PHP算法 《树形结构》 之 伸展树(1) - 基本概念
伸展树的介绍
1、出处:http://dongxicheng.org/structure/splay-tree/
A、 概述
二叉查找树(Binary Search Tree,也叫二叉排序树,即Binary Sort Tree)能够支持多种动态集合操作,它可以用来表示有序集合、建立索引等,因而在实际应用中,二叉排序树是一种非常重要的数据结构。
从算法复杂度角度考虑,我们知道,作用于二叉查找树上的基本操作(如查找,插入等)的时间复杂度与树的高度成正比。对一个含n个节点的完全二叉树,这些操作的最坏情况运行时间为O(log n)。但如果因为频繁的删除和插入操作,导致树退化成一个n个节点的线性链(此时即为一个单链表),则这些操作的最坏情况运行时间为O(n)。为了克服以上缺点,很多二叉查找树的变形出现了,如红黑树、AVL树,Treap树等。
本文介绍了二叉查找树的一种改进数据结构–伸展树(Splay Tree)。它的主要特点是不会保证树一直是平衡的,但各种操作的平摊时间复杂度是O(log n),因而,从平摊复杂度上看,二叉查找树也是一种平衡二叉树。另外,相比于其他树状数据结构(如红黑树,AVL树等),伸展树的空间要求与编程复杂度要小得多。
B、 基本操作
伸展树的出发点是这样的:考虑到局部性原理(刚被访问的内容下次可能仍会被访问,查找次数多的内容可能下一次会被访问),为了使整个查找时间更小,被查频率高的那些节点应当经常处于靠近树根的位置。这样,很容易得想到以下这个方案:每次查找节点之后对树进行重构,把被查找的节点搬移到树根,这种自调整形式的二叉查找树就是伸展树。每次对伸展树进行操作后,它均会通过旋转的方法把被访问节点旋转到树根的位置。
为了将当前被访问节点旋转到树根,我们通常将节点自底向上旋转,直至该节点成为树根为止。“旋转”的巧妙之处就是在不打乱数列中数据大小关系(指中序遍历结果是全序的)情况下,所有基本操作的平摊复杂度仍为O(log n)。
伸展树主要有三种旋转操作,分别为单旋转,一字形旋转和之字形旋转。为了便于解释,我们假设当前被访问节点为X,X的父亲节点为Y(如果X的父亲节点存在),X的祖父节点为Z(如果X的祖父节点存在)。
(1) 单旋转
节点X的父节点Y是根节点。这时,如果X是Y的左孩子,我们进行一次右旋操作;如果X 是Y 的右孩子,则我们进行一次左旋操作。经过旋转,X成为二叉查找树T的根节点,调整结束。

(2) 一字型旋转
节点X 的父节点Y不是根节点,Y 的父节点为Z,且X与Y同时是各自父节点的左孩子或者同时是各自父节点的右孩子。这时,我们进行一次左左旋转操作或者右右旋转操作。

(3) 之字形旋转
节点X的父节点Y不是根节点,Y的父节点为Z,X与Y中一个是其父节点的左孩子而另一个是其父节点的右孩子。这时,我们进行一次左右旋转操作或者右左旋转操作。

C、伸展树区间操作
在实际应用中,伸展树的中序遍历即为我们维护的数列,这就引出一个问题,怎么在伸展树中表示某个区间?比如我们要提取区间[a,b],那么我们将a前面一个数对应的结点转到树根,将b 后面一个结点对应的结点转到树根的右边,那么根右边的左子树就对应了区间[a,b]。原因很简单,将a 前面一个数对应的结点转到树根后, a 及a 后面的数就在根的右子树上,然后又将b后面一个结点对应的结点转到树根的右边,那么[a,b]这个区间就是下图中B所示的子树。

利用区间操作我们可以实现线段树的一些功能,比如回答对区间的询问(最大值,最小值等)。具体可以这样实现,在每个结点记录关于以这个结点为根的子树的信息,然后询问时先提取区间,再直接读取子树的相关信息。还可以对区间进行整体修改,这也要用到与线段树类似的延迟标记技术,即对于每个结点,额外记录一个或多个标记,表示以这个结点为根的子树是否被进行了某种操作,并且这种操作影响其子结点的信息值,当进行旋转和其他一些操作时相应地将标记向下传递。
与线段树相比,伸展树功能更强大,它能解决以下两个线段树不能解决的问题:
(1) 在a后面插入一些数。方法是:首先利用要插入的数构造一棵伸展树,接着,将a 转到根,并将a 后面一个数对应的结点转到根结点的右边,最后将这棵新的子树挂到根右子结点的左子结点上。
(2) 删除区间[a,b]内的数。首先提取[a,b]区间,直接删除即可。
2、出处:http://www.cnblogs.com/skywang12345/p/3604238.html
伸展树(Splay Tree)是一种二叉排序树,它能在O(log n)内完成插入、查找和删除操作。它由Daniel Sleator和Robert Tarjan创造。
(01) 伸展树属于二叉查找树,即它具有和二叉查找树一样的性质:假设x为树中的任意一个结点,x节点包含关键字key,节点x的key值记为key[x]。如果y是x的左子树中的一个结点,则key[y] <= key[x];如果y是x的右子树的一个结点,则key[y] >= key[x]。
(02) 除了拥有二叉查找树的性质之外,伸展树还具有的一个特点是:当某个节点被访问时,伸展树会通过旋转使该节点成为树根。这样做的好处是,下次要访问该节点时,能够迅速的访问到该节点。
假设想要对一个二叉查找树执行一系列的查找操作。为了使整个查找时间更小,被查频率高的那些条目就应当经常处于靠近树根的位置。于是想到设计一个简单方法,在每次查找之后对树进行重构,把被查找的条目搬移到离树根近一些的地方。伸展树应运而生,它是一种自调整形式的二叉查找树,它会沿着从某个节点到树根之间的路径,通过一系列的旋转把这个节点搬移到树根去。
相比于"二叉查找树"和"AVL树",学习伸展树时需要重点关注是"伸展树的旋转算法"。
旋转
旋转的代码:
/* * 旋转key对应的节点为根节点,并返回根节点。 */ Node* splaytree_splay(SplayTree tree, Type key) { Node N, *l, *r, *c; if (tree == NULL) return tree; N.left = N.right = NULL; l = r = &N; for (;;) { if (key < tree->key) { if (tree->left == NULL) break; if (key < tree->left->key) { c = tree->left; /* 01, rotate right */ tree->left = c->right; c->right = tree; tree = c; if (tree->left == NULL) break; } r->left = tree; /* 02, link right */ r = tree; tree = tree->left; } else if (key > tree->key) { if (tree->right == NULL) break; if (key > tree->right->key) { c = tree->right; /* 03, rotate left */ tree->right = c->left; c->left = tree; tree = c; if (tree->right == NULL) break; } l->right = tree; /* 04, link left */ l = tree; tree = tree->right; } else { break; } } l->right = tree->left; /* 05, assemble */ r->left = tree->right; tree->left = N.right; tree->right = N.left; return tree; }
上面的代码的作用:将"键值为key的节点"旋转为根节点,并返回根节点。它的处理情况共包括:
(a):伸展树中存在"键值为key的节点"。
将"键值为key的节点"旋转为根节点。
(b):伸展树中不存在"键值为key的节点",并且key < tree->key。
b-1) "键值为key的节点"的前驱节点存在的话,将"键值为key的节点"的前驱节点旋转为根节点。
b-2) "键值为key的节点"的前驱节点存在的话,则意味着,key比树中任何键值都小,那么此时,将最小节点旋转为根节点。
(c):伸展树中不存在"键值为key的节点",并且key > tree->key。
c-1) "键值为key的节点"的后继节点存在的话,将"键值为key的节点"的后继节点旋转为根节点。
c-2) "键值为key的节点"的后继节点不存在的话,则意味着,key比树中任何键值都大,那么此时,将最大节点旋转为根节点。
下面列举个例子分别对a进行说明。
在下面的伸展树中查找10,共包括"右旋" --> "右链接" --> "组合"这3步。
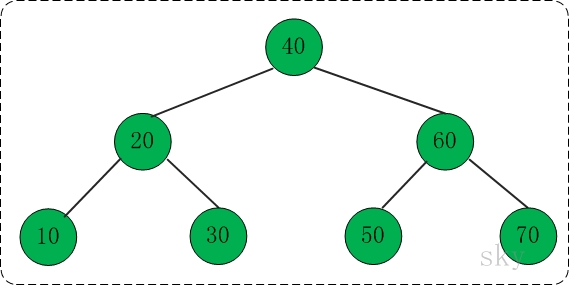
第一步: 右旋
对应代码中的"rotate right"部分
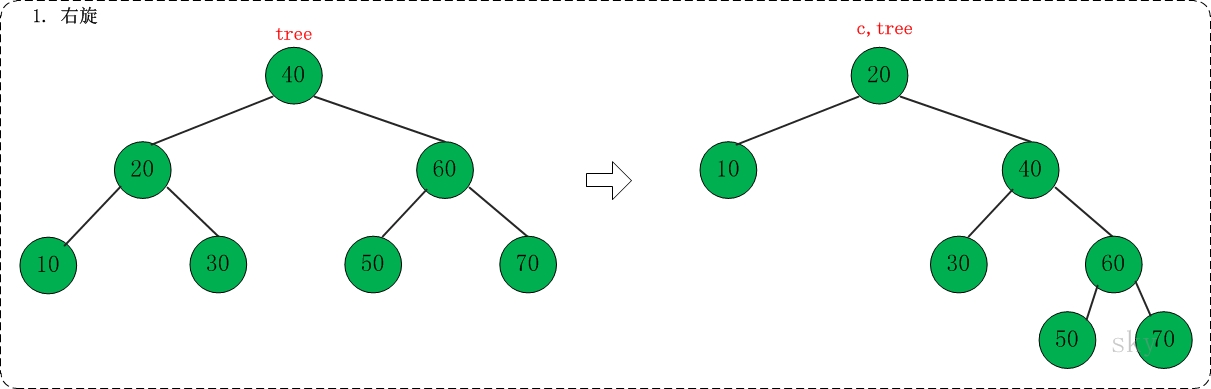
第二步: 右链接
对应代码中的"link right"部分
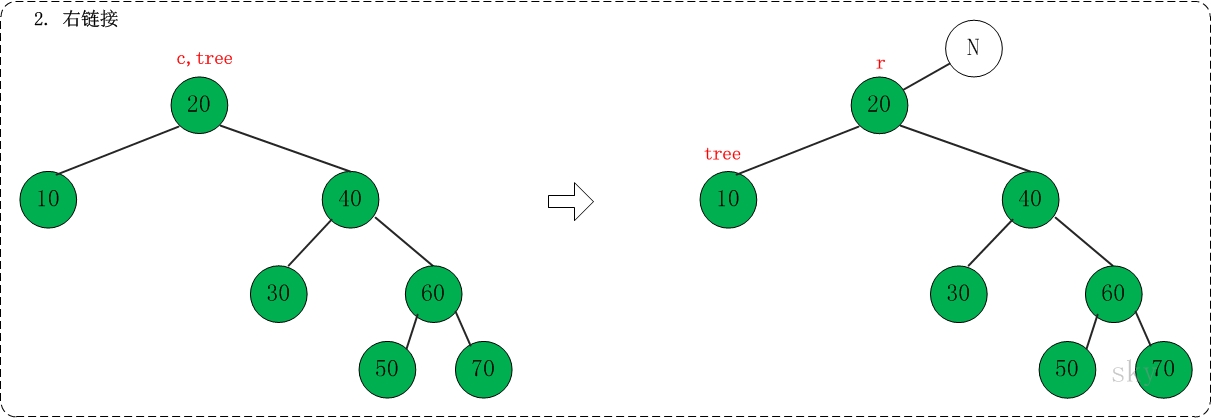
第三步: 组合
对应代码中的"assemble"部分
提示:如果在上面的伸展树中查找"70",则正好与"示例1"对称,而对应的操作则分别是"rotate left", "link left"和"assemble"。
其它的情况,例如"查找15是b-1的情况,查找5是b-2的情况"等等,这些都比较简单,大家可以自己分析。
例子:
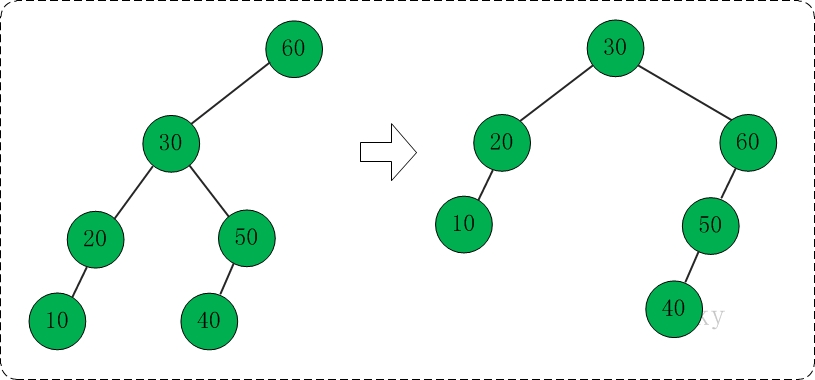
新建伸展树,然后向伸展树中依次插入10,50,40,30,20,60。插入完毕这些数据之后,伸展树的节点是60;此时,再旋转节点,使得30成为根节点。
依次插入10,50,40,30,20,60示意图如下:

将30旋转为根节点的示意图如下:
3、出处:http://www.cnblogs.com/vamei/archive/2013/03/24/2976545.html
树的搜索效率与树的深度有关。二叉搜索树的深度可能为n,这种情况下,每次搜索的复杂度为n的量级。AVL树通过动态平衡树的深度,单次搜索的复杂度为log(n) 。我们下面看伸展树(splay tree),它对于m次连续搜索操作有很好的效率。
伸展树会在一次搜索后,对树进行一些特殊的操作。这些操作的理念与AVL树有些类似,即通过旋转,来改变树节点的分布,并减小树的深度。但伸展树并没有AVL的平衡要求,任意节点的左右子树可以相差任意深度。与二叉搜索树类似,伸展树的单次搜索也可能需要n次操作。但伸展树可以保证,m次的连续搜索操作的复杂度为mlog(n)的量级,而不是mn量级。
具体来说,在查询到目标节点后,伸展树会不断进行下面三种操作中的一个,直到目标节点成为根节点 (注意,祖父节点是指父节点的父节点)
1. zig: 当目标节点是根节点的左子节点或右子节点时,进行一次单旋转,将目标节点调整到根节点的位置。
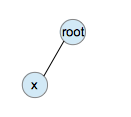
zig
2. zig-zag: 当目标节点、父节点和祖父节点成"zig-zag"构型时,进行一次双旋转,将目标节点调整到祖父节点的位置。
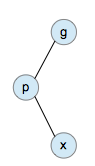
zig-zag
3. zig-zig:当目标节点、父节点和祖父节点成"zig-zig"构型时,进行一次zig-zig操作,将目标节点调整到祖父节点的位置。

zig-zig
单旋转操作和双旋转操作见AVL树。下面是zig-zig操作的示意图:
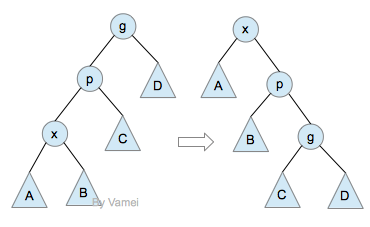
zig-zig operation
在伸展树中,zig-zig操作(基本上)取代了AVL树中的单旋转。通常来说,如果上面的树是失衡的,那么A、B子树很可能深度比较大。相对于单旋转(想一下单旋转的效果),zig-zig可以将A、B子树放在比较高的位置,从而减小树总的深度。
下面我们用一个具体的例子示范。我们将从树中搜索节点2:
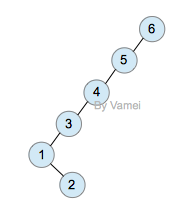
Original
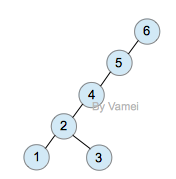
zig-zag (double rotation)
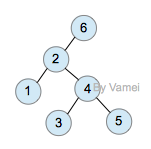
zig-zig
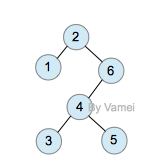
zig (single rotation at root)
上面的第一次查询需要n次操作。然而经过一次查询后,2节点成为了根节点,树的深度大减小。整体上看,树的大部分节点深度都减小。此后对各个节点的查询将更有效率。
伸展树的另一个好处是将最近搜索的节点放在最容易搜索的根节点的位置。在许多应用环境中,比如网络应用中,某些固定内容会被大量重复访问(比如江南style的MV)。伸展树可以让这种重复搜索以很高的效率完成。
4、出处:http://www.cnblogs.com/kernel_hcy/archive/2010/03/17/1688360.html
一、简介:
伸展树,或者叫自适应查找树,是一种用于保存有序集合的简单高效的数据结构。伸展树实质上是一个二叉查找树。允许查找,插入,删除,删除最小,删除最大,分割,合并等许多操作,这些操作的时间复杂度为O(logN)。由于伸展树可以适应需求序列,因此他们的性能在实际应用中更优秀。
伸展树支持所有的二叉树操作。伸展树不保证最坏情况下的时间复杂度为O(logN)。伸展树的时间复杂度边界是均摊的。尽管一个单独的操作可能很耗时,但对于一个任意的操作序列,时间复杂度可以保证为O(logN)。
二、自调整和均摊分析:
平衡查找树的一些限制:
1、平衡查找树每个节点都需要保存额外的信息。
2、难于实现,因此插入和删除操作复杂度高,且是潜在的错误点。
3、对于简单的输入,性能并没有什么提高。
平衡查找树可以考虑提高性能的地方:
1、平衡查找树在最差、平均和最坏情况下的时间复杂度在本质上是相同的。
2、对一个节点的访问,如果第二次访问的时间小于第一次访问,将是非常好的事情。
3、90-10法则。在实际情况中,90%的访问发生在10%的数据上。
4、处理好那90%的情况就很好了。
三、均摊时间边界:
在一颗二叉树中访问一个节点的时间复杂度是这个节点的深度。因此,我们可以重构树的结构,使得被经常访问的节点朝树根的方向移动。尽管这会引入额外的操作,但是经常被访问的节点被移动到了靠近根的位置,因此,对于这部分节点,我们可以很快的访问。根据上面的90-10法则,这样做可以提高性能。
为了达到上面的目的,我们需要使用一种策略──旋转到根(rotate-to-root)。具体实现如下:
旋转分为左旋和右旋,这两个是对称的。图示:

为了叙述的方便,上图的右旋叫做X绕Y右旋,左旋叫做Y绕X左旋。
下图展示了将节点3旋转到根:

图1
首先节点3绕2左旋,然后3绕节点4右旋。
注意:所查找的数据必须符合上面的90-10法则,否则性能上不升反降!!
四、基本的自底向上伸展树:
应用伸展(splaying)技术,可以得到对数均摊边界的时间复杂度。
在旋转的时候,可以分为三种情况:
1、zig情况。
X是查找路径上我们需要旋转的一个非根节点。
如果X的父节点是根,那么我们用下图所示的方法旋转X到根:

图2
这和一个普通的单旋转相同。
2、zig-zag情况。
在这种情况中,X有一个父节点P和祖父节点G(P的父节点)。X是右子节点,P是左子节点,或者反过来。这个就是双旋转。
先是X绕P左旋转,再接着X绕G右旋转。
如图所示:

图三
3、zig-zig情况。
这和前一个旋转不同。在这种情况中,X和P都是左子节点或右子节点。
先是P绕G右旋转,接着X绕P右旋转。
如图所示:

图四
下面是splay的伪代码:
P(X) : 获得X的父节点,G(X) : 获得X的祖父节点(=P(P(X)))。 Function Buttom-up-splay: Do If X 是 P(X) 的左子结点 Then If G(X) 为空 Then X 绕 P(X)右旋 Else If P(X)是G(X)的左子结点 P(X) 绕G(X)右旋 X 绕P(X)右旋 Else X绕P(X)右旋 X绕P(X)左旋 (P(X)和上面一句的不同,是原来的G(X)) Endif Else If X 是 P(X) 的右子结点 Then If G(X) 为空 Then X 绕 P(X)左旋 Else If P(X)是G(X)的右子结点 P(X) 绕G(X)左旋 X 绕P(X)左旋 Else X绕P(X)左旋 X绕P(X)右旋 (P(X)和上面一句的不同,是原来的G(X)) Endif Endif While (P(X) != NULL) EndFunction
仔细分析zig-zag,可以发现,其实zig-zag就是两次zig。因此上面的代码可以简化:
Function Buttom-up-splay: Do If X 是 P(X) 的左子结点 Then If P(X)是G(X)的左子结点 P(X) 绕G(X)右旋 Endif X 绕P(X)右旋 Else If X 是 P(X) 的右子结点 Then If P(X)是G(X)的右子结点 P(X) 绕G(X)左旋 Endif X 绕P(X)左旋 Endif While (P(X) != NULL) EndFunction
下面是一个例子,旋转节点c到根上。

图五
五、基本伸展树操作:
1、插入:
当一个节点插入时,伸展操作将执行。因此,新插入的节点在根上。
2、查找:
如果查找成功(找到),那么由于伸展操作,被查找的节点成为树的新根。
如果查找失败(没有),那么在查找遇到NULL之前的那个节点成为新的根。也就是,如果查找的节点在树中,那么,此时根上的节点就是距离这个节点最近的节点。
3、查找最大最小:
查找之后执行伸展。
4、删除最大最小:
a)删除最小:
首先执行查找最小的操作。
这时,要删除的节点就在根上。根据二叉查找树的特点,根没有左子节点。
使用根的右子结点作为新的根,删除旧的包含最小值的根。
b)删除最大:
首先执行查找最大的操作。
删除根,并把被删除的根的左子结点作为新的根。
5、删除:
将要删除的节点移至根。
删除根,剩下两个子树L(左子树)和R(右子树)。
使用DeleteMax查找L的最大节点,此时,L的根没有右子树。
使R成为L的根的右子树。
如下图示:

图六
六、自顶向下的伸展树:
在自底向上的伸展树中,我们需要求一个节点的父节点和祖父节点,因此这种伸展树难以实现。因此,我们可以构建自顶向下的伸展树。
当我们沿着树向下搜索某个节点X的时候,我们将搜索路径上的节点及其子树移走。我们构建两棵临时的树──左树和右树。没有被移走的节点构成的树称作中树。在伸展操作的过程中:
1、当前节点X是中树的根。
2、左树L保存小于X的节点。
3、右树R保存大于X的节点。
开始时候,X是树T的根,左右树L和R都是空的。和前面的自下而上相同,自上而下也分三种情况:
1、zig:

图七
如上图,在搜索到X的时候,所查找的节点比X小,将Y旋转到中树的树根。旋转之后,X及其右子树被移动到右树上。很显然,右树上的节点都大于所要查找的节点。注意X被放置在右树的最小的位置,也就是X及其子树比原先的右树中所有的节点都要小。这是由于越是在路径前面被移动到右树的节点,其值越大。读者可以分析一下树的结构,原因很简单。
2、zig-zig:
图八
在这种情况下,所查找的节点在Z的子树中,也就是,所查找的节点比X和Y都小。所以要将X,Y及其右子树都移动到右树中。首先是Y绕X右旋,然后Z绕Y右旋,最后将Z的右子树(此时Z的右子节点为Y)移动到右树中。注意右树中挂载点的位置。
3、zig-zag:

图九
在这种情况中,首先将Y右旋到根。这和Zig的情况是一样的。然后变成上图右边所示的形状。接着,对Z进行左旋,将Y及其左子树移动到左树上。这样,这种情况就被分成了两个Zig情况。这样,在编程的时候就会简化,但是操作的数目增加(相当于两次Zig情况)。
最后,在查找到节点后,将三棵树合并。如图:

图十
将中树的左右子树分别连接到左树的右子树和右树的左子树上。将左右树作为X的左右子树。重新最成了一所查找的节点为根的树。
下面给出伪代码:
右连接:将当前根及其右子树连接到右树上。左子结点作为新根。 左连接:将当前根及其左子树连接到左树上。右子结点作为新根。 T : 当前的根节点。 Function Top-Down-Splay Do If X 小于 T Then If X 等于 T 的左子结点 Then 右连接 ElseIf X 小于 T 的左子结点 Then T的左子节点绕T右旋 右连接 Else X大于 T 的左子结点 Then 右连接 左连接 EndIf ElseIf X大于 T Then IF X 等于 T 的右子结点 Then 左连接 ElseIf X 大于 T 的右子结点 Then T的右子节点绕T左旋 左连接 Else X小于 T 的右子结点 Then 左连接 右连接 EndIf EndIf While !(找到 X或遇到空节点) 组合左中右树 EndFunction
同样,上面的三种情况也可以简化:
Function Top-Down-Splay Do If X 小于 T Then If X 小于 T 的左孩子 Then T的左子节点绕T右旋 EndIf 右连接 Else If X大于 T Then If X 大于 T 的右孩子 Then T的右子节点绕T左旋 EndIf 左连接 EndIf While !(找到 X或遇到空节点) 组合左中右树 EndFuntion
下面是一个查找节点19的例子:
在例子中,树中并没有节点19,最后,距离节点最近的节点18被旋转到了根作为新的根。节点20也是距离节点19最近的节点,但是节点20没有成为新根,这和节点20在原来树中的位置有关系。

这个例子是查找节点c:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号