caffe核心代码分析
代码来源 :https://github.com/BVLC/caffe
caffe是伯克利BVLC实验室使用c++11开发的开源深度学习框架,其代码处处体现封装、继承、多态的面向对象特性,并且用到了单例模式、工厂模式、流水线模式等多种设计模式,较多的体现了effective c++中提及的内容,适合进行分析。由于caffe代码量超过五万行,其中即便是核心代码也超过三万行,因此下面将有针对性的对核心架构、面向对象特性着重分析。
1 整体架构分析
核心代码部分工程结构如下图所示:

1.1 caffe核心组件组合关系
caffe代码的层次结构图如下所示,可以分为核心代码、接口层、依赖库和工具、工程编译和管理、硬件交互工具等几个块。不同于其他的一些框架,Caffe没有采用符号计算的模式进行编写,整体上的架构以系统级的抽象为主。另有一点特色:Caffe中用到的很多结构化数据以Protocol Buffers格式存储,相关协议定义文件为src/caffe/proto/caffe.proto。
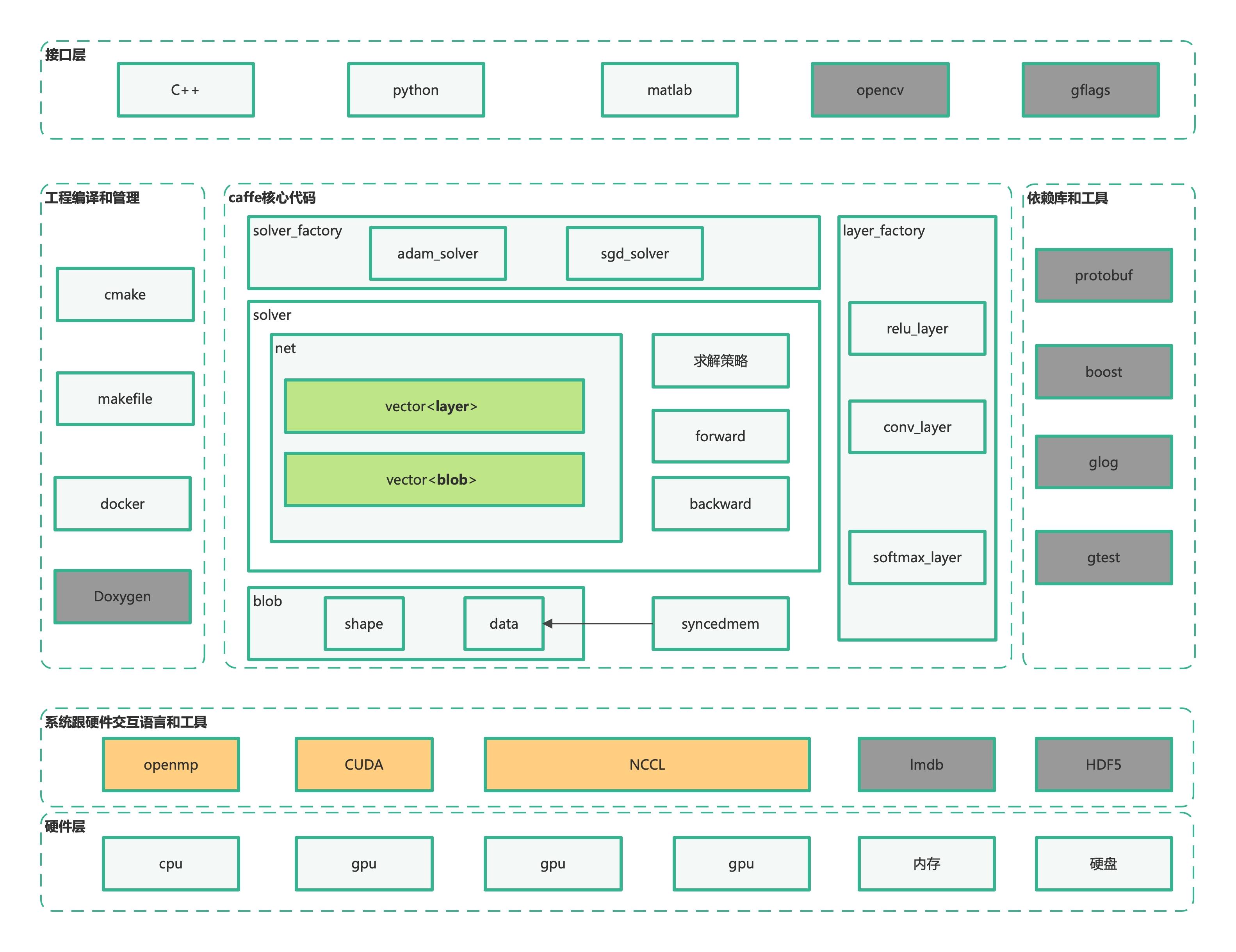
核心代码中的核心,就是其blob、layer、net、solver这四大组件。前三者为神经网络的结构组件,分别对应数据块,层和网络;Solver为求解器。由于caffe属于深度学习框架,这四个组件自然是按照深度学习的工作流程组织的。将深度学习预处理,配置网络结构、训练、测试的流程,与caffe的四大基本结构结合,就可以得到下图。
其中:
-
Blob (/include/blob.hpp):用于数据的保存、交换和操作。它是Caffe基础存储结构,是Layer, Net, Solver几个组件间交互的基本单元。无论是输入数据、层之间传递的数据(top & bottom blob)、还是层中的参数(param blob),都是以Blob形式封装的。同时 Blob 数据也支持在 CPU 与 GPU 上存储,能够在两者之间做同步。
-
主要成员:
data_ -->数据 diff_ -->梯度 shape_data_ -->GPU维度信息 shape_ --> 维度信息 count -->元素个数 capacity_ -->当前分配的内存容量
-
-
Layer (/include/layer.hpp):神经网络网络中各种计算单元的接口。用于模型和计算的基础,代表网络中的层。大多数层都会接收输入(bottom blob),通过某种类型的操作(如卷积,池化,全连接),给出输出(top blob)。有众多派生类,代表神经网络中的不同组件。
-
主要成员:
blobs_ -->层中参数 layer_propagate_ -->是否需要计算梯度 phase_ -->训练/测试阶段
-
-
Net (/include/net.hpp):整合连接layers,代表网络。它将layer连接在一起形成一张计算图。训练的过程会不断调用Forward(), Backward()函数。该函数调用的两个函数-Forward()和Backward()分别是对网络进行一次前向传播和后向传播。
-
主要成员:
layers_ -->网络层列表 blobs_ -->网络层输出结果列表 params_ -->参数列表 learnable_params_ -->需要学习的参数列表
-
-
Solver (include/solver.hpp)求解器,各种优化器的接口。它主要负责组织和协调网络结构的构建与初始化,模型参数优化(训练),模型的验证测试等。有众多派生类,代表神经网络的不同优化器。
-
主要成员:
net_ -->网络 test_nets_ -->测试网络 losses_ -->损失值 iter_ -->迭代次数
-
1.2 类图和整体架构
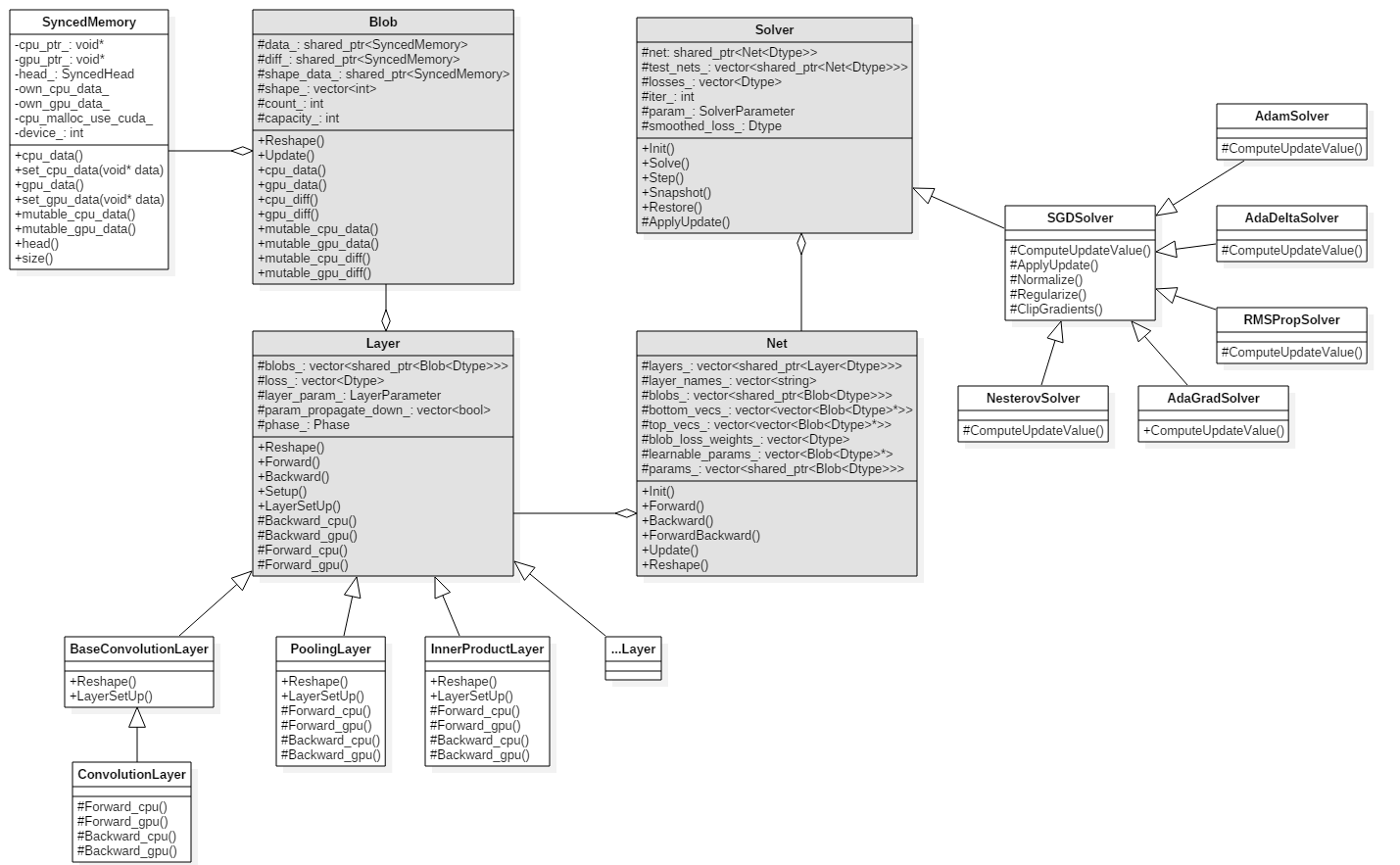
按照上面所述的组合关系,结合代码,可以画出核心类的UML类图:
-
不难发现,整体的工程架构是按照
SyncedMemory->Blob->Layer->Net->Solver->Py2PSync的层次结构组织的,其中,Layer和Solver则体现了多态性,派生出众多子类,使用工厂模式实现。 -
此外,在layer中,对于一些特殊种类的层还会有自己的抽象类,例如:ConvolutionLayer派生自BaseConvolutionLayer。
1.3 顺序图和caffe执行流程
在核心组件组合关系一节中,我们分析了caffe的大概流程,主要有初始化预处理、配置网络结构、训练、测试四个方面。这几个步骤的大致流程及对应的UML顺序图如下。
1.3.1 初始化并配置网络结构
-
主函数入口在
tools/caffe.cpp,主要有以下几个步骤:-
1:使用RegisterBrewFunction宏在程序载入时通过类的实例化来将函数注册到g_brew_map这个查找表中,通过ReadSolverParamsFromTextFileOrDie()函数从solver配置文件中把数据读入并填入SolverParameter结构。
-
2:配置GPU,CPU,设置计算模式。调用
Caffe::set_mode(Caffe::CPU)或者Caffe::set_mode(Caffe::GPU)。 -
3:通过
SolverRegistry::CreateSolver()根据solver配置文件中指定的优化类型创建Solver实例。这一步中完成了Solver,Net,Layer, Blob等很多创建与初始化工作。将在接下来进一步讨论。 -
4:调用
Solver::Solve()开始训练过程。![在这里插入图片描述]()
-
-
之前提到,在solver的构造函数中,完成了对网络结构和参数的配置。它调用到
Solver::Init()来初始化,通过InitTrainNet()和InitTestNets()两个函数来分别初始化训练和测试网络。大致流程如下:-
solver的配置文件中只有net参数,这里调用ReadNetParamsFromTextFileOrDie()函数来载入指定的网络结构描述文件,读入到NetParameter结构中。然后设置NetState(包括phase, level, stage信息),最后写入到NetParameter结构中。继而通过它来初始化Net对象。
-
new一个网络,利用
Net::Init()初始化网络。- 函数FilterNet()中处理网络结构描述文件中的过虑规则。根据前面设定的信息,对网络结构进行过滤处理。
函数InsertSplits()将那些共享的bottom blob用SplitLayer(一路输入,多路输出)替换。 - 从底层到高层逐层构建网络。对于网络结构中的每层,执行以下操作:
- 对于该层的所有bottom blob,调用AppendBottom()进行进行处理。添加一个下层到网络中。
- 对于该层所有的top blob,调用AppendTop()函数进行处理。添加一个上层到网络中。
- 调用当前层的SetUp()函数。包括校验底层/顶层数量,初始化网络层,计算并设置输出大小。
- 对于该层中所有的param blob,调用AppendParam()函数来处理。记录名字和blob对应的index。载入权值。
![在这里插入图片描述]()
- 函数FilterNet()中处理网络结构描述文件中的过虑规则。根据前面设定的信息,对网络结构进行过滤处理。
-


1.3.2 训练流程
-
调用
Solver::solve()函数开始训练。调用Step()函数进行训练,参数为需要迭代的次数。该函数为训练的主循环。循环的index从iter_到iter_+iters。循环次数由参数iters指定。 -
调用
Net::ClearParamDiffs()函数初始化参数的梯度信息。 -
ForwardBackward()函数完成一次前向和后向传递。该函数会按照层次结构递归地调用Layer,Blob的前向反向传播主体。最后记录平均loss,并用UpdateSmoothedLoss()函数做平滑。
-
调用Solver的虚函数
Solver::ApplyUpdate()更新权值参数值。- 通过GetLearningRate()函数计算学习率
- 通过ClipGradients()函数来clip梯度
- 调用Normalize(),Regularize()和ComputeUpdateValue()三个函数,使用优化方法计算权值参数更新量。
- 更新权值参数。
![在这里插入图片描述]()

2 封装性、继承与多态
2.1 封装
以下讨论以Blob类作为例子。Blob的主要代码分布在blob.hpp头文件与Blob.cpp文件中,体现了架构设计与实现的分离。Blob类的模板类头文件blob.hpp部分代码如下:
template <typename Dtype> //模板类,虚拟类型Dtype
class Blob {
public:
Blob() //构造函数:初始化列表 {空函数体}
: data_(), diff_(), count_(0), capacity_(0) {}
//当构造函数被声明 explicit 时,编译器将不使用它作为转换操作符。
/// @brief Deprecated; use <code>Blob(const vector<int>& shape)</code>.
explicit Blob(const int num, const int channels, const int height,
const int width); //可以通过设置数据维度(N,C,H,W)初始化
//const 传递过来的参数在函数内不可以改变(无意义,因为本身就是形参)
//const引用参数在函数内为常量不可变
explicit Blob(const vector<int>& shape); //也可以通过传入vector<int>直接传入维数
...
//内联函数 通过内联函数,编译器不需要跳转到内存其他地址去执行函数调用,也不需要保留函数调用时的现场数据。
// const 成员函数,任何不会修改数据成员的函数都应该声明为const 类型。
inline const vector<int>& shape() const { return shape_; }
inline int shape(int index) const { //根据索引返回维数,对于维数(N,C,H,W),shape(0)返回N,shape(-1)返回W。
return shape_[CanonicalAxisIndex(index)];
}
inline int count() const { return count_; } //返回Blob维度数,对于维数(N,C,H,W),返回N×C×H×W
//对于维数(N,C,H,W),count(0, 3)返回N×C×H
inline int count(int start_axis, int end_axis) const {
CHECK_LE(start_axis, end_axis);
CHECK_GE(start_axis, 0);
CHECK_GE(end_axis, 0);
CHECK_LE(start_axis, num_axes());
CHECK_LE(end_axis, num_axes());
int count = 1;
for (int i = start_axis; i < end_axis; ++i) {
count *= shape(i);
}
return count;
}
//对于维数(N,C,H,W),count(1)返回C×H×W
inline int count(int start_axis) const {
return count(start_axis, num_axes());
}
...
private:
shared_ptr<SyncedMemory> data_; //存储前向传递数据
shared_ptr<SyncedMemory> diff_; //存储反向传递梯度
shared_ptr<SyncedMemory> shape_data_;
vector<int> shape_; //参数维度
int count_; //Blob存储的元素个数(shape_所有元素乘积)
int capacity_;//当前Blob的元素个数(控制动态分配)
DISABLE_COPY_AND_ASSIGN(Blob);
}; // class Blob
其封装性主要体现在以下几点:
- 数据抽象:只向外界提供关键信息,并隐藏其后台的实现细节,即只表现必要的信息而不呈现细节。例如,类Blob的内部成员变量均为private,无法被外部直接修改,而只提供
inline int shape(int index) const,inline int count()等外部接口来提供对类成员变量的访问。这也符合effective c++中的将成员变量声明为private。 - 使用模板类template。template允许我们处理问题的逻辑从不同的数据类型中抽离出来,形成容器和算法。可以很好的创建泛型类。caffe中,
template <typename Dtype> class Blob {...}的写法就应用了模板类形成头文件。这样体现了封装性,较好的封装了Blob的内部结构和逻辑,同时Dtype作为虚拟数据类型,也体现出参数化的多样性,可以更好实现复用。 - 模板类头文件的写法,让架构设计与实现分离,也是封装。
- caffe向外封装了c++,python,matlab接口。
- caffe主体是c++开发的,其c++接口是把所有头文件都集合到了include下。
- python接口借用boost::python实现。
- 这也体现了一定程度的封装性。
- 使用抽象类实现接口,也一定程度的体现了多态性。而这样做的主要目的是为了多态,在下面的讨论中,我们就以Layer基类和子类为例讨论多态与继承。
2.2 继承与多态
下面包含继承多态、重载、构造析构、虚函数等多种关键思想和语法,主要用Layer基类和子类的代码来说明。
2.2.1 caffe中的继承与多态
- Layer和Solver都较好的体现了继承与多态。Layer类和Solver类都是caffe里给定的基类,定义了各种虚函数、显式构造函数、虚析构函数,属于抽象类,不能实例化。各种具体的层或者优化器,比如conv_layer,要先继承基类Layer,重写其核心方法(在基类中表现为虚函数)如Backward_gpu(),并保证实现所有虚函数,才能正常实例化。
- 由于c++的多态性,在实例化一种具体的layer时,利用了工厂模式得到指向基类Layer的指针。这么做体现了oop中的依赖倒转原则,便于自上而下的进行数据管理。尽管layer是一个指向基类Layer类型的指针,通过layer这个智能指针来调用各个成员函数会调用到各个子类(比如conv_layer等)实际实现的函数。这就是多态性的体现。
- 此外,重载(overloading),模板类实例化等也都体现出多态性,将在下面分析。
2.2.2 Layer基类代码分析
-
抽象类
-
Layer.hpp中的Layer类就是抽象类。 称带有纯虚函数的类为抽象类。抽象类的主要作用是将有关的操作作为结果接口组织在一个继承层次结构中,由它来为派生类提供一个公共的根,派生类将具体实现在其基类中作为接口的操作。所以派生类实际上刻画了一组子类的操作接口的通用语义,这些语义也传给子类,子类可以具体实现这些语义,也可以再将这些语义传给自己的子类。
-
抽象类只能作为基类来使用,其纯虚函数的实现由派生类给出。如果派生类中没有重新定义纯虚函数,而只是继承基类的纯虚函数,则这个派生类仍然还是一个抽象类。如果派生类中给出了基类纯虚函数的实现,则该派生类就不再是抽象类了,它是一个可以建立对象的具体的类。
-
抽象类Layer的部分代码结构:
template <typename Dtype> class Layer { public: // 显示的构造函数不需要重写,任何初始工作在SetUp()中完成 // 构造方法只复制层参数说明的值,如果层说明参数中提供了权值和偏置参数,也复制 // 继承自Layer类的子类都会显示的调用Layer的构造函数 explicit Layer(const LayerParameter& param) : layer_param_(param), is_shared_(false) { ... } // 虚析构 virtual ~Layer() {} // layer 初始化设置 void SetUp(const vector<Blob<Dtype>*>& bottom, //在模型初始化时重置 layers 及其相互之间的连接 ; const vector<Blob<Dtype>*>& top) { InitMutex(); CheckBlobCounts(bottom, top); LayerSetUp(bottom, top); Reshape(bottom, top); SetLossWeights(top); } /** @brief Using the CPU device, compute the layer output. * 纯虚函数,子类必须实现,使用cpu经行前向计算 */ virtual void Forward_cpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) = 0; virtual void Backward_cpu(const vector<Blob<Dtype>*>& top, const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) = 0; ......//各种虚函数定义 protected: /** The protobuf that stores the layer parameters */ //protobuf文件中存储的layer参数,从protocal buffers格式的网络结构说明文件中读取 //protected类成员,构造函数中初始化 LayerParameter layer_param_; Phase phase_; vector<shared_ptr<Blob<Dtype> > > blobs_; vector<bool> param_propagate_down_; vector<Dtype> loss_; private: bool is_shared_; shared_ptr<boost::mutex> forward_mutex_; }可见,其主要部分有:显式构造函数,初始化函数,虚析构函数,各种虚函数、纯虚函数。
-
-
显式构造函数
-
某些时候,explicit 可以有效得防止构造函数的隐式转换带来的错误或者误解,explicit只对构造函数起作用,用来抑制隐式转换。
-
Layer的子类不需要实现自己的构造函数,所有的set up操作应该在后面的SetUp函数中完成,构造函数中仅将纳入LayerParameter、设置pahse_以及写入初始网络权重。所以,Layer构造函数只起到传递参数的作用,实际的初始化将使用SetUp()函数利用多态在子类中实现。 -
// 构造方法只复制层参数说明的值,如果层说明参数中提供了权值和偏置参数,也复制 // 继承自Layer类的子类都会显示的调用Layer的构造函数 explicit Layer(const LayerParameter& param) : layer_param_(param), is_shared_(false) { ... }
-
-
初始化
-
SetUp是Layer基类最为重要的成员函数之一,顾名思义,其负责完成层的基础搭建工作。在Net初始化时会顺序调用每个层的SetUp函数来搭建网络,见Net::Init,Net::Init利用多态在一个循环中完成所有层的搭建。// in Net::Init for (int layer_id = 0; layer_id < param.layer_size(); ++layer_id) { // …… // After this layer is connected, set it up. layers_[layer_id]->SetUp(bottom_vecs_[layer_id], top_vecs_[layer_id]); // …… } // in net.hpp /// @brief Individual layers in the net vector<shared_ptr<Layer<Dtype> > > layers_; -
SetUp在设计时就采用了template method设计思想,基类Layer为所有派生类的SetUp定义好了流程框架,先检查bottom和top的blob数量是否正确,然后调用LayerSetUp为完成层“个性化”的搭建工作(如卷积层会设置pad、stride等参数),再根据层自己定义的操作以及bottom的shape去计算top的shape,最后根据loss_weight设置topblob在损失函数中的权重。其中,Reshape为纯虚函数,子类必须自己实现,CheckBlobCounts和LayerSetUp为虚函数,提供了默认实现,子类也可以定义自己的实现。一般,SetUp的执行顺序为:- 进入父类的
SetUp函数 - 执行父类的
CheckBlobCounts,在这个函数中会执行子类的ExactNumBottomBlobs等函数 - 执行子类的
LayerSetUp - 执行子类的
Reshape - 执行父类的
SetLossWeights - 退出父类的
SetUp函数
- 进入父类的
-
in Layer.hpp // layer 初始化设置 void SetUp(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) { CheckBlobCounts(bottom, top); LayerSetUp(bottom, top); Reshape(bottom, top); SetLossWeights(top); } // 检查输出输出的blobs的个数是否在给定范围内 virtual void CheckBlobCounts(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) { // 实现具体省略 } /* *此方法执行一次定制化的层初始化,包括从layer_param_读入并处理相关的层权值和偏置参数, * 调用Reshape函数申请top blob的存储空间,由派生类重写*/ virtual void LayerSetUp(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) {} /* This method should reshape top blobs as needed according to the shapes * of the bottom (input) blobs, as well as reshaping any internal buffers * and making any other necessary adjustments so that the layer can * accommodate the bottom blobs. */ virtual void Reshape(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) = 0; /** * Called by SetUp to initialize the weights associated with any top blobs in * the loss function. Store non-zero loss weights in the diff blob. */ inline void SetLossWeights(const vector<Blob<Dtype>*>& top) { const int num_loss_weights = layer_param_.loss_weight_size(); //...// } -
SetUp的调用关系如上面的代码所示。
-
-
重载overloading
inline int offset(const int n, const int c = 0, const int h = 0, const int w = 0) const { //计算物理偏移量,(n,c,h,w)的偏移量为((n∗C+c)∗H+h)∗W+w CHECK_GE(n, 0); CHECK_LE(n, num()); CHECK_GE(channels(), 0); CHECK_LE(c, channels()); CHECK_GE(height(), 0); CHECK_LE(h, height()); CHECK_GE(width(), 0); CHECK_LE(w, width()); return ((n * channels() + c) * height() + h) * width() + w; } inline int offset(const vector<int>& indices) const { CHECK_LE(indices.size(), num_axes()); int offset = 0; for (int i = 0; i < num_axes(); ++i) { offset *= shape(i); if (indices.size() > i) { CHECK_GE(indices[i], 0); CHECK_LT(indices[i], shape(i)); offset += indices[i]; } } return offset; }重载, 即同名函数, 不同参数。
-
析构函数与虚析构
-
在有动态分配堆上内存的时候,析构函数必须是虚函数,但没有必要是纯虚的。
-
析构函数应当是虚函数,将调用相应对象类型的析构函数,因此,如果指针指向的是子类对象,将调用子类的析构函数,然后自动调用基类的析构函数。
-
// 虚析构 virtual ~Layer() {} -
不仅仅是caffe,其他C++项目开发的时候,用来做基类的类的析构函数一般都是虚函数。这是为什么呢?
- 一般情况下类的析构函数里面都是释放内存资源,而析构函数不被调用的话就会造成内存泄漏。所以虚析构函数做是为了当用一个基类的指针删除一个派生类的对象时,派生类的析构函数会被调用,从而释放内存空间。
- 当然,并不是要把所有类的析构函数都写成虚函数。因为当类里面有虚函数的时候,编译器会给类添加一个虚函数表,里面来存放虚函数指针,这样就会增加类的存储空间。所以,只有当一个类被用来作为基类的时候,才把析构函数写成虚函数。
-
-
虚函数
下面的例子显示了Layer类中的部分虚函数和纯虚函数。
/** @brief Using the CPU device, compute the layer output. * 纯虚函数,子类必须实现,使用cpu经行前向计算 */ virtual void Forward_cpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) = 0; /** * @brief Using the GPU device, compute the layer output. * Fall back to Forward_cpu() if unavailable. */ /* void函数返回void函数 * 为什么这么设置,是为了模板的统一性 * template<class T> * T default_value() * { return T(); * } * 其中T可以为void */ virtual void Forward_gpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) { // LOG(WARNING) << "Using CPU code as backup."; return Forward_cpu(bottom, top); } /** * @brief Using the CPU device, compute the gradients for any parameters and * for the bottom blobs if propagate_down is true. * 纯虚函数,派生类必须实现 */ virtual void Backward_cpu(const vector<Blob<Dtype>*>& top, const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) = 0; virtual void Backward_gpu(const vector<Blob<Dtype>*>& top, const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) { // LOG(WARNING) << "Using CPU code as backup."; Backward_cpu(top, propagate_down, bottom); }- 对于虚函数来说,父类和子类都有各自的版本。由多态方式调用的时候动态绑定。
- 实现了纯虚函数的子类,该纯虚函数在子类中就变成了虚函数,子类的子类即孙子类可以覆盖该虚函数,由多态方式调用的时候动态绑定。
- 虚函数是C++中用于实现多态(polymorphism)的机制。核心理念就是通过基类访问派生类定义的函数。
- 友元不是成员函数,只有成员函数才可以是虚拟的,因此友元不能是虚拟函数。但可以通过让友元函数调用虚拟成员函数来解决友元的虚拟问题。
2.2.3 模板类的实例化
模板类在实例化时需要指定数据类型。caffe利用宏实例化为不同种类的数据类型,也是泛型和多态的体现之一。
实例化宏定义如下:
// Instantiate a class with float and double specifications.
#define INSTANTIATE_CLASS(classname) \
char gInstantiationGuard##classname; \
template class classname<float>; \
template class classname<double>
3 其他关键语法分析
上面的分析已经涉及了继承多态封装、重载、构造析构、虚函数、模板、
3.1 enum与状态机
下举一例:
SyncedMemory是caffe中基本数据结构Blob的组成方式,属于主存管理类的代码。在caffe的主存模型中,采用自动机进行管理。设有4种状态,以enum的形式定义于类SyncedMemory中:
enum SyncedHead { UNINITIALIZED, HEAD_AT_CPU, HEAD_AT_GPU, SYNCED };
这四种状态基本会被四个应用函数触发:cpu_data()、gpu_data()、mutable_cpu_data()、mutable_gpu_data()。在它们之上,有四个状态转移函数:to_cpu()、to_gpu()、mutable_cpu()、mutable_gpu()。前两个状态转移函数用于未进入Synced状态之前的状态机维护,后两个用于从Synced状态中打破出来。状态转移图如下:
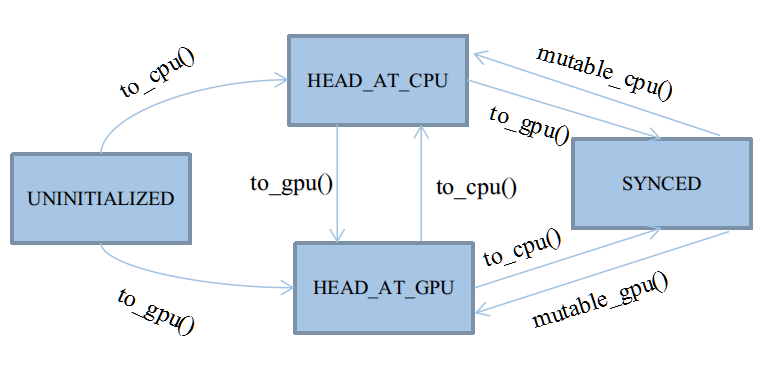
以to_gpu()函数为例,转移代码如下:
inline void SyncedMemory::to_gpu() {
#ifndef CPU_ONLY
switch (head_) {
case UNINITIALIZED:
CUDA_CHECK(cudaGetDevice(&gpu_device_));
CUDA_CHECK(cudaMalloc(&gpu_ptr_, size_));
caffe_gpu_memset(size_, 0, gpu_ptr_);
head_ = HEAD_AT_GPU;
own_gpu_data_ = true;
break;
case HEAD_AT_CPU:
if (gpu_ptr_ == NULL) {
CUDA_CHECK(cudaGetDevice(&gpu_device_));
CUDA_CHECK(cudaMalloc(&gpu_ptr_, size_));
own_gpu_data_ = true;
}
caffe_gpu_memcpy(size_, cpu_ptr_, gpu_ptr_);
head_ = SYNCED;
break;
case HEAD_AT_GPU:
case SYNCED:
break;
}
#else
NO_GPU;
#endif
}
3.2 const
-
const不止时常量,const 更大的魅力是它可以修饰函数的参数、返回值,甚至函数的定义体。const 是constant 的缩写,“恒定不变”的意思。被const 修饰的东西都受到强制保护,可以预防意外的变动,能提高程序的健壮性。“effective c++”建议:“Use const whenever you need”。
-
const修饰参数
-
const 只能修饰输入参数:如果输入参数采用“指针传递”,那么加const 修饰可以防止意外地改动该指针,起到保护作用。
-
如果输入参数采用“值传递”,由于函数将自动产生临时变量用于复制该参数,该输入参数本来就无需保护,所以不要加const 修饰。
-
caffe中,创建Net类时候的初始化
数据成员root_net_动作就应用了const修饰参数template <typename Dtype> Net<Dtype>::Net(const string& param_file, Phase phase, const Net* root_net):root_net_(root_net) { NetParameter param; ReadNetParamsFromTextFileOrDie(param_file, ¶m); param.mutable_state()->set_phase(phase); Init(param); } -
const Net* const root_net_;- 左边的底层const表示指针所指向的对象是个常量。
- 右边的顶层const表示指针本身是个常量。
-
3.3 inline
上面的代码中(尤其是基类或者模板类的代码)多次出现inline,这里就不贴代码了。
使用内联函数时应注意以下几个问题:
- 在一个文件中定义的内联函数不能在另一个文件中使用。它们通常放在头文件中共享。
- 内联函数应该简洁,只有几个语句,如果语句较多,不适合于定义为内联函数。
- 内联函数体中,不能有循环语句、if语句或switch语句,否则,函数定义时即使有inline关键字,编译器也会把该函数作为非内联函数处理。
- 内联函数要在函数被调用之前声明。
3.4 new和delete
- new:相当于malloc分配内存 + 调用构造函数。
- delete:相当于调用析构 + free。
//layer.hpp
explicit Layer(const LayerParameter& param)
: layer_param_(param), is_shared_(false) {
// Set phase and copy blobs (if there are any).
phase_ = param.phase(); //训练还是测试
// 在layer类中被初始化,如果blobs_size() > 0
// 在prototxt文件中一般没有提供blobs参数,所以这段代码一般不执行
if (layer_param_.blobs_size() > 0) {
blobs_.resize(layer_param_.blobs_size());
for (int i = 0; i < layer_param_.blobs_size(); ++i) {
blobs_[i].reset(new Blob<Dtype>());
blobs_[i]->FromProto(layer_param_.blobs(i));
}
}
}
//test_conv_layer.cpp
virtual ~ConvolutionLayerTest() {
delete blob_bottom_;
delete blob_bottom_2_;
delete blob_top_;
delete blob_top_2_;
}
4 设计模式
4.1 工厂模式
代码中,Layer和Solver都采用了工厂模式。两者是类似的,以Layer为例,Caffe通过工厂模式创建各种Layer派生类的对象:调用LayerRegistry这个类的静态成员函数CreateLayer得到一个指向Layer的指针来构造shared_ptr类型的layer。而且由于C++多态的特性,尽管layer是一个指向基类layer类型的指针,通过layer这个智能指针来调用各个成员函数会调用到各个子类(BaseConvLayer等)的函数。如何通过LayerRegistry这个类得到不同类型的Layer,就是应用了工厂模式。
下面对Layer的工厂模式进行分析:
-
初始化时,通过
LayerRegistry::CreateLayer()根据传入的LayerParameter创建相应的Layer对象,并将指针放入layers_这个数组中。LayerRegistry是一个工厂类,其中包含一个字符串到Layer创建函数(类型为Creator)指针的map结构,可以根据LayerParameter中的layer类型名找到相应的layer创建函数。 -
每种layer都会通过REGISTER_LAYER_CREATOR宏来进行注册,比如
REGISTER_LAYER_CREATOR(Convolution, GetConvolutionLayer)会为Convolution这种类型的layer在注册表中映射到GetConvolutionLayer()这个函数。#define REGISTER_LAYER_CREATOR(type, creator) \ static LayerRegisterer<float> g_creator_f_##type(#type, creator<float>); \ static LayerRegisterer<double> g_creator_d_##type(#type, creator<double>) \ /* * 宏 REGISTER_LAYER_CLASS 为每个type生成了create方法,并和type一起注册到了LayerRegistry中 * ,保存在一个map里面。 */ #define REGISTER_LAYER_CLASS(type) \ template <typename Dtype> \ shared_ptr<Layer<Dtype> > Creator_##type##Layer(const LayerParameter& param) \ { \ return shared_ptr<Layer<Dtype> >(new type##Layer<Dtype>(param)); \ } \ REGISTER_LAYER_CREATOR(type, Creator_##type##Layer) -
LayerRegistry类,里面有一个map<string, Creator>用来存放layer注册信息,通过g_registry_来保存键值对:
class LayerRegistry { public: typedef shared_ptr<LayerBase> (*Creator)(const LayerParameter&, Type, Type, size_t); typedef std::map<string, Creator> CreatorRegistry; static CreatorRegistry& Registry() { static CreatorRegistry g_registry_; return g_registry_; } //... } -
这样,当网络结构描述文件中有layer的type属性为Convolution时,就会调用GetConvlutionLayer()函数来创建相应的Layer对象。对于有些类型的layer,创建时不需要复杂的判断,就可以用REGISTER_LAYER_CLASS宏,它会生成一个简单的创建函数Creator_XXXLayer()。
4.2 单例模式
-
在caffe框架中,class Caffe是一个单例类,这个类是可以重入的,即可以被多个线程同时使用。
-
实现方法:
- 定义一个static 全局指针(
boost::thread_specific_ptr,该指针是thread local指针)。该指针表示当前线程是否第一次运行caffe的get函数。 - 定义class Caffe的构造函数为私有的。
- Get函数获取Caffe单例的引用(
Caffe& Caffe::Get()),如果全局指针不是null,即new一个Caffe实例;否则,返回caffe实例。
- 定义一个static 全局指针(
//common.hpp
class Caffe {
public:
~Caffe();
// Thread local context for Caffe. Moved to common.cpp instead of
// including boost/thread.hpp to avoid a boost/NVCC issues (#1009, #1010)
// on OSX. Also fails on Linux with CUDA 7.0.18.
//Get函数利用Boost的局部线程存储功能实现
static Caffe& Get();
//Brew就是CPU,GPU的枚举类型
enum Brew { CPU, GPU };
private:
// The private constructor to avoid duplicate instantiation.
Caffe(); //实现中构造函数被声明为私有方法,这样从根本上杜绝外部使用构造函数生成新的实例,
//同时禁用拷贝函数与赋值操作符(声明为私有但是不提供实现)避免通过拷贝函数或赋值操作生成新实例。
DISABLE_COPY_AND_ASSIGN(Caffe);
};
- 以上代码展示的是头文件中,定义class Caffe的构造函数为私有的。
//common.cpp
namespace caffe {
// Make sure each thread can have different values.
static boost::thread_specific_ptr<Caffe> thread_instance_;
Caffe& Caffe::Get() {
if (!thread_instance_.get()) {
thread_instance_.reset(new Caffe());
}
return *(thread_instance_.get());
}
//...//
}
- 以上代码展示的是cpp文件中,定义一个static 全局指针,Get函数获取Caffe单例的引用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号