

MPU 与 cache CPU内存的使用和注意
CPU内存分类
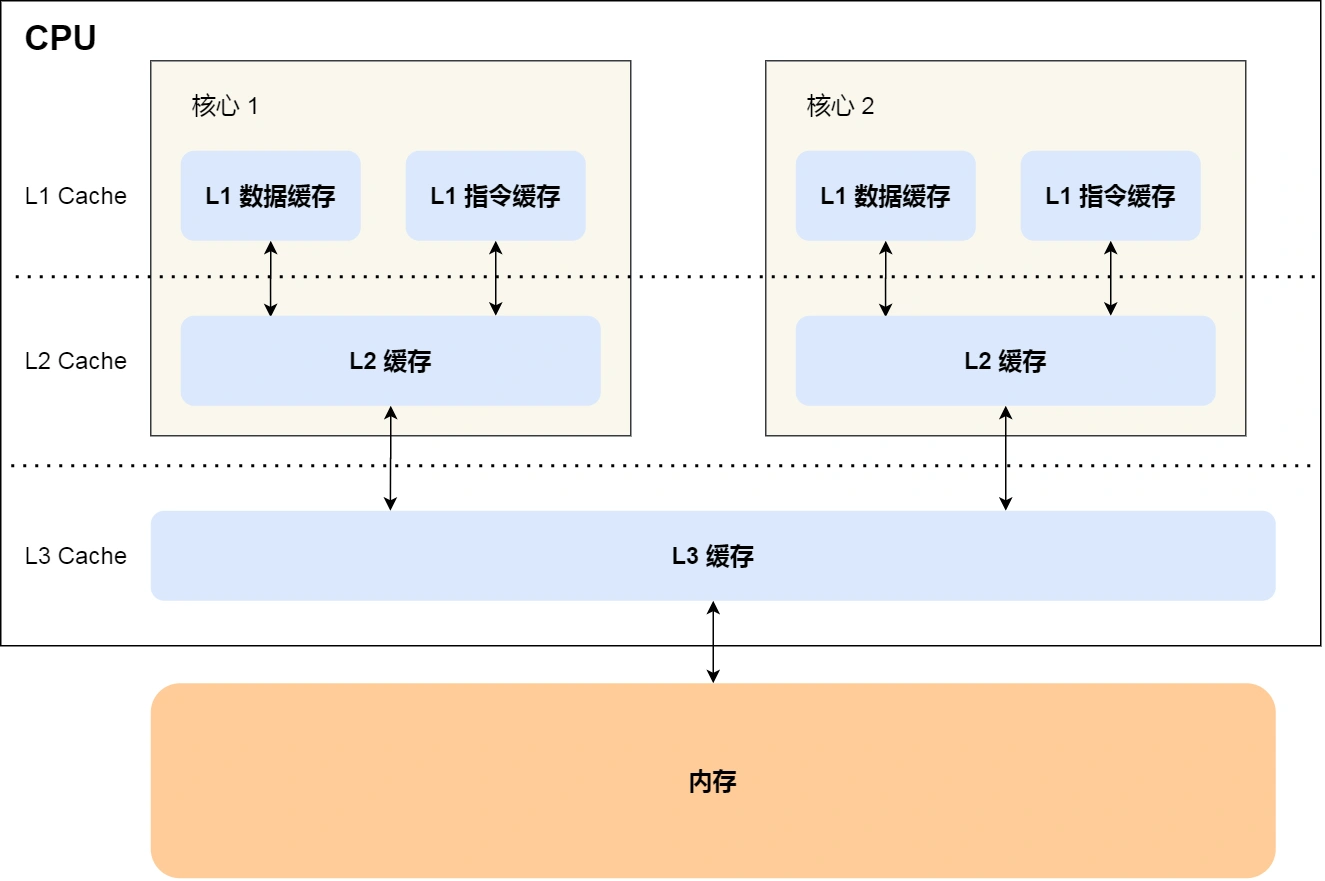
多核CPU内存分布,L1、L2是核独享的内存,L3、外部内存是所有核共享
为什么区分指令缓存和数据缓存
程序指令和程序数据的行为和热点分布差异很大(icache比dcache少了dirty标志),因此L1 Cache也被划分成L1i (i for instruction)和L1d (d for data)两种专门用途的缓存
cache能起作用的原理
对大量典型程序运行情况的分析结果表明,在一个较短的时间间隔内,由程序产生的地址往往集中在存储器逻辑地址空间的很小范围内。指令地址的分布本来就是连续的,再加上循环程序段和子程序段要重复执行多次。因此,对这些地址的访问就自然地具有时间上集中分布的倾向。
数据分布的这种集中倾向不如指令明显,但对数组的存储和访问以及工作单元的选择都可以使存储器地址相对集中。这种对局部范围的存储器地址频繁访问,而对此范围以外的地址则访问甚少的现象,就称为程序访问的局部性。
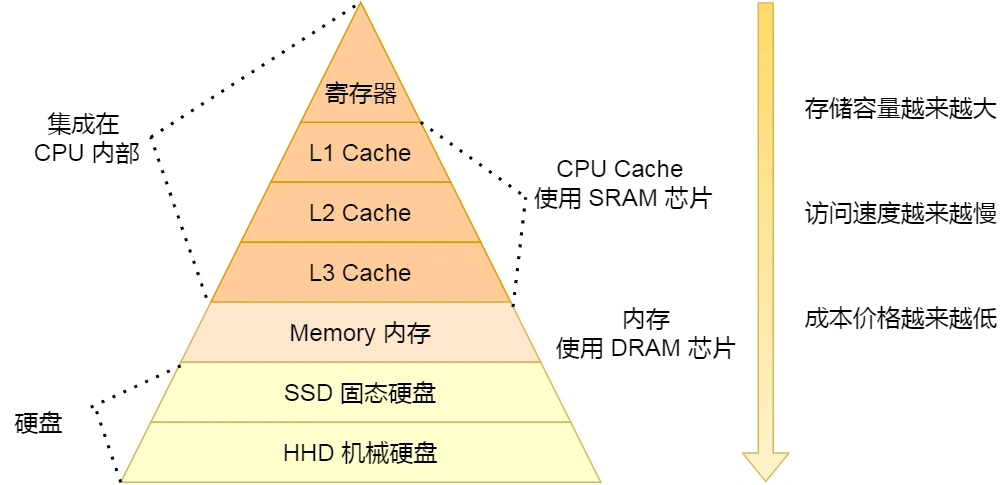
根据程序的局部性原理,可以在主存和CPU通用寄存器之间设置一个高速的容量相对较小的存储器,把正在执行的指令地址附近的一部分指令或数据从主存调入这 个存储器,供CPU在一段时间内使用。这对提高程序的运行速度有很大的作用。这个介于主存和CPU之间的高速小容量存储器称作高速缓冲存储器 (Cache)。
系统正是依据此原理,不断地将与当前指令集相关联的一个不太大的后继指令集从内存读到Cache,然后再与CPU高速传送,从而达到速度匹配。
CPU对存储器进行数据请求时,通常先访问Cache。由于局部性原理不能保证所请求的数据百分之百地在Cache中,这里便存在一个命中率。即CPU在任一时刻从Cache中可靠获取数据的几率。命中率越高,正确获取数据的可靠性就越大。一般来说,Cache的存储容量比主存的容量小得多,但不能太小,太小会使命中率太低;也没有必要过大,过大不仅会增加成本,而且当容量超过一定值后,命中率随容量的增加将不会有明显地增长。
只要Cache的空间与主存空间在一定范围内保持适当比例的映射关系,Cache的命中率还是相当高的。
cache命中率
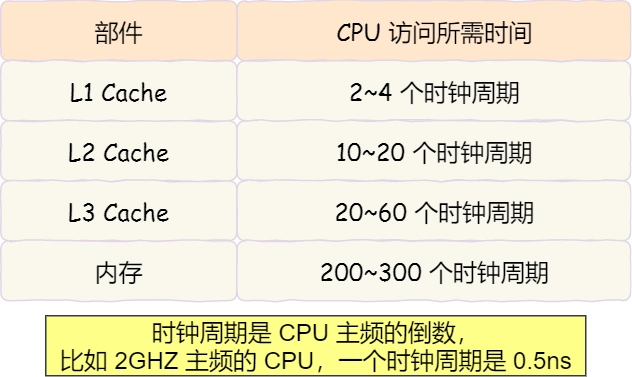
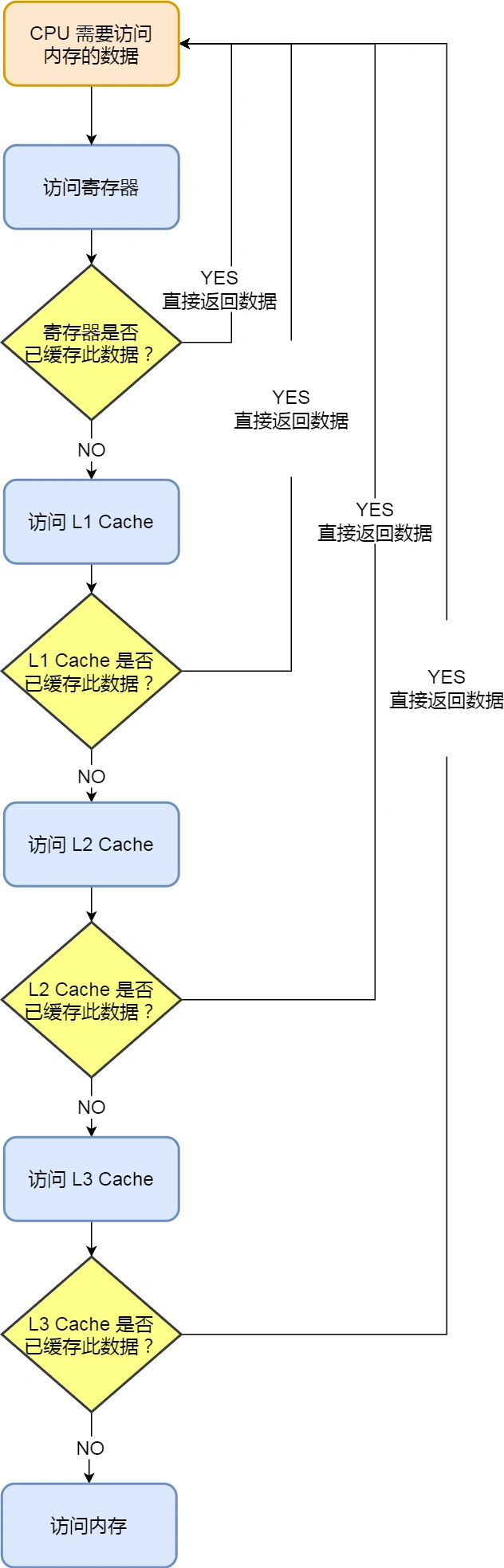
当 CPU 需要访问内存中某个数据的时候,如果寄存器有这个数据,CPU 就直接从寄存器取数据即可,如果寄存器没有这个数据,CPU 就会查询 L1 高速缓存,如果 L1 没有,则查询 L2 高速缓存,L2 还是没有的话就查询 L3 高速缓存,L3 依然没有的话,才去内存中取数据。CPU 从内存中读取数据到 Cache 的时候,并不是一个字节一个字节读取,而是一块一块的方式来读取数据的,这一块一块的数据被称为 CPU Cache Line(缓存块),所以 CPU Cache Line 是 CPU 从内存读取数据到 Cache 的单位。
要想写出让 CPU 跑得更快的代码,就需要写出缓存命中率高的代码,CPU L1 Cache 分为数据缓存和指令缓存,因而需要分别提高它们的缓存命中率:
- 对于数据缓存,我们在遍历数据的时候,应该按照内存布局的顺序操作,这是因为 CPU Cache 是根据 CPU Cache Line 批量操作数据的,所以顺序地操作连续内存数据时,性能能得到有效的提升;
- 对于指令缓存,有规律的条件分支语句能够让 CPU 的分支预测器发挥作用,进一步提高执行的效率;
另外,对于多核 CPU 系统,线程可能在不同 CPU 核心来回切换,这样各个核心的缓存命中率就会受到影响,于是要想提高线程的缓存命中率,可以考虑把线程绑定 CPU 到某一个 CPU 核心。
cache一致性
我们当然期望 CPU 读取数据的时候,都是尽可能地从 CPU Cache 中读取,而不是每一次都要从内存中获取数据。所以,身为程序员,我们要尽可能写出缓存命中率高的代码,这样就有效提高程序的性能。
事实上,数据不光是只有读操作,还有写操作,那么如果数据写入 Cache 之后,内存与 Cache 相对应的数据将会不同,这种情况下 Cache 和内存数据都不一致了,于是我们肯定是要把 Cache 中的数据同步到内存里的。
问题来了,那在什么时机才把 Cache 中的数据写回到内存呢?为了应对这个问题,下面介绍两种针对写入数据的方法:
- 写直达(Write Through),只要有数据写入,都会直接把数据写入到内存里面,这种方式简单直观,但是性能就会受限于内存的访问速度;
- 写回(Write Back),对于已经缓存在 Cache 的数据的写入,只需要更新其数据就可以,不用写入到内存,只有在需要把缓存里面的脏数据交换出去的时候,才把数据同步到内存里,这种方式在缓存命中率高的情况,性能会更好;
当今 CPU 都是多核的,每个核心都有各自独立的 L1/L2 Cache,只有 L3 Cache 是多个核心之间共享的。所以,我们要确保多核缓存是一致性的,否则会出现错误的结果。
要想实现缓存一致性,关键是要满足 2 点:
- 第一点是写传播,也就是当某个 CPU 核心发生写入操作时,需要把该事件广播通知给其他核心;
- 第二点是事物的串行化,这个很重要,只有保证了这个,才能保障我们的数据是真正一致的,我们的程序在各个不同的核心上运行的结果也是一致的;
基于总线嗅探机制的 MESI 协议,就满足上面了这两点,因此它是保障缓存一致性的协议。
MESI 协议,是已修改、独占、共享、已失效这四个状态的英文缩写的组合。整个 MESI 状态的变更,则是根据来自本地 CPU 核心的请求,或者来自其他 CPU 核心通过总线传输过来的请求,从而构成一个流动的状态机。另外,对于在「已修改」或者「独占」状态的 Cache Line,修改更新其数据不需要发送广播给其他 CPU 核心。
伪共享
所谓的 Cache Line 伪共享问题就是,多个线程同时读写同一个 Cache Line 的不同变量时,而导致 CPU Cache 失效的现象。那么对于多个线程共享的热点数据,即经常会修改的数据,应该避免这些数据刚好在同一个 Cache Line 中,避免的方式一般有 Cache Line 大小字节对齐,以及字节填充等方法。
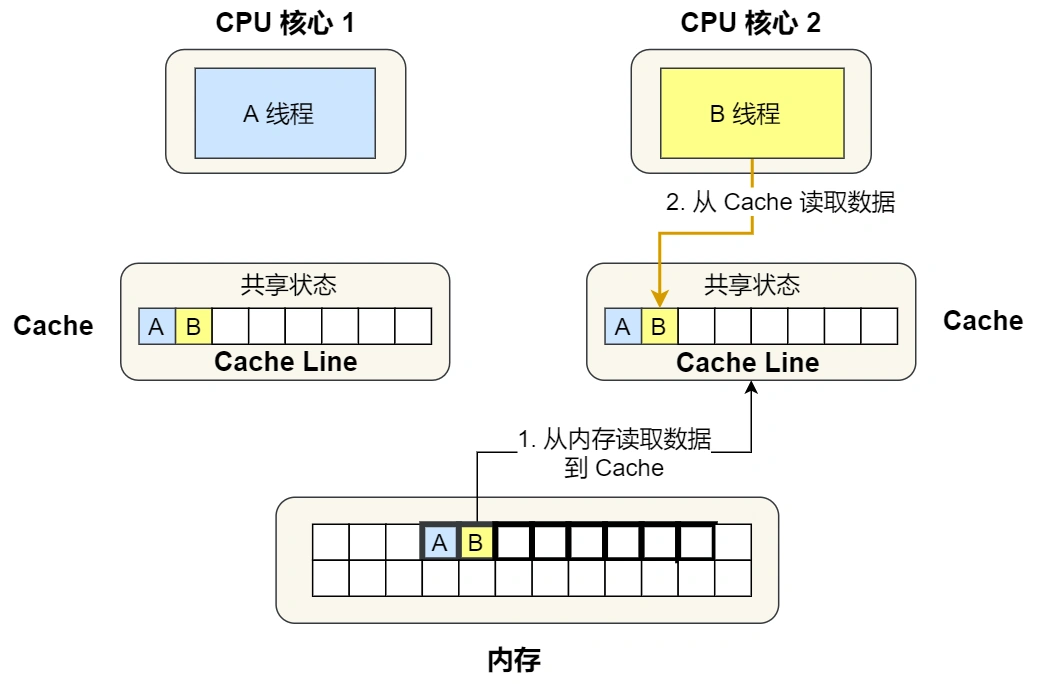
①. 最开始变量 A 和 B 都还不在 Cache 里面,假设 1 号核心绑定了线程 A,2 号核心绑定了线程 B,线程 A 只会读写变量 A,线程 B 只会读写变量 B。

②. 1 号核心读取变量 A,由于 CPU 从内存读取数据到 Cache 的单位是 Cache Line,也正好变量 A 和 变量 B 的数据归属于同一个 Cache Line,所以 A 和 B 的数据都会被加载到 Cache,并将此 Cache Line 标记为「独占」状态。

③. 接着,2 号核心开始从内存里读取变量 B,同样的也是读取 Cache Line 大小的数据到 Cache 中,此 Cache Line 中的数据也包含了变量 A 和 变量 B,此时 1 号和 2 号核心的 Cache Line 状态变为「共享」状态。
④. 1 号核心需要修改变量 A,发现此 Cache Line 的状态是「共享」状态,所以先需要通过总线发送消息给 2 号核心,通知 2 号核心把 Cache 中对应的 Cache Line 标记为「已失效」状态,然后 1 号核心对应的 Cache Line 状态变成「已修改」状态,并且修改变量 A。

⑤. 之后,2 号核心需要修改变量 B,此时 2 号核心的 Cache 中对应的 Cache Line 是已失效状态,另外由于 1 号核心的 Cache 也有此相同的数据,且状态为「已修改」状态,所以要先把 1 号核心的 Cache 对应的 Cache Line 写回到内存,然后 2 号核心再从内存读取 Cache Line 大小的数据到 Cache 中,最后把变量 B 修改到 2 号核心的 Cache 中,并将状态标记为「已修改」状态。
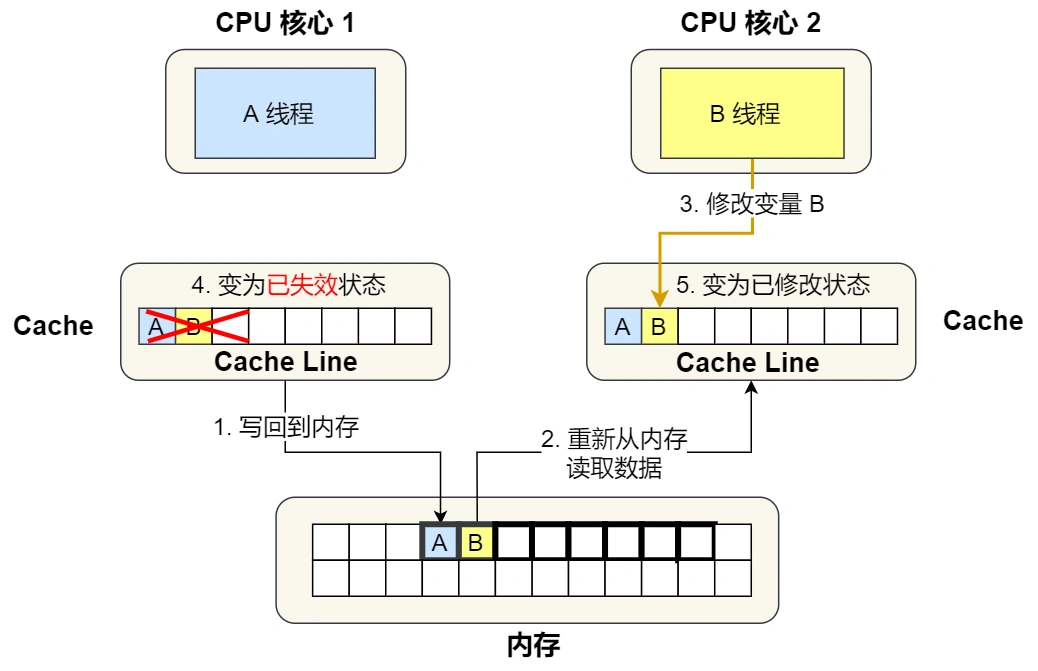
所以,可以发现如果 1 号和 2 号 CPU 核心这样持续交替的分别修改变量 A 和 B,就会重复 ④ 和 ⑤ 这两个步骤,Cache 并没有起到缓存的效果,虽然变量 A 和 B 之间其实并没有任何的关系,但是因为同时归属于一个 Cache Line ,这个 Cache Line 中的任意数据被修改后,都会相互影响,从而出现 ④ 和 ⑤ 这两个步骤。
因此,这种因为多个线程同时读写同一个 Cache Line 的不同变量时,而导致 CPU Cache 失效的现象称为伪共享(False Sharing)。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix