
多层级树形结构数据库存储方式
要做一个多层级树形结构数据,后端数据如何存储,以怎样的形式给前端呢
方法1:Adjacency List存储相邻关系
id, parent_id以邻接表(Adjacency List)的形式进行存储在一张表中
这种方式在关系存储比较简单,查询的时候比较复杂。
比如查询部门下的所有子部门信息,因为表中只记录的上下级的部门及其子部门信息。需要遍历表中的信息
这有两种方式。
方式1:
在数据库中递归遍历数据表,这样只需要一次io就可以完成这个操作。降低的数据库连接数,缺点是占用数据库的cpu,在数据量大的时候会赞成数据库服务器宕机,甚至直接损坏
方式2:
在编程语言中进行遍历。for循环中通过parent_id遍历出部门下的下级子部门,放入到map中,如果没有查询到信息就返回null
具体代码参考分销系统的用户关系,用户与推广链接的数据库设计。设计思路 。这个需要频繁的进行数据库查询,在部门层级数不大于50的时候是可以适用的。
也可以把表中的所有数据查询下来,放到list中,通过递归遍历list数据方式进行数据查询。在数据表比较小的时候也可以适用。优点是只需要进行一次IO,缺点是当数据表数据很大时,数据库内存消耗会很大。
方法1、升级版
给表增加冗余字段 parent_ids,表结构如下
CREATE TABLE tree_node( id VARCHAR(64) NOT NULL COMMENT 'id' , parent_id VARCHAR(64) DEFAULT '0' COMMENT '父节点,根节点默认为0' , parent_ids VARCHAR(1024) DEFAULT '0,' COMMENT '父节点id列表,逗号分隔' ... )
可以很方便的实现数据查询
比如要根据parent_id获取所有子孙节点数据,
select id, parent_id, parent_ids from tree_node where parent_ids like concat('0,1498954509554745345,', '%')
注意:需要修改的时候,要把对应树结构的子节点数据全部进行parent_ids字段更新。
因为 parent_ids 字段保留了该节点的所有父节点id的路径, 所以查询某个parent_id数据时,过程
1、获取到 节点 id 的数据的
select id, parent_id, parent_ids from tree_node where id=#{parentId}
2、对查出来的数据进行拼接,生成 parent_ids

比如查了是 id为 1498954509554745345的所有子节点数据。
然后查询到最后一条数据, 它的 parent_ids=0,
然后进行构造查询条件
select id, parent_id, parent_ids from tree_node where parent_ids like concat('0,1498954509554745345,', '%')
查询结果如下

方法2:左右值编码存储关系。
一条记录中增加两个字段,left 和 right
例如公司部门树型结构图
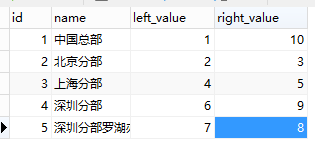
先看下他们构成的树结构图
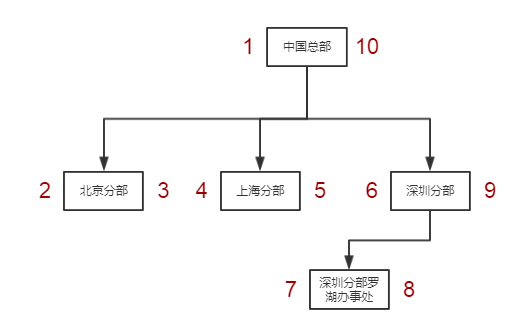
从上图可知,左右值的排序规律是按照先序遍历进行排序,即,根-->左-->右(因为根不需要计算值,排序从左子树到右子树从小到大排列)
查看规律,
中国总部这个根节点的左值比它的所有子节点都小。右值比它的所有子节点都大
如果层级数据不多,建议平级返回数据,客户端自己组合层级。
数据存储 一般是看你的需求,比如:
国家-城市-道路-母婴。这种差异较大的就是多个表关联存储
数据存储 一般是看你的需求,比如:
国家-城市-道路-母婴。这种差异较大的就是多个表关联存储
如果是很紧密的那就存储一个表就好,也可以使用NOSQL方式存储,这样筛查也是可以的。
如果数据量大那就分接口返回
比如查询1级接口。查询2级接口 3级接口....
依次的来,不要1~3级的全部返回了
就是购物的就可以啊
淘宝的筛选就类似,京东也是
依次的来,不要1~3级的全部返回了
就是购物的就可以啊
淘宝的筛选就类似,京东也是
作者:海绵般汲取
出处:https://www.cnblogs.com/gne-hwz/
版权:本文版权归作者和博客园共有
转载:欢迎转载,但未经作者同意,必须保留此段声明;必须在文章中给出原文连接;否则必究法律责任
出处:https://www.cnblogs.com/gne-hwz/
版权:本文版权归作者和博客园共有
转载:欢迎转载,但未经作者同意,必须保留此段声明;必须在文章中给出原文连接;否则必究法律责任


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架