数据挖掘1:K-means均值聚类算法
一.K-means均值聚类算法原理
对于给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇。让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大。
如果用数据表达式表示,假设簇划分为(C1,C2,…Ck),则我们的目标是最小化平方误差E:
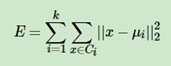
其中μi是簇Ci的均值向量,有时也称为质心,表达式为:
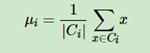
二.K-means均值聚类算法步骤:
数据样本间的相似性度量:欧式距离
评价聚类性能的准则函数:最小误差准则函数
输入:簇的数目k和包含n个对象的数据库
输出:k个簇,使平方误差准则最小
设置初始类别中心和簇数
根据簇中心对数据进行簇划分
重新计算当前簇划分下每个簇的中心
在得到簇中心下继续进行簇划分
如果连续两次的簇划分结果不变(即最小误差函数的值达到最优)则停止算法;否则一直循环
实验源码:
# 导入第三方模块
import random
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from mpl_toolkits.mplot3d import Axes3D # 空间三维画图
def load_data(path):
df = pd.read_excel(path)
column_count = df.shape[1]
df_li = df.values.tolist()
return df_li,column_count
# 计算欧式距离,并且存储到数组中
def distance(dataSet,centroids,k):
'''
利用np.tile()将dataSet中的元素扩展到与centroids同一个shape
也就是算出dataSet中的每一个元素分别与centroids的disatcne,
存储到一个列表中,并将这个列表存储到原先设定的空列表中,最后
将存储完数据的列表转换为数组格式
需要明确的是,分成几簇,必定会有k个质心,扩展成k维后,能分别
计算数据集中的某一个元素与这k个质心的距离
'''
dis_list = []
for data in dataSet:
diff = (np.tile(data,(k,1)))-centroids
squaredDiff = diff ** 2
squaredDist = np.sum(squaredDiff,axis=1)
distance = squaredDist ** 0.5
dis_list.append(distance)
dis_list = np.array(dis_list)
return dis_list
# 计算质心,并且返回质心变化量
def Centroids_Init(dataSet,centroids,k):
# 首先计算初始化质心与数据集元素之间的距离
dis_list = distance(dataSet,centroids,k)
# 根据第一次距离计算进行分类,并计算出新的质心
minDistIndices = np.argmin(dis_list,axis=1) #axis 表示每行最小值下标
# #DataFrame(dataSet)对DataSet分组
# groupby(min)按照min进行统计分类
# mean()对分类结果求均值
newCentroids = pd.DataFrame(dataSet).groupby(minDistIndices).mean()
newCentroids = newCentroids.values
# 计算新质心与初始化质心的变化量
centroids_change = newCentroids - centroids
return centroids_change,newCentroids
# 使用K-means进行分类
def k_means(dataSet,k):
# 随机获取质心,作初始化处理
# 从数据集中随机取k个元素作为质心
centroids = random.sample(dataSet,k)
centroids_change,newCentroids = Centroids_Init(dataSet,centroids,k)
# 不断更新质心,直到centroids_change为0,表示聚类中心已经确定
while np.any(centroids_change != 0 ):
centroids_change,newCentroids = Centroids_Init(dataSet,newCentroids,k)
# 将矩阵转换为列表,并排序
centroids = sorted(newCentroids.tolist())
# 根据质心来聚类
cluster = []
# 计算欧式距离
dis_list = distance(dataSet,centroids,k)
minDistIndices = np.argmin(dis_list,axis=1)
for i in range(k):
# 根据k个质心创建k个空列表,表示k个簇
cluster.append([])
for i,j in enumerate(minDistIndices):
# 将dataSet中的元素分类到指定的列表中
cluster[j].append(dataSet[i])
return centroids,cluster
# 数据可视化
def visualization(dataSet,centroids):
if column_count == 2:
for i in range(len(dataSet)):
plt.scatter(dataSet[i][0],dataSet[i][1],marker = 'o',color = 'blue',s = 40,label = '原始点')
for j in range(len(centroids)):
plt.scatter(centroids[j][0],centroids[j][1],marker = 'x',color = 'red',s = 50,label = '质心')
plt.show()
elif column_count == 3:
fig = plt.figure()
ax = Axes3D(fig)
for i in range(len(dataSet)):
ax.scatter(dataSet[i][0],dataSet[i][1],dataSet[i][2],marker = 'o',color = 'blue',s = 40,label = '原始点')
for j in range(len(centroids)):
ax.scatter(centroids[j][0],centroids[j][1],centroids[j][2],marker = 'x',color = 'red',s = 50,label = '质心')
ax.set_zlabel('Z', fontdict={'size': 15, 'color': 'red'})
ax.set_ylabel('Y', fontdict={'size': 15, 'color': 'red'})
ax.set_xlabel('X', fontdict={'size': 15, 'color': 'red'})
plt.show()
else:
print('数据维度过高,无法进行可视化')
if __name__ == '__main__':
path = input(r'请输入文件的路径:')
dataSet,column_count = load_data(path)
print(dataSet)
print('-'*30,'读取成功','-'*30)
k = int(input('请输入簇数:'))
centroids,cluster = k_means(dataSet,k)
print('质心为:%s'%centroids)
print('集群为:%s'%cluster)
visualization(dataSet,centroids)
三.运行截图
分别利用三维数据集和二维数据对算法进行测试
三维数据集:大连妇科医院哪家好 https://m.120ask.com/zhenshi/dlfk/
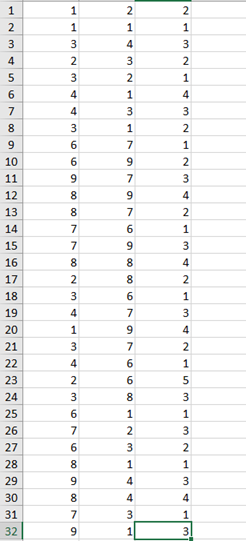
运行结果:

二维数据集:
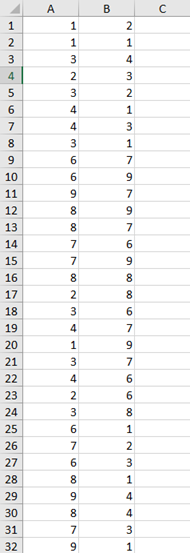
运行结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号