED标志就意味着触发抢占。
struct task_struct { #ifdef CONFIG_THREAD_INFO_IN_TASK /* * For reasons of header soup (see current_thread_info()), this * must be the first element of task_struct. */ struct thread_info thread_info; } struct thread_info { unsigned long flags; /* low level flags */ };
/* * thread information flags: * TIF_USEDFPU - FPU was used by this task this quantum (SMP) * TIF_POLLING_NRFLAG - true if poll_idle() is polling TIF_NEED_RESCHED * * Any bit in the range of 0..15 will cause do_work_pending() to be invoked. */ #define TIF_SIGPENDING 0 /* signal pending */ #define TIF_NEED_RESCHED 1 /* rescheduling necessary */ #define TIF_NOTIFY_RESUME 2 /* callback before returning to user */ #define TIF_UPROBE 3 /* breakpointed or singlestepping */ #define TIF_SYSCALL_TRACE 4 /* syscall trace active */
直接设置TIF_NEED_RESCHED标志的函数是 set_tsk_need_resched();
触发抢占的函数是resched_curr()。
TIF_NEED_RESCHED标志什么时候被设置呢?在以下时刻:
周期性的时钟中断
时钟中断处理函数会调用scheduler_tick(),这是调度器核心层(scheduler core)的函数,它通过调度类(scheduling class)的task_tick()检查进程的时间片是否耗尽,如果耗尽则触发抢占:
kernel/sched/core.c scheduler_tick ->curr->sched_class->task_tick(rq, curr, 0) ->task_tick_fair ->entity_tick ->check_preempt_tick ->4374 if (delta_exec > ideal_runtime) { //1.当前任务的实际运行时间大于理想运行时间 4375 resched_curr(rq_of(cfs_rq)); //设置重新调度标志 4389 if (delta_exec < sysctl_sched_min_granularity) //当前任务的实际运行时间 小于 最小调度粒度吗? 4390 return; 4398 if (delta > ideal_runtime) //2.红黑树最左边的任务的虚拟运行时间和当前任务的虚拟运行时间的差值大于理想运行时间 4399 resched_curr(rq_of(cfs_rq)); //设置重新调度标志
唤醒进程的时候
当调用 wake_up_process() 唤醒进程的时候,相应的内核代码中,try_to_wake_up()最终通过check_preempt_curr()检查是否触发抢占,判断条件:唤醒的任务的虚拟运行时间和当前任务的虚拟运行时间差值大于最小唤醒抢占粒度转换的虚拟运行时间(唤醒的任务的虚拟运行时间更小)
新进程创建的时候
如果新进程的优先级高于CPU上的当前进程,会触发抢占。相应的调度器核心层代码是sched_fork(),它再通过调度类的 task_fork方法触发抢占:
int sched_fork(unsigned long clone_flags, struct task_struct *p) { ... if (p->sched_class->task_fork) p->sched_class->task_fork(p); ... }
进程修改nice值的时候
如果进程修改nice值导致优先级高于CPU上的当前进程,也会触发抢占。内核代码参见 set_user_nice()。
进行负载均衡的时候
在多CPU的系统上,进程调度器尽量使各个CPU之间的负载保持均衡,而负载均衡操作可能会需要触发抢占。
不同的调度类有不同的负载均衡算法,涉及的核心代码也不一样,比如CFS类在load_balance()中触发抢占:
load_balance()
{
...
move_tasks();
...
resched_cpu();
...
}
RT类的负载均衡基于overload,如果当前运行队列中的RT进程超过一个,就调用push_rt_task()把进程推给别的CPU,在这里会触发抢占。
执行抢占的时机
触发抢占通过设置进程的TIF_NEED_RESCHED标志告诉调度器需要进行抢占操作了,但是真正执行抢占还要等内核代码发现这个标志才行,而内核代码只在设定的几个点上检查TIF_NEED_RESCHED标志,这也就是执行抢占的时机。
抢占分为User Preemption(用户态抢占)和Kernel Preemption(内核态抢占)。注意,抢占只能发生在内核。
执行User Preemption(用户态抢占)的时机
用户态抢占,不是在用户空间抢占,而且在返回用户空间前抢占,所以被抢占的点是用户空间。
用户态抢占是操作系统最基本的抢占,不可关闭
1. 从系统调用(syscall)返回用户态时;
2. 从中断返回用户态时(包括 tick 中断)
以上强制切换方式习惯地称为“非抢占式内核”也有叫“用户抢占”。其实也就只能叫作“半抢占式内核”或是“有条件抢占”。这种方式是linux2.4的实现方式。在linux2.6中对此进行了修改。大家习惯地称linux2.6内核是“抢占式内核”。
Linux2.4只实现了“有条件抢占式”的调度。它的缺点在于:当外部来一中断,中断程序过程完后,需要一个用户进程B对此进行进一步的处理(响应IP包数据)。此时进程A正在使用系统调用进入了内核态。那么等到A从系统调用返回之际,内核进行调度,B才有可能运行。假设A的系统调用占用了CPU的时间为T。这个T大于用户要求的响应时间。那这个系统就不够实时。为了提高Linux的实时性。在linux2.6中引入了“Kernel preemption”(内核抢占调度模式)。并很好的解决了这个问题。一句话就是抢占式内核可以在进程处于内核态时,进行抢占。
执行Kernel Preemption(内核态抢占)的时机
linux在2.6版本之后就支持内核抢占了,具体取决于内核编译时的这几个选项:
- CONFIG_PREEMPT_NONE=y
不允许内核抢占,只支持用户态抢占。服务器一般都是这个配置。
-
CONFIG_PREEMPT_DYNAMIC=y
在一些耗时较长的内核代码中主动调用cond_resched()让出CPU。
- CONFIG_PREEMPT=y
允许完全内核抢占。
CONFIG_PREEMPT_NONE=N 是“非抢占式内核”,含义是:不可抢占内核态的调度方式。
在 CONFIG_PREEMPT=y 的前提下,内核态抢占的时机是:
1. 中断处理程序(包括 tick 中断)返回内核空间之前会检查TIF_NEED_RESCHED标志,如果置位则调用preempt_schedule_irq()执行抢占。preempt_schedule_irq()内调用__schedule()
asmlinkage __visible void __sched preempt_schedule_irq(void) { enum ctx_state prev_state; /* Catch callers which need to be fixed */ BUG_ON(preempt_count() || !irqs_disabled()); prev_state = exception_enter(); do { preempt_disable(); local_irq_enable(); __schedule(SM_PREEMPT); local_irq_disable(); sched_preempt_enable_no_resched(); } while (need_resched()); exception_exit(prev_state); }
2. 当内核从non-preemptible(禁止抢占)状态变成preemptible(允许抢占)的时候;
在preempt_enable()中,会最终调用 preempt_schedule 来执行抢占。
#define preempt_enable() \ do { \ barrier(); \ if (unlikely(preempt_count_dec_and_test())) \ __preempt_schedule(); \ } while (0)
3. 调用 cond_resched() 主动让出CPU,但是不同于调用 schedule() 无条件进行进程切换,cond_resched() 会判断抢占是否开启,并且当前进程是否允许被抢占
4. 开软中断
local_bh_enable ->__local_bh_enable_ip ->preempt_check_resched ->if (should_resched(0)) \ __preempt_schedule(); ->preempt_schedule


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
2017-05-03 Qt creator 使用技巧
2016-05-03 智能配置上网(微信Airkiss )
2016-05-03 java 中unsigned类型的转换 和 java语言基本数据类型