一:视图层
Django视图层,视图就是Django项目下的views.py文件,她的内部是一系列的函数或者是类,用来专门处理客户端访问请求后处理请求并且返回相应的数据,相当于一个中央情报处理系统。
2.三板斧(HttpResponse对象)
"""
HttpResponse
返回字符串类型
render
返回html页面 并且在返回给浏览器之前还可以给html文件传值
redirect
重定向
"""
4.HttpResponse()
httpresponse() 括号内直接跟一个具体的字符串作为响应体,比较直接简单,所有这里主要介绍后面两种形式。
5.render()
render(request, template_name[, context])结合一个给定的模板和一个给定的上下文字典,并返回一个渲染后的 HttpResponse 对象。
# 参数:
request: 用于生成响应的请求对象。
template_name:要使用的模板的完整名称,可选的参数
context:添加到模板上下文的一个字典。默认是一个空字典。如果字典中的某个值是可调用的,视图将在渲染模板之前调用它。
render方法就是将一个模板页面中的模板语法进行渲染,最终渲染成一个html页面作为响应体。
6.redirect()
def my_view(request):
rerurn redirect('/some/url/')
7.也可以是一个完整的URL
def my_view(request):
...
return redirect('http://www.baidu.com/')
1)301和302的区别。
301和302状态码都表示重定向,就是说浏览器在拿到服务器返回的这个状态码后会自动跳转到
一个新的URL地址,这个地址可以从响应的Location首部中获取
(用户看到的效果就是他输入的地址A瞬间变成了另一个地址B)——这是它们的共同点。
他们的不同在于。301表示旧地址A的资源已经被永久地移除了(这个资源不可访问了),
搜索引擎在抓取新内容的同时也将旧的网址交换为重定向之后的网址;
302表示旧地址A的资源还在(仍然可以访问),这个重定向只是临时地从旧地址A跳转到地址B,
搜索引擎会抓取新的内容而保存旧的网址。 SEO302好于301
2)重定向原因:
(1)网站调整(如改变网页目录结构);
(2)网页被移到一个新地址;
(3)网页扩展名改变(如应用需要把.php改成.Html或.shtml)。
这种情况下,如果不做重定向,则用户收藏夹或搜索引擎数据库中旧地址只能让
访问客户得到一个404页面错误信息,访问流量白白丧失;再者某些注册了多个域名的
网站,也需要通过重定向让访问这些域名的用户自动跳转到主站点等。
二:三板斧本质
1.Django图层函数必须要返回一个HttpResponse对象
Django视图层函数必须要返回一个HttpResponse对象! 正确!
django视图层函数必须有一个返回值,并且返回值的数据类型必须是HttpResponse对象
2.研究三者的源码即可得处结论
# HttpResponse
class HttpResponse(HttpResponseBase):
"""
An HTTP response class with a string as content.
# 以字符串作为内容的HTTP响应类
This content that can be read, appended to or replaced.
# 可以读取、添加或替换的内容
"""
streaming = False
def __init__(self, content=b'', *args, **kwargs):
super(HttpResponse, self).__init__(*args, **kwargs)
# 内容是一个字符串 参见'content'属性方法
# Content is a bytestring. See the `content` property methods.
self.content = content
# render简单内部原理
from django.template import Template,Context
res = Template('<h1>{{ user }}</h1>')
con = Context({'user':{'username':'jason','password':123}})
ret = res.render(con)
print(ret)
return HttpResponse(ret)
# redirect
class HttpResponseRedirectBase(HttpResponse):
eg: redirect内部是继承了HttpRespone类
三:JsonResponse对象
1.json格式的数据有什么用?
前后端数据交互需要使用到json作为序列化,实现跨语言数据传输。
1. 混合开发项目:前端页面和后端代码写到一块
2. 前后端分离项目:前端是一个项目,后端是一个项目,后端只需要写接口
前端js序列化 后端序列化
JSON.stringify() json.dumps()
JSON.parse() json.loads()
2.给前端浏览器返回一个json格式的字符串
3.json序列化
# 导入模块
import json
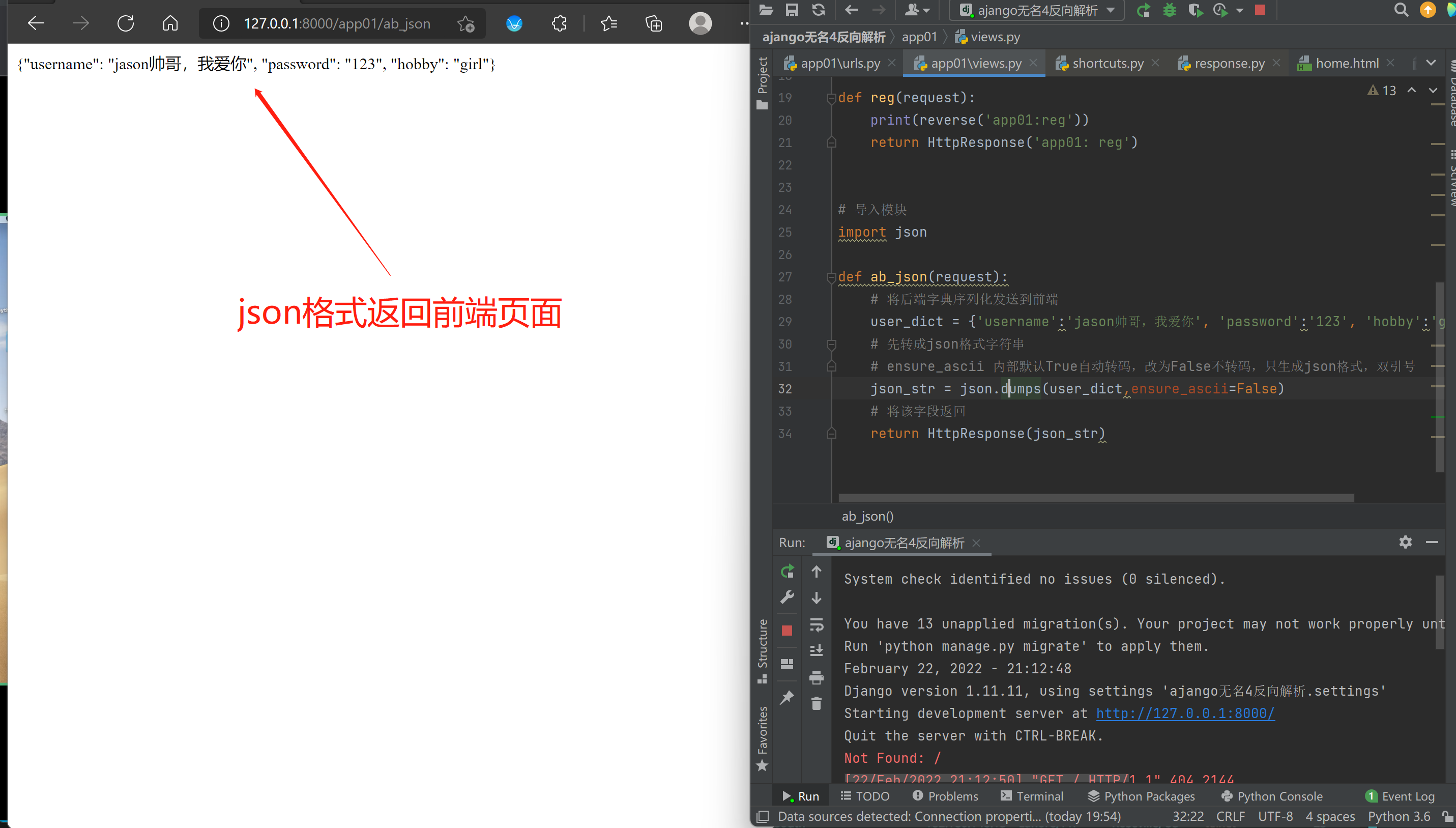
def ab_json(request):
# 将后端字典序列化发送到前端
user_dict = {'username':'jason帅哥,我爱你', 'password':'123', 'hobby':'girl'}
# 先转成json格式字符串
# ensure_ascii 内部默认True自动转码,改为False不转码,只生成json格式,双引号
json_str = json.dumps(user_dict,ensure_ascii=False)
# 将该字段返回
return HttpResponse(json_str)
ensure_ascii 内部默认True自动转码,改为False不转码,只生成json格式,双引号
4.JsonResponse序列化
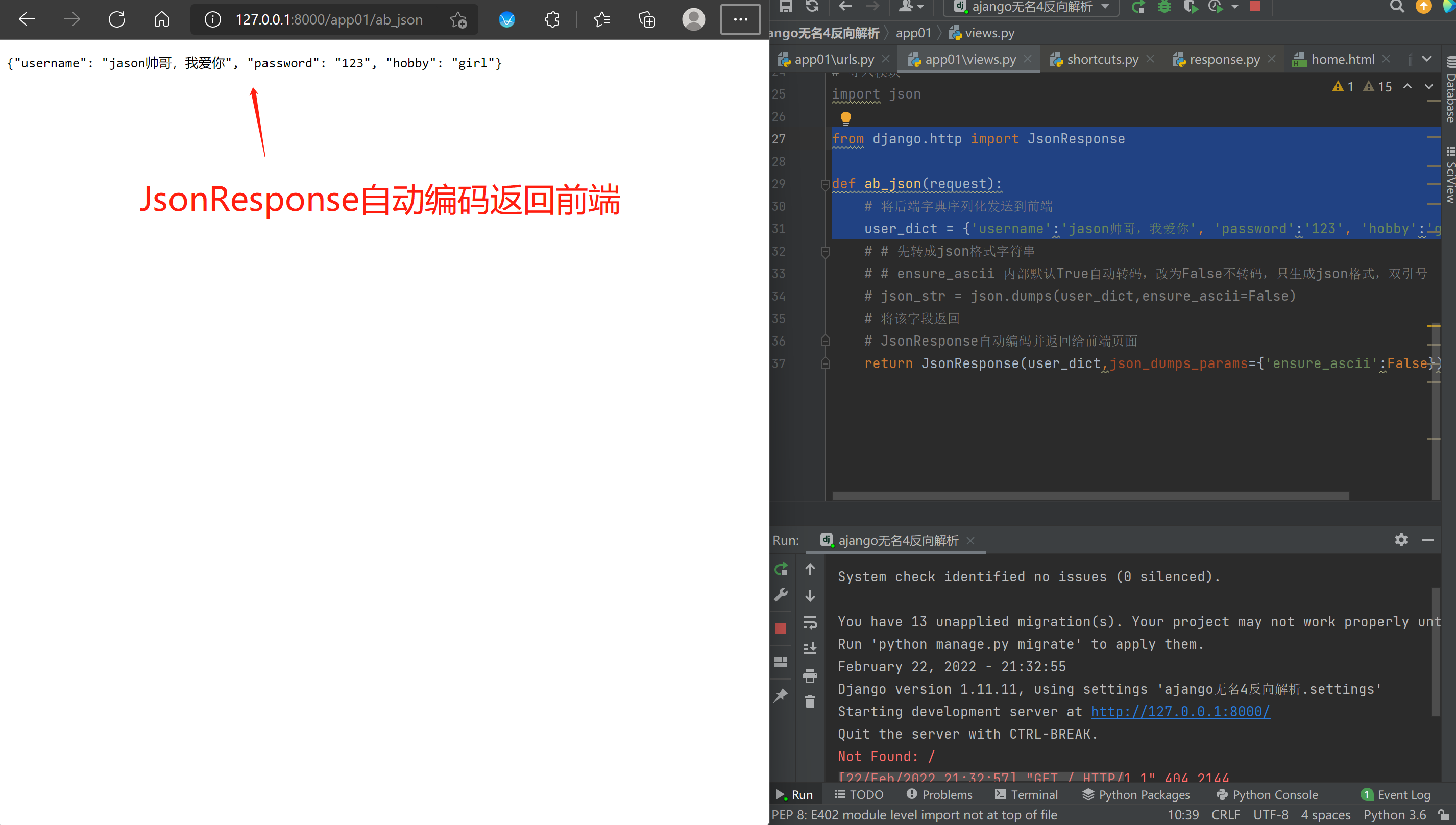
# 导入JsonResponse模块
from django.http import JsonResponse
def ab_json(request):
# 将后端字典序列化发送到前端
user_dict = {'username':'jason帅哥,我爱你', 'password':'123', 'hobby':'girl'}
# JsonResponse自动编码并返回给前端页面
return JsonResponse(user_dict,json_dumps_params={'ensure_ascii':False})
user_dict,json_dumps_params={'ensure_ascii':False} :解决前端汉字转码问题
5.JsonResponse序列化(列表注意事项)
# 导入JsonResponse模块
from django.http import JsonResponse
def ab_json(request):
l = [111,222,333,444,555]
# 默认只能序列化字典 序列化其他需要加safe参数 safe=False
return JsonResponse(l,safe=False)
6.json与pickle区别
import json
'''支持的数据类型:str,list, tuple, dict, set'''
# 序列化出来的数据是可以看得懂的,就是一个字符串
dumps
loads
dump
load
import pickle
'''支持的数据类型:python中的所有数据类型'''
# 序列化出来的结果看不懂,因为结果是一个二进制
# pickle序列化出的来的数据只能在python中使用
dumps
loads
dump
load
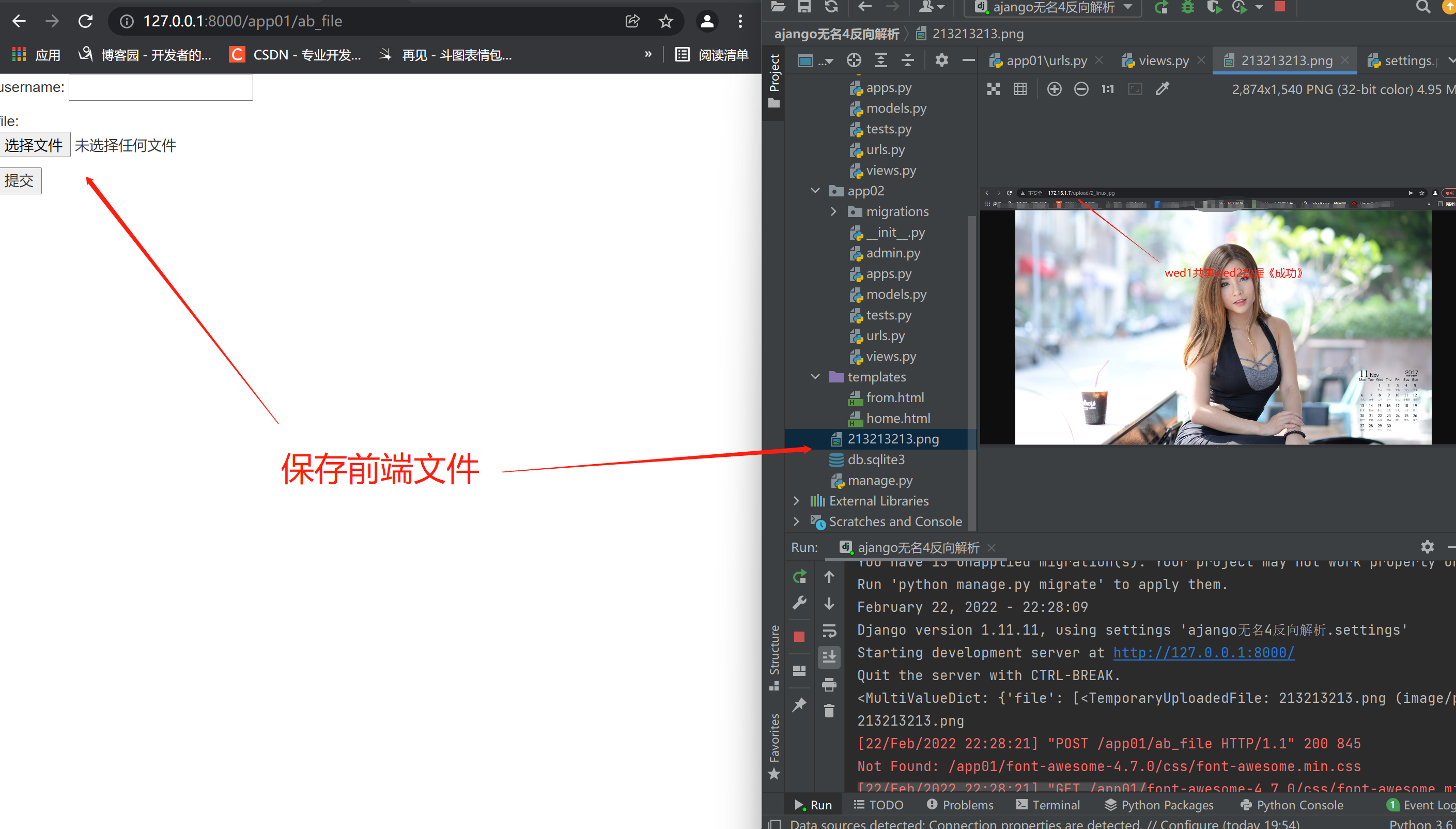
1.上传文件注意事项
form表单上传文件类型的数据
1.method必须指定成post
2.enctype='multipart/form-data'
后端:
在request.FILES中接收文件数据,其他数据一律按照请求方式接收
# views.py文件
def ab_file(request):
# 判断前端请求
if request.method == 'POST':
# 获取POST请求信息
# print(request.POST) # 只能获取普通的键值对数据 文件不行 <QueryDict: {'username': ['json']}>
print(request.FILES) # 获取文件数据
# < MultiValueDict: {'username': [ < InMemoryUploadedFile: 双层语法糖2.png(image / png) >]} >
file_obj = request.FILES.get('file') # (拿到最后一个元素) 文件对象
print(file_obj.name) # 拿到文件名字
# 将文件存起来 先打开文件
with open(file_obj.name, 'wb') as f:
# for循环 一行一行的读取文件内容
for line in file_obj.chunks(): # 推荐加上chunks方法 其实跟不加是一样的都是一行行的读取
# 将文件保存
f.write(line)
# get请求返回
return render(request, 'from.html')
# from.py文件
{# 1.method必须指定成post 2.enctype必须换成formdat #}
<form action="" method="post" enctype="multipart/form-data">
<p>username: <input type="text" name="username"></p>
<p>file: <input type="file" name="file"></p>
<input type="submit">
</form>
五:request对象方法
1.获取请求方式POST/GET
request.method
一个字符串,表示请求使用的HTTP 方法。必须使用大写。
2.request.POST
获取POST请求提交普通的键值对数据 一个类似于字典的对象,如果请求中包含表单数据,则将这些数据封装成
3.获取GET请求
request.GET
获取GET请求 一个类似于字典的对象,包含 HTTP GET 的所有参数
4.获取文件
request.FILES
一个类似于字典的对象,包含所有的上传文件信息。
FILES 中的每个键为<input type="file" name="" /> 中的name,值则为对应的数据。
注意,FILES 只有在请求的方法为POST 且提交的<form> 带有enctype="multipart/form-data" 的情况下才会包含数据。否则,FILES 将为一个空的类似于字典的对象。
5.原生的浏览器发过来的二进制数据
request.body
一个字符串,代表请求报文的主体。在处理非 HTTP 形式的报文时非常有用,
例如:二进制图片、XML,Json等。
6.拿到路由
request.path
个字符串,表示请求的路径组件(不含域名)
7.拿到路由
request.path_info
8.能过获取完整的url及问号后面的参数
request.get_full_path()

案列演示:
print(request.path) # /app01/ab_file/
print(request.path_info) # /app01/ab_file/
print(request.get_full_path()) # /app01/ab_file/?username=jason
六:FBV与CBV
1.FBV与CBV区别?
FBV基于函数的视图(Function base view) 我们前面写的视图函数都是FBV
CBV基于类的视图(Class base view)
视图文件种除了用一系列的函数来对应处理客户端请求的数据逻辑外,还可以通过定义类来处理相应的逻辑。
# 视图函数既可以是函数也可以是类
def index(request):
return HttpResponse('index')
2.CBV实际应用
# CBV路由
url(r'^login/', views.MyLogin.as_view()) # 加as_view参数
# 导入CBV模块
from django.views import View
# 继承模块
class MyLogin(View):
# 前端发起get请求走get函数
def get(self, request):
return render(request, 'from.html')
# 前端发起post请求走该post函数
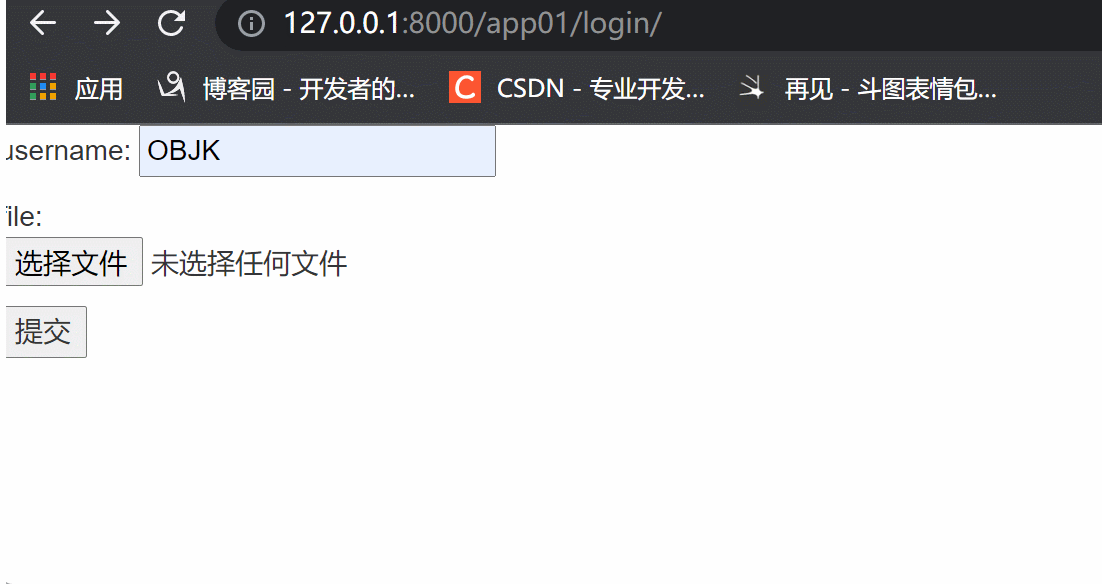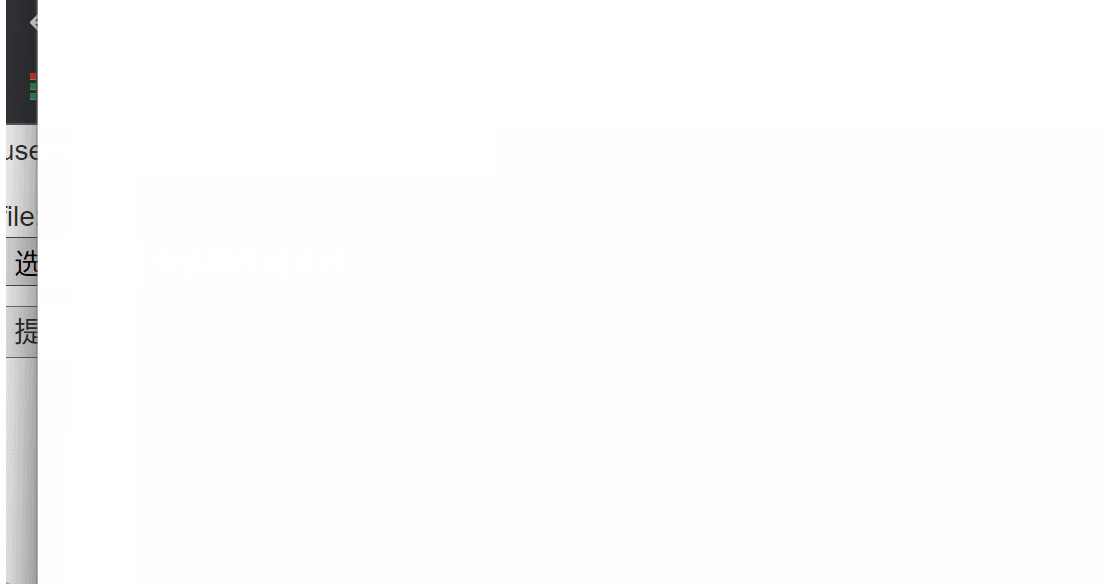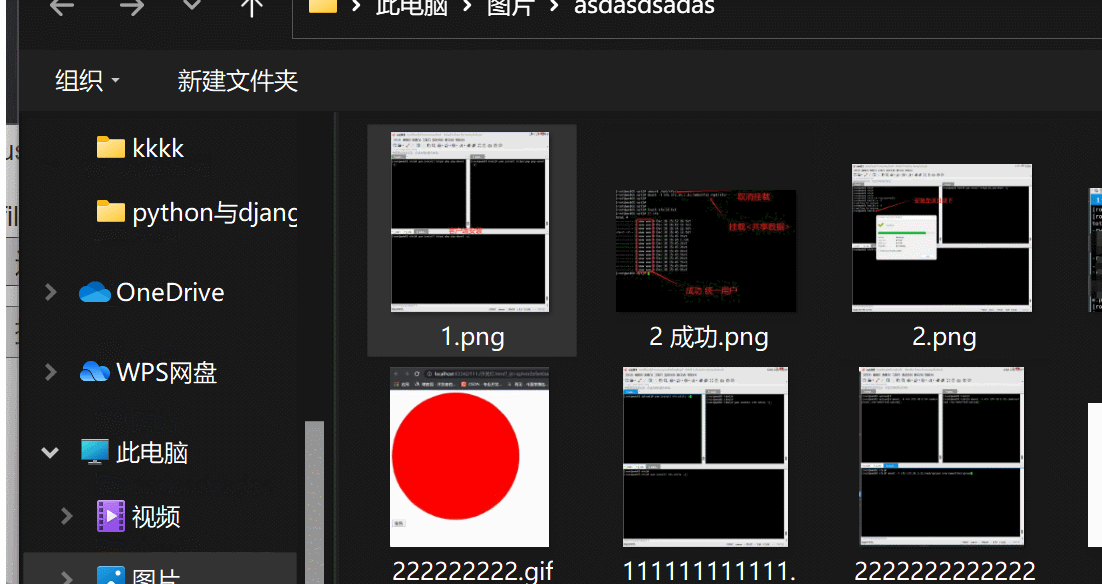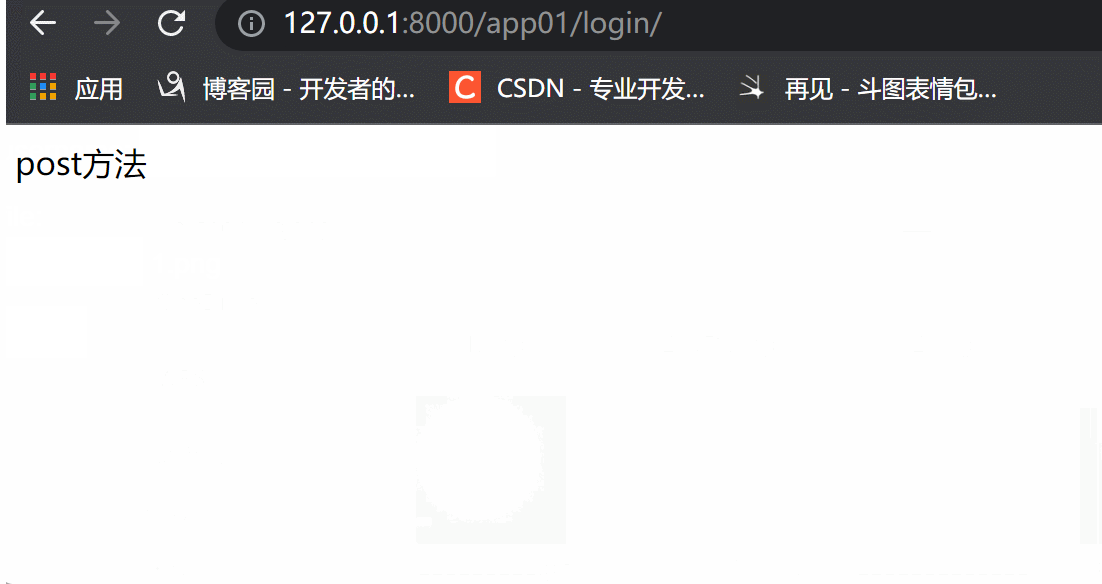
def post(self,request):
return HttpResponse('post方法')
FBV和CBV各有千秋
CBV特点
能够直接根据请求方式的不同直接匹配到对应的方法执行
七:CBV的源码剖析
1.CBV本质上跟FBV是一样的
urlpatterns = {
url(r'^login/', views.MyLogin.as_view())
# CBV于FBV在路由匹配上本质是一样的 都是路由 对应 函数内存地址
# url(r'^login/', views.view) # CBV与FBV本质一模一样
}
2.突破口:
知识点: 函数名/方法名: 加括号执行优先级最高
CBV写的是as_view(), 加括号意味着在项目启动的时候就会执行,那么猜测
要么是被@staicmethod修饰的静态方法,就是个普通函数没有形参
要么是被@classmethod修饰的类方法,类来调用自动将类传入当做第一个参数传入
3.CBV源码as_view解析(分步执行流程 全面扩展)
urlpatterns = [
# MyLogin类 点 方法
url(r'^login/', views.MyLogin.as_view())
]
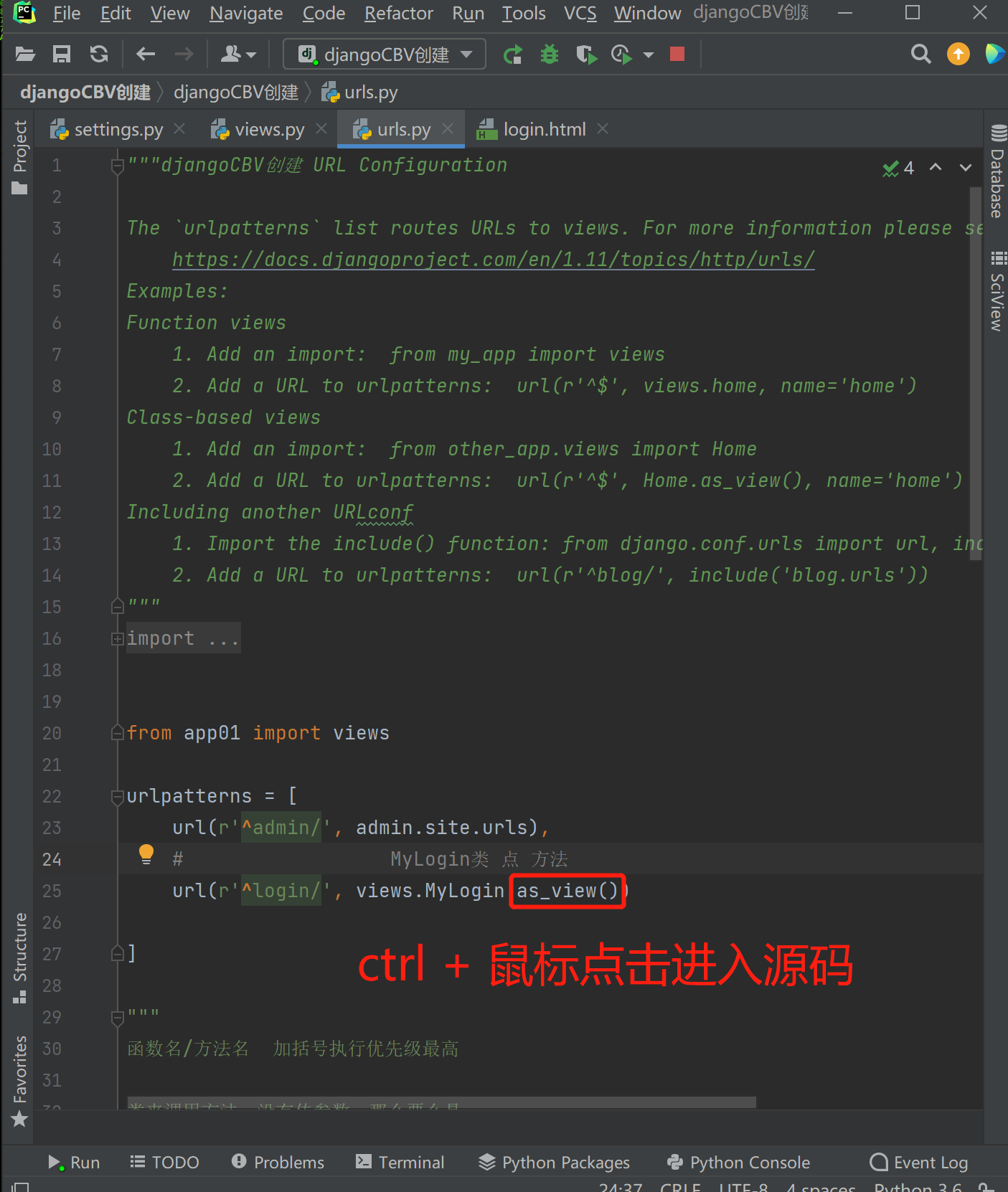
函数名/方法名 加括号执行优先级最高
类来调用方法,没有传参数,那么要么是以下两种
as_view()
要么是被@staicmethod修饰的静态方法
要么是被@classmethod修饰的类方法
# 源码显示
@classonlymethod # 绑定给类的方法
def as_view(cls, **initkwargs):
pass
as_view : 绑定给类的方法,类来调用把类传进去
# 闭包函数(内部函数引用外部函数名称空间中的名字)
def view(request, *args, **kwargs):
# 1.返回值是闭包函数的函数名
return view
代码在启动django的时候 就会立刻执行as_view方法
url(r'^login/', views.MyLogin.as_view()) # as_view 返回值 view
django代码运行 以上代码就等价于以下代码段
CBV与FBV在路由匹配上本质一样的 都是路由 对应 函数内存地址
url(r'^login/', views.view) django项目启动就等价于这个方法
view什么时候触发?
当用户在浏览器输入login的时候就自动执行 view方法
# 闭包函数(内部函数引用外部函数名称空间中的名字)
def view(request, *args, **kwargs):
self = cls(**initkwargs) # cls是我们自己写的类的对象
# self = MyLogin(**initkwargs) 产生一个我们自己写的类对象
# hasattr 映射 判断对象是否包含对应属性 (对象有该属性返回True 否则返回False)
if hasattr(self, 'get') and not hasattr(self, 'head'):
# 给对象赋值属性
self.head = self.get
self.request = request
self.args = args
self.kwargs = kwargs
# 对象点dispatch
return self.dispatch(request, *args, **kwargs)
# 面向对象属性方法查找顺序
1.先从对象自己名称空间找
2.在去产生类对象的类里面找
3.在去父类里面找
MyLogin >>名称空间中查找 >>产生类对象的类里面找 >>父类查找
class MyLogin(View): # 父类查找
def dispatch(self, request, *args, **kwargs):
# 判断 request.method将当前请求方式转成小写 在不在 self内 self==MyLogin
"http_method_names 内有八个请求方式 合法"
['get', 'post', 'put', 'patch', 'delete', 'head', 'options', 'trace']
if request.method.lower() in self.http_method_names:
"""
# getattr 反射: 通过字符串来操作对象的属性或者方法
# handler = gertattr(self,'get'),你写的Book类的get方法的内存地址
# handler = getattr(自己写的类产生的对象,'get',当找不到get属性或者方法的时候就会用第三个参数)
"""
handler = getattr(self, request.method.lower(), self.http_method_not_allowed)
else:
handler = self.http_method_not_allowed
return handler(request, *args, **kwargs) # 执行get(request)
class Book(View):
def get(self, request):
return HttpResponse('ok')
4.总结:
结论: as_view() 最终干的事情就是根据request请求方式来执行视图类的不同请求方法
以后会经常需要看源码,但是在看python源码的时候:
一定要时刻提醒自己面向对象属性方法查找顺序
1.先从对象自己找
2.在去产生对象的类里找
3.之后在去父类找
看源码只要看到了self点一个东西,一定要问自己当前这个self到底是谁。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号