
环境:Linux、python3.7.5
需要的数据集:链接: https://pan.baidu.com/s/1KdH1DgErvgu4GC8MrwY-FA 提取码: wb3h
代码如下
#k-近邻算法概述 ''' 简单的说k-近邻算法采用测量不同特征值之间的距离方法进行分类。 优点:精度高、对异常值不敏感、无数据输入假定。 缺点:计算复杂度高、空间复杂度高。 适用数据范围:数值型和标称型。 工作原理:存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一个数据与所属分类的对应关系。 输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类 标签。一般来说我们只选择样本数据集中前k个最相似的数据,这就是k-近邻算法中k的出处,通常k是不大于20的整数。最后,选择k个最相似数据 中出现次数最多的分类,作为新数据的分类。 电影分类的例子: 使用k-近邻算法分类爱情片和动作片,特征选为“打斗镜头”和“接吻镜头” 表2-1 每部电影的打斗镜头数、接吻镜头数以及电影评估类型 电影名称 打斗镜头 接吻镜头 电影类型 California Man 3 104 爱情片 He's Not Really into Dudes 2 100 爱情片 Beautiful Woman 1 81 爱情片 Kevin Longblade 101 10 动作片 Robo Slayer 3000 99 5 动作片 Amped II 98 2 动作片 ? 18 90 未知 表2-2 已知电影与未知电影的距离 电影名称 与未知电影的距离 California Man 20.5 He's Not Really into Dudes 18.7 Beautiful Woman 19.2 Kevin Longblade 115.3 Robo Slayer 3000 117.4 Amped II 118.9 现在我们得到了样本集中所有电影与未知电影的距离,按照距离递增排序,可以找到k个距离最近的电影。假定k=3,则三个最靠近的电影依次是 He's Not Really into Dudes、Beautiful Woman、California Man。k-近邻算法按照距离最近的三部电影的类型,决定未知电影的类型,而 这三部电影全是爱情片,因此我们判定未知电影是爱情片。 ''' import os from numpy import * import operator def createDataSet(): #导入数据接口 group = array([[1.0, 1.1], [1.0,1.0],[0,0],[0,0.1]]) labels = ['A', 'A', 'B', 'B'] return group, labels ''' 输入参数说明: inX:用于分类的输入向量 dataSet:输入的训练样本集 labels:标签向量 k:用于选择最近邻居的数目 实现思路(kNN核心思想): 对未知类别属性的数据集中的每个点依次执行以下操作 1.计算已知类别数据集中的点与当前点之间的距离 2.按照距离递增次序排序 3.选取与当前点距离最小的k个点 4.确定前k个点所在类别出现频率 5.返回前k个点出现频率最高的类别作为当前点的预测分类 ''' def classify0(inX, dataSet, labels, k): dataSetSize = dataSet.shape[0] #距离计算 diffMat = tile(inX, (dataSetSize,1)) - dataSet #print (diffMat) sqDiffMat = diffMat**2 sqDistances = sqDiffMat.sum(axis=1) distances = sqDistances**0.5 sortedDistIndicies = distances.argsort() #选择距离最小的k个点 classCount={} for i in range(k): voteIlabel = labels[sortedDistIndicies[i]] classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1 #print (classCount.items()) sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True) #print (sortedClassCount) return sortedClassCount[0][0] ''' 上述代码中的距离计算公式:d=sqrt((xA_0-xB_0)^2+(xA_1-xB_1)^2) 这就是传说中的 “欧式距离” 例如,点(0,0)与(1,2)之间的距离计算为:sqrt((1-2)^2+(2-0)^2) 这个可以看作 二维平面上的两点之间的距离计算 重点是这个 如果数据集存在4个特征值,点(1,0,0,1)与(7,6,9,4) sqrt((7-1)^2+(6-0)^2+(9-0)^2+(4-1)^2) 之间的距离计算 疑问:四维空间的距离可以这样计算么? ''' #2.2 使用k近邻算法改进约会网站的配对效果 #将文本记录到转换NumPy的解析程序 import matplotlib import matplotlib.pyplot as plt def file2matrix(filename): fr = open(filename) arrayOLines = fr.readlines() numberOfLines = len(arrayOLines) returnMat = zeros((numberOfLines,3)) #numberOfLines行,3列矩阵 classLabelVector = [] index = 0 for line in arrayOLines: line = line.strip() listFromLine = line.split('\t') returnMat[index,:] = listFromLine[0:3] classLabelVector.append(int(listFromLine[-1])) #classLabelVector.append(listFromLine[-1]) index += 1 return returnMat,classLabelVector #准备数据:归一化数值 newValue=(oldValue-min)/(max-min) #其中min和max分别是数据集中的最小特征值和最大特征值 def autoNorm(dataSet): minVals = dataSet.min(0) maxVals = dataSet.max(0) ranges = maxVals - minVals normDataSet = zeros(shape(dataSet)) m = dataSet.shape[0] normDataSet = dataSet - tile(minVals, (m ,1)) normDataSet = normDataSet/tile(ranges, (m,1)) return normDataSet, ranges, minVals ''' 机器学习算法一个很重要的工作就是评估算法的正确率,通常我们只提供已有数据的90%作为训练样本来训练分类器,而使用其余的10% 数据去测试分类器,检测分类器的正确率。本书后序章节还会介绍一些高级的方法去完成同样的任务,我们这里还是采用最原始的做法。 ''' def datingClassTest(): hoRatio = 0.10 datingDataMat, datingLabels = file2matrix('datingTestSet2.txt') normMat, ranges, minVals = autoNorm(datingDataMat) m = normMat.shape[0] numTestVecs = int(m*hoRatio) errorCount = 0.0 for i in range(numTestVecs): calssifierResult = classify0(normMat[i,:], normMat[numTestVecs:m,:], datingLabels[numTestVecs:m],3) print ("the classifier came back with: %d,the real answer is:%d" % (calssifierResult, datingLabels[i])) if (calssifierResult != datingLabels[i]): errorCount += 1.0 print ("the total error rate is: %f" % (errorCount/float(numTestVecs))) ''' 使用算法,构建完整可用系统 约会网站预测函数 ''' def classifyPerson(): resultList = ['不喜欢的人','魅力一般的人','极具魅力的人'] percentTats = float(input("玩视频游戏所耗时间百分比?")) ffMiles = float(input("每年获得的飞行常客里程数?")) iceCream = float(input("每周消耗的冰淇凌公升数?")) datingDataMat,datingLabels = file2matrix('datingTestSet2.txt') normMat, ranges, minVals = autoNorm(datingDataMat) inArr = array([ffMiles, percentTats, iceCream]) calssifierResult = classify0((inArr-minVals)/ranges, normMat, datingLabels, 3) print ("you will probably like this person: ", resultList[calssifierResult-1]) ''' 2.3示例:手写数字识别系统kNN 实现方法 简述:构造k近邻分类器的手写识别系统。为了简单起见,这里构造的系统只能识别0到9;需要识别的数字已经使用图形处理软件,处理成具有 相同的色彩和大小:宽高是32像素*32像素的黑白图像。尽管采用文本格式存储图像不能有效的利用内存空间,但为了方便理解,我们还是将图像 转换成文本格式。 实现步骤: 1.收集数据:提供文本文件。 2.准备数据:编写img2vector(),将图像格式转换为分类器使用的向量格式。 3.分析数据:在Python命令提示符中检查数据,确保它符合要求。 4.训练算法:此步骤不适用于k-近邻算法。 5.测试算法:编写函数使用提供的部分数据集作为测试样本,测试样本与非测试样本的区别在于测试样本是已经完成分类的数据,如果预测分类与实际 类别不同,则标记为一个错误。 6.使用算法:本例没有完成此步骤,若你感兴趣可以构建完整的应用程序,从图像中提取数字,并完成数字识别,美国的邮件分拣系统就是一个实际运行的类似系统。 ''' def img2vector(filename): returnVect = zeros((1,1024)) fr = open(filename) for i in range(32): lineStr = fr.readline() for j in range(32): returnVect[0, 32*i+j] = int(lineStr[j]) return returnVect def handwritingClassTest(): hwLabels = [] trainingFileList = os.listdir('trainingDigits') m = len(trainingFileList) #m就是有多少个文件(图片) trainingMat = zeros((m,1024)) #32*32 = 1024 把一张图片做成1024大小的一维数组 img2vector() for i in range(m): fileNameStr = trainingFileList[i] fileStr = fileNameStr.split('.')[0] classNumStr = int(fileStr.split('_')[0]) hwLabels.append(classNumStr) trainingMat[i,:] = img2vector('trainingDigits/%s' % fileNameStr) testFileList = os.listdir('testDigits') errorCount = 0.0 mTest = len(testFileList) for i in range(mTest): fileNameStr = testFileList[i] fileStr = fileNameStr.split('.')[0] classNumStr = int(fileStr.split('_')[0]) vectorUnderTest = img2vector('testDigits/%s' % fileNameStr) calssifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3) print ("the classifier came back with %d, the real answer is: %d" % (calssifierResult, classNumStr)) if (calssifierResult != classNumStr): errorCount += 1.0 print ("\nthe total number of errors is: %d" % errorCount) print ("\nthe total error rate is: %f" % (errorCount/float(mTest))) if __name__ == '__main__': #datingDataMat,datingLabels = file2matrix('datingTestSet2.txt') ''' #这个绘图工具还是很有意思的 fig = plt.figure() ax = fig.add_subplot(111) ax.scatter(datingDataMat[:, 1], datingDataMat[:,2]) ax.scatter(datingDataMat[:, 1], datingDataMat[:,2], 15.0*array(datingLabels), 15.0*array(datingLabels)) plt.xlabel('time spent playing video games') plt.ylabel('liters of ice cream consumed per week') plt.show() ''' ''' #特征值归一化 normMat, ranges, minVals = autoNorm(datingDataMat) print (normMat, ranges, minVals) ''' #测试算法准确率 #datingClassTest() #约会网站预测函数 #classifyPerson() #手写数字处理kNN k近邻实现 handwritingClassTest()
通过上述代码,你可以的到的结果
1.绘制特征二维分布图像
datingDataMat,datingLabels = file2matrix('datingTestSet2.txt') #这个绘图工具还是很有意思的 fig = plt.figure() ax = fig.add_subplot(111) ax.scatter(datingDataMat[:, 1], datingDataMat[:,2]) ax.scatter(datingDataMat[:, 1], datingDataMat[:,2], 15.0*array(datingLabels), 15.0*array(datingLabels)) plt.xlabel('time spent playing video games') plt.ylabel('liters of ice cream consumed per week') plt.show()
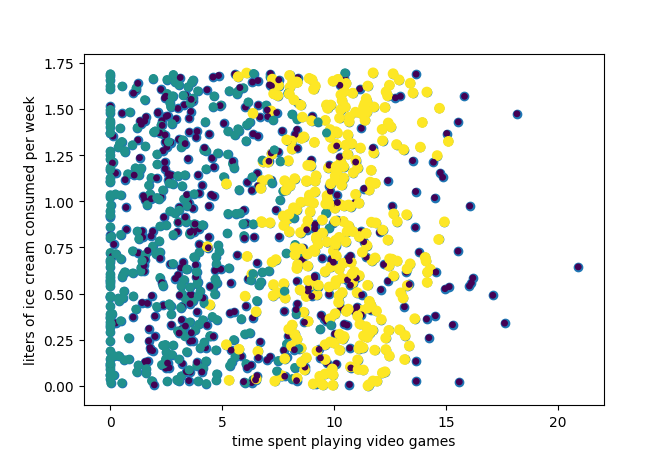
2.约会网站分类结果
#测试算法准确率 datingClassTest()

错误率是0.05,也就是说准确率为95%
3.手动预测要约会的人是否为你喜欢的类型
#约会网站预测函数 classifyPerson()

4.k近邻实现手写数字识别
#手写数字处理kNN k近邻实现 handwritingClassTest()

准确率竟然达到了98.8372%,厉害吧!
还有手写数字的数据集很有意思:

7-3-8-8-9

