
Python人工智能识别文字内容(OCR)
环境准备
安装pytesseract和PIL
安装这两个包可以借助pip命令行安装pip install PIL
pip install pytesseract 安装识别引擎tesseract-ocr
下载地址:
https://digi.bib.uni-mannheim.de/tesseract/
https://github.com/UB-Mannheim/tesseract/wiki
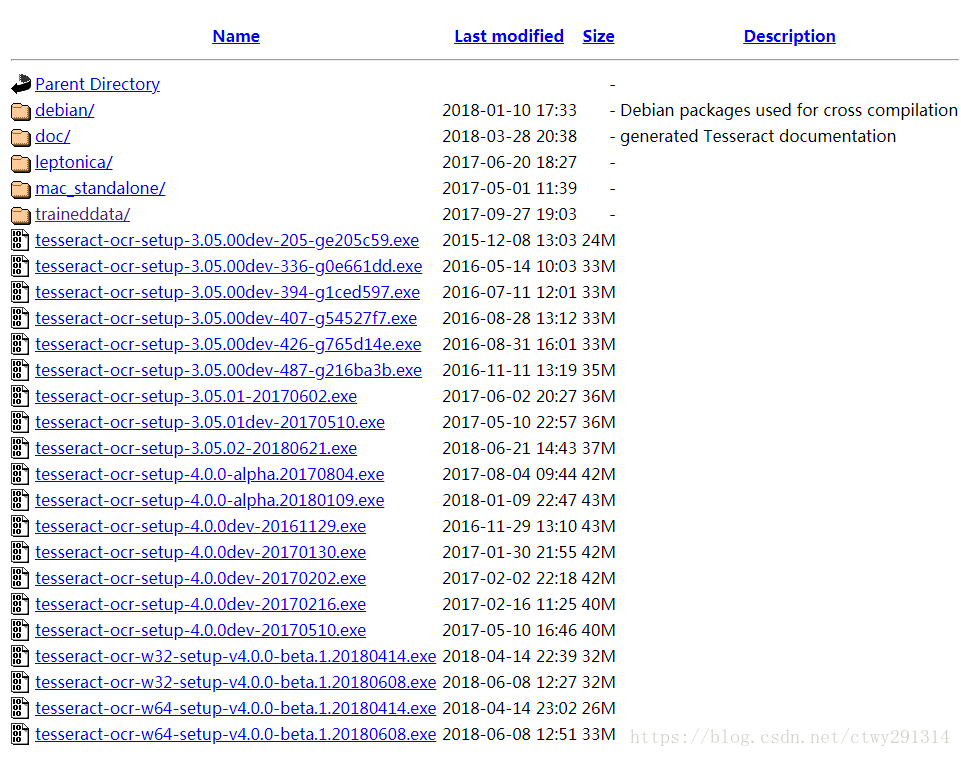
选择对应版本下载
实现及效果
原图

代码
from PIL import Image
import pytesseract
#上面都是导包,只需要下面这一行就能实现图片文字识别
text=pytesseract.image_to_string(Image.open('1.png'),lang='eng')
print(text)说明:lang=“为模型名称”。
效果
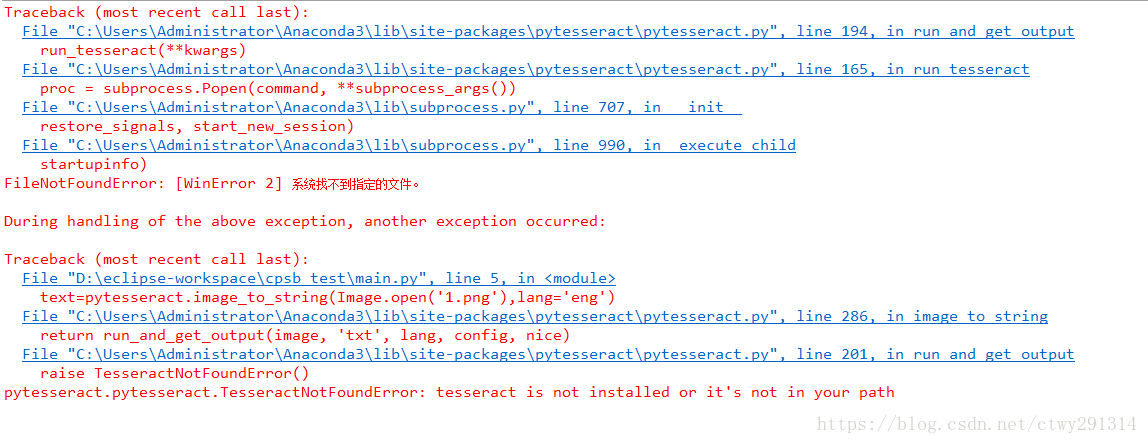
TesseractNotFoundError错误,提示未发现Tesseract-OCR安装路径
解决方案:
1、将Tesseract-OCR配置为环境变量
2、修改pytesseract.py源码,如下图:

再次运行效果

附录:
要是实现中文识别,需要下载中文模型:
下载地址:https://github.com/gm19900510/tessdata
修改源码的模型名称即可。
后期中文训练请参照:https://blog.csdn.net/ctwy291314/article/details/80865455
代码
from PIL import Image
import pytesseract
#上面都是导包,只需要下面这一行就能实现图片文字识别
text=pytesseract.image_to_string(Image.open('test2.jpg'),lang='chi_sim')
print(text)原图

效果

谨以此文献给即将成熟的我们,都成了与想象中截然不同的人

