

CDH版本Hbase二级索引详细配置方案Solr key value index(二)中文分词
前提
已完成二级索引创建,请参照:https://gaoming.blog.csdn.net/article/details/107555193
目前有很多优秀的中文分词组件。本篇只以 IKAnalyzer 分词为例,讲解如何在 solr 中及集成中文分词,使用 IKAnalyzer的原因 IK 比其他中文分词维护的勤快,和 Solr 集成也相对容易。
IK Analyzer 分词安装
-
下载
官方地址:https://gitee.com/wltea/IK-Analyzer-2012FF/
下载完成后需自行编译,可以在此地址下载编译完成的版本。 -
上传相关文件
①将
IKAnalyzer2012FF_u1.jar上传至/opt/cloudera/parcels/CDH-5.16.2-1.cdh5.16.2.p0.8/lib/solr/webapps/solr/WEB-INF/lib目录

②在
/opt/cloudera/parcels/CDH-5.16.2-1.cdh5.16.2.p0.8/lib/solr/webapps/solr/WEB-INF目录下创建目录classes,然后把IKAnalyzer.cfg.xml和stopword.dic拷贝到新创建的classes目录下即可

③将
IKAnalyzer2012FF_u1.jar上传至/opt/cloudera/parcels/CDH-5.16.2-1.cdh5.16.2.p0.8/lib/hadoop-yarn目录
-
将相关配置复制到集群中的其他机器
scp /opt/cloudera/parcels/CDH-5.16.2-1.cdh5.16.2.p0.8/lib/solr/webapps/solr/WEB-INF/lib/IKAnalyzer2012FF_u1.jar root@192.168.3.18:/opt/cloudera/parcels/CDH-5.16.2-1.cdh5.16.2.p0.8/lib/solr/webapps/solr/WEB-INF/lib/ scp /opt/cloudera/parcels/CDH-5.16.2-1.cdh5.16.2.p0.8/lib/solr/webapps/solr/WEB-INF/lib/IKAnalyzer2012FF_u1.jar root@192.168.3.161:/opt/cloudera/parcels/CDH-5.16.2-1.cdh5.16.2.p0.8/lib/solr/webapps/solr/WEB-INF/lib/ scp /opt/cloudera/parcels/CDH-5.16.2-1.cdh5.16.2.p0.8/lib/solr/webapps/solr/WEB-INF/lib/IKAnalyzer2012FF_u1.jar root@192.168.3.136:/opt/cloudera/parcels/CDH-5.16.2-1.cdh5.16.2.p0.8/lib/solr/webapps/solr/WEB-INF/lib/ scp /opt/cloudera/parcels/CDH-5.16.2-1.cdh5.16.2.p0.8/lib/solr/webapps/solr/WEB-INF/lib/IKAnalyzer2012FF_u1.jar root@192.168.3.18:/opt/cloudera/parcels/CDH-5.16.2-1.cdh5.16.2.p0.8/lib/hadoop-yarn scp /opt/cloudera/parcels/CDH-5.16.2-1.cdh5.16.2.p0.8/lib/solr/webapps/solr/WEB-INF/lib/IKAnalyzer2012FF_u1.jar root@192.168.3.161:/opt/cloudera/parcels/CDH-5.16.2-1.cdh5.16.2.p0.8/lib/hadoop-yarn scp /opt/cloudera/parcels/CDH-5.16.2-1.cdh5.16.2.p0.8/lib/solr/webapps/solr/WEB-INF/lib/IKAnalyzer2012FF_u1.jar root@192.168.3.136:/opt/cloudera/parcels/CDH-5.16.2-1.cdh5.16.2.p0.8/lib/hadoop-yarn scp -r /opt/cloudera/parcels/CDH-5.16.2-1.cdh5.16.2.p0.8/lib/solr/webapps/solr/WEB-INF/lib/classes root@192.168.3.18:/opt/cloudera/parcels/CDH-5.16.2-1.cdh5.16.2.p0.8/lib/solr/webapps/solr/WEB-INF/lib/classes scp -r /opt/cloudera/parcels/CDH-5.16.2-1.cdh5.16.2.p0.8/lib/solr/webapps/solr/WEB-INF/lib/classes root@192.168.3.161:/opt/cloudera/parcels/CDH-5.16.2-1.cdh5.16.2.p0.8/lib/solr/webapps/solr/WEB-INF/lib/classes scp -r /opt/cloudera/parcels/CDH-5.16.2-1.cdh5.16.2.p0.8/lib/solr/webapps/solr/WEB-INF/lib/classes root@192.168.3.136:/opt/cloudera/parcels/CDH-5.16.2-1.cdh5.16.2.p0.8/lib/solr/webapps/solr/WEB-INF/lib/classes -
重启Solr集群
IK Analyzer 分词使用
以 https://gaoming.blog.csdn.net/article/details/107555193 为基础,在已创建完成的索引上进行修改
hbase-indexer delete-indexer -n myindexer2
solrctl collection --delete mysolr
solrctl instancedir --delete mysolr
hdfs dfs -rm -r /solr/mysolr
以前未创建索引可不执行上述命令
执行:solrctl instancedir --generate /opt/mysolr生成实体配置文件
-
修改schema.xml文件
在schema.xml文件中新增以下内容:
<!-- 我添加的IK分词 --> <fieldType name="text_ik" class="solr.TextField"> <analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/> <analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType>
同时,把需要分词的字段,设置为text_ik<field name="firstname" type="text_ik" indexed="true" stored="true" required="true" multiValued="false" />
-
新增或更新索引
solrctl instancedir --create mysolr /opt/mysolr solrctl collection --create mysolr -s 2 -c mysolr -r 2 -m 3 -a hbase-indexer add-indexer -n myindexer2 -c /opt/mysolr/mytest.xml -cp solr.zk=S0:2181,S1:2181,S2:2181,S3:2181/solr -cp solr.collection=mysolr -
批量同步索引
hadoop jar /opt/cloudera/parcels/CDH-5.16.2-1.cdh5.16.2.p0.8/lib/hbase-solr/tools/hbase-indexer-mr-job.jar --hbase-indexer-file /opt/mysolr/mytest.xml --zk-host S0:2181,S1:2181,S2:2181,S3:2181/solr --collection mysolr --go-live -
手动插入数据
put 'mytest','001','info:firstname','张三' put 'mytest','001','info:age','20' put 'mytest','002','info:firstname','李四' put 'mytest','002','info:age','25' put 'mytest','003','info:firstname','王五' put 'mytest','003','info:age','30'
验证
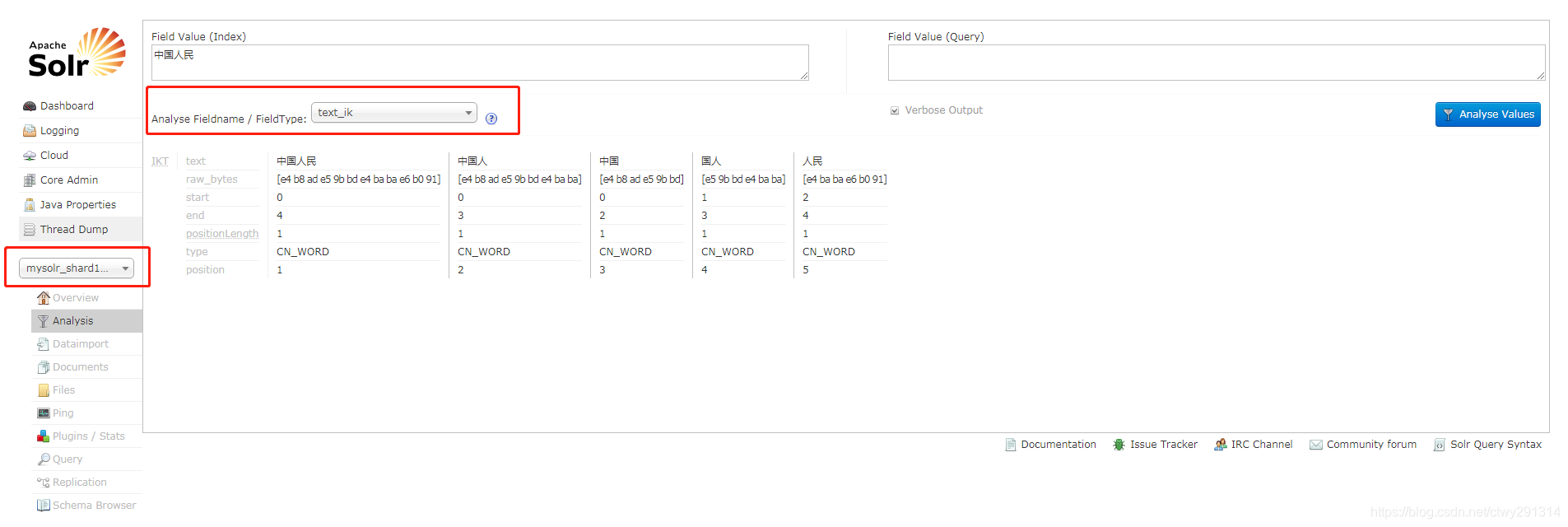
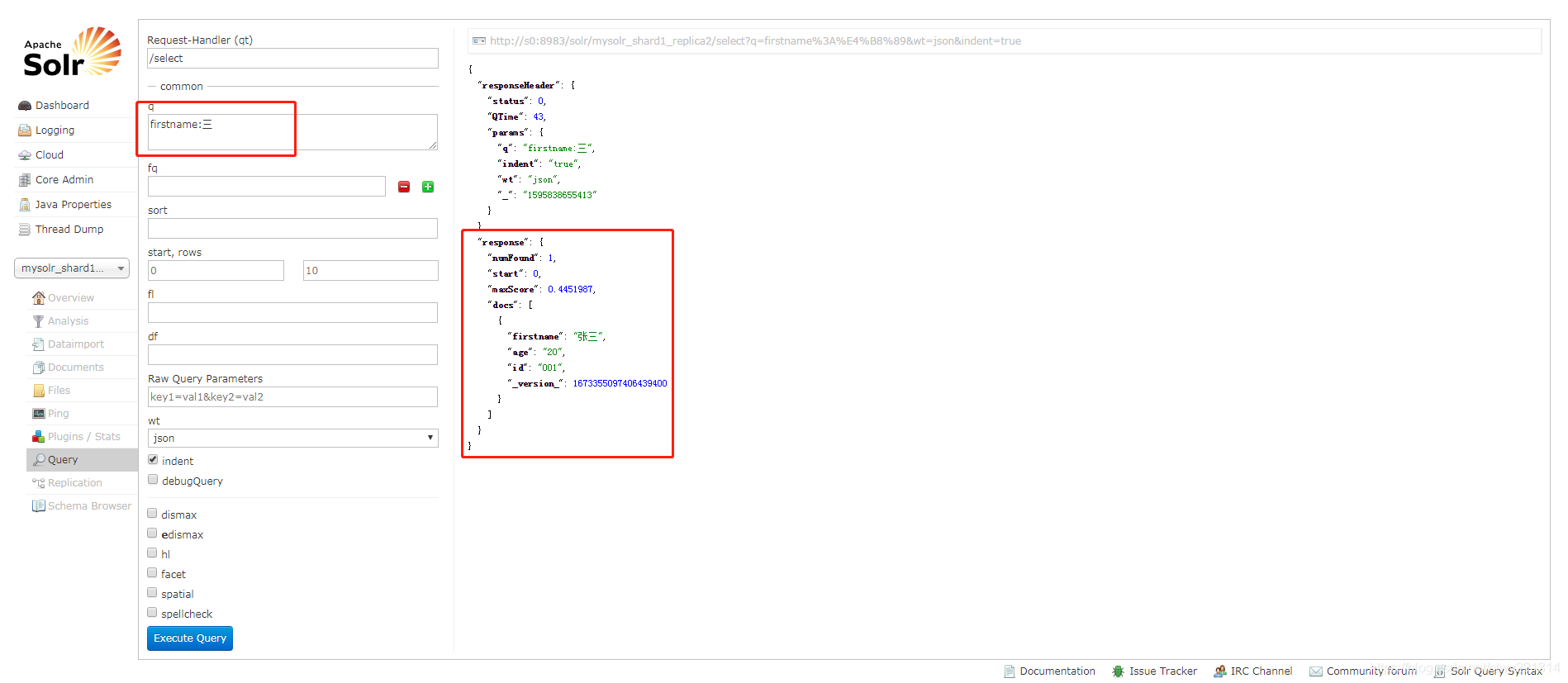
进入solr web界面http://s0:8983/solr,看到下图操作结果即为配置成功
lucene-analyzers-smartcn 分词
- 下载地址
https://repository.cloudera.com/artifactory/cdh-releases-rcs/org/apache/lucene/lucene-analyzers-smartcn/4.10.3-cdh5.16.2/
- 配置方式
<!-- 配置中文分词器 -->
<fieldType name="text_zh" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
</fieldType>


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架