

CDH版本Hbase二级索引详细配置方案Solr key value index
概述
Hbase
在Hbase中,表的RowKey 按照字典排序, Region按照RowKey设置split point进行shard,通过这种方式实现的全局、分布式索引. 成为了其成功的最大的砝码。
然而单一的通过RowKey检索数据的方式,不再满足更多的需求,查询成为Hbase的瓶颈,人们更加希望像Sql一样快速检索数据,可是,Hbase之前定位的是大表的存储,要进行这样的查询,往往是要通过类似Hive、Pig等系统进行全表的MapReduce计算,这种方式既浪费了机器的计算资源,又因高延迟使得应用黯然失色。于是,针对HBase Secondary Indexing的方案出现了。
Solr
Solr是一个独立的企业级搜索应用服务器,是Apache Lucene项目的开源企业搜索平台,
其主要功能包括全文检索、命中标示、分面搜索、动态聚类、数据库集成,以及富文本(如Word、PDF)的处理。Solr是高度可扩展的,并提供了分布式搜索和索引复制。Solr 4还增加了NoSQL支持,以及基于Zookeeper的分布式扩展功能SolrCloud。SolrCloud的说明可以参看:SolrCloud分布式部署。它的主要特性包括:高效、灵活的缓存功能,垂直搜索功能,Solr是一个高性能,采用Java5开发,基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。
Solr可以高亮显示搜索结果,通过索引复制来提高可用,性,提供一套强大Data Schema来定义字段,类型和设置文本分析,提供基于Web的管理界面等。
Key-Value Store Indexer
这个组件非常关键,是Hbase到Solr生成索引的中间工具。
Lily HBase Indexer是一款灵活的、可扩展的、高容错的、事务性的,并且近实时的处理HBase列索引数据的分布式服务软件。它是NGDATA公司开发的Lily系统的一部分,已开放源代码。Lily HBase Indexer使用SolrCloud来存储HBase的索引数据,当HBase执行写入、更新或删除操作时,Indexer通过HBase的replication功能来把这些操作抽象成一系列的Event事件,并用来保证写入Solr中的HBase索引数据的一致性。并且Indexer支持用户自定义的抽取,转换规则来索引HBase列数据。Solr搜索结果会包含用户自定义的columnfamily:qualifier字段结果,这样应用程序就可以直接访问HBase的列数据。而且Indexer索引和搜索不会影响HBase运行的稳定性和HBase数据写入的吞吐量,因为索引和搜索过程是完全分开并且异步的。Lily HBase Indexer在CDH5中运行必须依赖HBase、SolrCloud和Zookeeper服务。
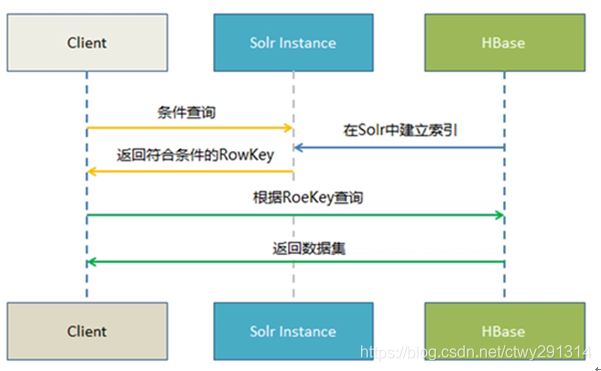
实时查询方案
Hbase -----> Key Value Store —> Solr -------> Web前端实时查询展示
1.Hbase 提供海量数据存储
2.Solr提供索引构建与查询
3.Key Value Store 提供自动化索引构建(从Hbase到Solr)
使用流程
前提:HBase、SolrCloud、Zookeeper、Key-Value Store Indexer集群搭建好,可参照:https://gaoming.blog.csdn.net/article/details/107399914
集群环境

方案一
-
Hbase表需要开启REPLICATION复制功能
create 'table',{NAME => 'cf', REPLICATION_SCOPE => 1} #其中1表示开启replication功能,0表示不开启,默认为0对于已经创建的表可以使用如下命令
disable 'table' alter 'table',{NAME => 'cf', REPLICATION_SCOPE => 1} enable 'table'创建测试表
create 'mytest', { NAME => 'info', REPLICATION_SCOPE => '1' } -
创建相应的SolrCloud集合
注意要在安装有solr的节点执行,可在CM中查看solr实例,确定solr节点
①生成实体配置文件
solrctl instancedir --generate /opt/mysolr/opt/mysolr是自定义路径,可以自己设置注:
I. 要知道命令如何使用,比如solrctl命令,可以直接键入solrctl,回车,可以看到帮助。然后再键入solrctl instancedir,回车,即可知道子命令如何使用。下面将要使用的命令也依此类推,即可知道用法。
II. --generate 后的路径由自己指定。
②命令完成后会在指定的路径下生成目录,目录下有个子目录conf,修改conf中的schema.xml,在最后添加一个节点如下

<field name="firstname" type="string" indexed="true" stored="true" required="false" multiValued="false" /> <field name="age" type="string" indexed="true" stored="true" required="false" multiValued="false" />属性解析:
name:这里的name是自定义,但是后面要使用到,要和后面的Morphline.conf文件中的outputField属性对应。
type:字段类型
indexed:是否建立索引
stored:是否存储③修改 solrconfig.xml,找到下面的配置片段,将false改为true,这个是硬提交,会影响性能
<autoCommit> <maxTime>${solr.autoCommit.maxTime:60000}</maxTime> <openSearcher>true</openSearcher> </autoCommit>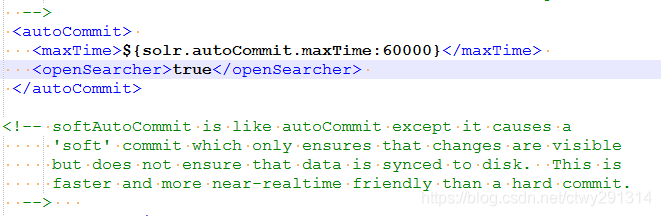
④上传配置文件到zookeepersolrctl instancedir --create mysolr /opt/mysolr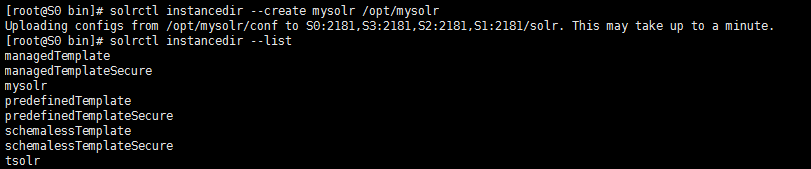
注:
命令如何使用参照上面说的方法。
–create 后接name,此name自定义,它决定在zookeeper上保存的目录名,接下来要创建的collection名,在索引创建完成后在solr web页面上看到的core selector名。如果已经存在,会有提示,或更新,或改名
name后是配置的路径,即刚才solrctl instancedir --generate所自定义的路径⑤上传后,zk会自己同步配置,然后创建collection,分单节点存储检索和多节点存储检索两种情况,如下:
I.单节点情况下:solrctl collection --mysolr注:–create 后接name,此name必须和上一步的name一致,不然找不到配置文件;
II. 多节点情况下:如果希望将数据分散到各个节点进行存储和检索,则需要创建多个shard,需要使用如下命令,solr集群共4个solrserver:
solrctl collection --create mysolr -s 2 -c mysolr -r 2 -m 3 -a我执行的是:
solrctl collection --create mysolr -s 2 -c mysolr -r 2 -m 3 -a注:
其中-s是2个分片(shard),我的solrserver集群共4个节点,-r是2个副本(replication),-c是指定zk上solr/configs节点下使用的配置文件名称,-a是允许添加副本(必须写,否则创建不了副本),-m 默认值是1,此处设为3。
注意三个数值:numShards、replicationFactor、liveSolrNode,
一个正常的solrCloud集群不容许同一个liveSolrNode上部署同一个shard的多个replic,因此当maxShardsPerNode=1时,numShards*replicationFactor>liveSolrNode时,报错。
因此正确时因满足以下条件:
numShards*replicationFactor<=liveSolrNode*maxShardsPerNode,放在命令中,
公式即:
-m * 存活的solrserver节点数 >= -s * -r,
含义:每个节点最大分片数*存活的solr节点 >= 分片数*副本数
这样分布后,在soloweb页面上可以直观看到它们的分布情况,以及这些参数产生的影响。http://s0:8983/solr/#/~cloud > Cloud >Graph查看

当创建collection命令完成后,可以在solr 的web页面上看到mysolr开头的选择器,只不过没有数据。⑥创建 Lily HBase Indexer 配置
在/opt/mysolr/目录下,创建mytest.xml文件,
目录地址和文件名称可自定义,内容如下。<?xml version="1.0"?> <indexer table="mytest"> <field name="firstname" value="info:firstname"/> <field name="age" value="info:age"/> </indexer>注:
table属性表示hbase中要建立索引的表
name属性表示输出的数据字段名称,该名称必须和solr中的schema.xml文件的field节点自定义的name名称保持一致,否则写入不正确
value属性表示需要写入到solr中的HBase列字段
⑦注册 Lily HBase Indexer Configuration 和 Lily HBase Indexer Service
hbase-indexer add-indexer -n mytestindexer -c /opt/mysolr/mytest.xml -cp solr.zk=S0:2181,S1:2181,S2:2181,S3:2181/solr -cp solr.collection=mysolr注:
键入hbase-indexer回车,获取命令帮助
–name:为indexer取名,自定义
–indexer-conf 上面创建的mytest.xml文件地址
–connection-param solr.zk :solr安装所在节点的zk地址,如有zk节点上没有安装solr,这里不写节点
–connection-param solr.collection:上面创建的solr.collection名称,要与上面一致
–zookeeper:zk节点地址⑧在hbase中插入数据
put 'mytest','001','info:firstname','zhansan' put 'mytest','001','info:age','20' put 'mytest','002','info:firstname','lisi' put 'mytest','002','info:age','25' put 'mytest','003','info:firstname','wangwu' put 'mytest','003','info:age','30'⑨在solr中查看索引,打开地址为:solr节点ip:8983/solr,查看结果如下
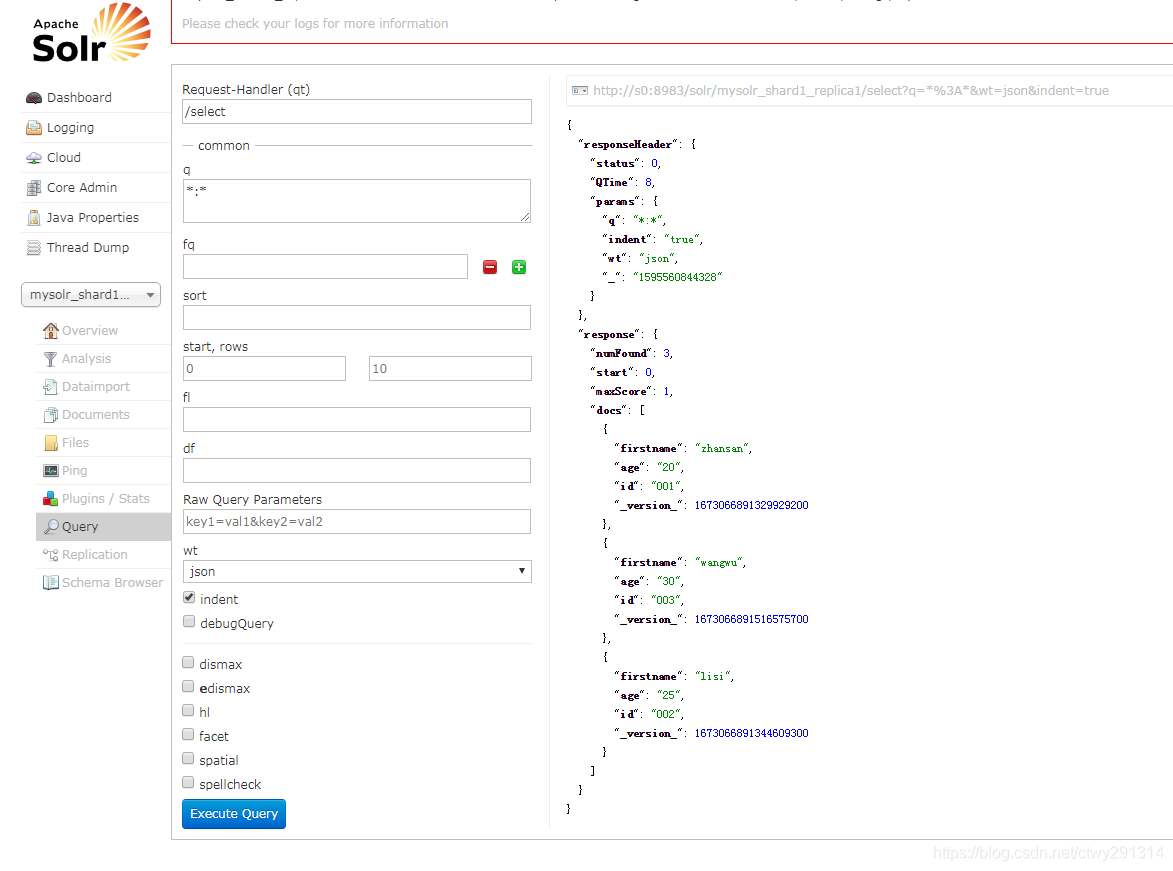
方案二
相关解释请参照方案一
-
创建测试表
create 'user', { NAME => 'info', REPLICATION_SCOPE => '1' } -
创建相应的SolrCloud集合
①生成实体配置文件
solrctl instancedir --generate /opt/tsolr②命令完成后会在指定的路径下生成目录,目录下有个子目录conf,修改conf中的schema.xml,在最后添加一个节点如下

<field name="firstname" type="string" indexed="true" stored="true" required="false" multiValued="false" /> <field name="age" type="string" indexed="true" stored="true" required="false" multiValued="false" />③修改 solrconfig.xml,找到下面的配置片段,将false改为true,这个是硬提交,会影响性能
<autoCommit> <maxTime>${solr.autoCommit.maxTime:60000}</maxTime> <openSearcher>true</openSearcher> </autoCommit>
④上传配置文件到zookeepersolrctl instancedir --create tsolr /opt/tsolr⑤上传后,zk会自己同步配置,然后创建collection,
solrctl collection --create tsolrhttp://s0:8983/solr/#/~cloud > Cloud >Graph查看

当创建collection命令完成后,可以在solr 的web页面上看到mysolr开头的选择器,只不过没有数据。
⑥创建 Lily HBase Indexer 配置
在/opt/tsolr/目录下,创建indexdemo-user.xml文件,
目录地址和文件名称可自定义,内容如下。<?xml version="1.0"?> <indexer table="users" mapper="com.ngdata.hbaseindexer.morphline.MorphlineResultToSolrMapper"> <param name="morphlineFile" value="morphlines.conf"/> <param name="morphlineId" value="userMap"/> </indexer>注:
table属性表示hbase中要建立索引的表
value=“morphlines.conf”,value用来指定morphlines.conf文件的路径,绝对或者相对路径用来指定本地路径,如果是使用Cloudera Manager来管理morphlines.conf就直接写入值morphlines.conf。
value=“userMap”,这里userMap是自定义,接下来要使用,
其他的mapper,param name等属性默认即可⑦配置morphlines.conf文件,通过CM搜索
Key-Value Store Indexer页面进入到Key-Value Store Indexer的配置页面,里面有一个Morphlines文件。
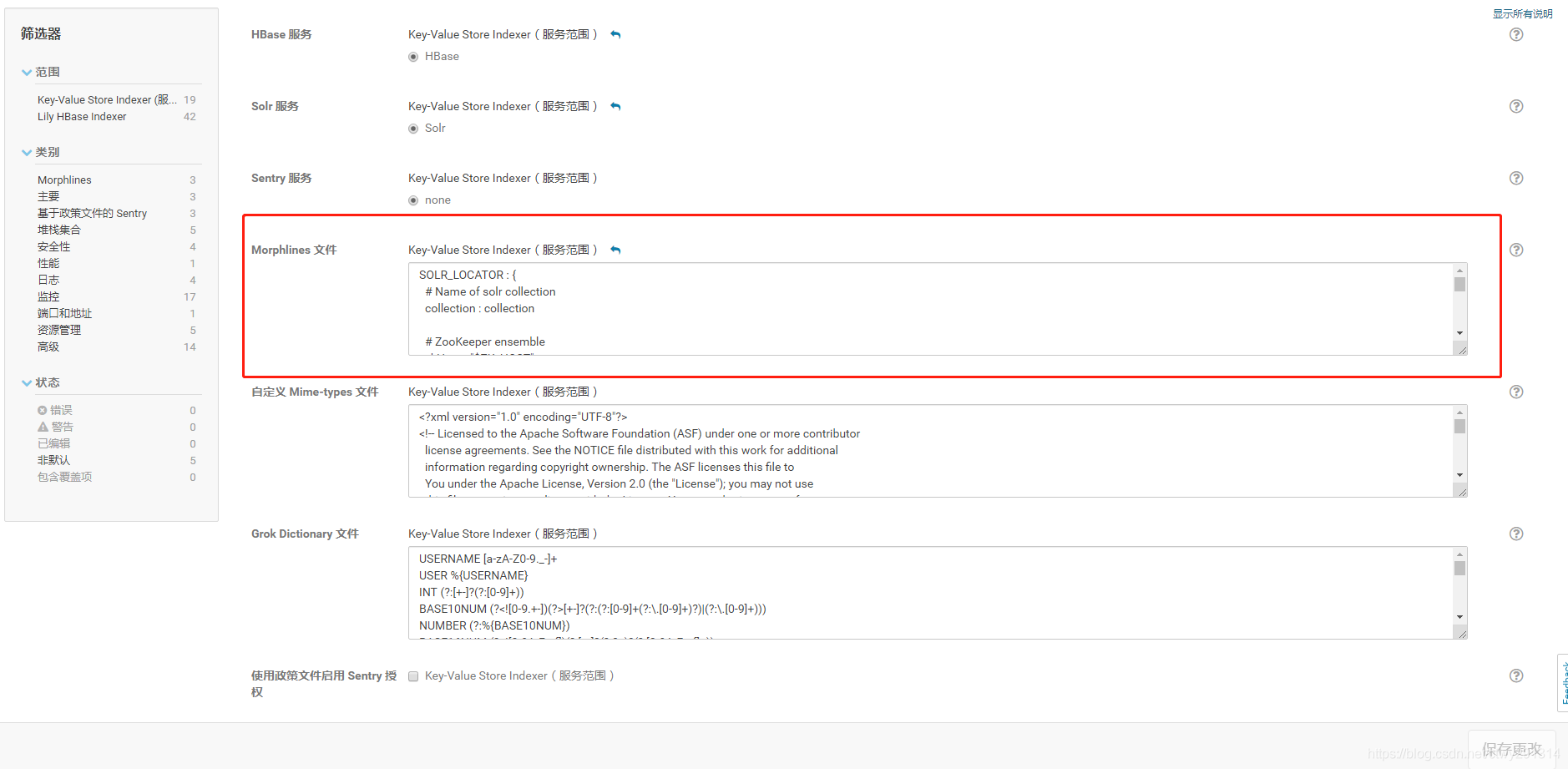
具体配置内容如下:SOLR_LOCATOR : { # Name of solr collection # collection : collection # ZooKeeper ensemble zkHost : "$ZK_HOST" } morphlines : [ { id :userMap importCommands : ["org.kitesdk.**", "com.ngdata.**"] commands : [ { extractHBaseCells { mappings : [ { inputColumn : "info:firstname" outputField : "firstname" type : string source : value }, { inputColumn : "info:age" outputField : "age" type : string source : value } ] } } { logDebug { format : "output record: {}", args : ["@{}"] } } ] } ]注:
id:表示当前morphlines的名称,与上一步的value="userMap"要一致: importCommands:需要引入的命令包地址: extractHBaseCells:该命令用来读取HBase列数据并写入到SolrInputDocument对象中, 该命令必须包含零个或者多个mappings命令对象。 mappings:用来指定HBase列限定符的字段映射。 inputColumn:需要写入到solr中的HBase列字段。值包含列族和列限定符,并用‘ : ’分开。 其中列限定符也可以使用通配符*来表示, 譬如可以使用c1:*表示读取只要列族为data的所有hbase列数据, 也可以通过c1:na*来表示读取列族为c1列限定符已na开头的字段值. outputField:用来表示morphline读取的记录需要输出的数据字段名称, 该名称必须和solr中的schema.xml文件的field节点自定义的name名称保持一致,否则写入不正确 type:用来定义读取HBase数据的数据类型,HBase中的数据都是以byte[]的形式保存, 但是所有的内容在Solr中索引为text形式,所以需要一个方法来把byte[]类型转换为实际的数据类型。 type参数的值就是用来做这件事情的。 现在支持的数据类型有:byte,int,long,string,boolean,float,double,short和bigdecimal。 当然你也可以指定自定的数据类型,只需要实现com.ngdata.hbaseindexer.parse.ByteArrayValueMapper接口即可 source:用来指定HBase的KeyValue那一部分作为索引输入数据, 可选的有‘value’和'qualifier',当为value的时候表示使用HBase的列值作为索引输入, 当为qualifier的时候表示使用HBase的列限定符作为索引输入⑧修改后,保存,重启Key-Value Store Indexer。
⑨注册 Lily HBase Indexer Configuration 和 Lily HBase Indexer Service
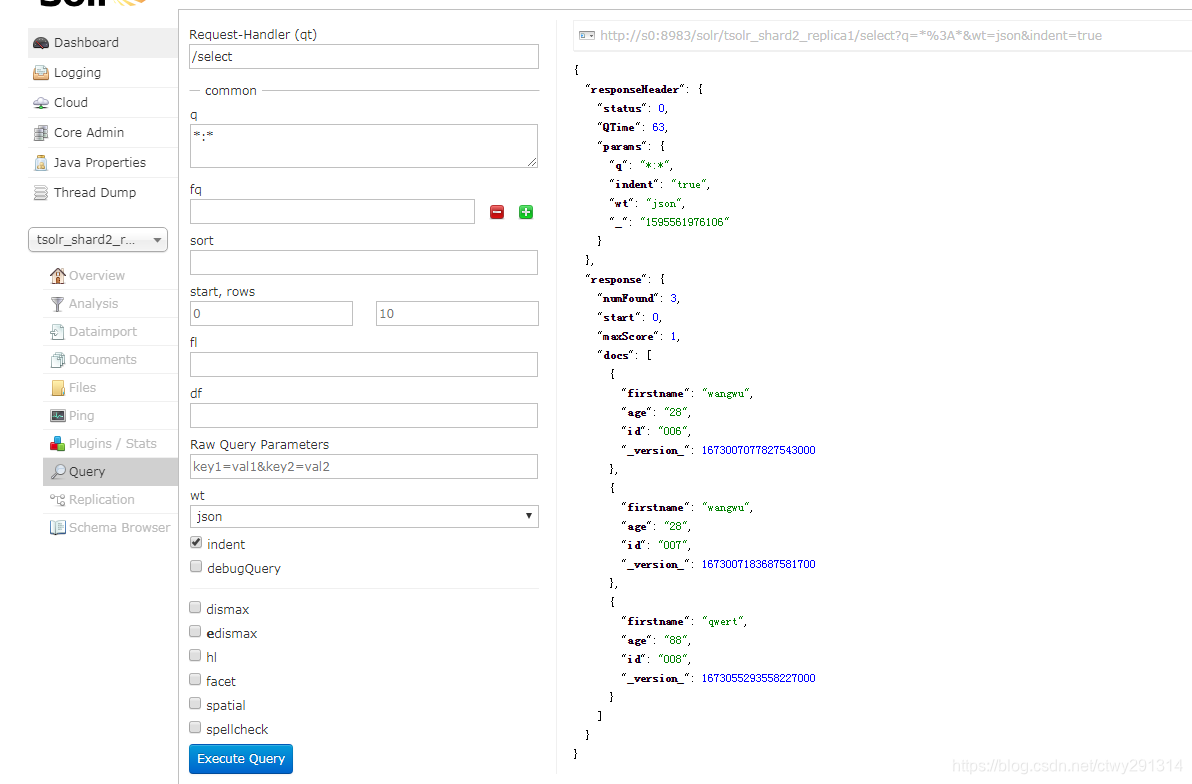
hbase-indexer add-indexer -n myindexer -c /opt/tsolr/indexdemo-user.xml -cp solr.zk=S0:2181,S1:2181,S2:2181,S3:2181/solr -cp solr.collection=tsolr⑩在hbase中插入数据
put 'users','006','info:firstname','wangwu' put 'users','006','info:age','28' put 'users','007','info:firstname','wangwu' put 'users','007','info:age','28' put 'users','008','info:firstname','qwert' put 'users','008','info:age','88'在solr中查看索引,打开地址为:solr节点ip:8983/solr,查看结果如下
卸载索引
如果想删除索引,倒着来就可以了
①键入hbase-indexer命令,有delete-indexer和 list-indexers可使用,若忘记了刚刚自己定义的indexer名称,可使用hbase-indexer list-indexers查看,然后删除
hbase-indexer delete-indexer --name mysolr
②到Key-Value Store Indexer的配置页面,把Morphlines文件中相关配置删除,也可不删,等创建其他索引的时候在该基础上改,或者删除也可
③删除collection,如果忘记名称,使用solrctl collection --list查看
solrctl collection --delete mysolr
上述指令会将Solr中该Collection中的数据进行清空。
solrctl collection --delete mysolr
上述指令会将SolrCloud中的Collection进行删除,在Solr的可视化界面将无法看到该Collection的分片数据。
④删除zk上的配置文件,如果忘记名称,使用solrctl instancedir --list查看
solrctl instancedir --delete mysolr
⑤删除本地配置
rm -rf /opt/mysolr
批量同步索引
如果对一个已经存在数据的hbase表做了索引,会发现只记录了后面插入的数据,已经存在的数据没有索引。那么就要将之前的数据的索引同步上
方案一
我使用的是CM5.16.2,JAR的路径是/opt/cloudera/parcels/CDH-5.16.2-1.cdh5.16.2.p0.8/lib/hbase-solr/tools/
hadoop jar /opt/cloudera/parcels/CDH-5.16.2-1.cdh5.16.2.p0.8/lib/hbase-solr/tools/hbase-indexer-mr-job.jar --hbase-indexer-file /opt/mysolr/mytest.xml --zk-host S0:2181,S1:2181,S2:2181,S3:2181/solr --collection mysolr --go-live
注: jar:后面的jar路径需要查看所使用的cloudera安装目录下的jar包具体名字
–hbase-indexer-file:/opt/mysolr/mytest.xml文件路径,如果执行命令的节点该文件不存在,则从存在的机器上复制过来即可
默认会出现以下异常:
setfacl: The ACL operation has been rejected. Support for ACLs has been disabled by setting dfs.namenode.acls.enabled to false.
解决方案如下,在hdfs-site.xml文件中添加如下配置即可
<property>
<name>dfs.namenode.acls.enabled</name>
<value>true</value>
</property>
在CM中搜索dfs.namenode.acls.enabled如下图

修改后,保存,重启HDFS,之后重新执行上述命令。
方案二
在hbase的master节点上,执行命令,查看morphlines.conf文件位置:
find / |grep morphlines.conf$

运行以下命令进行索引同步
hadoop jar /opt/cloudera/parcels/CDH-5.16.2-1.cdh5.16.2.p0.8/lib/hbase-solr/tools/hbase-indexer-mr-job.jar --hbase-indexer-file /opt/tsolr/indexdemo-user.xml --zk-host S0:2181,S1:2181,S2:2181,S3:2181/solr --collection tsolr --go-live --log4j /opt/tsolr/log4j.properties --morphline-file /opt/tsolr/morphlines.conf
注: jar:后面的jar路径需要查看所使用的cloudera安装目录下的jar包具体名字
–hbase-indexer-file:/opt/mysolr/mytest.xml文件路径,如果执行命令的节点该文件不存在,则从存在的机器上复制过来即可
–log4j:log4j.properties的文件路径
–morphline-file:morphlines.conf文件路径
注意:在不配置–morphline-file的情况下,在运行命令的目录下必须有morphlines.conf文件。
更新索引
这里分为两种情况。
①索引还未建立完成想修改配置,或者索引建立完成,还未插入数据,想修改配置。比如想修改schema.xml,增加一个field字段,如下操作
修改schema.xml
更新配置文件;
solrctl instancedir --update mysolr /opt/mysolr
更新collection;
solrctl collection --reload mysolr
-
对于采用方案二创建索引的,如果还想更改
morphline.conf文件中指定的列族,列名等,修改后重启Key-Value Store Indexer,然后插入hbase数据即可。 -
对于方案一 创建索引的,果还想更改
mytest.xml文件中指定的列族,列名等,修改后执行hbase-indexer update-indexer -n myindexer2 -c /opt/mysolr/mytest.xml -cp solr.zk=S0:2181,S1:2181,S2:2181,S3:2181/solr -cp solr.collection=mysolr
②如果索引已经建立,已经有了索引数据,想要修改索引,则要先删除索引数据集,清空数据集可以通过solr API来完成,也可以在命令行中完成,键入如下命令:
首先清空该collection;
solrctl collection --deletedocs test4
按照上面的操作,修改配置;
但是现在只有新插入的数据才有索引,需要使用上面批量同步索引的方法,将以前的数据的索引重新创建好。
参考
https://docs.cloudera.com/documentation/enterprise/5-16-x/topics/search_hbase_batch_indexer.html
https://blog.csdn.net/u010936936/article/details/78064148
https://www.cnblogs.com/wanchen-chen/p/12934093.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架