
轻量级车牌检测开源项目(支持车牌四顶点定位、车牌矫正对齐)
先看效果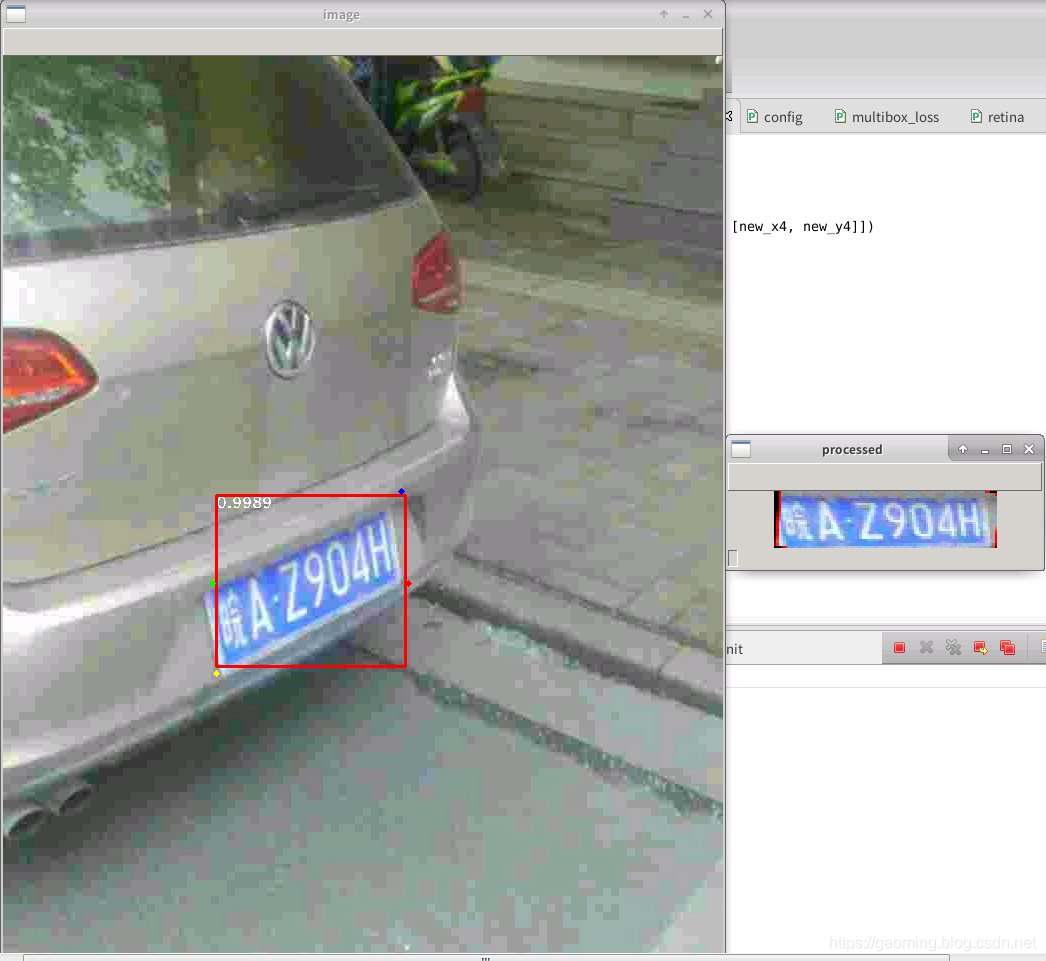
项目地址
https://github.com/gm19900510/Pytorch_Retina_License_Plate
内容
- 环境说明
- 安装
- 数据
- 训练
- TODO
- 参考文献
环境说明
- python=3.7
- pytorch=1.2.0
- torchvision=0.4.0
- cudatoolkit=10.0
- cudnn=7.6.4
安装
- 克隆并安装
git clone https://github.com/biubug6/Pytorch_Retinaface.git
数据
地址
https://github.com/detectRecog/CCPD
数据容量
| CCPD | 数量/k | 描述 |
|---|---|---|
| Base | 200 | 正常车牌 |
| FN | 20 | 距离摄像头相当的远或者相当近 |
| DB | 20 | 光线暗或者比较亮 |
| Rotate | 10 | 水平倾斜20-25°,垂直倾斜-10-10° |
| Tilt | 10 | 水平倾斜15-45°,垂直倾斜15-45° |
| Weather | 10 | 在雨天,雪天,或者雾天 |
| Blur | 5 | 由于相机抖动造成的模糊 |
| Challenge | 10 | 其他的比较有挑战性的车牌 |
| NP | 5 | 没有车牌的新车 |
注释说明
注释嵌入在文件名中。
样本图像名称为“ 025-95_113-154&383_386&473-386&473_177&454_154&383_363&402-0_0_22_27_27_33_16-37-15.jpg”。每个名称可以分为七个字段。这些字段解释如下。
-
面积:牌照面积与整个图片区域的面积比。
-
倾斜度:水平倾斜程度和垂直倾斜度。
-
边界框坐标:左上和右下顶点的坐标。
-
四个顶点位置:整个图像中LP的四个顶点的精确(x,y)坐标。这些坐标从右下角->左下角->左上角->右上角
车牌号:CCPD中的每个图像只有一个LP。每个LP号码由一个汉字,一个字母和五个字母或数字组成。有效的中文车牌由七个字符组成:省(1个字符),字母(1个字符),字母+数字(5个字符)。0_0_22_27_27_33_16”是每个字符的索引。这三个数组定义如下。每个数组的最后一个字符是字母O,而不是数字0。我们将O用作“无字符”的符号,因为中文车牌字符中没有O。
provinces = ["皖", "沪", "津", "渝", "冀", "晋", "蒙", "辽", "吉", "黑", "苏", "浙", "京", "闽", "赣", "鲁", "豫", "鄂", "湘", "粤", "桂", "琼", "川", "贵", "云", "藏", "陕", "甘", "青", "宁", "新", "警", "学", "O"]
alphabets = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W',
'X', 'Y', 'Z', 'O']
ads = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X',
'Y', 'Z', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'O']
模型训练
-
数据预处理
cd Pytorch_Retina_License_Plate/prepare_data
python reformat_CCPD.py
python dataset_provider.py注意修改执行文件中的数据集地址
-
训练
培训之前,您可以在中检查网络配置(例如batch_size,min_sizes和步骤等。)data/config.py and train.py。
CUDA_VISIBLE_DEVICES = 0,1,2,3 python train.py --network resnet50或
CUDA_VISIBLE_DEVICES = 0 python train.py --network mobile0.25
测试
python detect.py -m ./weights/mobilenet0.25_epoch_19_ccpd.pth -image test_images/0.jpg
效果更好的预训练模型在后期陆续提供
请大家多多支持与star,后续开源车牌识别项目

