TensorFlow2教程20:自编码器
自动编码器的两个主要组成部分; 编码器和解码器
编码器将输入压缩成一小组“编码”(通常,编码器输出的维数远小于编码器输入)
解码器然后将编码器输出扩展为与编码器输入具有相同维度的输出
换句话说,自动编码器旨在“重建”输入,同时学习数据的有限表示(即“编码”)
1.导入数据
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = x_train.reshape((-1, 28*28)) / 255.0
x_test = x_test.reshape((-1, 28*28)) / 255.0
print(x_train.shape, ' ', y_train.shape)
print(x_test.shape, ' ', y_test.shape)
(60000, 784) (60000,)
(10000, 784) (10000,)
2.简单的自编码器
code_dim = 32
inputs = layers.Input(shape=(x_train.shape[1],), name='inputs')
code = layers.Dense(code_dim, activation='relu', name='code')(inputs)
outputs = layers.Dense(x_train.shape[1], activation='softmax', name='outputs')(code)
auto_encoder = keras.Model(inputs, outputs)
auto_encoder.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
inputs (InputLayer) [(None, 784)] 0
_________________________________________________________________
code (Dense) (None, 32) 25120
_________________________________________________________________
outputs (Dense) (None, 784) 25872
=================================================================
Total params: 50,992
Trainable params: 50,992
Non-trainable params: 0
_________________________________________________________________
keras.utils.plot_model(auto_encoder, show_shapes=True)
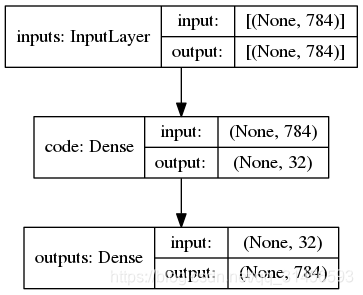
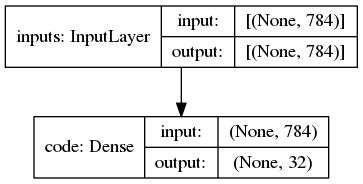
encoder = keras.Model(inputs,code)
keras.utils.plot_model(encoder, show_shapes=True)
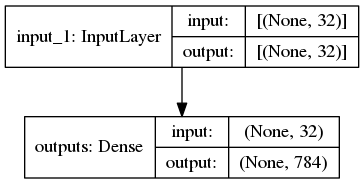
decoder_input = keras.Input((code_dim,))
decoder_output = auto_encoder.layers[-1](decoder_input)
decoder = keras.Model(decoder_input, decoder_output)
keras.utils.plot_model(decoder, show_shapes=True)
无锡妇科医院哪家好 http://www.xasgfk.cn/
auto_encoder.compile(optimizer='adam',
loss='binary_crossentropy')
训练模型
%%time
history = auto_encoder.fit(x_train, x_train, batch_size=64, epochs=100, validation_split=0.1)
Train on 54000 samples, validate on 6000 samples
Epoch 1/100
Epoch 100/100
54000/54000 [==============================] - 2s 45us/sample - loss: 0.6715 - val_loss: 0.6688
CPU times: user 6min 53s, sys: 23.2 s, total: 7min 16s
Wall time: 4min 24s
encoded = encoder.predict(x_test)
decoded = decoder.predict(encoded)
import matplotlib.pyplot as plt
plt.figure(figsize=(10,4))
n = 5
for i in range(n):
ax = plt.subplot(2, n, i+1)
plt.imshow(x_test[i].reshape(28,28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(2, n, n+i+1)
plt.imshow(decoded[i].reshape(28,28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号