

mysql系列之一条sql的旅程(二)
在介绍一条sql是怎么执行的之前,我们先来了解一下mysql的架构:
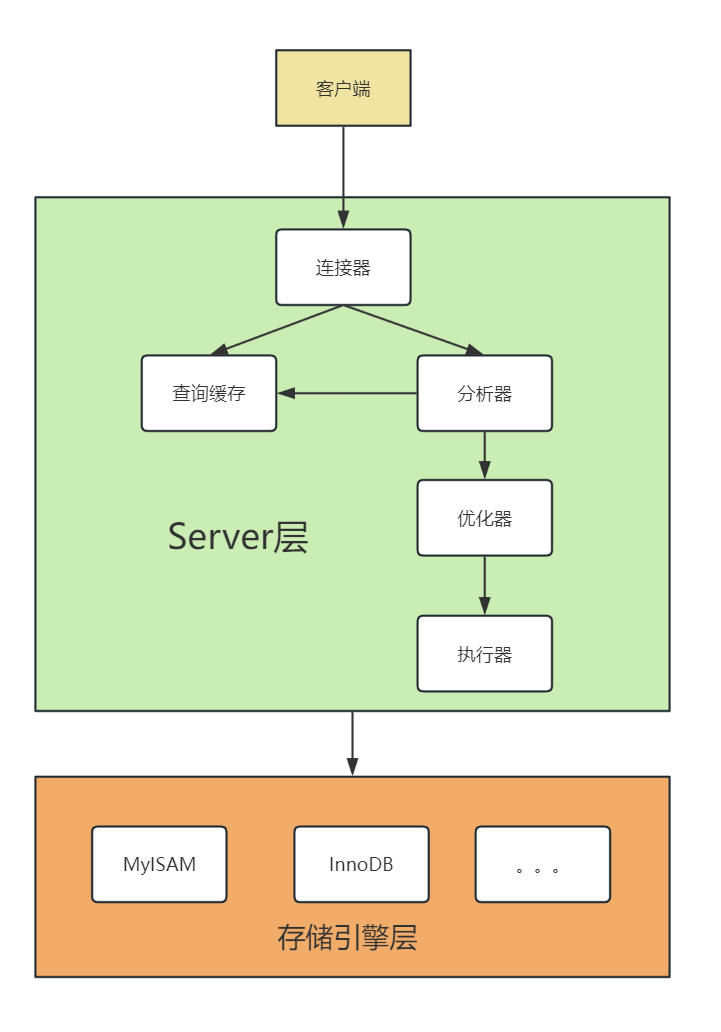
如上图mysql主要分为server层和存储引擎层:
server层算是mysql的核心能力层,如sql语句的解析优化,权限管控,各类的sql函数、存储过程,以及自身数据备份,恢复等高级功能(binlog实现),我们用到的一些基础的增删改查,这里都实现了。
存储引擎我们比较最熟悉的便是innodb,其他的比如mylsam,memory等等,每种存储引擎都有自己的特点,适用于不同的业务场景,而innodb由于其支持事务,行级锁和外键约束等特点,受到广泛欢迎。除此之外innodb还有着自己的日志系统redo log(重做日志)和undo log(撤销日志),redo log用于保证事务的持久性,本节后面我们也会聊到这一点,undo log主要用于事务回滚和多版本并发控制(mvcc) ,这块后续会详细介绍。存储引擎层在我看来相当于server层的插件,增强了mysql的能力。
那么一条sql又是如何在mysql的架构上流转的呢:
客户端访问mysql最先访问的便是server层的连接器,玩过的应该都知道,首先需要输入用户名和密码,连接器主要做的便是身份认证和权限校验。
接下来一般会来查询缓存(8.0以后去除了查询缓存),mysql会以key-value的形式,key是sql语句,所以知道为啥8.0以后去掉了吧,因为我们绝大多数业务是疯狂变化的,基本上大部分场景查询语句都不一样,而那些基本不变动的反而可以通过离用户更近的本地缓存或者第三方缓存如redis来处理,完全没必要再走mysql的查询缓存。
再往后便是分析器,它会分析你的语法是否合法,会从information_schema中获取到对应的表结构,和sql作对比。
之后便是优化器,会计算你使用什么索引更合适,会优化你的join查询(一般会优化成小表驱动大表)
确定好要做什么后,便会来到执行器,执行器会调用存储引擎提供的接口,最终将整合的数据结果返回给客户端。
至此一条sql也执行完毕了,看着是比较简单的,但其实每个里面的功能都特别复杂,想想优化器是怎么优化的,怎么就知道我该用哪个怎么用呢,这个后面有机会再聊。
