并发编程之fork/join(分而治之)
1.什么是分而治之
分而治之就是将一个大任务层层拆分成一个个的小任务,直到不可拆分,拆分依据定义的阈值划分任务规模。
fork/join通过fork将大任务拆分成小任务,在将小任务的结果join汇总
2.fork/join标准范式
先上图
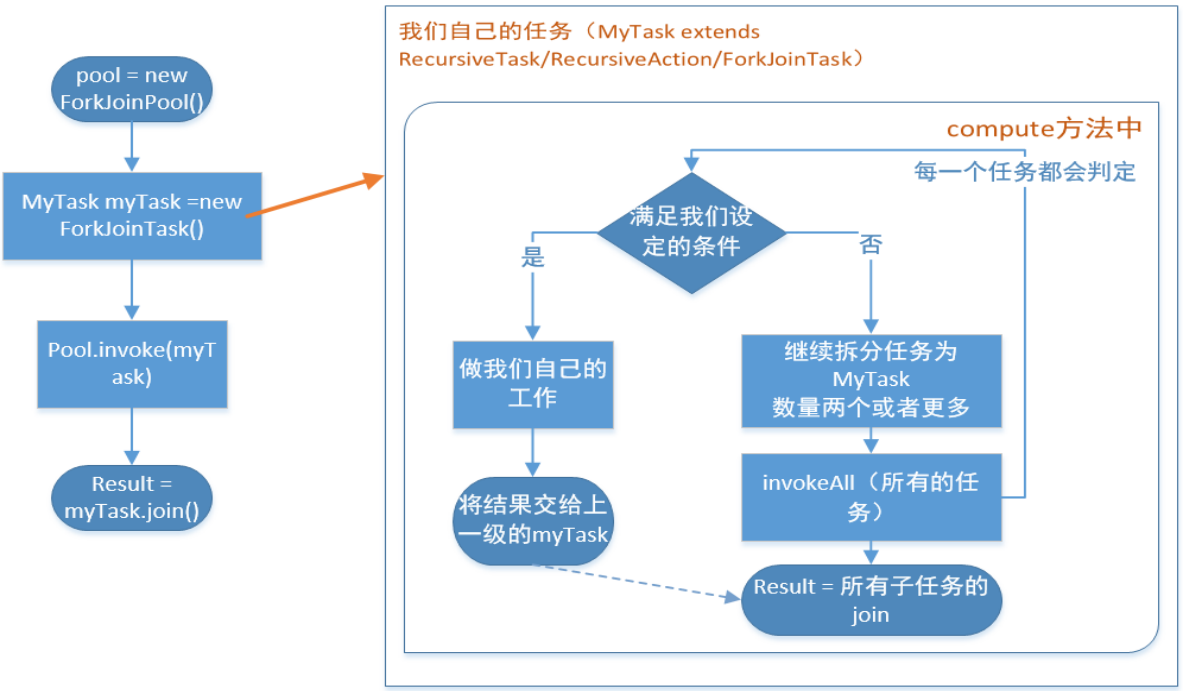
在使用fork/join做任务分配之前,首先得了解其中的几个类:
ForkJoinPool:充当fork/join框架里面的管理者,最原始的任务都要交给它才能处理。它负责控制整个fork/join有多少个workerThread,workerThread的创建,激活都是由它来掌控。它还负责workQueue队列的创建和分配,每当创建一个workerThread,它负责分配相应的workQueue。然后它把接到的活都交给workerThread去处理,它可以说是整个frok/join的容器。
ForkJoinWorkerThread:fork/join里面真正干活的"工人",本质是一个线程。里面有一个ForkJoinPool.WorkQueue的队列存放着它要干的活,接活之前它要向ForkJoinPool注册(registerWorker),拿到相应的workQueue。然后就从workQueue里面拿任务出来处理。它是依附于ForkJoinPool而存活,如果ForkJoinPool的销毁了,它也会跟着结束。
ForkJoinPool.WorkQueue: 双端队列就是它,它负责存储接收的任务。
ForkJoinTask:代表fork/join里面任务类型,我们一般用它的两个子类RecursiveTask、RecursiveAction。这两个区别在于RecursiveTask任务是有返回值,RecursiveAction没有返回值。任务的处理逻辑包括任务的切分都集中在compute()方法里面。
3.废话不多说,代码走起
fork/join在平时的使用过程中,一般分为同步调用和异步调用,下面是两种情况的实例:
/**同步用法*/
1 public class SumArray { 2 private static class SumTask extends RecursiveTask<Integer>{ 3 4 private final static int THRESHOLD = MakeArray.ARRAY_LENGTH/10; 5 private int[] src; //表示我们要实际统计的数组 6 private int fromIndex;//开始统计的下标 7 private int toIndex;//统计到哪里结束的下标 8 9 public SumTask(int[] src, int fromIndex, int toIndex) { 10 this.src = src; 11 this.fromIndex = fromIndex; 12 this.toIndex = toIndex; 13 } 14 15 @Override 16 protected Integer compute() { 17 if(toIndex-fromIndex < THRESHOLD) { 18 int count = 0; 19 for(int i=fromIndex;i<=toIndex;i++) { 20 //SleepTools.ms(1); 21 count = count + src[i]; 22 } 23 return count; 24 }else { 25 //fromIndex....mid....toIndex 26 //1...................70....100 27 int mid = (fromIndex+toIndex)/2;
//将任务一分为二 28 SumTask left = new SumTask(src,fromIndex,mid); 29 SumTask right = new SumTask(src,mid+1,toIndex); 30 invokeAll(left,right); //提交任务 31 return left.join()+right.join(); 32 } 33 } 34 } 35 36 public static void main(String[] args) { 37 38 ForkJoinPool pool = new ForkJoinPool(); 39 int[] src = MakeArray.makeArray(); 40 41 SumTask innerFind = new SumTask(src,0,src.length-1); 42 43 long start = System.currentTimeMillis(); 44 45 int a = pool.invoke(innerFind);//同步调用 46 System.out.println("Task is Running....."); 47 System.out.println("The count is "+innerFind.join() 48 +" spend time:"+(System.currentTimeMillis()-start)+"ms"+a); 49 } 50 }
/** *异步用法 * *类说明:遍历指定目录(含子目录)找寻指定类型文件 */ public class FindDirsFiles extends RecursiveAction{ private File path;//当前任务需要搜寻的目录 public FindDirsFiles(File path) { this.path = path; } public static void main(String [] args){ try { // 用一个 ForkJoinPool 实例调度总任务 ForkJoinPool pool = new ForkJoinPool(); FindDirsFiles task = new FindDirsFiles(new File("F:/")); pool.execute(task);//异步调用 System.out.println("Task is Running......"); Thread.sleep(1); int otherWork = 0; for(int i=0;i<100;i++){ otherWork = otherWork+i; } System.out.println("Main Thread done sth......,otherWork="+otherWork); task.join();//阻塞的方法 System.out.println("Task end"); } catch (Exception e) { e.printStackTrace(); } } @Override protected void compute() { List<FindDirsFiles> subTasks = new ArrayList<>(); File[] files = path.listFiles(); if(files!=null) { for(File file:files) { if(file.isDirectory()) { subTasks.add(new FindDirsFiles(file)); }else { //遇到文件,检查 if(file.getAbsolutePath().endsWith("txt")) { System.out.println("文件:"+file.getAbsolutePath()); } } } if(!subTasks.isEmpty()) { for(FindDirsFiles subTask:invokeAll(subTasks)) { subTask.join();//等待子任务执行完成 } } } } }
这段代码可以直接运行试试,跟上面的标准范式一样,在这里我是实现了RecursiveTask(有兴趣的可以自己改成RecursiveAction玩玩,但是RecursiveAction是没有返回值的,使用的时候需要注意),当调用ForkJoinPool的invoke方法启动任务,会同步调用重写的compute方法,这个方法里面才是你要写的fork/join业务代码。
可以看到,我定义了一个阈值THRESHOLD,当任务小于这个阈值的时候,执行运算,否则继续切分任务,提交任务,循环调用,直到任务不可切分,将所有的运算结果整合。其实我在调用invokeAll方法时,并不会立刻返回结果,里面还是会去重复判断每一个任务是否小于阈值,当所有的任务都满足条件并执行完成,才会返回,其实就是递归调用。
总结:
fork/join的使用其实没什么难度,其基本思想是将大任务分割成小任务,最后将小任务聚合起来得到结果。fork是分解的意思, join是收集的意思. 它非常类似于HADOOP提供的MapReduce框架,只是MapReduce的任务可以针对集群内的所有计算节点,可以充分利用集群的能力完成计算任务。ForkJoin更加类似于单机版的MapReduce。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号