

linux 中断下半部实现方案 --- 软中断 和 tasklet
中断的分类
中断分为硬中断和软中断,其分类依据是实现机制,而不是触发机制,比如CPU硬中断,它是由CPU这个硬件实现的中断机制,但它的触发可以通过外部硬件(比如GPIO),软件的 INT 指令,或者CPU执行检测(访问非法地址、除法异常)。一些资料会把以上三种方式做区分,把INT n这种方式叫做软件中断,因为是由软件程序主动触发的,把中断和异常叫做硬件中断,因为他们都是硬件自动触发的。关于硬中断的具体实现,就是 CPU 在每一条指令周期的最后,都会留一个CPU时钟周期去查看是否有中断,如果有,就把中断号取出,去中断向量表中寻找中断处理程序,然后跳过去执行。
类似地,软中断是由软件实现的中断,是纯粹由软件实现的一种类似中断的机制,实际上是模仿硬件,在内存中存储着一组软中断的标志位,然后由内核的一个线程检查这些标志位,如果有哪个标志位有效,则再去执行这个软中断对应的中断处理程序。
软中断定义
Linux 将中断处理过程分成了两个阶段,也就是上半部和下半部:
- 上半部用来快速处理中断,它在中断禁止模式下运行,主要处理跟硬件紧密相关的或时间敏感的工作。
- 下半部用来延迟处理上半部未完成的工作,通常以内核线程的方式运行。
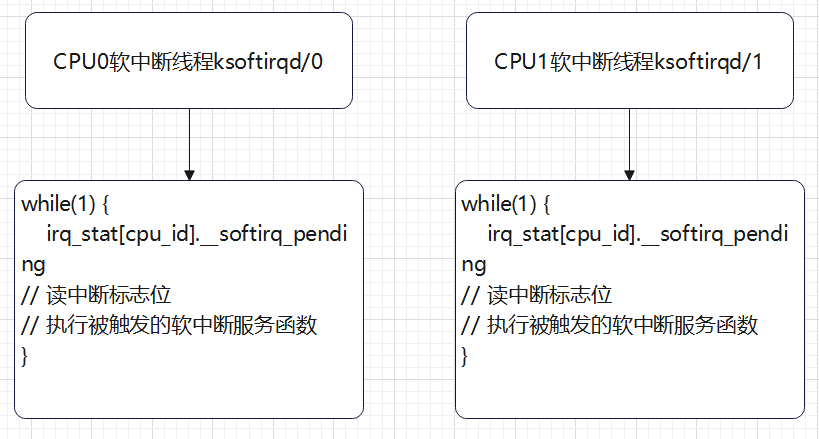
上半部会打断CPU正在执行的任务,然后立即执行中断服务程序。而下半部以内核线程的方式执行,并且每个CPU对应一个软中断内核线程,名字为“ksoftirqd/CPU编号”,比如说, 0 号 CPU 对应的软中断内核线程的名字就是 ksoftirqd/0。软中断线程读取中断标志位,进而执行不同类型的软中断服务函数。
由于每个CPU都有一个软中断线程,所以软中断服务函数可以并发运行在多个CPU上(即使同一类型软中断的也可以),所以软中断执行函数必须设计为可重入的函数(允许多个CPU同时操作),因此也需要使用自旋锁来保其数据结构。
软中断不只包括了硬件设备中断处理程序的下半部,一些内核自定义的事件也属于软中断,比如内核调度和 RCU 锁等
proc 文件系统。它是一种内核空间和用户空间进行通信的机制,可以用来查看内核的数据结构,或者用来动态修改内核的配置。其中:
- /proc/softirqs提供了软中断的运行情况;
- /proc/interrupts 提供看硬中断的运行情况。
软中断(softirq) 之所以性能高的原因,在 SMP 系统下允许多个 cpu 同时并发处理同一类型软中断服务函数,并且软中断上下文不会调用任何阻塞接口。如网卡的 fifo 半满中断触发,被 cpu0 处理,cpu0 会在关闭中断后,将数据从网卡的 fifo 拷贝到 ram 之后触发软中断,再打开中断,基于哪个CPU触发软中断就哪个CPU执行软中断服务函数原则,cpu0 会继续执行软中断服务函数。若网卡的 fifo 全满中断有再次触发,就会被 cpu1 处理,同样是关闭中断后拷贝数据再开启中断,再去触发和执行软中断进行网卡数据包处理。若此时 cpu0\cpu1 都还在软中断处理数据,网卡再次产生中断,那么 cpu2 就会继续相同的流程。由此可见,软中断充分利用多 cpu 进行并发处理,同一类型软中断服务函数在三个CPU上同时运行,因此性能非常高,但也同时因为并发的存在,就需要考虑临界区的问题。
内核代码分析
软中断类型
每个软中断都对应一个执行函数

enum { HI_SOFTIRQ=0, TIMER_SOFTIRQ, NET_TX_SOFTIRQ, NET_RX_SOFTIRQ, BLOCK_SOFTIRQ, IRQ_POLL_SOFTIRQ, TASKLET_SOFTIRQ, SCHED_SOFTIRQ, HRTIMER_SOFTIRQ, RCU_SOFTIRQ, /* Preferable RCU should always be the last softirq */ NR_SOFTIRQS };
软中断注册
软中断的注册(软中断执行函数写到内核管理的全局数组内),默认注册 HI_SOFTIRQ 和 TASKLET_SOFTIRQ 这两个软中断
void __init softirq_init(void) { int cpu; for_each_possible_cpu(cpu) { per_cpu(tasklet_vec, cpu).tail = &per_cpu(tasklet_vec, cpu).head; per_cpu(tasklet_hi_vec, cpu).tail = &per_cpu(tasklet_hi_vec, cpu).head; } open_softirq(TASKLET_SOFTIRQ, tasklet_action); open_softirq(HI_SOFTIRQ, tasklet_hi_action); }
软中断注册函数
void open_softirq(int nr, void (*action)(struct softirq_action *)) { softirq_vec[nr].action = action; }
触发软中断
写标志位,唤醒软中断线程,根据标志位执行软中断服务函数
void raise_softirq(unsigned int nr) // 唤醒软中断 { unsigned long flags; local_irq_save(flags); raise_softirq_irqoff(nr); local_irq_restore(flags); }
软中断类型nr对应每cpu变量irq_stat[cpu_id].__softirq_pending的一个比特,即中断标志位,比特置一表示触发了该类型软件中断,这也是同一类型软中断可以在多个cpu上并行运行的根本原因。
static struct smp_hotplug_thread softirq_threads = { .store = &ksoftirqd, .thread_should_run = ksoftirqd_should_run, .thread_fn = run_ksoftirqd, .thread_comm = "ksoftirqd/%u", };
执行软中断
创建软中断线程
static int smpboot_thread_fn(void *data) { struct smpboot_thread_data *td = data; struct smp_hotplug_thread *ht = td->ht; while (1) { set_current_state(TASK_INTERRUPTIBLE); preempt_disable(); ...if (!ht->thread_should_run(td->cpu)) { preempt_enable_no_resched(); schedule(); } else { __set_current_state(TASK_RUNNING); preempt_enable(); ht->thread_fn(td->cpu); } } }
执行软中断服务函数
asmlinkage __visible void __softirq_entry __do_softirq(void) { unsigned long end = jiffies + MAX_SOFTIRQ_TIME; unsigned long old_flags = current->flags; int max_restart = MAX_SOFTIRQ_RESTART; ... current->flags &= ~PF_MEMALLOC; pending = local_softirq_pending(); softirq_handle_begin(); in_hardirq = lockdep_softirq_start(); account_softirq_enter(current); restart: /* Reset the pending bitmask before enabling irqs */... while ((softirq_bit = ffs(pending))) { // 读取中断标志位 ... h->action(h); // 执行被触发的软中断服务函数 ... h++; pending >>= softirq_bit; } ... pending = local_softirq_pending(); if (pending) { // 检查是否在上面代码执行期间,软中断被重新置位 if (time_before(jiffies, end) && !need_resched() && --max_restart) // 检查函数执行时间未超时,并且次数未超次数,重新执行中断服务函数 goto restart; wakeup_softirqd(); } ... }
__do_softirq 会遍历执行每个置位的软中断的中断服务函数,执行完后,再次判断是否有在执行中断服务函数期间重新置位的软中断,在 __do_softirq 执行时间未超时,执行次数未超次数的情况下,会再次遍历执行每个置位的软中断的中断服务函数。否则执行wakeup_softirqd,放置到就绪进程的列表末尾,等待调度器下次调度。
软中断执行优先级为什么比较高
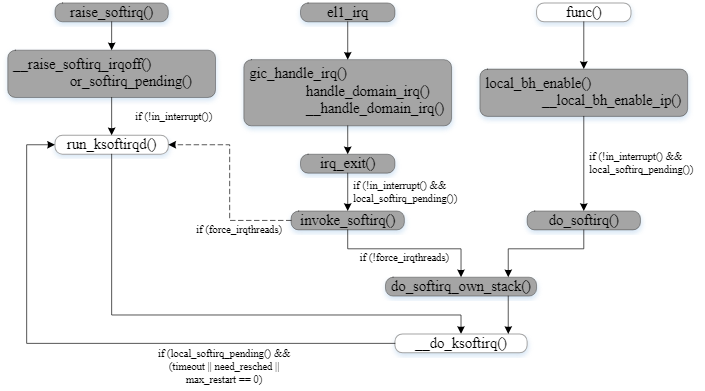
软中断的执行时机有3个:
- 执行 raise_softirq() 。raise_softirq()在中断函数中被调用,此时in_interrupt()非0,不唤醒软中断线程,只设置软中断标志位,等到退出中断前检查中断标志位,直接执行软中断。
- 硬中断退出时(irq_exit时),根据配置可选直接执行或者唤醒软中断线程
- 任何调用local_bh_enable打开本地软中断,直接执行
其中 in_interrupt() 不是表示是否在中断,名字有迷惑行为。
#define in_interrupt() (irq_count()) #define irq_count() (nmi_count() | hardirq_count() | softirq_count()) #define nmi_count() (preempt_count() & NMI_MASK) #define hardirq_count() (preempt_count() & HARDIRQ_MASK) # define softirq_count() (preempt_count() & SOFTIRQ_MASK)
preempt_count() 是记录在 struct thread_info 的成员变量 preempt_count,preempt_count被分成几个部分
* PREEMPT_MASK: 0x000000ff * SOFTIRQ_MASK: 0x0000ff00 * HARDIRQ_MASK: 0x000f0000 * NMI_MASK: 0x00f00000 * PREEMPT_NEED_RESCHED: 0x80000000
SOFTIRQ_MASK:bit8 表示当前是否有软中断在执行,而 bit9 ~ bit15 表示软中断被禁止的次数,local_bh_disable()计数加一,所以如果需要判断是否有软中断正在执行,需要将 softirq_count() & 1<< 8;
HARDIRQ_MASK:在中断函数的开始处,调用 irq_enter() 把 HARDIRQ_MASK 区域加一,在中断函数的结尾处调用 irq_exit() 把 HARDIRQ_MASK 区域减一,所以 HARDIRQ_MASK 区域记录进中断次数,为0表示没有中断嵌套,并且当前中断也处理完,在中断函数的结尾可以处理软中断。硬件中断虽然占据 bit16 ~ bit19,因为新内核不支持中断嵌套,所以只使用了 bit16,其它三位属于冗余部分。
NMI_MASK:不可屏蔽中断进入次数
PREEMPT_MASK:内核线程关闭抢占的次数,preempt_disable()计数加一
tasklet
使用示例模版
#include <linux/module.h> #include <linux/init.h> #include <linux/kernel.h> #include <linux/interrupt.h> static struct tasklet_struct my_tasklet; static void my_tasklet_handle(unsigned long data) { printk("tasklet handle running...\n"); } static irqreturn_t xxx_interrupt(int irq, void *dev_id) { tasklet_schedule(&my_tasklet); // 中断服务函数内触发执行 tasklet 关联的处理函数 } static int __init demo_driver_init(void) { tasklet_init(&my_tasklet, my_tasklet_handle, 0); // 初始化一个 tasklet,关联处理函数 request_irq(xxx, xxx_interrupt, IRQF_SHARED, xxx, xxx); // 注册一个中断服务函数 return 0; } static void __exit demo_driver_exit(void) { tasklet_kill(&my_tasklet); // 保证此 tasklet 从待执行链表移除,因为 exit 后,此 tasklet 的内存空间被释放了 return ; } module_init(demo_driver_init); module_exit(demo_driver_exit); MODULE_LICENSE("GPL v2");
软中断和 tasklet 的关系:
由于软中断必须使用可重入函数,这就导致设计上的复杂度变高,临界区必须用自旋锁保护,因为同一个软中断服务函数可以在几个 CPU 上同时运行。作为设备驱动程序的开发者来说,增加了负担。而如果某种应用并不需要在多个CPU上并行执行,那么软中断其实是没有必要的。tasklet具有以下特性:
- 一种特定类型的tasklet只能运行在一个CPU上,不能并行,只能串行执行。
- 多个不同类型的tasklet可以并行在多个CPU上。
- 从软中断的实现机制可知,内核也没有提供通用的增加软中断的接口,软中断是静态分配的,在内核编译好之后,就不能改变。但tasklet就灵活许多,可以在运行时改变(比如添加模块时)。
- 软中断的pending标志位只有32位,tasklet使用链表管理,没有数量限制。
- 为了cache优化,每个tasklet只会在调度它的CPU上运行,即哪个CPU执行tasklet_schedule,哪个CPU就处理tasklet。
tasklet是在两种软中断类型的基础上实现的,如果不需要软中断的并行特性,tasklet就是最好的选择。也就是说tasklet是软中断的一种特殊用法,即延迟情况下的串行执行。
内核源码分析
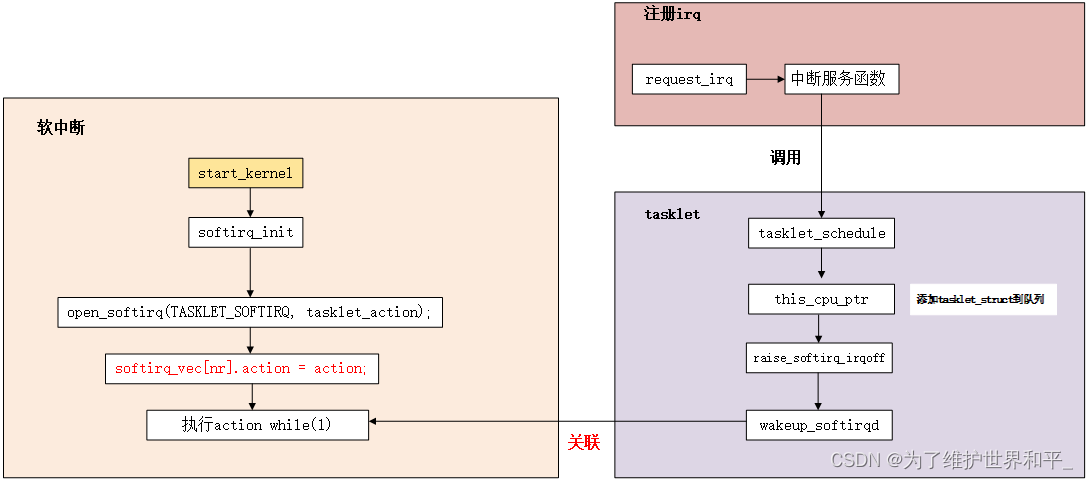
TASKLET_SOFTIRQ软中断初始化
void __init softirq_init(void) { int cpu; for_each_possible_cpu(cpu) { per_cpu(tasklet_vec, cpu).tail = &per_cpu(tasklet_vec, cpu).head; per_cpu(tasklet_hi_vec, cpu).tail = &per_cpu(tasklet_hi_vec, cpu).head; } open_softirq(TASKLET_SOFTIRQ, tasklet_action); open_softirq(HI_SOFTIRQ, tasklet_hi_action); }
- 初始化 tasklet 的链表
- 为 TASKLET_SOFTIRQ 软中断与 tasklet_action() 建立关联的关系,因此软中断触发时,就会调用 tasklet_action()。
tasklet_struct 实例添加到链表,触发执行 tasklet 实例处理函数
通过将 struct tasklet_struct 实例添加到链表,执行实例对应的函数
struct tasklet_struct { struct tasklet_struct *next; unsigned long state; atomic_t count; bool use_callback; union { void (*func)(unsigned long data); void (*callback)(struct tasklet_struct *t); }; unsigned long data; };
- next: 指向下一个tasklet的指针
- state: 定义了这个tasklet的当前状态。这一个32位的无符号长整数,当前只使用了bit[TASKLET_STATE_RUN]和bit[TASKLET_STATE_SCHED]两个状态位。其中,bit[TASKLET_STATE_RUN]=1表示这个tasklet当前正在某个CPU上被执行,它仅对SMP系统才有意义,其作用就是为了防止多个CPU同时执行一个tasklet的情形出现;bit[TASKLET_STATE_SCHED]=1表示这个tasklet已经被调度(使用)等待被执行了。
- count: 只有当count等于0时,tasklet代码段才能执行;如果count非零,则这个tasklet是被禁止的
- func: 该 tasklet 对应的函数
- data: func 的入参
当调用 tasklet_schedule() 时,如果该 tasklet 实例没有被设置 TASKLET_STATE_SCHED 标记时,才会加入链表内,如果已经设置了 TASKLET_STATE_SCHED 了,那么就会忽略此次的 tasklet _schedule()。添加到链表后会通过 raise_softirq_irqoff() 触发执行 TASKLET_SOFTIRQ 软中断。
static inline void tasklet_schedule(struct tasklet_struct *t) { if (!test_and_set_bit(TASKLET_STATE_SCHED, &t->state)) __tasklet_schedule(t); } void __tasklet_schedule(struct tasklet_struct *t) { __tasklet_schedule_common(t, &tasklet_vec, TASKLET_SOFTIRQ); } static void __tasklet_schedule_common(struct tasklet_struct *t, struct tasklet_head __percpu *headp, unsigned int softirq_nr) { struct tasklet_head *head; unsigned long flags; local_irq_save(flags); head = this_cpu_ptr(headp); // 当前CPU的链表头 t->next = NULL; *head->tail = t; head->tail = &(t->next); raise_softirq_irqoff(softirq_nr); local_irq_restore(flags); }
tasklet_schedule 的 if 判断分支保证,tasklet 被添加到某个 cpu 的链表后,未调度 tasklet 对应的函数前不会再被添加到某个 cpu 的链表
执行 __tasklet_schedule_common,tasklet 只会加入到当前 cpu 的 tasklet 链表内,添加到链表的过程如下:
struct tasklet_head { struct tasklet_struct *head; struct tasklet_struct **tail; };

添加完链表,就执行该软中断类型对应的中断服务函数
static __latent_entropy void tasklet_action(struct softirq_action *a) { tasklet_action_common(a, this_cpu_ptr(&tasklet_vec), TASKLET_SOFTIRQ); } static void tasklet_action_common(struct softirq_action *a, struct tasklet_head *tl_head, unsigned int softirq_nr) { struct tasklet_struct *list; local_irq_disable(); list = tl_head->head; // 获取 tasklet 链表,后面一个一个处理 tl_head->head = NULL; // 清空 tasklet 链表,即 tasklet_vec 链表 tl_head->tail = &tl_head->head; local_irq_enable(); while (list) { struct tasklet_struct *t = list; list = list->next;
// TASKLET_STATE_SCHED: 表示该 tasklet 已经被挂接到某个 CPU 上
// TASKLET_STATE_RUN: 表示该 tasklet 正在某个 CPU 上执行
if (tasklet_trylock(t)) { // 原子操作,检查并设置 TASKLET_STATE_RUN 标记,返回1:表示 tasklet 没有被执行,返回0:表明 tasklet 已经被执行 if (!atomic_read(&t->count)) { // 如果当前 tasklet 没有被 tasklet_disable() if (tasklet_clear_sched(t)) { // 清除 TASKLET_STATE_SCHED 状态,便于该 tasklet 可以再次被添加到某个 cpu 的链表中
// 这期间,该 tasklet 可以被 tasklet_schedule()并添加到某个 cpu 的链表中,但由于该 tasklet 的 TASKLET_STATE_RUN 还是1
// 无法被执行,从而引出下面第二种情况 if (t->use_callback) t->callback(t); else t->func(t->data); // 执行 tasklet 函数 } tasklet_unlock(t); // 执行完一个tasklet,清理 TASKLET_STATE_RUN 标记 continue; // 继续下一个 tasklet } tasklet_unlock(t);// 如果 tasklet 被 disable 了,清除 TASKLET_STATE_RUN 标记 }
// 有两种情况下,会执行下面代码,将该 tasklet 再挂接回链表内,并重新触发,等待下一次执行的机会
// 1. 如果没有被执行,但是被调用 tasklet_disable() 接口 disable 了
// 2. 当前 tasklet 正在某 CPU 执行,这时候 tasklet 又被挂到其他 cpu 的链表中并执行到上面的 "if(tasklet_trylock(t))" 语句,
// 但是该 tasklet 还没处理完,它的 TASKLET_STATE_RUN 还是1,if语句进不去,只能
// 再次挂入链表等待下次执行,满足了同一个 tasklet 只能在一个 CPU 执行的设计原则
local_irq_disable(); t->next = NULL; *tl_head->tail = t; tl_head->tail = &t->next; __raise_softirq_irqoff(softirq_nr); local_irq_enable(); } }
tasklet_kill() 等待已经调度的 tasklet 执行完,并且让在执行期间又调度这个tasklet不再执行(有待整理)
void tasklet_kill(struct tasklet_struct *t) { if (in_interrupt()) pr_notice("Attempt to kill tasklet from interrupt\n"); while (test_and_set_bit(TASKLET_STATE_SCHED, &t->state)) // 设置 SCHED 的值为1,并返回 SCHED 的原值 wait_var_event(&t->state, !test_bit(TASKLET_STATE_SCHED, &t->state)); //之前已经调度了,就等待 SCHED 清零(RUN值1后才会清零) tasklet_unlock_wait(t); // 等待执行完成 tasklet_clear_sched(t); // 清除 SCHED 标志 } void tasklet_unlock_wait(struct tasklet_struct *t) { wait_var_event(&t->state, !test_bit(TASKLET_STATE_RUN, &t->state)); }
tasklet 机制总结
1. 每颗 cpu 都有自己的 tasklet 链表,这样可以将 tasklet 分布在各个 cpu 上,可实现并发不同的 tasklet。
2. 相同的 tasklet 实例只能在某一颗 cpu 上串行执行,其它 cpu 会暂时无法添加到自己的链表,在此情况下,不需要考虑并发问题(即不需要加锁)。
3. 如果 tasklet 已经被调度(加入待执行链表),指定的 tasklet 不会再次被加入链表内,即该请求不会被受理。
4. tasklet_disable() 接口只是不执行指定的 tasklet,依旧可以通过 tasklet_schedule() 添加到待执行链表内,等 enable 了就可以被执行。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· 写一个简单的SQL生成工具
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
2021-04-30 编译器 ------ MinGW-w64
2021-04-30 POSIX库、glibc库、pthreads库、libc库、newlib、uClibc
2020-04-30 STM32 ------ 处理 int64 类型数据需要注意