

Linux C/C++服务器
Redis缓存数据库
MySQL通常会作为我们项目中的主要数据库,因为每次增删改都会通过redolog进行落盘,因此它比Redis这种内存数据库的数据安全性要高一些,而且存储的数据量也更大;
但是由于MySQL读数据几乎都要去磁盘中查找,虽然有B+树,也有BufferPool缓存机制,但是BufferPool的缓存机制为LRU(缓存热点数据),并不允许用户定制自己的缓存策略。
如何提升MySQL的读写性能?
1.Redis缓存方案
缓存用户自定义的热点数据,用户直接从Redis缓存获取热点数据,降低数据库的读写压力
- 由于MySQL的缓冲层不由用户来控制,也就是不能由用户来控制缓存具体数据;
- 访问磁盘的速度比较慢,尽量获取数据从内存中获取;
- 主要解决读的性能;因为写没必要优化,必须让数据正确的落盘;如果写性能出现问题,那么请使用横向扩展集群方式来解决;
- 项目中需要存储的数据应该远大于内存的容量,同时需要进行数据统计分析,所以数据存储获取的依据应该是关系型数据库;
- Redis缓存数据库为辅助数据库,存放用户自定义热点数据
1.1 什么是业务相关热点数据?
我们举个例子说明:
某电商平台推出一个限时抢购活动,于今天中午12点开始,那么12点时会有大量用户的登陆行为(用户名及密码确认),会给MySQL造成很大的压力,甚至会导致服务崩溃,因为MySQL的缓存只有LRU数据,并没有用户登录数据;
如果我们提前通过Redis缓存了用户的用户名和密码数据,那么将直接通过Redis进行登录确认,会大大降低MySQL的压力,我们把Redis提前缓存的数据称为业务相关热点数据。
2. Redis与MySQL间数据同步
没有redis缓冲层之前,我们对数据的读写都是基于 mysql;所以不存在同步问题;这句话也不是必然,比如读写分离就存在同步问题(数据一致性问题);引入缓冲层后,我们对数据的获取需要分别操作缓存数据库和mysql;
那么这个时候数据可能存在几个状态?
- mysql 有,缓存无
- mysql 无,缓存有
- 都有,但数据不一致
- 都有,数据一致
- 都没有
4 和 5显然是没问题的,我们现在需要考虑1、2以及3;
首先明确一点:我们获取数据的主要依据是 mysql,只需要将mysql 的数据正确同步到缓存数据库就可以了;同理,缓存有,mysql 没有,这比较危险,此时我们可以认为该数据为脏数据;所以我们需要在同步策略中避免该情况发生;同时可能存在mysql 和缓存都有数据,但是数据不一致,这种也需要在同步策略中避免;
注意:缓存不可用,整个系统依然要保持正常工作
2.1 同步策略
在工程中,我们通常会在效率和安全之间做权衡,从而产生不同的策略
2.1.1 策略1(安全优先)
读用户自定义的热点数据在redis内读,其余读写依然以mysql为主
-
读流程
先读缓存,若缓存有,直接返回;若缓存没有,读mysql;若 mysql 有,同步到缓存,并返回;若 mysql 没有,则返回没有; -
写流程(避免出现状态2和3)
先删除redis缓存,再写 mysql,后面数据同步交由 go-mysql-transfer 等中间件处理;(将状态 3 转化成 1)
先删除redis缓存,为了避免其他服务读取旧的数据;也是告知系统这个数据已经不是最新,建议从 mysql 获取数据;但是对于服务 A 而言,写入 mysql 后,接着读操作必须要能读到最新的数据;
-
确保同一个key没有并发问题:
使用连接池,确保热点数据key总是在同一条连接上进行操作(通过hash),同一个key必须要走同一个MySQL连接或同一个redis连接来确保key没有并发问题,也就是说有一条连接在访问某个key,不可能有另外一条连接也在访问这个key
2.1.2 策略2(效率优先)
效率为主安全性次之,Redis为主,读写都为redis,mysql做持久化数据库使用,工作中常用
现在主要以pika为主,pika支持redis协议内有rocksdb做持久化
- 读流程
先读缓存,若缓存有,直接返回;若缓存没有,读mysql;若 mysql 有,同步到缓存,并返回;若 mysql 没有,则返回没有; - 写流程:
先写Redis缓存,并设置过期时间(如 200ms,此数据200ms后自动删除),再写mysql,后面数据同步交由其他中间件处理;这里设置的过期时间是预估时间,大致上是 mysql 到缓存同步的时间;
在写的过程中如果 mysql 停止服务,或数据没写入 mysql,则200 ms 内提供了脏数据服务;但仅仅只有 200ms 的数据错乱;
2.2 如何把mysql数据同步到Redis
开源解决方案
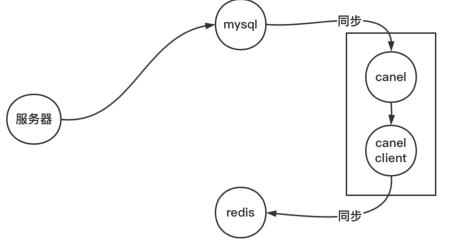
2.2.1 伪装从数据库
拉取binlog,分析变更数据
- 阿里 开源 canal
- go语言go-mysql-transfer

2.2.2 触发器
把热点数据表设置触发器,触发器(解析undolog) + udf(c/c++ mysql扩展代码 与redis建立连接,把数据进行同步)
3. 缓存健壮性问题
我们刚刚思考的方向全是正常流程下的方式,我们来看异常情况;
3.1 缓存穿透
假设某个数据 redis 不存在,mysql 也不存在,而且一直尝试读怎么办?缓存穿透,数据最终压力依然堆积在 mysql,可能造成 mysql 不堪重负而崩溃;
解决方案:
- 发现 mysql 不存在,将 redis 设置为 <key, nil> 设置过期时间 下次访问 key 的时候 不再访问 mysql 容易造成 redis 缓存很多无效数据;
- 布隆过滤器,将 mysql 当中已经存在的 key,写入布隆过滤器,不存在的直接 pass 掉;
3.2 缓存击穿
缓存击穿某些数据 redis 没有,但是 mysql 有;此时当大量这类数据的并发请求,同样造成 mysql 过大;
解决方案:
- 分布式锁
请求数据的时候获取锁,若获取成功,则操作后释放锁;若获取失败,则休眠一段时间(200ms)再去获取,当获取成功,操作后释放锁 - 将很热的 key,设置不过期;
3.3 缓存雪崩
表示一段时间内,缓存集中失效(redis 无, mysql 有),导致请求全部走 mysql,有可能搞垮数据库,使整个服务失效;
mysql 主要的数据的依据;redis 可有可无的状态;
解决方案:
缓存数据库在整个系统不是必须的,也就是缓存宕机不会影响整个系统提供服务;
- 如果因为缓存数据库宕机,造成所有数据涌向 mysql;
采用高可用的集群方案,如哨兵模式、cluster模式; - 如果因为设置了相同的过期时间,造成缓存集中失效;
设置随机过期值或者其他机制错开失效时间; - 如果因为系统重启的时候,造成缓存数据消失;
重启时间短,redis 开启持久化(过期信息也会持久化)就行了; 重启时间长提前将热数据导入 redis 当中;

