
JVM 运行时数据区域划分
目录
前言
我们知道,计算机CPU和内存的交互是最频繁的,内存是我们的高速缓存区,用户磁盘和CPU的交互,而CPU运转速度越来越快,磁盘远远跟不上CPU的读写速度,才设计了内存,用户缓冲用户IO等待导致CPU的等待成本,但是随着CPU的发展,内存的读写速度也远远跟不上CPU的读写速度,因此,为了解决这一纠纷,CPU厂商在每颗CPU上加入了高速缓存,用来缓解这种症状,因此,现在CPU同内存交互就变成了下面的样子。

同样,根据摩尔定律,我们知道单核CPU的主频不可能无限制的增长,要想很多的提升新能,需要多个处理器协同工作, Intel总裁的贝瑞特单膝下跪事件标志着多核时代的到来。

基于高速缓存的存储交互很好的解决了处理器与内存之间的矛盾,也引入了新的问题:缓存一致性问题。在多处理器系统中,每个处理器有自己的高速缓存,而他们又共享同一块内存(下文成主存,main memory 主要内存),当多个处理器运算都涉及到同一块内存区域的时候,就有可能发生缓存不一致的现象。为了解决这一问题,需要各个处理器运行时都遵循一些协议,在运行时需要将这些协议保证数据的一致性。这类协议包括MSI、MESI、MOSI、Synapse、Firely、DragonProtocol等。如下图所示

什么是JVM
JVM是Java Virtual Machine(Java虚拟机)的缩写,JVM是一种用于计算设备的规范,它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。Java虚拟机包括一套字节码指令集、一组寄存器、一个栈、一个垃圾回收堆和一个存储方法域。
JRE/JDK/JVM是什么关系
JRE(JavaRuntimeEnvironment,Java运行环境),也就是Java平台。所有的Java 程序都要在JRE下才能运行。普通用户只需要运行已开发好的java程序,安装JRE即可。
JDK(Java Development Kit)是程序开发者用来来编译、调试java程序用的开发工具包。JDK的工具也是Java程序,也需要JRE才能运行。为了保持JDK的独立性和完整性,在JDK的安装过程中,JRE也是安装的一部分。所以,在JDK的安装目录下有一个名为jre的目录,用于存放JRE文件。
JVM(JavaVirtualMachine,Java虚拟机)是JRE的一部分。它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。JVM有自己完善的硬件架构,如处理器、堆栈、寄存器等,还具有相应的指令系统。Java语言最重要的特点就是跨平台运行。使用JVM就是为了支持与操作系统无关,实现跨平台。
JVM执行程序的过程
1) 加载.class文件
2) 管理并分配内存
3) 执行垃圾收集
JRE(java运行时环境)是JVM构造的java程序的运行环境,也是Java程序运行的环境,但是一个操作系统的一个应用程序一个进程也有他自己的运行的生命周期,也有自己的代码和数据空间。JVM在整个jdk中处于最底层,负责于操作系统的交互,用来屏蔽操作系统环境,提供一个完整的Java运行环境,因此也就虚拟计算机。操作系统装入JVM是通过jdk中Java.exe来完成,通过下面4步来完成JVM环境:
1) 创建JVM装载环境和配置
2) 装载JVM.dll
3) 初始化JVM.dll并挂界到JNIENV(JNI调用接口)实例
4) 调用JNIEnv实例装载并处理class类。
JVM的生命周期
1) JVM实例对应了一个独立运行的java程序它是进程级别
a) 启动。启动一个Java程序时,一个JVM实例就产生了,任何一个拥有public static void main(String[] args)函数的class都可以作为JVM实例运行的起点
b) 运行。main()作为该程序初始线程的起点,任何其他线程均由该线程启动。JVM内部有两种线程:守护线程和非守护线程,main()属于非守护线程,守护线程通常由JVM自己使用,java程序也可以表明自己创建的线程是守护线程
c) 消亡。当程序中的所有非守护线程都终止时,JVM才退出;若安全管理器允许,程序也可以使用Runtime类或者System.exit()来退出
2) JVM执行引擎实例则对应了属于用户运行程序的线程它是线程级别的
JVM垃圾回收
GC (Garbage Collection)的基本原理:将内存中不再被使用的对象进行回收,GC中用于回收的方法称为收集器,由于GC需要消耗一些资源和时间,Java在对对象的生命周期特征进行分析后,按照新生代、旧生代的方式来对对象进行收集,以尽可能的缩短GC对应用造成的暂停
(1)对新生代的对象的收集称为minor GC;
(2)对旧生代的对象的收集称为Full GC;
(3)程序中主动调用System.gc()强制执行的GC为Full GC。
不同的对象引用类型, GC会采用不同的方法进行回收,JVM对象的引用分为了四种类型:
(1)强引用:默认情况下,对象采用的均为强引用(这个对象的实例没有其他对象引用,GC时才会被回收)
(2)软引用:软引用是Java中提供的一种比较适合于缓存场景的应用(只有在内存不够用的情况下才会被GC)
(3)弱引用:在GC时一定会被GC回收
(4)虚引用:由于虚引用只是用来得知对象是否被GC

JVM的内存区域划分
学过C语言的朋友都知道C编译器在划分内存区域的时候经常将管理的区域划分为数据段和代码段,数据段包括堆、栈以及静态数据区。那么在Java语言当中,内存又是如何划分的呢?
由于Java程序是交由JVM执行的,所以我们在谈Java内存区域划分的时候事实上是指JVM内存区域划分。在讨论JVM内存区域划分之前,先来看一下Java程序具体执行的过程:


如上图所示,首先Java源代码文件(.java后缀)会被Java编译器编译为字节码文件(.class后缀),然后由JVM中的类加载器加载各个类的字节码文件,加载完毕之后,交由JVM执行引擎执行。在整个程序执行过程中,JVM会用一段空间来存储程序执行期间需要用到的数据和相关信息,这段空间一般被称作为Runtime Data Area(运行时数据区),也就是我们常说的JVM内存。因此,在Java中我们常常说到的内存管理就是针对这段空间进行管理(如何分配和回收内存空间)。
在知道了JVM内存是什么东西之后,下面我们就来讨论一下这段空间具体是如何划分区域的,是不是也像C语言中一样也存在栈和堆呢?
一.运行时数据区包括哪几部分?
根据《Java虚拟机规范》的规定,运行时数据区通常包括这几个部分:程序计数器(Program Counter Register)、Java栈(VM Stack)、本地方法栈(Native Method Stack)、方法区(Method Area)、堆(Heap)。

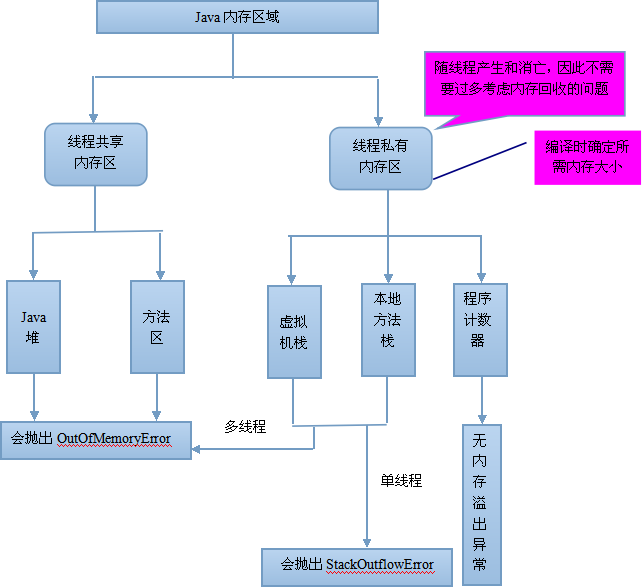
如上图所示,JVM中的运行时数据区应该包括这些部分。在JVM规范中虽然规定了程序在执行期间运行时数据区应该包括这几部分,但是至于具体如何实现并没有做出规定,不同的虚拟机厂商可以有不同的实现方式。
二.运行时数据区的每部分到底存储了哪些数据?
下面我们来了解一下运行时数据区的每部分具体用来存储程序执行过程中的哪些数据。
1.程序计数器
程序计数器(Program Counter Register),也有称作为PC寄存器。想必学过汇编语言的朋友对程序计数器这个概念并不陌生,在汇编语言中,程序计数器是指CPU中的寄存器,它保存的是程序当前执行的指令的地址(也可以说保存下一条指令的所在存储单元的地址),当CPU需要执行指令时,需要从程序计数器中得到当前需要执行的指令所在存储单元的地址,然后根据得到的地址获取到指令,在得到指令之后,程序计数器便自动加1或者根据转移指针得到下一条指令的地址,如此循环,直至执行完所有的指令。
虽然JVM中的程序计数器并不像汇编语言中的程序计数器一样是物理概念上的CPU寄存器,但是JVM中的程序计数器的功能跟汇编语言中的程序计数器的功能在逻辑上是等同的,也就是说是用来指示 执行哪条指令的。
由于在JVM中,多线程是通过线程轮流切换来获得CPU执行时间的,因此,在任一具体时刻,一个CPU的内核只会执行一条线程中的指令,因此,为了能够使得每个线程都在线程切换后能够恢复在切换之前的程序执行位置,每个线程都需要有自己独立的程序计数器,并且不能互相被干扰,否则就会影响到程序的正常执行次序。因此,可以这么说,程序计数器是每个线程所私有的。
在JVM规范中规定,如果线程执行的是非native方法,则程序计数器中保存的是当前需要执行的指令的地址;如果线程执行的是native方法,则程序计数器中的值是undefined。
由于程序计数器中存储的数据所占空间的大小不会随程序的执行而发生改变,因此,对于程序计数器是不会发生内存溢出现象(OutOfMemory)的。
2.Java栈
Java栈也称作虚拟机栈(Java Vitual Machine Stack),也就是我们常常所说的栈,跟C语言的数据段中的栈类似。事实上,Java栈是Java方法执行的内存模型。为什么这么说呢?下面就来解释一下其中的原因。
Java栈中存放的是一个个的栈帧,每个栈帧对应一个被调用的方法,在栈帧中包括局部变量表(Local Variables)、操作数栈(Operand Stack)、指向当前方法所属的类的运行时常量池(运行时常量池的概念在方法区部分会谈到)的引用(Reference to runtime constant pool)、方法返回地址(Return Address)和一些额外的附加信息。当线程执行一个方法时,就会随之创建一个对应的栈帧,并将建立的栈帧压栈。当方法执行完毕之后,便会将栈帧出栈。因此可知,线程当前执行的方法所对应的栈帧必定位于Java栈的顶部。讲到这里,大家就应该会明白为什么 在 使用 递归方法的时候容易导致栈内存溢出的现象了以及为什么栈区的空间不用程序员去管理了(当然在Java中,程序员基本不用关系到内存分配和释放的事情,因为Java有自己的垃圾回收机制),这部分空间的分配和释放都是由系统自动实施的。对于所有的程序设计语言来说,栈这部分空间对程序员来说是不透明的。下图表示了一个Java栈的模型:

局部变量表,顾名思义,想必不用解释大家应该明白它的作用了吧。就是用来存储方法中的局部变量(包括在方法中声明的非静态变量以及函数形参)。对于基本数据类型的变量,则直接存储它的值,对于引用类型的变量,则存的是指向对象的引用。局部变量表的大小在编译器就可以确定其大小了,因此在程序执行期间局部变量表的大小是不会改变的。
操作数栈,想必学过数据结构中的栈的朋友想必对表达式求值问题不会陌生,栈最典型的一个应用就是用来对表达式求值。想想一个线程执行方法的过程中,实际上就是不断执行语句的过程,而归根到底就是进行计算的过程。因此可以这么说,程序中的所有计算过程都是在借助于操作数栈来完成的。
指向运行时常量池的引用,因为在方法执行的过程中有可能需要用到类中的常量,所以必须要有一个引用指向运行时常量。
方法返回地址,当一个方法执行完毕之后,要返回之前调用它的地方,因此在栈帧中必须保存一个方法返回地址。
由于每个线程正在执行的方法可能不同,因此每个线程都会有一个自己的Java栈,互不干扰。
3.本地方法栈
本地方法栈与Java栈的作用和原理非常相似。区别只不过是Java栈是为执行Java方法服务的,而本地方法栈则是为执行本地方法(Native Method)服务的。在JVM规范中,并没有对本地方发展的具体实现方法以及数据结构作强制规定,虚拟机可以自由实现它。在HotSopt虚拟机中直接就把本地方法栈和Java栈合二为一。
4.堆
在C语言中,堆这部分空间是唯一一个程序员可以管理的内存区域。程序员可以通过malloc函数和free函数在堆上申请和释放空间。那么在Java中是怎么样的呢?
Java中的堆是用来存储对象本身的以及数组(当然,数组引用是存放在Java栈中的)。只不过和C语言中的不同,在Java中,程序员基本不用去关心空间释放的问题,Java的垃圾回收机制会自动进行处理。因此这部分空间也是Java垃圾收集器管理的主要区域。另外,堆是被所有线程共享的,在JVM中只有一个堆。

上图引自网络,但有个问题:方法区和heap堆都是线程共享的内存区域。
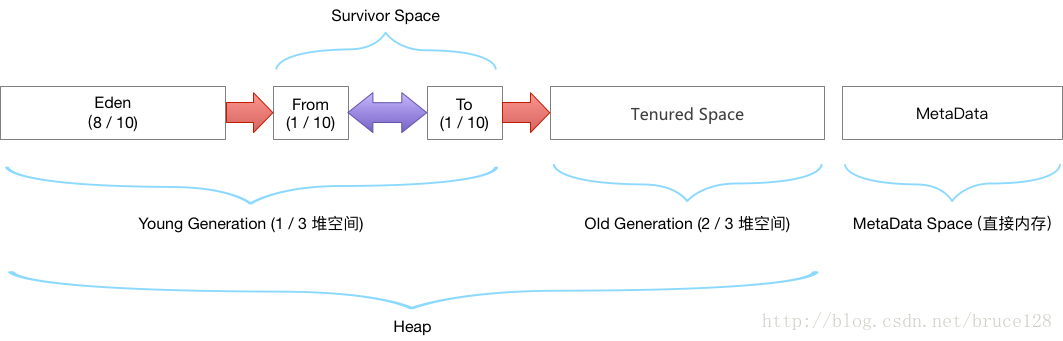
堆空间内存分配(默认情况下)
老年代 : 三分之二的堆空间
年轻代 : 三分之一的堆空间
eden区: 8/10 的年轻代空间
From survivor : 1/10 的年轻代空间
To survivor : 1/10 的年轻代空间
命令行上执行如下命令,查看所有默认的jvm参数
java -XX:+PrintFlagsFinal -version-XX:InitialSurvivorRatio 新生代Eden/Survivor空间的初始比例
-XX:Newratio Old区 和 Yong区 的内存比例一道推算题:默认参数下,如果仅给出eden区40M,求堆空间总大小
根据比例可以推算出,两个survivor区各5M,年轻代50M。老年代是年轻代的两倍,即100M。那么堆总大小就是150M
关于方法区和永久代:
在HotSpot JVM中,这次讨论的永久代,就是上图的方法区(JVM规范中称为方法区)。《Java虚拟机规范》只是规定了有方法区这么个概念和它的作用,并没有规定如何去实现它。在其他JVM上不存在永久代。
1.7构成
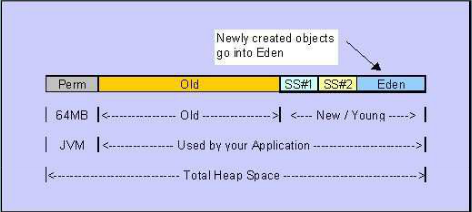
1.8的构成
堆是JVM内存占用最大,管理最复杂的一个区域。其唯一的用途就是存放对象实例:所有的对象实例及数组都在对上进行分配。1.7后,字符串常量池从永久代中剥离出来,存放在堆中。堆有自己进一步的内存分块划分,按照GC分代收集角度的划分请参见上图。
(1) 堆是JVM中所有线程共享的,因此在其上进行对象内存的分配均需要进行加锁,这也导致了new对象的开销是比较大的
(2) Sun Hotspot JVM为了提升对象内存分配的效率,对于所创建的线程都会分配一块独立的空间TLAB(Thread Local Allocation Buffer),其大小由JVM根据运行的情况计算而得,在TLAB上分配对象时不需要加锁,因此JVM在给线程的对象分配内存时会尽量的在TLAB上分配,在这种情况下JVM中分配对象内存的性能和C基本是一样高效的,但如果对象过大的话则仍然是直接使用堆空间分配
(3) TLAB仅作用于新生代的Eden Space,因此在编写Java程序时,通常多个小的对象比大的对象分配起来更加高效。
(4) 所有新创建的Object 都将会存储在新生代Yong Generation中。如果Young Generation的数据在一次或多次GC后存活下来,那么将被转移到OldGeneration。新的Object总是创建在Eden Space。

1.新生代:Eden+From Survivor+To Survivor
2.老年代:OldGen
3.永久代(方法区的实现) : PermGen----->替换为Metaspace(本地内存中)
5.方法区
方法区在JVM中也是一个非常重要的区域,它与堆一样,是被线程共享的区域。在方法区中,存储了每个类的信息(包括类的名称、方法信息、字段信息)、静态变量、常量以及编译器编译后的代码等。方法区逻辑上属于堆的一部分,但是为了与堆进行区分,通常又叫“非堆”。
在Class文件中除了类的字段、方法、接口等描述信息外,还有一项信息是常量池,用来存储编译期间生成的字面量和符号引用。
在方法区中有一个非常重要的部分就是运行时常量池,它是每一个类或接口的常量池的运行时表示形式,在类和接口被加载到JVM后,对应的运行时常量池就被创建出来。当然并非Class文件常量池中的内容才能进入运行时常量池,在运行期间也可将新的常量放入运行时常量池中,比如String的intern方法。
在JVM规范中,没有强制要求方法区必须实现垃圾回收。很多人习惯将方法区称为“永久代”,是因为HotSpot虚拟机以永久代来实现方法区,从而JVM的垃圾收集器可以像管理堆区一样管理这部分区域,从而不需要专门为这部分设计垃圾回收机制。不过自从JDK7之后,Hotspot虚拟机便将运行时常量池从永久代移除了。
永久代(PermGen) ,绝大部分 Java 程序员应该都见过 “java.lang.OutOfMemoryError: PermGen space “这个异常。这里的 “PermGen space”其实指的就是方法区。不过方法区和“PermGen space”又有着本质的区别。前者是 JVM 的规范,而后者则是 JVM 规范的一种实现,并且只有 HotSpot 才有 “PermGen space”,而对于其他类型的虚拟机,如 JRockit(Oracle)、J9(IBM) 并没有“PermGen space”。由于方法区主要存储类的相关信息,所以对于动态生成类的情况比较容易出现永久代的内存溢出。最典型的场景就是,在 jsp 页面比较多的情况,容易出现永久代内存溢出。
6.元空间(Metaspace)
元空间的内存大小
元空间是方法区的在HotSpot jvm 中的实现,方法区主要用于存储类的信息、常量池、方法数据、方法代码等。方法区逻辑上属于堆的一部分,但是为了与堆进行区分,通常又叫“非堆”。
元空间的本质和永久代类似,都是对JVM规范中方法区的实现。不过元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存。,理论上取决于32位/64位系统可虚拟的内存大小。可见也不是无限制的,需要配置参数。
常用配置参数
1.MetaspaceSize
初始化的Metaspace大小,控制元空间发生GC的阈值。GC后,动态增加或降低MetaspaceSize。在默认情况下,这个值大小根据不同的平台在12M到20M浮动。使用Java -XX:+PrintFlagsInitial命令查看本机的初始化参数。
2.MaxMetaspaceSize
限制Metaspace增长的上限,防止因为某些情况导致Metaspace无限的使用本地内存,影响到其他程序。在本机上该参数的默认值为4294967295B(大约4096MB)。
3.MinMetaspaceFreeRatio
当进行过Metaspace GC之后,会计算当前Metaspace的空闲空间比,如果空闲比小于这个参数(即实际非空闲占比过大,内存不够用),那么虚拟机将增长Metaspace的大小。默认值为40,也就是40%。设置该参数可以控制Metaspace的增长的速度,太小的值会导致Metaspace增长的缓慢,Metaspace的使用逐渐趋于饱和,可能会影响之后类的加载。而太大的值会导致Metaspace增长的过快,浪费内存。
4.MaxMetasaceFreeRatio
当进行过Metaspace GC之后, 会计算当前Metaspace的空闲空间比,如果空闲比大于这个参数,那么虚拟机会释放Metaspace的部分空间。默认值为70,也就是70%。
5.MaxMetaspaceExpansion
Metaspace增长时的最大幅度。在本机上该参数的默认值为5452592B(大约为5MB)。
6.MinMetaspaceExpansion
Metaspace增长时的最小幅度。在本机上该参数的默认值为340784B(大约330KB为)。
测试并追踪元空间大小
a. jvm参数配置
-XX:MaxPermSize=10m
-XX:PermSize=10m
-Xms100m
-Xmx100m
-XX:-UseGCOverheadLimitb. 测试代码
public class StringOomMock {
static String base = "string";
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
for (int i=0;i< Integer.MAX_VALUE;i++){
String str = base + base;
base = str;
list.add(str.intern());
}
}
}c. jdk1.6 下的运行结果,jdk1.6 环境下是永久代OOM
153658
153660
Exception in thread "main" java.lang.OutOfMemoryError: PermGen space
at java.lang.String.intern(Native Method)
at com.jd.im.StringOomMock.main(StringOomMock.java:17)d. jdk1.7 下的运行结果,jdk1.7 下是堆OOM,并且伴随着频繁的FullGC, CPU一直高位运行
2252792
2252794
2252796
2252798
*** java.lang.instrument ASSERTION FAILED ***: "!errorOutstanding" with message can't create name string at ../../../src/share/instrument/JPLISAgent.c line: 807
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at java.nio.CharBuffer.wrap(CharBuffer.java:369)
at sun.nio.cs.StreamEncoder.implWrite(StreamEncoder.java:265)
at sun.nio.cs.StreamEncoder.write(StreamEncoder.java:125)
at java.io.OutputStreamWriter.write(OutputStreamWriter.java:207)
at java.io.BufferedWriter.flushBuffer(BufferedWriter.java:129)
at java.io.PrintStream.write(PrintStream.java:526)
at java.io.PrintStream.print(PrintStream.java:597)
at java.io.PrintStream.println(PrintStream.java:736)
at com.jd.im.StringOomMock.main(StringOomMock.java:16)e. jdk1.8 下的运行结果,jdk1.8的运行结果同1.7的一样,都是堆空间OOM。
2236898
2236900
2236902
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at java.lang.Integer.toString(Integer.java:403)
at java.lang.String.valueOf(String.java:3099)
at java.io.PrintStream.print(PrintStream.java:597)
at java.io.PrintStream.println(PrintStream.java:736)
at com.jd.im.StringOomMock.main(StringOomMock.java:16)测试元空间溢出
元数据区取代了1.7版本及以前的永久代。元数据区和永久代本质上都是方法区的实现。方法区存放虚拟机加载的类信息,静态变量,常量等数据
a. jvm参数配置
-XX:MetaspaceSize=8m
-XX:MaxMetaspaceSize=50mb. 测试代码
借助cglib框架生成新类。
<dependency>
<groupId>cglib</groupId>
<artifactId>cglib</artifactId>
<version>2.2.2</version>
</dependency>import java.lang.management.ClassLoadingMXBean;
import java.lang.management.ManagementFactory;
import java.lang.reflect.Method;
import net.sf.cglib.proxy.CallbackFilter;
import net.sf.cglib.proxy.Dispatcher;
import net.sf.cglib.proxy.Enhancer;
import net.sf.cglib.proxy.MethodInterceptor;
public class MetaSpaceOomMock {
public static void main(String[] args) {
ClassLoadingMXBean loadingBean = ManagementFactory.getClassLoadingMXBean();
while (true) {
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(MetaSpaceOomMock.class);
enhancer.setCallbackTypes(new Class[]{Dispatcher.class, MethodInterceptor.class});
enhancer.setCallbackFilter(new CallbackFilter() {
public int accept(Method method) {
return 1;
}
@Override
public boolean equals(Object obj) {
return super.equals(obj);
}
});
Class clazz = enhancer.createClass();
System.out.println(clazz.getName());
//显示数量信息(共加载过的类型数目,当前还有效的类型数目,已经被卸载的类型数目)
System.out.println("total: " + loadingBean.getTotalLoadedClassCount());
System.out.println("active: " + loadingBean.getLoadedClassCount());
System.out.println("unloaded: " + loadingBean.getUnloadedClassCount());
}
}
}c. 运行输出:
jvm.MetaSpaceOomMock$$EnhancerByCGLIB$$567f7ec0
total: 6265
active: 6265
unloaded: 0
jvm.MetaSpaceOomMock$$EnhancerByCGLIB$$3501581b
total: 6266
active: 6266
unloaded: 0
Exception in thread "main" net.sf.cglib.core.CodeGenerationException: java.lang.reflect.InvocationTargetException-->null
at net.sf.cglib.core.AbstractClassGenerator.generate(AbstractClassGenerator.java:345)
at net.sf.cglib.proxy.Enhancer.generate(Enhancer.java:492)
at net.sf.cglib.core.AbstractClassGenerator$ClassLoaderData$3.apply(AbstractClassGenerator.java:93)
at net.sf.cglib.core.AbstractClassGenerator$ClassLoaderData$3.apply(AbstractClassGenerator.java:91)
at net.sf.cglib.core.internal.LoadingCache$2.call(LoadingCache.java:54)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at net.sf.cglib.core.internal.LoadingCache.createEntry(LoadingCache.java:61)
at net.sf.cglib.core.internal.LoadingCache.get(LoadingCache.java:34)
at net.sf.cglib.core.AbstractClassGenerator$ClassLoaderData.get(AbstractClassGenerator.java:116)
at net.sf.cglib.core.AbstractClassGenerator.create(AbstractClassGenerator.java:291)
at net.sf.cglib.proxy.Enhancer.createHelper(Enhancer.java:480)
at net.sf.cglib.proxy.Enhancer.createClass(Enhancer.java:337)
at jvm.MetaSpaceOomMock.main(MetaSpaceOomMock.java:38)
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.GeneratedMethodAccessor1.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at net.sf.cglib.core.ReflectUtils.defineClass(ReflectUtils.java:413)
at net.sf.cglib.core.AbstractClassGenerator.generate(AbstractClassGenerator.java:336)
... 12 more
Caused by: java.lang.OutOfMemoryError: Metaspace
at java.lang.ClassLoader.defineClass1(Native Method)
at java.lang.ClassLoader.defineClass(ClassLoader.java:763)
... 17 more我们的JDK8中类加载(方法区的功能)已经不在永久代PerGem中了,而是Metaspace中,如果是1.7的jdk,那么报OOM的将是PermGen区域。
JDK1.8 JVM运行时数据区域概览

这里介绍的是JDK1.8 JVM运行时内存数据区域划分。1.8同1.7比,最大的差别就是:元数据区取代了永久代。元空间的本质和永久代类似,都是对JVM规范中方法区的实现。不过元空间与永久代之间最大的区别在于:元数据空间并不在虚拟机中,而是使用本地内存。
直接内存
直接内存并不是虚拟机运行时数据区的一部分,也不是Java 虚拟机规范中农定义的内存区域。在JDK1.4 中新加入了NIO(New Input/Output)类,引入了一种基于通道(Channel)与缓冲区(Buffer)的I/O 方式,它可以使用native 函数库直接分配堆外内存,然后通脱一个存储在Java堆中的DirectByteBuffer 对象作为这块内存的引用进行操作。这样能在一些场景中显著提高性能,因为避免了在Java堆和Native堆中来回复制数据。
- 本机直接内存的分配不会受到Java 堆大小的限制,受到本机总内存大小限制
- 配置虚拟机参数时,不要忽略直接内存 防止出现OutOfMemoryError异常
直接内存(堆外内存)与堆内存比较
- 直接内存申请空间耗费更高的性能,当频繁申请到一定量时尤为明显
- 直接内存IO读写的性能要优于普通的堆内存,在多次读写操作的情况下差异明显
import java.nio.ByteBuffer;
/**
* 直接内存 与 堆内存的比较
*/
public class ByteBufferCompare {
public static void main(String[] args) {
allocateCompare(); //分配比较
operateCompare(); //读写比较
}
/**
* 直接内存 和 堆内存的 分配空间比较
*
* 结论: 在数据量提升时,直接内存相比非直接内的申请,有很严重的性能问题
*
*/
public static void allocateCompare(){
int time = 10000000; //操作次数
long st = System.currentTimeMillis();
for (int i = 0; i < time; i++) {
ByteBuffer buffer = ByteBuffer.allocate(2); //非直接内存分配申请
}
long et = System.currentTimeMillis();
System.out.println("在进行"+time+"次分配操作时,堆内存 分配耗时:" + (et-st) +"ms" );
long st_heap = System.currentTimeMillis();
for (int i = 0; i < time; i++) {
ByteBuffer buffer = ByteBuffer.allocateDirect(2); //直接内存分配申请
}
long et_direct = System.currentTimeMillis();
System.out.println("在进行"+time+"次分配操作时,直接内存 分配耗时:" + (et_direct-st_heap) +"ms" );
}
/**
* 直接内存 和 堆内存的 读写性能比较
*
* 结论:直接内存在直接的IO 操作上,在频繁的读写时 会有显著的性能提升
*
*/
public static void operateCompare(){
int time = 1000000000;
ByteBuffer buffer = ByteBuffer.allocate(2*time);
long st = System.currentTimeMillis();
for (int i = 0; i < time; i++) {
buffer.putChar('a');
}
buffer.flip();
for (int i = 0; i < time; i++) {
buffer.getChar();
}
long et = System.currentTimeMillis();
System.out.println("在进行"+time+"次读写操作时,非直接内存读写耗时:" + (et-st) +"ms");
ByteBuffer buffer_d = ByteBuffer.allocateDirect(2*time);
long st_direct = System.currentTimeMillis();
for (int i = 0; i < time; i++) {
buffer_d.putChar('a');
}
buffer_d.flip();
for (int i = 0; i < time; i++) {
buffer_d.getChar();
}
long et_direct = System.currentTimeMillis();
System.out.println("在进行"+time+"次读写操作时,直接内存读写耗时:" + (et_direct - st_direct) +"ms");
}
}输出:
在进行10000000次分配操作时,堆内存 分配耗时:12ms
在进行10000000次分配操作时,直接内存 分配耗时:8233ms
在进行1000000000次读写操作时,非直接内存读写耗时:4055ms
在进行1000000000次读写操作时,直接内存读写耗时:745ms可以自己设置不同的time 值进行比较
分析
从数据流的角度,非直接内存作用链:
本地IO –>直接内存–>非直接内存–>直接内存–>本地IO
直接内存作用链:
本地IO–>直接内存–>本地IO直接内存使用场景
- 有很大的数据需要存储,它的生命周期很长
- 适合频繁的IO操作,例如网络并发场景

