

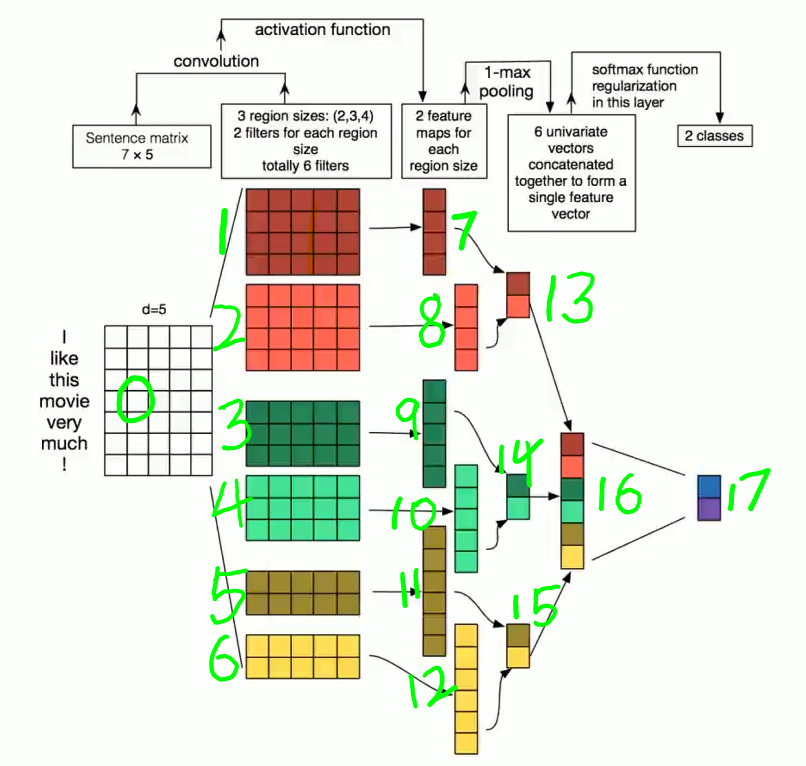
首先看一张图,这是来自炼数成金的讲师Ben关于深度学习框架tensorflow课程中的一张图,textcnn(paper),一般理解了这张图就基本理解了cnn文本分类的基本方法;
简单总结一下:
首先我对这些矩阵数据从0-17做了标号,方便后续的说明;
其中0为输入数据“I like this movie very much !”,nlp中首先会将要处理的一句话转换为矩阵的表示,,开始矩阵的值是随机初始化的,上图中矩阵维度d=5,用5个0-1的浮点数组表示一个词的向量;
编号1、2、3、4、5、6为3种尺寸(联想分词中的ngram为2,3,4)的卷积核,每个尺寸两个(可以联想到图像的channel=2),其中上图的卷积核宽度为5,(1、2),(3、4),(5、6)的维度两两相同;卷积核1从上向下与0相乘,首先是0的前四列(I like this movie)与1相乘,得到7的第一行(就一个值),然后0的第二列到第五列(like this movie very)与1相乘,得到7的第二行...依次类推,我们就得到了7、8、9、10、11、12的卷积结果
再经过max pooling,取7最大的值及8中最大的值组成13,取9、10中各自最大的值组成14,取11、12中各自最大的值组成15,最后将13、14、15拼接成16,整个卷积、池化这些特征提取的工作就完成了,最后在16和17之间加上一层全连接,17表示网络的输出为2,也就是二分类;到这里整个分类工程基本搭建好了。
代码实现:
这里我们参考google brain的工程师在github上的cnn-text-classification-tf代码
上面链接下载解压之后可直接运行,代码逻辑也较清晰;之后有时间会把训练及测试数据改为中文
如果想要实现textcnn中文文本分类,请点击这个text-cnn代码链接,或者去github上查找你所想要的工程代码。
上面的代码我已验证过,可以实现,效果还是很好的;同样你也可以查找下目前较流行的bert文本分类的实现方法。
目录:
- tensorflow简介、目录
- tensorflow中的图(02-1)
- tensorflow变量的使用(02-2)
- tensorflow中的Fetch、Feed(02-3)
- tensorflow版helloworld---拟合线性函数的k和b(02-4)
- tensorflow非线性回归(03-1)
- MNIST手写数字分类simple版(03-2)
- 二次代价函数、交叉熵(cross-entropy)、对数似然代价函数(log-likelihood cost)(04-1)
- 多层网络通过防止过拟合,增加模型的准确率(04-2)
- 修改优化器进一步提升准确率(04-3)
- 手写数字识别-卷积神经网络cnn(06-2)
- 循环神经网络rnn与长短时记忆神经网络简述(07-2)
- 循环神经网络lstm代码实现(07-3)
- tensorflow模型保存和使用08
- 下载inception v3 google训练好的模型并解压08-3
- 使用inception v3做各种图像分类识别08-4
- word2vec模型训练简单案例
- word2vec+textcnn文本分类简述及代码

