Linux C/C++服务器
连接池
创建数据库连接是一个很耗时的操作,也容易对数据库造成安全隐患。所以,在程序初始化的时候,集中创建多个数据库连接,并把他们集中管理,供程序使用,可以保证较快的数据库读写速度,还更加安全可靠。
这里讲的数据库,不单只是指Mysql,也同样适用于Redis
连接池的意义
- 资源复用
由于数据库连接得到复用,避免了频繁的创建、释放连接引起的性能开销,在减少系统消耗的基础上,另一方面也增进了系统运行环境的平稳性(减少内存碎片以及数据库临时进程/线程的数量) - 更快的系统响应速度
数据库连接池在初始化过程中,往往已经创建了若干数据库连接置于池中备用。此时连接的初始化工作均已完成。对于业务请求处理而言,直接利用现有可用连接,避免了从数据库连接初始化和释放过程的开销,从而缩减了系统整体响应时间。 - 统一的连接管理,避免数据库连接泄露
在较为完备的数据库连接池实现中,可根据预先的连接占用超时设定,强制收回被占用连接。从而避免了常规数据库连接操作中可能出现的资源泄露。
mysql api c客户端范例
hiredis api 使用
长连接和连接池的区别
- 长连接是一些驱动、驱动框架、ORM工具的特性,由驱动来保持连接句柄的打开,以便后续的数据库操作可以重用连接,从而减少数据库的连接开销。
- 连接池是应用服务器的组件,它可以通过参数来配置连接数、连接检测、连接的生命周期等。
- 连接池内的连接,其实就是长连接。
连接池的设计要点
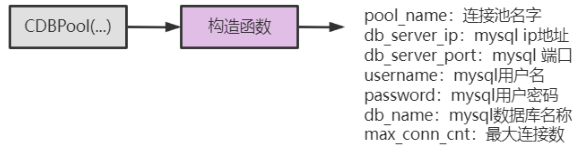
- 连接到数据库,涉及到数据库ip、端口、用户名、密码、数据库名字等;
- 连接的操作,每个连接对象都是独立的连接通道,它们是独立的
- 配置最小连接数和最大连接数
- 需要一个队列管理他的连接,比如使用list;
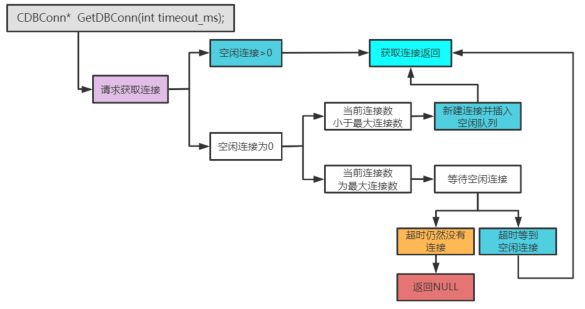
- 获取连接对象:
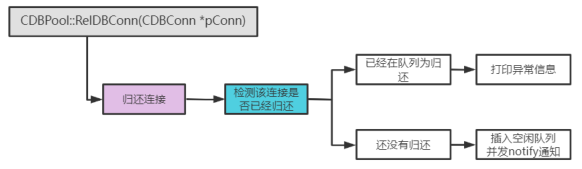
- 归还连接对象;
连接池的设计逻辑
- 构造函数
![]()
- 初始化
![]()
- 请求获取连接
![]()
- 归还连接
![]()
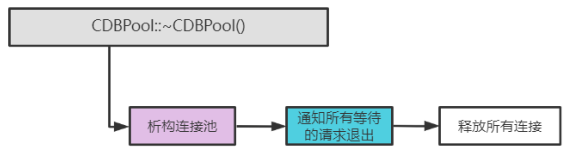
- 析构连接池
![]()
- 构造多个连接池
![]()

连接池代码
代码不复杂,简单了解下连接池设计逻辑后,建议直接调试代码来学习连接池
mysql连接池
- 编译
cd mysql_pool
mdkir build
cmake ..
make
编译后的执行文件在build目录
- 测试数据库连接
- test_curd.cpp对应源码
- 修改主机的地址: #define DB_HOST_IP "127.0.0.1" // 数据库服务器ip 以及其他的参数,比如端口、用户名、密码等
- 执行:./test_curd
redis连接池
- 编译
cd mysql_pool
mdkir build
cmake ..
make
编译后的执行文件在build目录
- 对应test_CachePoo.cpp
testCacheUsePool 函数 测试使用同一连接重复set数据
testCacheOneCmdPerConn函数测试 每次set都重新创建连接 - 对应test_dbpool.cpp
./test_dbpool 4 4 1 代表使用4线程,4连接,1使用连接池
./test_dbpool 4 4 0 代表使用4线程,4连接,0不用连接池

 浙公网安备 33010602011771号
浙公网安备 33010602011771号