c++笔记-scoped_lock/unique_lock解析
scoped_lock vs unique_lock
在C++中,std::scoped_lock和std::unique_lock都是用来管理互斥量(mutex)的RAII(Resource Acquisition Is Initialization)类,用于简化多线程编程中的锁管理。它们之间有一些区别,主要体现在以下几个方面:
灵活性
std::scoped_lock:C++17引入的std::scoped_lock允许你一次性锁住多个互斥量。你可以传递多个互斥量给scoped_lock的构造函数,它会自动锁住所有传递的互斥量,并且在scoped_lock的生命周期结束时自动解锁。这样可以避免出现死锁,因为它会在一次性锁住所有互斥量时,自动避免死锁情况。
std::unique_lock:unique_lock在构造时只能锁住一个互斥量。但与scoped_lock不同的是,你可以在后续的代码中手动解锁、重新锁住或者在不同的地方重新锁住另一个互斥量。这种灵活性有时可以用于更复杂的场景。
生命周期
std::scoped_lock:scoped_lock是一次性的,它在构造时锁住互斥量,并在离开作用域时自动解锁。这使得其用法简单明了,尤其适合用于临时锁住多个互斥量的情况。
std::unique_lock:unique_lock的生命周期可以由程序员手动控制。这允许更高度的灵活性,但也需要更多的手动管理,以确保正确的锁定和解锁,特别是在异常处理时。
资源所有权
std::scoped_lock:没有提供std::scoped_lock::release()方法,因此它无法在生命周期内释放锁定并重新获得它。这意味着你不能在临时情况下释放锁,然后再次获取锁。
std::unique_lock:unique_lock提供了unlock()和lock()方法,允许在生命周期内释放和重新获取锁。这对于需要在一段时间内解锁的情况(例如,进行一些计算或等待其他条件)可能很有用。
综上所述,std::scoped_lock适用于简单的一次性锁定多个互斥量的场景,以及希望避免死锁的情况。而std::unique_lock适用于更复杂的场景,需要更多的灵活性和手动管理。在选择使用哪个类时,要考虑你的具体需求和代码的复杂性。
性能对比
例
定义结构体 TestStruct,两个线程同时对TestStruct.id++,利用对互斥量加锁保证写正确。分别测试使用unqiue_lock/scoped_lock时的性能
// 编译
// g++ test_lock.cpp -o test -std=c++17 -lpthread
#include <atomic>
#include <chrono>
#include <iomanip>
#include <iostream>
#include <mutex>
#include <thread>
std::mutex cout_mutex;
constexpr int max_write_iterations{10'000'000}; // the benchmark time tuning
struct TestStruct {
std::mutex mutex_;
uint32_t id = 0;
std::atomic_uint64_t cost = 0;
};
TestStruct test_scoped_lock;
TestStruct test_unique_lock;
inline auto now() noexcept { return std::chrono::high_resolution_clock::now(); }
void scopedLockThread() {
const auto start { now() };
for (uint64_t count{}; count != max_write_iterations; ++count) {
std::scoped_lock _(test_scoped_lock.mutex_);
test_scoped_lock.id++;
}
const std::chrono::duration<double, std::milli> elapsed { now() - start };
test_scoped_lock.cost.fetch_add(static_cast<uint64_t>(elapsed.count()), std::memory_order_relaxed);
std::lock_guard lk{cout_mutex};
std::cout << "scoped_lock() spent " << elapsed.count() << " ms\n";
}
void uniqueLockThread() {
const auto start { now() };
for (uint64_t count{}; count != max_write_iterations; ++count) {
std::unique_lock _(test_unique_lock.mutex_);
test_unique_lock.id++;
}
const std::chrono::duration<double, std::milli> elapsed { now() - start };
test_unique_lock.cost.fetch_add(static_cast<uint64_t>(elapsed.count()), std::memory_order_relaxed);
std::lock_guard lk{cout_mutex};
std::cout << "unique_lock() spent " << elapsed.count() << " ms\n";
}
int main() {
std::cout
<< std::fixed << std::setprecision(2)
<< "sizeof( TestStruct ) == " << sizeof( TestStruct ) << '\n';
constexpr int max_runs{20};
uint64_t scoped_lock_average{0};
for (auto i{0}; i != max_runs; ++i) {
std::cout << "round [" << i << "]" << std::endl;
std::thread th1{scopedLockThread};
std::thread th2{scopedLockThread};
th1.join(); th2.join();
}
scoped_lock_average = test_scoped_lock.cost;
std::cout << std::endl;
uint64_t uniq_lock_average{0};
for (auto i{0}; i != max_runs; ++i) {
std::cout << "round [" << i << "]" << std::endl;
std::thread th1{uniqueLockThread};
std::thread th2{uniqueLockThread};
th1.join(); th2.join();
}
uniq_lock_average = test_unique_lock.cost;
std::cout << std::endl;
std::cout << "Average scoped_lock time: " << (scoped_lock_average / max_runs / 2) << " ms" << std::endl;
std::cout << "Average uniq_lock time: " << (uniq_lock_average / max_runs / 2) << " ms" << std::endl;
}
结果
Average scoped_lock time: 3147 ms
Average uniq_lock time: 3647 ms
源码
unque_lock
template <typename _Mutex>
class unique_lock {
public:
typedef _Mutex mutex_type;
unique_lock() noexcept : _M_device(0), _M_owns(false) {}
explicit unique_lock(mutex_type& __m)
: _M_device(std::__addressof(__m)), _M_owns(false) {
lock();
_M_owns = true;
}
// ...
~unique_lock() {
if (_M_owns) unlock();
}
// ...
void lock() {
if (!_M_device)
__throw_system_error(int(errc::operation_not_permitted));
else if (_M_owns)
__throw_system_error(int(errc::resource_deadlock_would_occur));
else {
_M_device->lock();
_M_owns = true;
}
}
// ...
void unlock() {
if (!_M_owns)
__throw_system_error(int(errc::operation_not_permitted));
else if (_M_device) {
_M_device->unlock();
_M_owns = false;
}
}
// ...
private:
mutex_type* _M_device;
bool _M_owns; // XXX use atomic_bool
};
scoped_lock
template <typename... _MutexTypes>
class scoped_lock {
public:
explicit scoped_lock(_MutexTypes&... __m) : _M_devices(std::tie(__m...)) {
std::lock(__m...);
}
explicit scoped_lock(adopt_lock_t, _MutexTypes&... __m) noexcept
: _M_devices(std::tie(__m...)) {} // calling thread owns mutex
~scoped_lock() {
std::apply(
[](_MutexTypes&... __m) {
char __i[] __attribute__((__unused__)) = {(__m.unlock(), 0)...};
},
_M_devices);
}
scoped_lock(const scoped_lock&) = delete;
scoped_lock& operator=(const scoped_lock&) = delete;
private:
tuple<_MutexTypes&...> _M_devices;
};
template <>
class scoped_lock<> {
public:
explicit scoped_lock() = default;
explicit scoped_lock(adopt_lock_t) noexcept {}
~scoped_lock() = default;
scoped_lock(const scoped_lock&) = delete;
scoped_lock& operator=(const scoped_lock&) = delete;
};
template <typename _Mutex>
class scoped_lock<_Mutex> {
public:
using mutex_type = _Mutex;
explicit scoped_lock(mutex_type& __m) : _M_device(__m) { _M_device.lock(); }
explicit scoped_lock(adopt_lock_t, mutex_type& __m) noexcept
: _M_device(__m) {} // calling thread owns mutex
~scoped_lock() { _M_device.unlock(); }
scoped_lock(const scoped_lock&) = delete;
scoped_lock& operator=(const scoped_lock&) = delete;
private:
mutex_type& _M_device;
};

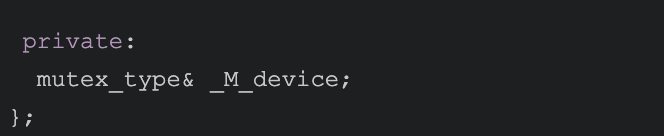
对比 unque_lock和scoped_lock, unque_lock多了 bool _M_owns; 成员,以及在lock和unlock时对_M_owns和_M_device的判断
耗时差异怀疑来自于此

 浙公网安备 33010602011771号
浙公网安备 33010602011771号