

pyspark On Yarn 的模块依赖问题
创建自定义模块
dependency/mydata.py,这个模块被主函数依赖
data = range(100)
创建主程序
引入自定义模块,进行数据打印和和保存至HDFS
# -*- coding: utf-8 -*-
from pyspark import SparkContext
from dependency.mydata import data # 自己写的模块
# 获取spark的上下文
sc = SparkContext()
sc.setLogLevel('WARN')
out = sc.parallelize(data)
print(out.collect())
# out是RDD格式需调用.toDF()转为spark.dataFrame格式
df = out.toDF()
df.show()
out.saveAsTextFile("hdfs://s0:8020/input/text")
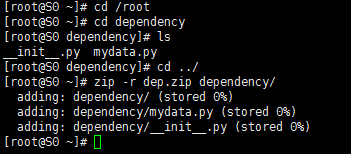
自定义模块打压缩包
[root@S0 ~]# cd /root
[root@S0 ~]# cd dependency
[root@S0 dependency]# ls
__init__.py mydata.py
[root@S0 dependency]# cd ../
[root@S0 ~]# zip -r dep.zip dependency/
adding: dependency/ (stored 0%)
adding: dependency/mydata.py (stored 0%)
adding: dependency/__init__.py (stored 0%)
执行命令
spark-submit --master yarn --deploy-mode cluster --py-files /root/dep.zip /root/Demo6.py
注:压缩文件必须是全路径,即使它在 PYTHONPATH 环境变量内,不写全路径也会报错 file do not exist
--py-files
它是 spark-submit 的参数,官方解释如下:
Comma-separated list of .zip, .egg, or .py files to place on the PYTHONPATH for Python apps.
用逗号分隔的 zip、egg、py 文件列表来代替 PYTHONPATH 环境变量


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架