

论文笔记:An Empirical Guide to the Behavior and Use of Scalable Persistent Memory
《An Empirical Guide to the Behavior and Use of Scalable Persistent Memory》是在FAST20上的一篇论文。在过去几年间,研究人员就已经开始研究如何将非易失性内存引入应用程序、库、文件系统中,然而那时候真正的NVM硬件还没有出来,很多Paper都是基于理论仿真模型而得到的。而最近,Intel推出了真正的支持字节粒度访问、持久存储的Intel Optane DIMM硬件。本文从宏观和微观角度,
- 探究Intel Optane DIMM的性能特点。
- 比较Intel Optane DIMM与DRAM的性能,并指出真正的Optane DIMM与之前人们通过仿真等方法构建出的理论层面的NVM的差异。
- 结合其性能特点,指出使用Optane DIMM的Best practice。
- 分析现有的为NVM开发的程序有哪些性能问题,并对它们进行优化。
Optane Memory架构
特点
- 不需要像SSD之类的外设一样通过PCIe总线与CPU相连,直接连接到Memory Controller上。因此比SSD之类的延时更低、带宽更高。
- 提供了按照内存地址来访问存储单元的接口,而不像磁盘等外设,借助于块访问。
- 容量更大(128/256/512GB),支持持久存储,断电内容不会消失。
- 目前唯一支持傲腾内存的微架构是Intel Cascade Lake。
传统的存储介质(补充)
SRAM
SRAM使用Flip flop来存储bit。一般一个cell存一个bit,一个cell需要6个MOS管。性能很高,但是容量很小,价格很贵。一般用来做L1、L2 Cache,或者CPU内部寄存器。且数据一掉电即消失,无法持久存储。
DRAM
DRAM用电容阵列存储bit。性能较好(相比SRAM较差),容量一般,价格较SRAM便宜一些。目前的主存一般使用DRAM来实现。同样,DRAM也没法持久存储数据。SDRAM和DDR SDRAM与普通DRAM的主要区别在于数据传输的时机方面,对于存储数据的持久性问题也一直无法解决。
PROM
每个存储单元由晶体管构成。晶体管发射级上由金属氧化物。编程时,按照用户的数据,通过脉冲使氧化物分解。以此实现更改存储单元的bit。由于分解之后氧化物没法再还原,故PROM虽然可以持久存储数据,但是它是不可在第一次写入后更改的。
UVEPROM/EEPROM
EPROM是可擦除的ROM。同样可以持久存储数据,但是擦除需要借助紫外线或高电压等特殊手段来实现。
FLASH
回头填坑
磁盘
磁盘具有很大的容量,可以很方便地进行数据读写,并且可以保证数据持久性。机械硬盘的最大问题在于读写速度慢。机械硬盘由盘片,磁道、扇区构成。如果下一个要访问的数据距离当前读写臂所指向的扇区比较远,那么读写臂需要进行寻道,移动到目标的扇区,然后才能开始进行读写。这个寻道的过程非常耗时,一般是毫秒级别。远远大于DRAM的读写时间。SSD回头填坑
Optane Memory整体结构
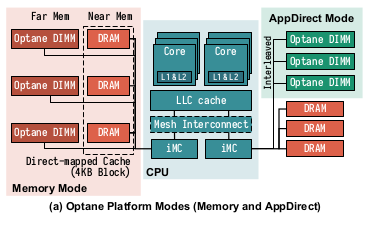
所有Optane DIMM都连在内存总线上,连接到处理器的iMC(Integrated memory controller)。每个处理器芯片有两个iMC,每个iMC又有三个通道,每个通道可以链接一个Optane DIMM。所以一个CPU可以连接到6个Optane DIMM上。这6个DIMM可以采用低位交叉连接的方式,提升并行性。如图:
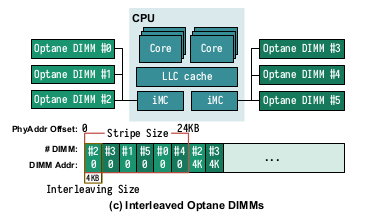
Optane DIMM具有Memory mode和App direct mode两种操作模式。在Memory mode中,Optane DIMM被用来当main memory用,而原本的DRAM则被作为Optane DIMM的Cache。而在App direct mode中,Optane DIMM被作为一个单独的PM设备。
一个问题在于,因为有Cache,并不是所有数据在发出store指令之后会被立刻write back到真正的NVM硬件当中。并且,它们写到NVM中的顺序也是不确定的。默认情况下,只有当一个cache line被替换掉的时候,里面的数据才会被写入内存中。这就给崩溃一致性(Crash consistency)的处理造成困难。对于一些系统程序(比如数据库、文件系统),我们希望数据被真正地写入到持久内存的时间是可控的。ISA中提供了clflush、clwb等一系列Cache line刷新指令,允许程序员手动把整个Cache line全部清空,并将里面的数据写入内存中。此外,也提供了ntstore系列的指令。ntstore可以让用户直接将数据写入主存,绕开Cache。上述指令都是Non-blocking的,也就是可能还没写回完成下一条指令就开始跑了。如果想要保证这些指令都做完才继续做后面的步骤,需要插入一个sfence。
Optane Memory内部结构

Optane Memory(傲腾内存)的内部采用3D-XPoint Media。这个存储介质主要采用回头填坑。
为了增强断电等failure情况下的处理能力,Intel提出了异步DRAM刷新(ADR)机制。这套机制可以确保进入了ADR Domain的数据即使是断电,也能被顺利写入NVM当中。相当于一旦数据进了内存控制其中的写缓冲队列(Write pending queue),那就稳了,即使中间断电,数据也能进入主存中。然而比较坑的是,如果断电了,数据还在Cache里,还没进入到内存控制器中,那数据就会丢失。(特地查了一下,英特尔最新出了eADR技术,也就是增强型异步DRAM刷新。这套技术可以保证即使断电,Cache中的数据也能最终被写回主存。对于ADR系列技术,可见英特尔官方文献https://software.intel.com/content/www/us/en/develop/articles/eadr-new-opportunities-for-persistent-memory-applications.html)
内存控制器和Optane DIMM之间采用DDR-T接口传输数据。一次传送一个Cache line的数据(64B)。内存控制器向Optane DIMM发出读写请求之后,Optane DIMM内置了一个地址转换表(Address indirection table, AIT),DIMM内部的控制电路XPController将请求访问的地址转译成存储介质相关的地址,然后进行实际的存储介质访问。此外,因为存储介质的访问粒度为256字节,而DIMM本身支持1字节粒度访问,所以XPController还需要将访问请求转换成256字节块,也就是XPLine级别的粒度。这样会造成写放大现象(比如我要写入4个字节,但是因为存储介质的访问粒度问题,实际上写入到3DXPoint Media里面了256个字节)。
此外,Optane DIMM中还有一个XPBuffer。这个是为了缓解前面的写放大问题。这个Buffer又称Write-combining buffer。较为密集的小范围内的、连续多次内存访问,并不是每一次都要直接写到介质中。完全可以先写到XPBuffer中,等凑够了再写到介质当中。(笔者认为对于读操作也有这种优化,因为同样存在读放大问题。并且后文中提到了XPBuffer对于读操作也有影响。但是文中没有提及。)
性能特点
之前人们都觉得Optane“比DRAM慢一点点“。实际上,经过试验发现,Optane Memory的性能特点远远比这句话概括的要复杂。对于不同的读写方式(比如随机读还是顺序读),不同的数据块大小(写入多少字节?连续吗?),不同的并发性(多线程还是单线程写入?)等情况,相对DRAM来讲都有不同的表现。
对Optane memory做性能评估很麻烦,因为:
- Optane和普通DRAM技术大相径庭,但是Optane是Intel新出的独家产品,文档、资料很少。
- 目前内存性能评估工具一般只需要测试在不同的局部性和访问粒度下访存的表现。而Optane memory受到很多因素影响,很难测试。
于是作者们开发了一个microbenchmark工具包,LATTester。这个软件:
- 作为一个特制的文件系统运行在内核态。
- 页表映射都已经提前在内核中设定好。于是不会出现运行时Page fault。
- 把自己需要的内核态线程绑定在几个固定的CPU核心,并且关闭了IRQ和Cache预取器。
- 不仅仅测量延时和带宽,而且会收集很多来自CPU和NVM的硬件事件信息辅助统计。
整个性能测试程序和数据集在https://github.com/NVSL/OptaneStudy中开源。
读/写延时
测试方法
- 读:取多次8字节随机/连续load指令的延时均值。通过清空CPU流水线并加上mfence减少cache、queuing、乱序造成的影响。
- 写:把一个cacheline大小的内存块写入到cache中。测量ntstore+mfence的情况和clwb+mfence的情况造成的延时。
测试结果

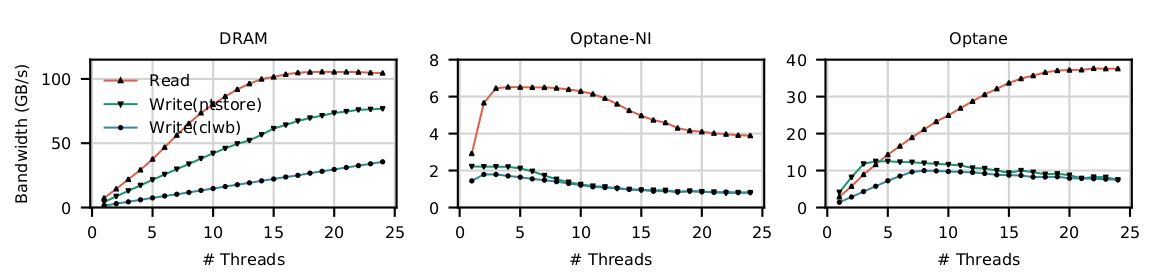
可以看出:
- 顺序读相比DRAM有2x开销。
- 随机读相比DRAM有3x开销。
- 两种写的方法开销相近。
原因分析
- Optane读的延时比DRAM高2x-3x,主要应该是因为Optane的存储介质的延时造成的。
- Optane对于顺序/随机更敏感,主要应该是因为Optane里面的XPBuffer可以优化连续的读取。而随机读取就用不上这种优化了,完全是Optane存储介质的延时了。
- Optane实际上在写到ADR Domain里面之后,mfence就结束了。(因为这样数据就已经安全了,不论如何一定都会写到主存中)。
带宽
测试方法
- 第一组:选择不同的并发量(线程数目),然后进行顺序、以256B为粒度(使用了Intel AVX-512指令,一次存取256B)进行内存访问。来测试带宽。
- 第二组:选择不同的访问大小进行随机访问。
测试结果
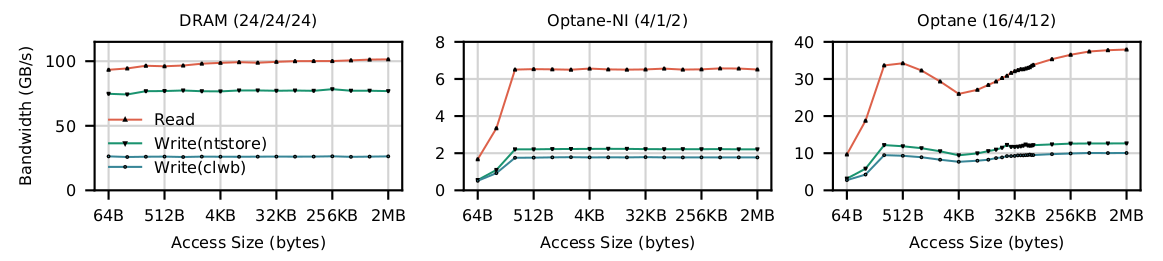
- DRAM带宽最大,且变化趋势容易被人预知,比较有规律。
回头填坑
最佳实践
减少少于256B的随机访问
Tip
- 尽量减少少于256B的随机访问。
- 但如果无法减少,尽量保证这些访问具有局部性,把work size控制在XPBuffer的大小——16KB以内。这样开销也不会太大。
解释
文章提出了一个EWR指标,表示写操作有效率(Effective Write Ratio,有效写操作的比例)。
设想一下,我先向这里写1字节,然后再向隔1GB的地方写1字节。实际上我请求写入的是两个字节,但是这么做的话实际上会写入512个字节。EWR就是
这个\(EWR<1\),意味着写操作有效率很低,大部分都在作无用功。而如果我想写连续的256字节(且刚好对齐到256字节边界),那这样我请求写入的是256字节,实际写入的也是256字节。于是
上面就对应了效率很高的情况。所以如果我们能把随机访问的粒度放大到接近256B,比起更小粒度的随机访问是大有好处的。由于XPBuffer能合并写操作,所以\(EWR\)可能超过1。比如我向同一个地方连续写257次,可能最终实际只需要写入介质一次。于是
当\(EWR\)越小,无用的写越多,性能影响越大。
经过测试,XPBuffer有16KB。所以尽量将work size控制在16KB范围之内。这样可以充分利用内置的读/写合并的机制来减少访问存储介质的次数,以减少执行时间。
对于大块写入选择ntstore
Tip
如果写入的数据块较大,且是那种写一下就不用了的,不妨使用ntstore。直接绕开Cache。
解释

从图中可以看出,在要写入的数据块较大的情况下,store的带宽是最低的。这个的原因是因为store会影响Cache,需要让系统自己去淘汰数据块,而ntstore不影响cache line,store+clwb会主动把当前数据块淘汰掉。所以不会影响访问的顺序。而让系统自己去淘汰会影响访问顺序,降低带宽。
为什么ntstore比store+clwb更快,则是因为ntstore绕开了cache,避免多余的cache读取操作(因为clwb还需要把数据从cache里load到nvm中),获得更多的带宽。
限制并发访问Optane DIMM的线程数
多线程并发访问DIMM,其开销主要来自于:
- XPBuffer的竞争。XPBuffer空间较小,只有16KB。多线程访问时,会导致更多的数据淘汰到介质中。
- iMC的竞争。iMC中有WPQ,而因为DIMM访问较慢,队列会出现堆积的现象(也就是因为队首请求阻塞后面的请求)。
避免访问其他NUMA节点上的Optane DIMM
回头填坑

 浙公网安备 33010602011771号
浙公网安备 33010602011771号