二分k均值聚类是k均值聚类的增强版:为克服K-均值算法收敛于局部最小值的问题,有人提出了另一个称为二分K-均值(bisecting K-means)的算法。
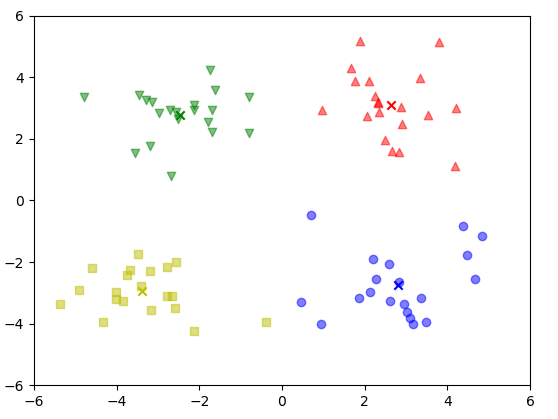
#K-means聚类 from numpy import * import matplotlib.pyplot as plt plt.ion() #开启交互模式,实时绘制 plt.subplots() plt.xlim(-6, 6) plt.ylim(-6, 6) #plt.pause(5) def loadDataSet(fileName): dataMat = [] fr = open(fileName) for line in fr.readlines(): curLine = line.strip().split('\t') fltLine = list(map(float,curLine)) dataMat.append(fltLine) return dataMat def distEclud(vecA, vecB): #print("vecA:",vecA,"vecB:",vecB) return sqrt(sum(power(vecA-vecB, 2))) #欧式距离 #给定数据集构建一个包含k个随机质心的集合 #该函数为给定数据集构建一个包含k个随机质心的集合 #集合中的值位于min合max之间 def randCent(dataSet, k): n = shape(dataSet)[1] centroids = mat(zeros((k,n))) for j in range(n): minJ = min(dataSet[:,j]) rangeJ = float(max(dataSet[:,j]) - minJ) centroids[:,j] = minJ + rangeJ*random.rand(k,1) return centroids ''' k-均值聚类算法: 该算法会创建k个质心,然后将每个点分配到最近的质心。这个过程重复数次,直到数据点的簇分配结果不再改变为止。 这个接口的缺点是:质心是随机初始化的,虽然最后会通过划分后的点加均值函数重新计算,但质心没有真正的进行最优化收敛 k均值算法收敛(kMeans函数)到了局部最小值,而非全局最小值 一种用于度量聚类效果的指标是SSE(Sum of Squared Error,误差平方和),SSE值越小表示数据点越接近于它们的质心,聚类 效果也就越好。因为对误差取了平方,因此更加重视那些远离中心的点,一种肯定可以降低SSE值的方法是怎加簇的个数, 但这违背了聚类的目标。聚类的目标是在保持簇数目不变的情况下提高簇的质量。 ''' def kMeans(dataSet, k, distMeans=distEclud, createCent=randCent): m = shape(dataSet)[0] clusterAssment = mat(zeros((m, 2))) #记录每个样本点到质心的最小距离,及最小距离质心的索引 centroids = createCent(dataSet, k) centroids_mean_before=centroids plt_scatter(dataSet,centroids,clusterAssment) clusterChanged = True while clusterChanged: clusterChanged = False for i in range(m): #样本数据按行遍历 minDist = inf; minIndex = -1 #inf 表示正无穷 for j in range(k): #遍历质心,寻找最近质心 distJI = distMeans(centroids[j,:], dataSet[i,:]) #计算i点到j质心的距离 if distJI < minDist: minDist = distJI; minIndex=j #计算出每个样本数据最近的质心点与距离 if clusterAssment[i,0] != minIndex: clusterChanged = True clusterAssment[i,:] = minIndex,minDist**2 plt_scatter(dataSet,centroids_mean_before,clusterAssment) for cent in range(k): #遍历所有的质心并更新它们的取值 ptsInClust = dataSet[nonzero(clusterAssment[:,0].A == cent)[0]] centroids[cent,:] = mean(ptsInClust, axis=0) centroids_mean_before = centroids plt_scatter(dataSet,centroids,clusterAssment) return centroids, clusterAssment #二分K-均值算法 ''' 为了克服k-均值算法收敛于局部最小值的问题,有人提出了另一个称为二分K-均值的算法。 二分k-均值:首先将所有点作为一个簇,然后将该簇一分为二。之后选择其中一个簇继续进行划分, 选择哪个簇继续划分取决于对其划分是否可以最大程度降低SSE的值。上述基于SSE的划分过程不断重复, 直到得到用户指定的簇数目为止。 ''' def biKmeans(dataSet, k, distMeas=distEclud): m = shape(dataSet)[0] clusterAssment = mat(zeros((m,2))) #创建一个m*2的零矩阵 #print('clusterAssment:',clusterAssment) centroid0 = mean(dataSet, axis=0).tolist()[0] #tolist() 把mat转为list centList = [centroid0] plt_scatter(dataSet, mat(centList), clusterAssment) #print('centList:', centList) for j in range(m): clusterAssment[j,1] = distMeas(mat(centroid0), dataSet[j,:])**2 #记录每个点到质心的距离的平方 #print('clusterAssment:',clusterAssment) while (len(centList) < k): lowestSSE = inf #正无穷 for i in range(len(centList)): #以clusterAssment中第一列索引为i的行为索引,找到这些索引对应dataSet的的值返回。通俗讲 就是找出第i个质心关联的点 ptsInCurrCluster = dataSet[nonzero(clusterAssment[:,0].A==i)[0],:] centroidMat,splitClustAss = kMeans(ptsInCurrCluster, 2, distMeas) sseSplit = sum(splitClustAss[:,1]) sseNotSplit = sum(clusterAssment[nonzero(clusterAssment[:,0].A!=i)[0],1]) #求划分前其余(除i质心之外的)质心的sse值 print("sseSplit, and notSplit:",sseSplit, sseNotSplit) if (sseSplit + sseNotSplit) < lowestSSE: bestCentToSplit = i bestNewCents = centroidMat bestClustAss = splitClustAss.copy() lowestSSE = sseSplit + sseNotSplit #所有质心(被分割的质心加没被分割的质心)距离的平方 #更新bestClustAss簇的分配结果 bestClustAss[nonzero(bestClustAss[:,0].A == 1)[0],0] = len(centList) bestClustAss[nonzero(bestClustAss[:,0].A == 0)[0],0] = bestCentToSplit print("the bestCentToSplit is:",bestCentToSplit) print("the len of bestClustAss is:", len(bestClustAss)) #将bestCentTosplit(最适合分割的质心点),替换为分割后的第0个质心点,分割后生成的另一个质心点通过 append方法添加 centList[bestCentToSplit] = bestNewCents[0,:].tolist()[0] #python3修改 centList.append(bestNewCents[1,:].tolist()[0]) #将被分割的质心cluter索引和最小距离平方(minDist**2) 重新赋值 clusterAssment[nonzero(clusterAssment[:,0].A == bestCentToSplit)[0],:] = bestClustAss plt_scatter(dataSet, mat(centList), clusterAssment) return mat(centList),clusterAssment #绘图接口 def plt_scatter(datMat,datCent,cluster): plt.clf() # 清空画布 plt.xlim(-6, 6) # 因为清空了画布,所以要重新设置坐标轴的范围 plt.ylim(-6, 6) m = shape(datMat)[0] n = shape(datCent)[0] ms=['^','v','o','s','p','<','>','1','2','3'] #数据点形状 cs=['r','g','b','y','m','c','k','r','g','b'] #数据点的颜色 for i in range(m): k=int(cluster[i,0]) plt.scatter(datMat[i,0],datMat[i,1],c=cs[k],marker=ms[k],alpha=0.5) for j in range(n): plt.scatter(datCent[j,0],datCent[j,1],c=cs[j],marker='x',alpha=1.0) plt.pause(0.3) if __name__ == '__main__': datMat = mat(loadDataSet('testSet.txt')) #myCentroids,clusterAssing = kMeans(datMat, 4) #plt_scatter(datMat,myCentroids,clusterAssing) centList,myNewAssments=biKmeans(datMat,4) plt_scatter(datMat,centList,myNewAssments) plt.ioff() plt.show()
链接:https://pan.baidu.com/s/1E-x93BbFhZ32CnucPpHOWw
提取码:abt2
网盘中数据为“testSet.txt”数据和聚类的动态视频